【Docker】ES、Kibana及IK安装配置
目录
一.单节点安装部署
1.版本选择
2.推荐及总结
3.官网下载地址
4.创建网络
5.拉取镜像
6.创建文件夹
7.运行docker命令
二、安装kibana
1.安装kibana
2.浏览器访问
3.国际化
三、Elasticsearch查询
1.数据插入:POST或PUT
2.数据查询GET
3.分词测试
四、安装分词器IK
(一)手动安装
1.下载IK安装包
2.解压IK,修改plugin-descriptor.properties 文件
(二)在线安装IK
1.在线安装IK
2.浏览器访问
3.测试
一.单节点安装部署
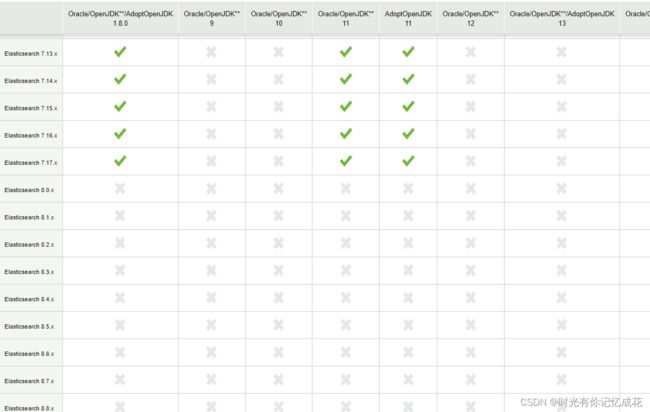
1.版本选择
[支持一览表 | Elastic]
2.推荐及总结
- ES 7.x 及之前版本,选择 Java 8
- ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 18
- Java 9、Java 10、Java 12 和 Java 13 均为短期版本,不推荐使用
- M1(Arm) 系列 Mac 用户建议选择 ES 7.8.x 以上版本,因为考虑到 ELK 不同产品自身兼容性,7.8.x以上版本原生支持 Arm 原生 JDK
3.官网下载地址
Past Releases of Elastic Stack Software | Elastic
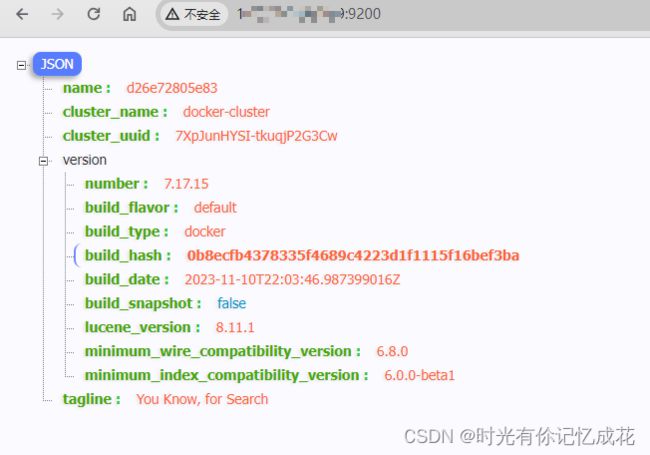
以下安裝教程选择7.x 的最新版本: 7.17.15
注:建议选择7.15.5或7.17.6 ,因为分词器的版本最高为7.17.6。当然,安装7.17.15也有对应的解决办法。
4.创建网络
docker network create elastic5.拉取镜像
docker pull elasticsearch:7.17.156.创建文件夹
创建数据、日志、插件存放文件夹
mkdir -p {'/docker/es/data','/docker/es/logs','/docker/es/plugins','/docker/es/config'}7.运行docker命令
docker run -d \
-p 9200:9200 \
--restart=always \
--name es \
-v /docker/es/logs:/usr/share/elasticsearch/logs \
-v /docker/es/data:/usr/share/elasticsearch/data \
-v /docker/es/plugins:/usr/share/elasticsearch/plugins \
-v /docker/es/config:/usr/share/elasticsearch/config \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
-e "TAKE_FILE_OWNERSHIP=true" \
--network elastic --privileged elasticsearch:7.17.15
# 命令解释:
# -p 9200:9200:端口映射配置
# restart=always:开机启动
# -e “discovery.type=single-node”:非集群模式
# -e “ES_JAVA_OPTS=-Xms512m -Xmx512m”:设置内存,如果服务器内存不是很大,这里设置小点,否则服务将起不来
# -v 本地目录:逻辑目录
# -v /usr/local/es/single/logs:/usr/share/elasticsearch/logs 挂载逻辑卷,绑定es的日志目录
# -v /usr/local/es/single/data:/usr/share/elasticsearch/data 挂载逻辑卷,绑定es的数据目录
# -v /usr/local/es/single/plugins:/usr/share/elasticsearch/plugins 挂载逻辑卷,绑定es的插件目录
# --network elastic 加入一个名为elastic的网络中
# –privileged 允许访问挂载目录
# --name es 容器名
# TAKE_FILE_OWNERSHIP:挂载权限问题,绑定-挂载本地目录或文件,请确保该用户能够读懂它,而数据和日志dirs则需要另外的写访问权限。一个好的策略是为本地目录授予组对gid 1000或0的访问权限浏览器访问http://xxxxxx:9200
二、安装kibana
