Oracle中的数据类型详解
因为业务需求,我们通常需要知道数据库中的数据类型。本文就Oracle数据库,列出了比较详尽的数据类型,仅供大家参考。
分类目录
一、字符类型
二、数值类型
三、日期类型
四、long类型与lob大型对象数据类型
五、rowid & urowid类型
一、字符类型
- char 定长字符类型(未达到指定长度时,自动在末尾用空格补全);默认值为1;最大2000字节;非unicode。
- nchar 定长字符类型(未达到指定长度时,自动在末尾用空格补全);默认值为1;最大1000字节;根据unicode,所有字符都占两个字节。
- varchar2 变长字符类型(未达到指定长度时,不自动补全空格);定义时需指定长度;最大为4000字节;非unicode。
- nvarchar2 变长字符类型(未达到指定长度时,不自动补全空格);定义时需指定长度;最大为2000字节;根据unicode,所有字符都占两个字节。
说明:(1)unicode字符集是为了解决字符集不兼容的问题而产生的,所有字符都用两个字节表示,即英文字符也用两个字节表示。(2)以上的最大长度都是指字节长度,而非字符个数,如char(1)就连一个汉字都不能存放。
举例:
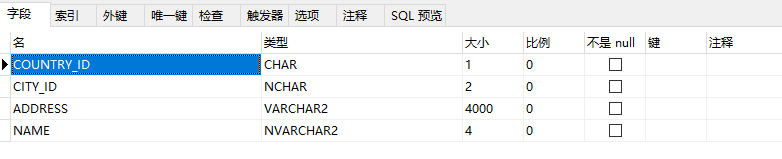
create table test_char(
country_id char,
city_id nchar(2),
address varchar2(4000),
name nvarchar2(4)
);
插入数据并查询:
insert into test_char values ('1', '中国', '浙江省杭州市西湖区', '司马相如');
二、数值类型
oracle中的数值类型主要为三种:number,binary_float,binary_double,其他的类型基本上都是number类型的子类型。
- number(p,s)类型
- p精度,表示包括小数在内的总共有效位数,p的取值范围为[1~38](若没有指定,默认为38);s表示精确到多少位,取值范围为[-84~127](若没有指定,默认为0),当s取负数时,将小数点左边的s位置为0,并四舍五入。
- 当小数位数大于s时,采用四舍五入的方式。当整数部分的长度大于p-s时,报错。
- 需要22个字节的存储空间。
官方文档给出的几个例子如下:
| 输入数据 | 定义类型 | 存储结果 |
| 7,456,123.89 | NUMBER | 7456123.89 |
| 7,456,123.89 | NUMBER(*,1) | 7456123.9 |
| 7,456,123.89 | NUMBER(9) | 7456124 |
| 7,456,123.89 | NUMBER(9,2) | 7456123.89 |
| 7,456,123.89 | NUMBER(9,1) | 7456123.9 |
| 7,456,123.89 | NUMBER(6) | 报错,超精度 |
| 7,456,123.89 | NUMBER(7,-2) | 7456100 |
2. number类型的子类型
- integer或int是number的子类型,等同于number(38)
- smallint是number的子类型,等同于number(38)
- decimal是number(p,s)的子类型,可以使用decimal(p,s),若p,s未指定,等同于number(38)
3. float类型
- float(b),数b表示二进制进度,b的取值范围为[1,126],默认为126
- real是float(b)的子类型,等同于float(63)
上述的b是一个二进制精度(binary precision),而不是我们通常说的十进制精度(decimal precision),需要进行以下的转换:binary precision=int(b*0.30103)
举例来说:当b=2,则对应的十进制精度为int(2*0.30103)=0,即小数点后精度为0。
eg:56.2存储到float(2)变为60。计算过程:56.2=5.62*10^1,因为精度为0只能取到整数,5.62四舍五入后为6,最后取值为6*10^1=60
4. binary_float和binary_double类型
- binary_float 32位单精度浮点数数据类型,需要5个字节(4字节+1个长度字节)支持至少6位精度。
- binary_double 64位双精度浮点数数据类型,需要9个字节(8字节+1个长度字节)。
举例:
create table test_num(
n1 number,
n2 number(38),
n3 number(9,2),
n4 int,
n5 smallint,
n6 decimal(5,2),
n7 float,
n8 float(2),
n9 real,
n10 binary_float,
n11 binary_double
); 
插入数据并查询结果:
insert into test_num values (1.23, 123, 7456123.89, 573, 34, 673.43, 34.1264, 56.2, 23.231, 12.34f, 34.56d);
select * from test_num;
数值类型总结:binary_float和binary_double不常用,因为其表示范围更大可用于科学计算,但精度没有number类型高(可用于金融数据),而float表示的是二进制精度,需要进行精度转换。综上,在使用Oracle的数值类型时我们最好都采用number(p,s)的方式。
三、日期类型
- date 存储以下信息:世纪,年,月,日,时,分,秒。占用七个字节存储空间,每个部分占用一个字节。
- timestamp(precision) ,precision的取值范围为[0,9],默认为6(微秒),最大为9(纳秒);7字节或12字节的定宽日期/时间数据类型;秒的小数部分位数超过precision但未超过9时,按精度四舍五入,超过9时报错
- timestamp(precision) with time zone 该类型是在timestamp(precison)的基础上加入了时区偏移量的值。
