【改进YOLOv8】车道抛洒物检测系统:融合RT-DETR骨干网络HGNetv2
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
近年来,随着自动驾驶技术的快速发展,车辆安全问题引起了广泛关注。在道路上,车辆行驶过程中可能会遇到各种各样的抛洒物,如石块、玻璃碎片、轮胎碎片等。这些抛洒物不仅会对车辆自身造成损害,还会对其他车辆和行人的安全构成威胁。因此,开发一种高效准确的车道抛洒物检测系统对于提高道路安全具有重要意义。
目前,YOLOv8是一种广泛应用于目标检测领域的深度学习模型。它具有快速的检测速度和较高的准确率,但在车道抛洒物检测任务中仍然存在一些问题。首先,YOLOv8在处理小目标时存在较大的误检率和漏检率。其次,YOLOv8在处理遮挡目标时也存在一定的困难。因此,为了进一步提高车道抛洒物检测系统的性能,需要对YOLOv8进行改进。
为了解决上述问题,本研究提出了一种改进的车道抛洒物检测系统,该系统融合了RT-DETR骨干网络和HGNetv2。RT-DETR是一种新型的目标检测模型,它通过引入Transformer结构来提高目标检测的准确性和效率。而HGNetv2是一种高效的骨干网络,它可以提取更丰富的特征信息,从而进一步提高目标检测的性能。
本研究的主要贡献如下:
首先,通过融合RT-DETR骨干网络,可以有效提高车道抛洒物检测系统的准确性。RT-DETR的Transformer结构可以捕捉目标之间的长距离依赖关系,从而减少误检率和漏检率。同时,RT-DETR还可以自适应地调整目标的尺度和形状,从而更好地适应不同大小和形状的抛洒物。
其次,通过融合HGNetv2骨干网络,可以进一步提高车道抛洒物检测系统的性能。HGNetv2可以提取更丰富的特征信息,从而更好地区分抛洒物和背景。此外,HGNetv2还可以提高目标检测的速度和效率,从而实现实时的车道抛洒物检测。
最后,本研究还将对改进的车道抛洒物检测系统进行大量的实验和评估。通过与其他常用的目标检测模型进行比较,可以验证所提出的系统的有效性和优越性。同时,还将对系统的检测速度、准确率和鲁棒性进行评估,以进一步验证系统的性能。
总之,本研究旨在改进YOLOv8车道抛洒物检测系统,通过融合RT-DETR骨干网络和HGNetv2,提高系统的准确性和效率。这将为道路安全提供重要的技术支持,减少车辆事故和人员伤亡,具有重要的实际应用价值。
2.图片演示
3.视频演示
【改进YOLOv8】车道抛洒物检测系统:融合RT-DETR骨干网络HGNetv2_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集PSDatasets。
labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode='train', batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
assert mode in ['train', 'val']
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
self.model.nc = self.data['nc']
self.model.names = self.data['names']
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def label_loss_items(self, loss_items=None, prefix='train'):
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot)
def plot_metrics(self):
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
if __name__ == '__main__':
args = dict(model='./yolov8-RCSOSA.yaml', data='coco8.yaml', epochs=200)
trainer = DetectionTrainer(overrides=args)
trainer.train()
该程序文件是一个用于训练基于检测模型的程序。它使用Ultralytics YOLO库进行训练。
该文件首先导入了所需的库和模块,包括numpy、copy、ultralytics等。
然后定义了一个名为DetectionTrainer的类,该类继承自BaseTrainer类。DetectionTrainer类用于构建和训练检测模型。
该类中定义了一些方法,包括build_dataset、get_dataloader、preprocess_batch等。这些方法用于构建数据集、构建数据加载器、预处理数据等。
还定义了一些其他方法,如set_model_attributes、get_model、get_validator等,用于设置模型属性、获取模型、获取验证器等。
最后,在主函数中创建了一个DetectionTrainer对象,并调用其train方法进行训练。
整体来说,该程序文件是一个用于训练检测模型的程序,使用了Ultralytics YOLO库。
5.2 backbone\efficientViT.py
class EfficientViT_M0(nn.Module):
def __init__(self, num_classes=1000, img_size=224, patch_size=16, in_chans=3, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=False, drop_rate=0.0, attn_drop_rate=0.0, drop_path_rate=0.0):
super(EfficientViT_M0, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i])
for i in range(depth)])
self.norm = nn.LayerNorm(embed_dim)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