[支持一览表 | Elastic]
即es是哪个版本,kibana就安装对应的版本即可
1.安装kibana
docker pull kibana:7.17.15docker run -d \
-p 5601:5601 \
-e "ELASTICSEARCH_HOSTS=http://es:9200" \
--network=elastic \
--name kibana kibana:7.17.15
# 命令解释
# -p 5601:5601 端口映射
# –network elastic 加入一个名为elastic的网络中,与elasticsearch在同一个网络中
# -e ELASTICSEARCH_HOSTS=http://127.0.0.1:9200 设置elasticsearch的地址,也可以用es容器名,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch2.浏览器访问
http://xxxxx:5601

3.国际化
# 将容器内的配置拷贝到本地
docker cp 容器id:/usr/share/kibana/config/kibana.yml /usr/local/kibana/kibana.yml
# 修改配置文件,添加国际化后保存
i18n.locale: "zh-CN"
# 将修改后的配置拷贝到容器内
docker cp /usr/local/kibana/kibana.yml 容器id:/usr/share/kibana/config/kibana.yml
# 重启kibana
docker restart kibana三、Elasticsearch查询
1.数据插入:POST或PUT
PUT /mytest/user/1
{
"name": "李四lisi",
"age": 21,
"car": "宝马x5"
}
# 结果
{
"_index" : "mytest",
"_type" : "user",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}2.数据查询GET
# 根据id进行查询
GET /mytest/user/1
# 结果:
{
"_index" : "mytest",
"_type" : "user",
"_id" : "1",
"_version" : 3,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "李四lisi",
"age" : 21,
"car" : "宝马x5"
}
}
# 查当前索引下所有数据
GET /mytest/user/_search
#结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "mytest",
"_type" : "user",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "张三,zhangsan",
"age" : 21,
"car" : "奥迪a6l"
}
},
{
"_index" : "mytest",
"_type" : "user",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "李四lisi",
"age" : 21,
"car" : "宝马x5"
}
}
]
}
}
# 查当前索引下多个id的数据
GET /mytest/user/_mget
{
"ids": ["1","2"]
}
#结果:
{
"docs" : [
{
"_index" : "mytest",
"_type" : "user",
"_id" : "1",
"_version" : 3,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "李四lisi",
"age" : 21,
"car" : "宝马x5"
}
},
{
"_index" : "mytest",
"_type" : "user",
"_id" : "2",
"_version" : 1,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "张三,zhangsan",
"age" : 21,
"car" : "奥迪a6l"
}
}
]
}3.分词测试
如果没装分词器,中文分词不是很友好,结果如下:
#分词查询
GET _analyze
{
