Render Graph 全网最细介绍(一)
基本知识
GPU中的渲染管线
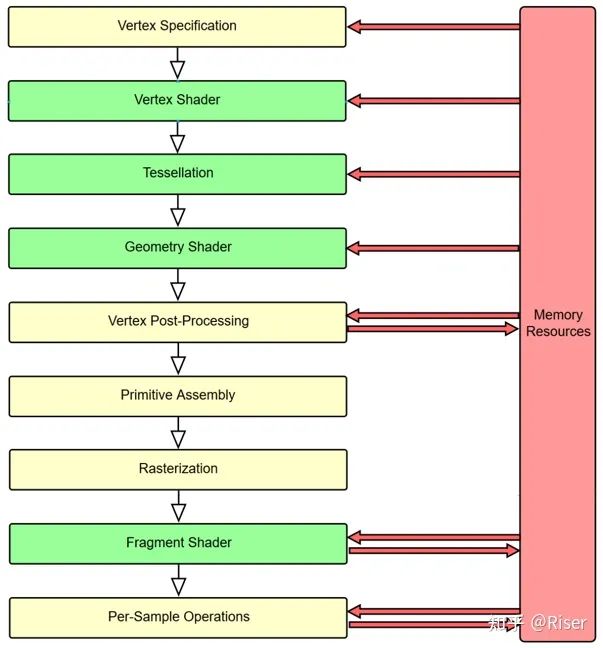
GPU的渲染管线
pass
我们首先来看看GPU中的渲染管线(采用OpenGL中的命名),我们将GPU的一次完整的执行流程叫做一个pass。
resource
我们能够在GPU执行一次之后,就将整个游戏场景给渲染出来吗?答案显然是不可能的,那么这些渲染结果被存储在哪里呢?我们在学习OpenGL的时候,会学习到一个概念叫做FrameBuffer的缓冲,我们通常将GPU的渲染结果存储在各种Buffer中。
我们将搭载GPU的输出信息的Buffer,称作Resource(这是一种狭隘的理解,但是RenderGraph中,Resource大部分都是指的是这些Buffer)
我们下文中提到的Resource概念,大部分都是指的是Buffer、RenderTarget,这些Buffer占用GPU的内存。
游戏开发中最注重的质量评估指标就是性能。上文提到的各种buffer是非常占用显存的,如果这些资源在用完之后不能及时收回,那将会导致GPU的内存利用率降低,甚至GPU内存泄露的问题,所以资源的及时回收非常得重要。对于大部分的Buffer的生命周期只会在一帧之内,某些特殊的buffer除外(例如Front/Back Buffer)。
GPU资源的分配与释放
那么如何对Resource进行分配与释放呢?
在Dx12之前,程序员是不需要对这些Resource进行管理的,底层的图形API会自行对资源的声明周期进行跟踪,自动进行回收。但是这样做的前提是,资源的回收是可被推导的,如果我们的程序是单线程的,那么我们的程序中的资源的声明周期是可以被图形API推导出来的,但是如果涉及到多线程呢?图形API就不知道你到底想要在哪一个时刻回收资源。
所以在Dx12之后,各种现代图形API(Dx12、Vulkan等)就将资源分配与回收的工作交给了我们程序,所有的资源需要我们手动地去跟踪、管理、回收。

如何合理、高效地对这些资源进行管理就成了一个非常难办的事情。
传统的渲染流程
在讲RenderGraph之前,我们需要知道传统的渲染流程,或者说是传统的引擎在渲染的时候是怎么做的。
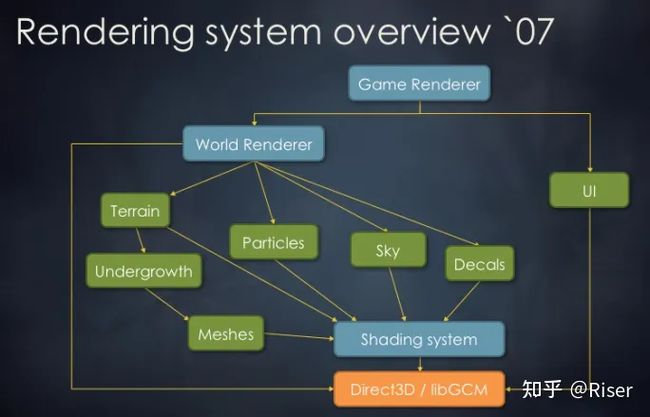
寒霜引擎07年时的系统架构
这是07年Frostbite在GDC上做pre时的架构,我们可以看到整个系统的功能还不是很多。
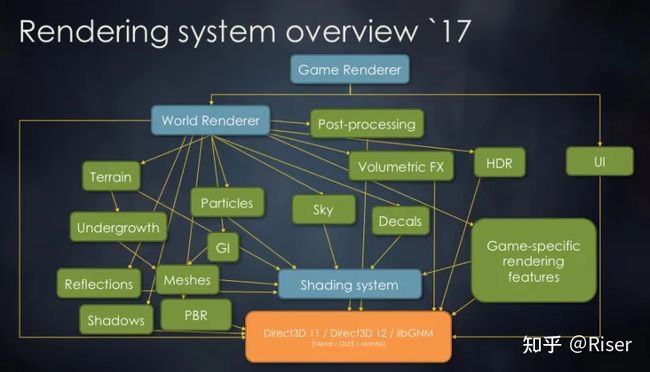
寒霜引擎17年时的系统架构