该程序文件是一个EfficientViT模型的架构定义文件。它定义了一系列EfficientViT模型的类,包括EfficientViT_M0、EfficientViT_M1、EfficientViT_M2、EfficientViT_M3、EfficientViT_M4和EfficientViT_M5。
该文件中还定义了一些辅助类和函数,如Conv2d_BN、replace_batchnorm、PatchMerging、Residual、FFN、CascadedGroupAttention和LocalWindowAttention等。
这些类和函数用于构建EfficientViT模型的不同组件,如卷积层、批归一化层、残差连接、注意力机制等。这些组件被用于构建EfficientViT模型的主体结构,并在前向传播过程中被调用。
总的来说,该程序文件定义了EfficientViT模型的架构和组件,并提供了相应的前向传播方法。
5.3 backbone\fasternet.py
class Partial_conv3(nn.Module):
def __init__(self, dim, n_div, forward):
super().__init__()
self.dim_conv3 = dim // n_div
self.dim_untouched = dim - self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x: Tensor) -> Tensor:
# only for inference
x = x.clone() # !!! Keep the original input intact for the residual connection later
x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])
return x
def forward_split_cat(self, x: Tensor) -> Tensor:
# for training/inference
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
return x
class MLPBlock(nn.Module):
def __init__(self, dim, n_div, mlp_ratio, drop_path, layer_scale_init_value, act_layer, norm_layer, pconv_fw_type):
super().__init__()
self.dim = dim
self.mlp_ratio = mlp_ratio
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.n_div = n_div
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.spatial_mixing = Partial_conv3(
dim,
n_div,
pconv_fw_type
)
if layer_scale_init_value > 0:
self.layer_scale = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.forward = self.forward_layer_scale
else:
self.forward = self.forward
def forward(self, x: Tensor) -> Tensor:
shortcut = x
x = self.spatial_mixing(x)
x = shortcut + self.drop_path(self.mlp(x))
return x
def forward_layer_scale(self, x: Tensor) -> Tensor:
shortcut = x
x = self.spatial_mixing(x)
x = shortcut + self.drop_path(
self.layer_scale.unsqueeze(-1).unsqueeze(-1) * self.mlp(x))
return x
class BasicStage(nn.Module):
def __init__(self, dim, depth, n_div, mlp_ratio, drop_path, layer_scale_init_value, norm_layer, act_layer, pconv_fw_type):
super().__init__()
blocks_list = [
MLPBlock(
dim=dim,
n_div=n_div,
mlp_ratio=mlp_ratio,
drop_path=drop_path[i],
layer_scale_init_value=layer_scale_init_value,
norm_layer=norm_layer,
act_layer=act_layer,
pconv_fw_type=pconv_fw_type
)
for i in range(depth)
]
self.blocks = nn.Sequential(*blocks_list)
def forward(self, x: Tensor) -> Tensor:
x = self.blocks(x)
return x
class PatchEmbed(nn.Module):
def __init__(self, patch_size, patch_stride, in_chans, embed_dim, norm_layer):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, bias=False)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
x = self.norm(self.proj(x))
return x
class PatchMerging(nn.Module):
def __init__(self, patch_size2, patch_stride2, dim, norm_layer):
