C++模板进阶
文章目录
- 前言
- 反向迭代器
-
- 反向迭代器和正向迭代器的区别
- stl反向迭代器源码
- 反向迭代器模拟实现
- 测试
- 模板进阶
-
- 非类型模板参数
-
- Array
- 模板的特化
- 模板的分离编译
前言
模板进阶也没有到一些特别的东西,就是讲比较偏的一些特性。
在这里我们先来讲一下反向迭代器。
反向迭代器
反向迭代器和正向迭代器的区别
严格来说没有大的区别。真正的区别在于++或者- -的方向不一样。
它是倒着走的。

如果是list, 以我们自己的思路实现我们会怎么做?
我们可能有这样一个思路,我们把正向迭代器拷贝一份出来,名字变一下,其他保持不变。
再把反向迭代器的++变成node =node->prev; 就是增加一个类的思路。
这样行不行呢?我们可以测试一下。


![]()
我们再提供一个rbegin(), rend();


最后测试一下

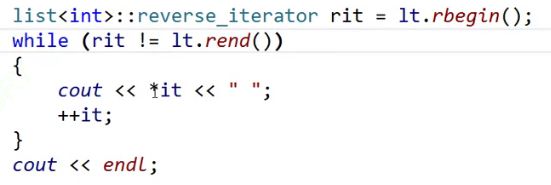

好像还可以,就这么esay.但是还是太年轻太简单了。
我们普通人写的代码,还得看一下高手写的代码,在实践中进步
stl反向迭代器源码
我们看一下stl的源码。
它没有像我们前面一样实现一个类。
它的反向迭代器是这样实现的。
![]()
这怎么传了一个正向迭代器过去。
这是个类模板。
还得接着从源码中找。
用适配器。
发现stl极度的讨厌冗余重复的设计。
看源码。
也就是说你用一个正向迭代器就可以构造一个反向迭代器。

然后看这里++就是正向迭代器的- -, - -就是正向迭代器的+ +;

但是这里又有一个诡异的东西。

它的解引用没有取当前位置,它取了前一个位置。
正向和反向的区别来了。


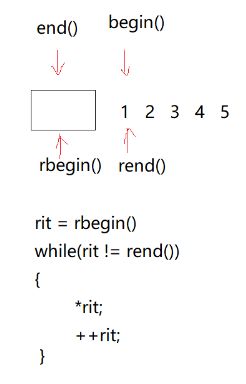
看结构就已经知道为解引用是取前一个位置
反向迭代器模拟实现
现在的思路跟之前不一样了,还是写一个类,但是我现在是用一个正向迭代器取构造一个反向迭代器。
现在重点在于反向迭代器的++是正向迭代器的- -;
template<class Iterator>
struct ReverseIterator
{
typedef ReverseIterator<Iterator> Self;
Iterator _cur;
ReverseIterator(Iterator it)
:_cur(it)
{}
Self& operator++()
{
--_cur;
return *this;
}
Self& operator--()
{
++_cur;
return *this;
}
//内核比较的还是指针
bool operator!=(const Self& s)
{
return _cur != s._cur;
}
};
正向迭代器在物理上是个啥东西,它多大?
4个字节,就是个指针,只是自定义类型封装。
内置类型*it直接变成指令,直接调用那个地址的内容去解引用,自定义类型调用函数。
反向迭代器在物理上是多大?
也是四个字节。
类型的力量,都是4个字节存一个地址,但是三个不同的物种。
现在麻烦的东西来了。

返回前一个位置这很好处理,现在返回值是最难处理的。
这个位置需要T&或者const T&
可以看一下源码是怎么处理的,但是源码用的到东西远超我们目前的水平,所以我们不这样搞。
![]()
现在我们用一个简单的方式去解决,加两个模板参数就解决了。
template<class Iterator, class Ref, class Ptr>
typedef ReverseIterator<Iterator, Ref, Ptr> Self;
Ref operator*()
{
Iterator tmp = _cur;
--tmp;
return *tmp;
}
至此,反向迭代器就成型了,我们就可以不用重复的方式了。
测试
接着我们在自己模拟实现的list当中测试一下。
![]()