这是17年Frostbite的系统架构,当然整个图都是精简过的,如果涉及到PBR(Physical-Based Rendering),系统将会更加复杂。随着系统越来越复杂,就会诞生出很多问题。我们逐个进行分析。
- 强耦合:各个系统之间不可能完全独立,一个渲染系统需要的资源(Buffer,RenderTarget等)可能会依赖于另外一个渲染系统,各个系统之间的相互调用的情况非常多。这样有什么问题呢?我们在维护的时候,可能改了一个系统,那么其他很多系统的地方都得改。同时,随着系统越来越复杂,耦合性也会越来越紧密,代码的行数就会飞速增长。
- 资源的显示定义:我们在前文中已经讲到,我们程序员是需要对资源进行手动管理的。什么时候申请资源,什么时候实际分配资源、什么时候回收资源,统统都得程序员自己定义。
- 显式即时模式呈现:我们在渲染的时候,是采取即时渲染的策略,这是一种“说干就干”的策略(我自己的理解来看)。只要程序的指令轮到我了,那我就去找我需要的资源,然后马上开始执行。
- 扩展的局限性:程序的执行完全是按照我们程序编写的顺序进行执行的,当程序运行的时候,渲染流程就已经固定死了,如果要想再调整渲染策略,就得改代码,然后再进行编译执行,难以进行扩展与渲染流程的自定义配置。
- 难以Debug:游戏引擎的代码成十万上百万行,一个bug可能就得让人找的崩溃,更别说这些系统之间还存在极强的耦合性,这样的代码难以进行维护。
Render Graph的诞生
这些问题中的每一个都非常难搞,Frostbite在开发的过程中意识到了这一点。如果不对现有的代码进行重构,那么后边的代码写起来将会非常地难受,因为feature总是在不断的增加。

我们需要对整个渲染流程进行高层次抽象,我们希望有一个系统能够自动管理资源、简化异步计算、提高可扩展性。
于是RenderGraph横空出世。
RenderGraph的目标
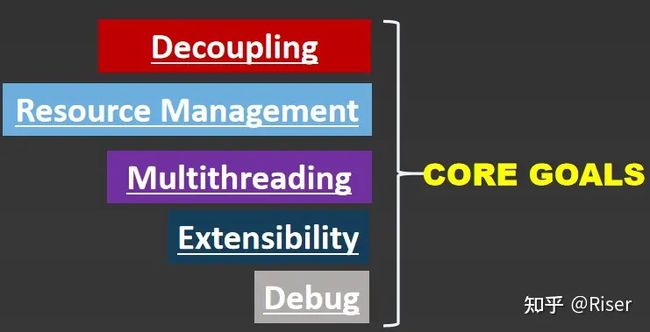
我们希望RenderGraph能够实现以下几点目标:
- 解耦合
- 自动的资源管理
- 简化的多线程渲染
- 良好的可扩展性
- 容易debug
本篇文章只讲了解耦合以及自动的资源管理这两个目标,后续目标之后将会跟进。
什么是RenderGraph
从数据结构上来讲,它是一个有向无环图。它长这样:

RenderGraph的图中,主要有两种节点:1.pass节点。2.resource节点。
在上图中:
- 橙色边框:pass节点
- 蓝色边框:resource节点
- 红色箭头:pass节点指向resource节点,表示该pass对该resource进行写操作。
- 绿色节点:resource节点指向pass节点,表示该resource被该pass读取。