super().__init__()
self.reduction = nn.Conv2d(dim, 2 * dim, kernel_size=patch_size2, stride=patch_stride2, bias=False)
if norm_layer is not None:
self.norm = norm_layer(2 * dim)
else:
self.norm = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
x = self.norm(self.reduction(x))
return x
class FasterNet(nn.Module):
def __init__(self, in_chans=3, num_classes=1000, embed_dim=96, depths=(1, 2, 8, 2), mlp_ratio=2., n_div=4, patch_size=4, patch_stride=4, patch_size2=2, patch_stride2=2, patch_norm=True, feature_dim=1280, drop_path_rate=0.1, layer_scale_init_value=0, norm_layer='BN', act_layer='RELU', init_cfg=None, pretrained=None, pconv_fw_type='split_cat', **kwargs):
super().__init__()
if norm_layer == 'BN':
norm_layer = nn.BatchNorm2d
else:
raise NotImplementedError
if act_layer == 'GELU':
act_layer = nn.GELU
elif act_layer == 'RELU':
act_layer = partial(nn.ReLU, inplace=True)
else:
raise NotImplementedError
self.num_stages = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_stages - 1))
self.mlp_ratio = mlp_ratio
self.depths = depths
# split image into non-overlapping patches
该程序文件是一个名为fasternet.py的Python程序文件,主要包含了一个名为FasterNet的神经网络模型类,以及一些辅助函数。
FasterNet类是一个神经网络模型,用于图像分类任务。它包含了多个基本模块BasicStage,每个基本模块由多个MLP块MLPBlock组成。每个MLP块包含了一个部分卷积层Partial_conv3和一个MLP层。模型还包含了图像分割和图像融合的模块PatchEmbed和PatchMerging。整个模型的结构是一个由多个基本模块和图像分割模块组成的串联结构。
该程序文件还包含了一些辅助函数,如update_weight用于更新模型的权重,fasternet_t0、fasternet_t1等函数用于创建不同配置的FasterNet模型。
在if __name__ == '__main__':的部分,程序创建了一个FasterNet模型对象,并对输入数据进行了前向传播,打印了模型的输出尺寸。
该程序文件还导入了一些其他的Python模块,如torch、yaml等,用于实现模型的训练和加载权重等功能。
5.4 backbone\revcol.py
class RevCol(nn.Module):
def __init__(self, kernel='C2f', channels=[32, 64, 96, 128], layers=[2, 3, 6, 3], num_subnet=5, save_memory=True) -> None:
super().__init__()
self.num_subnet = num_subnet
self.channels = channels
self.layers = layers
self.stem = Conv(3, channels[0], k=4, s=4, p=0)
for i in range(num_subnet):
first_col = True if i == 0 else False
self.add_module(f'subnet{str(i)}', SubNet(channels, layers, kernel, first_col, save_memory=save_memory))
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def forward(self, x):
c0, c1, c2, c3 = 0, 0, 0, 0
x = self.stem(x)
for i in range(self.num_subnet):
c0, c1, c2, c3 = getattr(self, f'subnet{str(i)}')(x, c0, c1, c2, c3)
return [c0, c1, c2, c3]
该程序文件名为backbone\revcol.py,是一个用于神经网络的反向传播的模块。该模块包含了一些函数和类,主要用于实现反向传播的过程。
该文件中的主要内容包括:
- 导入了一些必要的库和模块
- 定义了一些辅助函数,如获取GPU状态、设置设备状态、分离和梯度等
- 定义了一个
ReverseFunction类,用于实现反向传播的函数 - 定义了一些其他的类,如
Fusion、Level和SubNet,用于构建神经网络的不同层级和子网络 - 定义了一个
RevCol类,用于构建整个神经网络模型
该模块的主要功能是实现神经网络的反向传播过程,包括计算梯度、更新参数等操作。它可以作为一个模块被其他程序调用,用于训练和优化神经网络模型。
5.5 backbone\SwinTransformer.py
class Mlp(nn.Module):
