熟悉HDFS
(一)熟悉HDFS操作常用的Shell命令
(1)使用hadoop用户登录Linux系统,启动Hadoop(Hadoop的安装目录为“/usr/local/hadoop”),为hadoop用户在HDFS中创建用户目录“/user/Hadoop”。
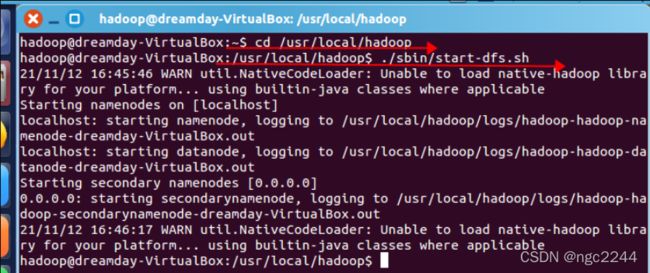
(2)接着在HDFS的目录“/user/hadoop”下,创建test文件夹,并查看文件列表。



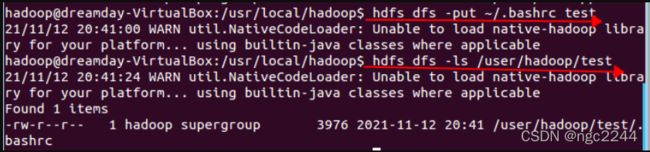
(3)将Linux系统本地的“~/.bashrc”文件上传到HDFS的test文件夹中,并查看test。

(4)将HDFS文件夹test复制到Linux系统本地文件系统的“/usr/local/hadoop”目录下。
(二)编程实现以下功能:
(1)向 HDFS 中上传任意文本文件,如果指定的文件在 HDFS 中已经存在,则由用户来
指定是追加到原有文件末尾还是覆盖原有的文件;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSAPi1{
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
/**
* 复制文件到指定路径
* 若路径已存在,则进行覆盖
*/
public static void copyFromLocalFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path localPath = new Path(localFilePath);
Path remotePath = new Path(remoteFilePath);
/* fs.copyFromLocalFile 第一个参数表示是否删除源文件,第二个参数表示是否覆盖 */
fs.copyFromLocalFile(false, true, localPath, remotePath);
fs.close();
}
/**
* 追加文件内容
*/
public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
/* 创建一个文件读入流 */
FileInputStream in = new FileInputStream(localFilePath);
/* 创建一个文件输出流,输出的内容将追加到文件末尾 */
FSDataOutputStream out = fs.append(remotePath);
/* 读写文件内容 */
byte[] data = new byte[1024];
int read = -1;
while ( (read = in.read(data)) > 0 ) {
out.write(data, 0, read);
}
out.close();
in.close();
fs.close();
}
/**
* 主函数
*/
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER");
conf.set("dfs.client.block.write.replace-datanode-on-failure.enable","true");
String localFilePath = "/home/hadoop/text.txt"; // 本地路径
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径
String choice = "append"; // 若文件存在则追加到文件末尾
//String choice = "overwrite"; // 若文件存在则覆盖
try {
/* 判断文件是否存在 */
boolean fileExists = false;
if (HDFSAPi1.test(conf, remoteFilePath)) {
fileExists = true;
System.out.println(remoteFilePath + " 已存在.");
} else {
System.out.println(remoteFilePath + " 不存在.");
}
/* 进行处理 */
if ( !fileExists) { // 文件不存在,则上传
HDFSAPi1.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已上传至 " + remoteFilePath);
} else if ( choice.equals("overwrite") ) { // 选择覆盖
HDFSAPi1.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已覆盖 " + remoteFilePath);
} else if ( choice.equals("append") ) { // 选择追加
HDFSAPi1.appendToFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已追加至 " + remoteFilePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}