好了。
两种实现方式的比较
关键点来了,好像这两种实现方式没有什么差别,都是实现一个类。
第一种方式,实现了一个正向迭代器,我把正向迭代器拷贝下来,再改一下就实现了。
第二种方式,第二种方式,用正向迭代器去初始化一个反向迭代器。
用正向迭代器去初始反向迭代器。那反向迭代器是不是包含一个正向迭代器对象。
最关键的地方来了。vector的反向迭代器怎么搞?
难道像第一种方式一样吗?不行,因为vector的迭代器本身就是内置类型,搞定。
但是第二种方式可以。
反向迭代器搞适配最重要的原因就是为了真正复用
给出list的正向迭代器可以适配出反向迭代器。那vector呢?
其实你实现除了一个反向迭代器,所以容器的反向迭代器都出来了
只要你有正向迭代器,你的正向迭代器能支持- -,也就是双向迭代器。
跟你的迭代器是原生指针还是自定义类型没有什么关系。
模板进阶
首先我们要把自己的视角打开一些,不能局限于只是类型的概念。
还有我们前面学到的适配器,仿函数这些。
我们前面讲的那些参数叫做模板参数,准确点叫做类型模板参数。
今天我们还要讲一个非类型模板参数。
非类型模板参数
这个非类型模板参数在什么地方有用呢?
假设我需要写一个静态的数组。以前的方式。
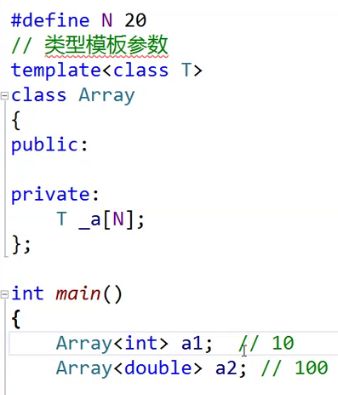
好像非常好,那假设N一个要10,一个要100是不是解决不了。
所以引入了非类型模板参数,它不是类型,它是常量,准确来说是整型常量。
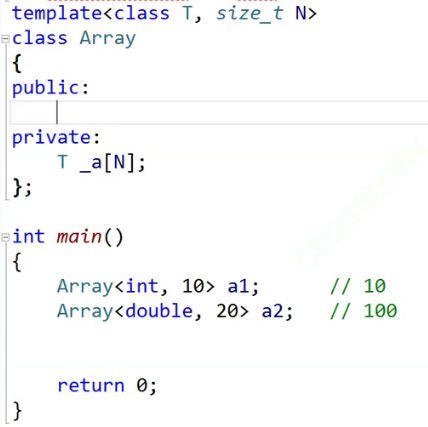
// 类型模板参数
// 非类型模板参数 -- 整形常量
template<class T, int N = 20>
class Array
{
public:
private:
T _a[N];
};
int main()
{
Array<int, 10> a1;
Array<double, 20> a1;
return 0;
}
所以它还是很方便。
它针对的是有些容器一开始就想去固定一些东西。
比如:

非类型模板只能是整型常量,而且只能是右值。
int, char,bool, long, long这些都属于整型家族。
用了非类型模板参数就不怎么需要typedef
Array
给大家看一个新东西,C11增加了一个新容器。

Array是一个静态数组,一个固定大小的顺序容器。
这东西怎么用呢?

C++设计出这个是为了对标vector吗?
它对标的是C语言的静态数组,它对比静态数组的优势是什么?
它对越界的检查更加严格

它怎样做到全面检查的?
很简单,你传的标识符是一个内置类型,它不需要解引用。
它是一个函数调用,它里面可以对这个参数进行检查。
这里有一个挺有意思的点,我为什么要用这个Araay.我直接用vector,还可以初始化。
vector<int> v(10, 0);
v[10];
唯一有点区别的就是array的空间是在栈上,以为它是直接开一个数组。
vector是在堆上,它要动态申请一下。
动态申请效率也很高,array在栈上,还可能把栈本来就不大,堆很大。
模板的特化
有些地方有需求,我们想对某些类型进行特殊处理。
比如我们比较日期类

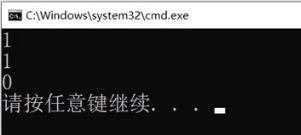
但是这个比较好像并不满足我的需求
我还是希望按日期去比较但是它现在是日期的指针,日期的指针本身也是可以比较的,但是它比较的方式并不符合需求。我还是想要用实际的日期来比较。
那怎么办?
不用仿函数,还有别的方式吗?
我们可以用模板特化的语法。