""" Multilayer perceptron."""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk
该程序文件是一个用于构建Swin Transformer模型的Python文件。它包含了Swin Transformer模型的各个组件,如多层感知机(Mlp)、窗口注意力(WindowAttention)、Swin Transformer块(SwinTransformerBlock)、Patch Merging层(PatchMerging)和基本层(BasicLayer)等。
其中,Mlp是一个多层感知机模块,用于对输入进行线性变换和激活函数处理。
WindowAttention是一个基于窗口的多头自注意力模块,支持使用相对位置偏差。它将输入特征分割成窗口,并计算窗口内的注意力权重。
SwinTransformerBlock是Swin Transformer的基本模块,它包含了窗口注意力模块、残差连接和多层感知机模块。
PatchMerging是一个用于合并特征图的模块,它将输入特征图按照一定规则进行合并。
BasicLayer是一个用于构建Swin Transformer的基本层,它包含了多个SwinTransformerBlock模块。
该程序文件的主要功能是构建Swin Transformer模型的各个组件,并提供了相应的前向传播函数。
5.6 backbone\VanillaNet.py
class activation(nn.ReLU):
def __init__(self, dim, act_num=3, deploy=False):
super(activation, self).__init__()
self.deploy = deploy
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num*2 + 1, act_num*2 + 1))
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6)
self.dim = dim
self.act_num = act_num
weight_init.trunc_normal_(self.weight, std=.02)
def forward(self, x):
if self.deploy:
return torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, self.bias, padding=(self.act_num*2 + 1)//2, groups=self.dim)
else:
return self.bn(torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, padding=self.act_num
该程序文件名为backbone\VanillaNet.py,是一个使用PyTorch实现的神经网络模型。该模型是VanillaNet,用于图像分类任务。该模型包含了多个不同的网络结构,可以根据需要选择不同的模型进行训练和测试。
该程序文件中定义了以下类和函数:
- activation类:激活函数类,继承自nn.ReLU,包含了前向传播函数和参数初始化函数。
- Block类:网络块类,继承自nn.Module,包含了前向传播函数和参数初始化函数。
- VanillaNet类:VanillaNet模型类,继承自nn.Module,包含了前向传播函数和参数初始化函数。
- update_weight函数:用于更新模型权重的函数。
- vanillanet_5到vanillanet_13_x1_5_ada_pool函数:
6.系统整体结构
下表总结了每个文件的功能:
| 文件 | 功能 |
|---|---|
| train.py | 训练模型的主程序 |
| backbone\efficientViT.py | 实现EfficientViT模型的骨干网络 |
| backbone\fasternet.py | 实现Fasternet模型的骨干网络 |
| backbone\lsknet.py | 实现LSKNet模型的骨干网络 |
| backbone\repvit.py | 实现RepVIT模型的骨干网络 |
| backbone\revcol.py | 实现RevCol模型的骨干网络 |
| backbone\SwinTransformer.py | 实现Swin Transformer模型的骨干网络 |
| backbone\VanillaNet.py | 实现VanillaNet模型的骨干网络 |
| extra_modules\head.py | 实现模型的头部结构 |
| extra_modules\kernel_warehouse.py | 存储模型的卷积核 |
| extra_modules\orepa.py | 实现Orepa模块 |
| extra_modules\rep_block.py | 实现RepBlock模块 |
| extra_modules\RFAConv.py | 实现RFAConv模块 |
| models\common.py | 包含一些通用的模型函数 |
| models\experimental.py | 包含一些实验性的模型 |
| models\tf.py | 包含一些与TensorFlow相关的模型 |
| models\yolo.py | 实现YOLO模型 |
| ultralytics… | Ultralytics库的各个模块和功能 |
| utils… | 包含一些通用的工具函数和辅助功能 |
| utils\aws… | 与AWS相关的工具函数 |
| utils\flask_rest_api… | 实现Flask REST API的功能 |
| utils\loggers… | 实现不同日志记录器的功能 |
以上是对每个文件的简要概括,具体的功能和实现细节可能需要查看每个文件的具体代码来了解。
7.YOLOv8简介
YOLOv8是一种目标检测模型,是基于YOLO (You Only Look Once)系列算法发展而来的最新版本。它的核心思想是将目标检测任务转化为一个回归问题,通过单次前向传播即可直接预测出图像中的多个目标的位置和类别。