pass节点
我们可以狭义地将pass理解为一个函数,它可以接受一个或多个输入,并产生一个或多个输出。这里的输入与输出只能是resource节点。pass的在拿到resource之后,调用自己内部的执行函数,执行函数一般是调用一次或若干次GPU,产生一个或多个结果,并将这些结果输出。
resource节点
它就是资源节点,每一个资源都有它自己的状态(clear or discard/undefined)。
再次理解RenderGraph
在理解RenderGraph的时候,需要注意以下几点:
- RenderGraph不是一个抽象图、概念图,它是实实在在的一种数据结构,它的每一部分都是能够找到它的实现代码的。
- 各个pass之间是完全独立的存在,pass之间不存在相互调用,每一个pass就根据自己的输入调用GPU,产生若干输出。
- resource节点就是各个pass之间的纽带,但是pass并不关心自己的输入到底是哪一个pass产生的。
这样的抽象,很好解决了以前渲染流程存在的强耦合的问题。
Render Graph是怎样实现的
一个小故事
我们先来看一个关于荒野大镖客的故事。
达奇是我们帮派的首领,他总是有各种点子。有一天我们的点子王达奇想到了一个好点子:


达奇说:我们可以去抢瓦伦丁的银行。抢银行前,我们肯定要制定一个天衣无缝的计划,以下是达奇他提出的计划图:
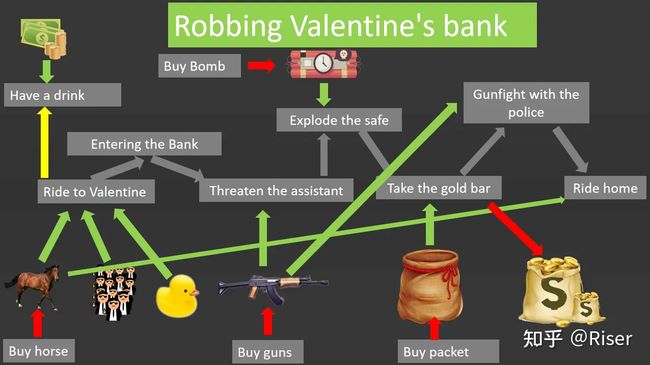
图中:
- 灰色方框:一个需要执行的过程
- 红色箭头:得到、创造、写入
- 绿色箭头:使用
- 灰色箭头:执行顺序
- 黄色箭头:可选的执行路线。
- 图片:需要的资源
何西阿是我们帮派的军师,帮助达奇优化解决方案。何西阿看完这个计划之后:

何西阿表示对计划中去酒馆喝酒的分支和小黄鸭表示不解,于是打算将这些砍掉。
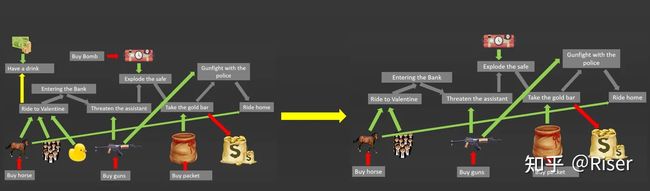
于是,这两部分就被砍掉了。这样计划的制定与优化都做好了,就到了具体的实施阶段。我们的亚瑟同志勇于争先,亚瑟是我们帮派的武力担当:

由故事进行映射对比
这样的一个简单的故事,其实就对应着RenderGraph的三个阶段
- Setup
- Compile
- Execute
我们挨个分析每个阶段做的事情
Setup 阶段
达奇指定的计划图是不是非常眼熟,它和RenderGraph十分相似
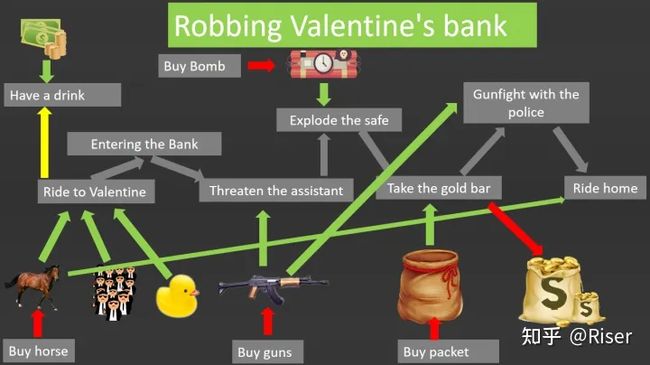
达奇的计划图
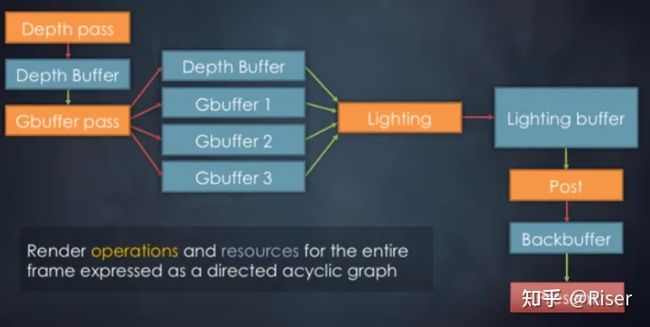
RenderGraph的例子