"analyzer": "standard",
"text": "宝马x5"
}
#结果:
{
"tokens" : [
{
"token" : "宝",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "马",
"start_offset" : 1,
"end_offset" : 2,
"type" : "",
"position" : 1
},
{
"token" : "x5",
"start_offset" : 2,
"end_offset" : 4,
"type" : "",
"position" : 2
}
]
} 四、安装分词器IK
(一)手动安装
IK版本必须和es版本一致,由于安装的es版本为7.17.15,而 当前 ik的最新版本为7.17.6,因此不能在线安装,改为手动安装
在线安装时报错:
Plugin [analysis-ik] was built for Elasticsearch version 7.17.6 but version 7.17.15 is running1.下载IK安装包
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.6/elasticsearch-analysis-ik-7.17.6.zip
2.解压IK,修改plugin-descriptor.properties 文件
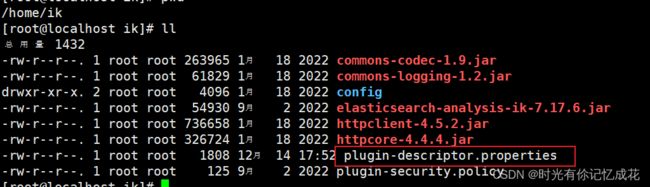
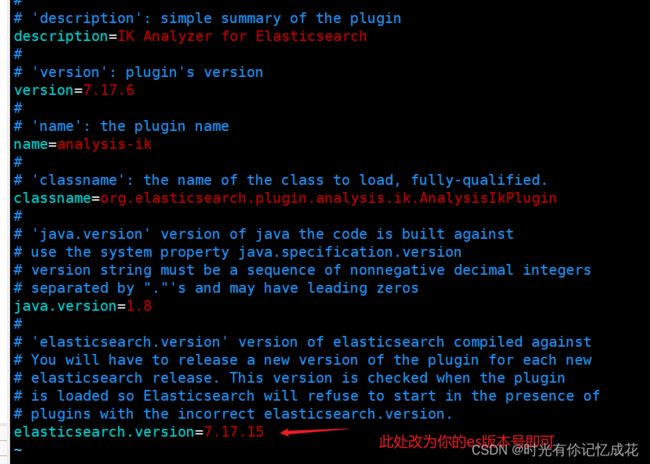
将修改后的IK复制到es容器内:
# d26e72805e83 为容器id,docker ps 即可查看
docker cp /home/ik/ d26e72805e83:/usr/share/elasticsearch/plugins/ik然后重启es即可
# es 你的容器名称
docker restart es(二)在线安装IK
1.在线安装IK
# 查看es容器id
docker ps
# 进入容器内部
docker exec -it 容器id /bin/bash
# 在线下载安装IK
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.6/elasticsearch-analysis-ik-7.17.6.zip
# 退出容器
exit
# 重启容器
docker restart 容器id2.浏览器访问
http://xxxxx:5601/app/dev_tools#/console

3.测试
IK分词安装后有两种分词策略:ik_smart,ik_max_word。其中ik_smart称为智能分词,网上还有别的称呼:最少切分,最粗粒度划分。ik_max_word称为最细粒度划分。
ik_max_word:对输入文本根据词典穷尽各种分割方法是细力度分割策略。
ik_smart:会对输入文本根据词典以及歧义判断等方式进行一次最合理的粗粒度分割。
ik_max_word 测试
GET _analyze
{
"analyzer": "ik_max_word",
"text": "宝马x5"
}
#结果:
{
"tokens" : [
{
"token" : "宝马",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "x5",
"start_offset" : 2,
"end_offset" : 4,
"type" : "LETTER",
"position" : 1
},
{
"token" : "x",
"start_offset" : 2,
"end_offset" : 3,
"type" : "ENGLISH",
"position" : 2
},
{
"token" : "5",
"start_offset" : 3,
"end_offset" : 4,
"type" : "ARABIC",
"position" : 3
}
]
}ik_smart测试
GET _analyze
{
"analyzer": "ik_smart",
"text": "宝马x5"
}
#结果:
{
"tokens" : [
{
"token" : "宝马",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "x5",
"start_offset" : 2,
"end_offset" : 4,
"type" : "LETTER",
"position" : 1
}
]
}