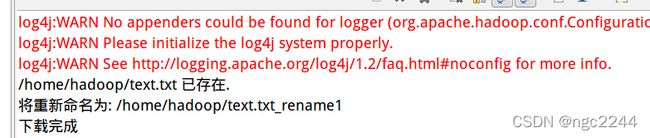
(2)从 HDFS 中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载
的文件重命名;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSAPi2 {
/**
* 下载文件到本地
* 判断本地路径是否已存在,若已存在,则自动进行重命名
*/
public static void copyToLocal(Configuration conf, String remoteFilePath, String localFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
File f = new File(localFilePath);
/* 如果文件名存在,自动重命名(在文件名后面加上 _0, _1 ...) */
if (f.exists()) {
System.out.println(localFilePath + " 已存在.");
localFilePath =localFilePath+"_rename1" ;
System.out.println("将重新命名为: " + localFilePath);
}
// 下载文件到本地
Path localPath = new Path(localFilePath);
fs.copyToLocalFile(remotePath, localPath);
fs.close();
}
/**
* 主函数
*/
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String localFilePath = "/home/hadoop/text.txt"; // 本地路径
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径
try {
HDFSAPi2.copyToLocal(conf, remoteFilePath, localFilePath);
System.out.println("下载完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
(3)将 HDFS 中指定文件的内容输出到终端中;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class HDFSFileRead {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");//给出文件系统的入口
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); //
FileSystem fs = FileSystem.get(conf);//前四行保留
Path file = new Path("text.txt");//当前路径下直接给文件名text.txt
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content=null;
while((content = d.readLine())!=null){
System.out.println(content);//一行一行读,读到没有为止
}
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}

(4)提供一个 HDFS 内的文件的路径,对该文件进行创建和删除操作。如果文件所在目
录不存在,则自动创建目录;
(5)删除 HDFS 中指定的文件;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSSetup {
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path)
throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
/**
* 创建目录
*/
public static boolean mkdir(Configuration conf, String remoteDir)
throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
boolean result = fs.mkdirs(dirPath);
fs.close();
return result;
}
/**
* . 创建文件
*/
public static void touchz(Configuration conf, String remoteFilePath)
throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataOutputStream outputStream = fs.create(remotePath);
outputStream.close();
fs.close();
}
/**
* 删除文件
*/
public static boolean rm(Configuration conf, String remoteFilePath)
throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
boolean result = fs.delete(remotePath, false);
fs.close();
return result;
}
/**
*
主函数
*/
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
String remoteFilePath = "/user/hadoop/mm/my.txt";// HDFS路径
String remoteDir = "/user/hadoop/mm"; // HDFS路径对应的目录
try {
/* 判断路径是否存在,存在则删除,否则进行创建 */
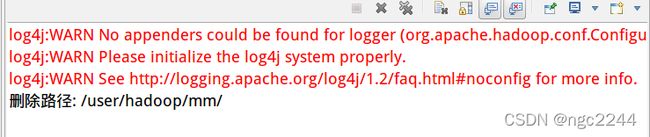
if (HDFSSetup.test(conf, remoteFilePath)) {
HDFSSetup.rm(conf, remoteFilePath); // 删除
System.out.println("删除路径: " + remoteFilePath);
} else {
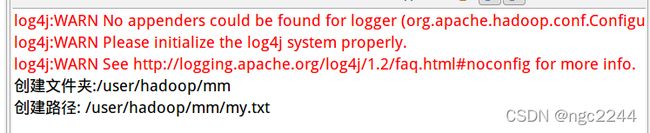
if (!HDFSSetup.test(conf, remoteDir)) {// 若目录不存在,则进行创建
HDFSSetup.mkdir(conf, remoteDir);
System.out.println("创建文件夹:" + remoteDir);
HDFSSetup.touchz(conf, remoteFilePath);
System.out.println("创建路径: " + remoteFilePath);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}

修改:
![]()
(三)编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInput
Stream”,要求如下:实现按行读取 HDFS 中指定文件的方法“readLine()”,如果读到文件末
尾,则返回空,否则返回文件一行的文本。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class MyFSDataInputStream extends FSDataInputStream {
MyFSDataInputStream(InputStream in)
{
super(in);
}
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");//给出文件系统的入口
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); //
FileSystem fs = FileSystem.get(conf);//前四行保留
Path file = new Path("text.txt");//当前路径下直接给文件名text.txt
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content;
while((content=d.readLine())!=null){
System.out.println(content);
}
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