RenderGraph最亮眼的部分就是在Setup阶段,这个阶段也是它与传统渲染流程最不同的地方。
RenderGraph需要掌握整帧的所有信息。
为什么呢?RenderGraph的策略不是一个“说干就干”的策略,它是一个“只打有准备的仗”的策略。在开始干(执行GPU渲染程序)之前,RenderGraph要看看每个pass要用到哪些resource。pass需要声明:1. 需要操作哪些resource。 2. 要对resource进行哪种操作(read,write,create)。
pass在执行之前,都是需要向RenderGraph进行注册,提前进行声明,pass不能读或写没有声明的resource。
为什么要这么干呢?我们之前提到,手动管理resource是一个不容易的活,所以我们想要将资源的自动管理交给系统来做,我们程序员不管。pass对于resource的声明,能够让RenderGraph帮我们确定resource的生命周期,resource应该在何时被分配,应该在何时被回收,RenderGraph自动帮我们计算,使得resource的声明周期尽可能得短。
需要注意的一点是,在setup阶段,resource还没有被分配空间,系统对于资源的分配遵循“让resource的声明周期尽可能得短”,由于setup阶段,我们并没有用到resource,所以其实这个时候resource只有一个handle,而分配实际的GPU空间。所以pass在声明资源的时候,需要确定resource的状态(clear or discard/undefined),让系统知道现在还不能分配资源。
同时,setup阶段,还会把一些持久资源(生命周期大于一帧)调入内存,例如Back Buffer等。
总结,setup阶段主要干了以下几件事:
- pass声明注册自己用到的资源,需要确定资源的状态
- 未实际分配GPU资源
- 将持久资源导入内存
Compile 阶段
对比何西阿将达奇的计划进行精简,只留下对最终目的有用的部分。
在Compile阶段,RenderGraph中未被引用的resource 和 pass将会被裁减掉,只留下真正执行的部分,相当于是做一次优化。
同时,Compile阶段会对resource的声明周期进行计算,确定resource应该在何时分配资源、何时被回收。
Execute 阶段
对比亚瑟开始执行计划。
在Execute阶段,各个pass开始执行自己的Execute函数(在这个时候才会真正用到GPU)。Execute阶段最大的特点就是,它真正的需要GPU为它分配资源了。
总结
RenderGraph是一个对于渲染流程的一个高层次抽象,它实现了对整帧信息的整体把握,并对整帧的渲染进行整体优化。