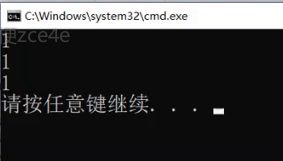
这种写法的意思就是,你不用日期的指针就用原来那个。
你是日期的指针我就用特化的那个。
模板针对的是广泛的类型,但是我们可能想对某些类型进行特殊处理。
上面的函数模板是可以不用特化的


这两个是可以同时存在的,只是它跟模板实例化出来的函数构成函数重载。
刚才用的是特化,这个是匹配。
虽然好像可以用这个匹配替换掉特化,但是特化的用途还是非常大的。
再给大家看一个场景
这是我们我们讲仿函数时举过的一个例子。

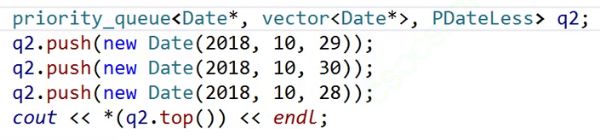
我不想写这个仿函数,我有没有其他的方式。
我们可以用特化的方式。
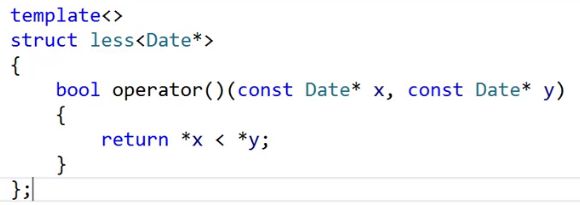
Date*可以调用这个特化版本。
函数模板特化的意义好像确实不大,但是类模板很有意义。
再看一个应用场景
这是一个仿函数


特化除了我们之前的玩法,还有一个更宽泛的玩法。
之前专门特化了Date*,现在还能这样特化。

这个特化叫做偏特化,它和前面的特化有什么区别呢?
刚才的特化是针对T实例成具体的Date*,它是针对具体的类型。
现在对她进行进一步的限制,所以叫做偏特化。
它是针对指针这个泛类。
如果你写全特化,要写好几个。现在只要你是指针都可以解引用,我都不是用指针比较,我是用指针比较的对象比较。
特化就是要对某些类型处理,但不一定是具体的类型,它可以是泛的类型,比如指针。
1.当全特化和偏特化同时存在的时候走哪个?
肯定是走全特化,全特化是现成的…
2.当它们同时存在的时候有没有意义?
有一定的意义。
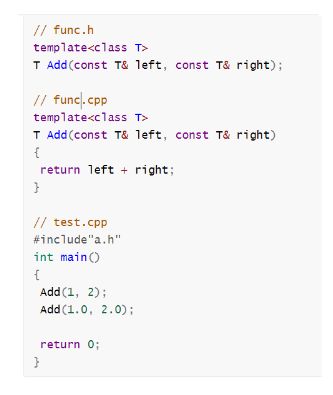
模板的分离编译
模板不支持分离编译,这个我们在前面的文章是有提到的。
我们这里说的不支持分离编译是在两个文件,声明在.h文件,定义在.cpp文件。
为什么?
模板会报链接错误。
fatal error
![]()
我们怎么来看待这个链接错误呢?
首先我们得先分析一下程序会发生什么。
我们还得搞懂为什么普通函数可以,函数模板不可以,或者普通类可以类模板不可以?

刚开始走的都是单线,后面两条线进行交互,除了合并还做一件很重要的事情,链接。

大家注意,func.i生成fun.o的时候生成一堆汇编指令,但是它只能生成func的,生不成Add的。

为什么它生不成Add的?

现在其实就已经可以解释为什么链接错误了,因为没有Add的地址。
怎么解决呢?
编译不通过就是找不到函数的地址,为什么找不到函数的地址呢?
不知道怎么实例化。
那告诉它怎么实例化就可以了
第一种解决方案
显示实例化

但是这样很不好用
更好的方式
第二种方式
可以声明和定义分离,但是不要分离到两个文件
上面是函数模板,类模板呢?
可以参考一下stl的源码。
模板只定义在一个文件。
继续看其他的,比较短小的函数直接在类里面定义,为什么?
类里面默认就是类联,短小的适合类联。
比较长一点的就在类里面声明,类外面定义。
为什么我放在.h就不存在链接错误?
因为.h在函数调用的地方展开。
Add()只有声明,所以变成call(?),没有地址,然后链接的时候去找。
![]()
那这个函数有没有地址?
有,因为我既有声明又有定义。有定义就不需要找了,直接实例化,然后在当前函数就生成地址。