- timestamp with local time zone 存储时转化为数据库时区进行规范化存储,但不存储时区信息,客户端检索时,按客户端时区的时间数据返回给客户端
- interval year(precision) to month 可以用来表示几年几月的时间间隔,precision的取值范围为[0~9],默认为2表示不超过两位数的一个数
- interval day(days_precision) to second(seconds_precision) 可以用来存储天、小时、分和秒的时间间隔,days_preciosn取值范围为[0~9],默认是2,seconds_precision取值范围为[0~9],默认是6
举例:
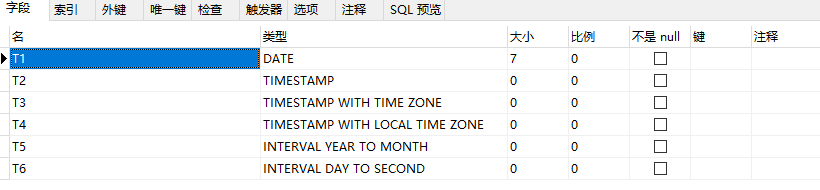
create table test_date(
t1 date,
t2 timestamp(6),
t3 timestamp(9) with time zone,
t4 timestamp with local time zone,
t5 interval year(3) to month,
t6 interval day(3) to second(6)
); 
插入数据并查询结果
insert into test_date (t1, t2, t3, t4) values (sysdate, sysdate, sysdate, sysdate);
insert into test_date (t1) values (to_date('2013-1-21 5:23:01','yyyy-mm-dd hh24:mi:ss'));
insert into test_date (t1) values (to_date('20131112203256', 'yyyymmddhh24miss'));
insert into test_date (t2) values (to_timestamp('20191112203357.999997623', 'yyyymmddhh24miss.ff'));
insert into test_date (t3) values (to_timestamp_tz('20191112203357.999996623', 'yyyymmddhh24miss.ff'));
insert into test_date (t4) values (to_timestamp_tz('20191112203357.999996623', 'yyyymmddhh24miss.ff'));
insert into test_date (t5) values (interval '11' year);
insert into test_date (t5) values (interval '223-9' year(3) to month);
insert into test_date (t6) values (interval '12 10:23:01.1234568' day to second);
注意:第四条t2数据超过精度四舍五入,第六条t4数据超过精度四舍五入。这里先留一个问题:第八条t5记录,插入的月份没有正常显示(知道原因的可以和我讨论)。
四、long类型与lob大型对象数据类型
- long 文本类型,最多达2GB;long列不能作为主键或唯一约束;存储时需要进行字符集转换;一个表中只有一列可以为long或long raw;不支持分布式事务;限制较多
- long raw 可变长二进制数据,不用进行字符集转换的数据,最长2GB。
- blob二进制大型对象,存储图片,音乐,视频等信息,通常将文件转为二进制再存进去;存储的最大大小为4G;支持随机存储
- clob字符大型对象,存储文章或较长的文字。存储的最大大小为4G。
- nclob存储Unicode类型的数据,根据字符集而定的字符类型,最大长度4G。
- bfile二进制文件,存放指向操作系统文件的指针;指向的文件不是数据库的一部分,只能在数据库外维护;只读,数据库将该文件当二进制文件处理。
举例:
create table test_bigfile(
f1 long,
f2 blob,
f3 clob,
f4 nclob,
f5 bfile
);
数据插入与查询:
insert into test_bigfile (f1, f2, f3, f4) values ('12323232', '2312', '111', '212');
insert into test_bigfile (f1, f2, f3, f4) values ('12323232', '231234', '111', '212');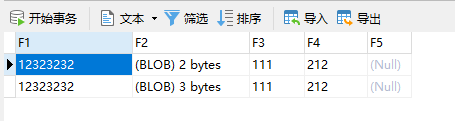
说明:bfile类型的插入需要指定文件所在的目录位置,类似于 insert into test_bigfile (f5) values (bfilename('bfiledir', 'bfile1.txt'));其中bfiledir为文件路径,这里就不在扩展;long类型因为其限制过多,我们通常用blob,clob类型来代替。
五、rowid & urowid类型
- rowid 行地址,十六进制串,表示行在所在的表中唯一的行地址,该数据类型主要用于返回ROWID伪列,常用在可以将表中的每一条记录都加以唯一标识的场合,使用rowid来建立内部索引。
- urowid支持逻辑的和物理的rowids。
我们以上述test_bigfile表为例:
select rowid from test_bigfile;上述两条记录的查询结果为:

解释:从rowid伪列里查询出来的rowid是基于base64编码,一共有18位,分为4部分:OOOOOOFFFBBBBBBRRR
OOOOOO: 六位表示data object id,根据object id可以确定segment; FFF: 三位表示相对文件号;BBBBBB:六位表示data block number; RRR:三位表示row number,以此来确定唯一的行地址。