YOLOv8的网络结构采用了Darknet作为其主干网络,主要由卷积层和池化层构成。与之前的版本相比,YOLOv8在网络结构上进行了改进,引入了更多的卷积层和残差模块,以提高模型的准确性和鲁棒性。
YOLOv8采用了一种特征金字塔网络(Feature Pyramid Network,FPN)的结构,通过在不同层级上融合多尺度的特征信息,可以对不同尺度的目标进行有效的检测。此外,YOLOv8还引入了一种自适应感知域(Adaptive Anchors
的机制,通过自适应地学习目标的尺度和
长宽比,提高了模型对于不同尺度和形状目标的检测效果。
总体来说,YOLOv8结构模型综合了多个先进的目标检测技术,在保证检测速度的同时提升了检测精度和鲁棒性,被广泛应用于实时目标检测任务中。
yolov8网络模型结构图
YOLOv8 (You Only Look Once version 8)是一种目标检测算法,它在实时场景下可以快速准确地检测图像中的目标。
YOLOv8的网络模型结构基于Darknet框架,由一系列卷积层、池化层和全连接层组成。主要包含以下几个组件:
1.输入层:接收输入图像。
2.卷积层:使用不同尺寸的卷积核来提取图像特征。
3.残差块(Residual blocks):通过使用跳跃连接(skip connections)来解决梯度消失问题,使得网络更容易训练。
4.上采样层(Upsample layers):通过插值操作将特征图的尺寸放大,以便在不同尺度上进行目标检测。
5.池化层:用于减小特征图的尺寸,同时保留重要的特征。
6.1x1卷积层:用于降低通道数,减少网络参数量。
7.3x3卷积层:用于进—步提取和组合特征。
8.全连接层:用于最后的目标分类和定位。
YOLOv8的网络结构采用了多个不同尺度的特征图来检测不同大小的目标,从而提高了目标检测的准确性和多尺度性能。
请注意,YOLOv8网络模型结构图的具体细节可能因YOLO版本和实现方式而有所不同。
yolov8模型结构
YOLOv8模型是一种目标检测模型,其结构是基于YOLOv3模型进行改进的。模型结构可以分为主干网络和检测头两个部分。
主干网络是一种由Darknet-53构成的卷积神经网络。Darknet-53是一个经过多层卷积和残差连接构建起来的深度神经网络。它能够提取图像的特征信息,并将这些信息传递给检测头。
检测头是YOLOv8的关键部分,它负责在图像中定位和识别目标。检测头由一系列卷积层和全连接层组成。在每个检测头中,会生成一组锚框,并针对每个锚框预测目标的类别和位置信息。
YOLOv8模型使用了预训练的权重,其中在COCO数据集上进行了训练。这意味着该模型已经通过大规模数据集的学习,具有一定的目标检测能力。
8.RT-DETR骨干网络HGNetv2简介
RT-DETR横空出世
前几天被百度的RT-DETR刷屏,参考该博客提出的目标检测新范式对原始DETR的网络结构进行了调整和优化,以提高计算速度和减小模型大小。这包括使用更轻量级的基础网络和调整Transformer结构。并且,摒弃了nms处理的detr结构与传统的物体检测方法相比,不仅训练是端到端的,检测也能端到端,这意味着整个网络在训练过程中一起进行优化,推理过程不需要昂贵的后处理代价,这有助于提高模型的泛化能力和性能。
当然,人们对RT-DETR之所以产生浓厚的兴趣,我觉得大概率还是对YOLO系列审美疲劳了,就算是出到了YOLO10086,我还是只想用YOLOv5和YOLOv7的框架来魔改做业务。。
初识HGNet
看到RT-DETR的性能指标,发现指标最好的两个模型backbone都是用的HGNetv2,毫无疑问,和当时的picodet一样,骨干都是使用百度自家的网络。初识HGNet的时候,当时是参加了第四届百度网盘图像处理大赛,文档图像方向识别专题赛道,简单来说,就是使用分类网络对一些文档截图或者图片进行方向角度分类。
当时的方案并没有那么快定型,通常是打榜过程发现哪个网络性能好就使用哪个网络做魔改,而且木有显卡,只能蹭Ai Studio的平台,不过v100一天8小时的实验时间有点短,这也注定了大模型用不了。
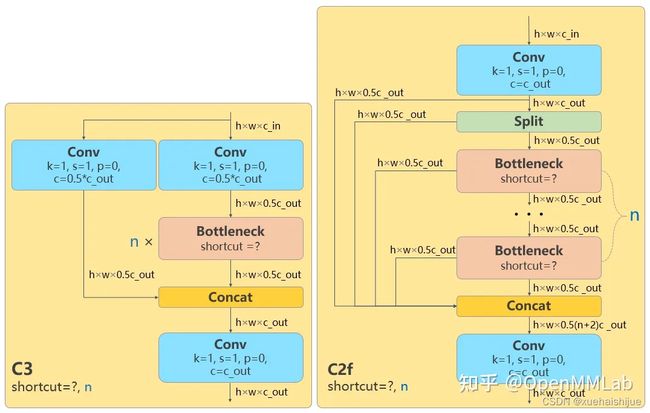
流水的模型,铁打的炼丹人,最后发现HGNet-tiny各方面指标都很符合我们的预期,后面就一直围绕它魔改。当然,比赛打榜是目的,学习才是享受过程,当时看到效果还可以,便开始折腾起了HGNet的网络架构,我们可以看到,PP-HGNet 针对 GPU 设备,对目前 GPU 友好的网络做了分析和归纳,尽可能多的使用 3x3 标准卷积(计算密度最高),PP-HGNet是由多个HG-Block组成,细节如下:
ConvBNAct是啥?简单聊一聊,就是Conv+BN+Act,CV Man应该最熟悉不过了:
class ConvBNAct(TheseusLayer):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride,
groups=1,
use_act=True):
super().__init__()
self.use_act = use_act
self.conv = Conv2D(
in_channels,
out_channels,
kernel_size,
stride,
padding=(kernel_size - 1) // 2,
groups=groups,
bias_attr=False)
self.bn = BatchNorm2D(
out_channels,
weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
if self.use_act:
self.act = ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.use_act:
x = self.act(x)
return x
且标准卷积的数量随层数深度增加而增多,从而得到一个有利于 GPU 推理的骨干网络,同样速度下,精度也超越其他 CNN ,性价比也优于ViT-base模型。
另外,我们可以看到:
PP-HGNet 的第一层由channel为96的Stem模块构成,目的是为了减少参数量和计算量。PP-HGNet
Tiny的整体结构由四个HG Stage构成,而每个HG Stage主要由包含大量标准卷积的HG Block构成。
PP-HGNet的第三到第五层使用了使用了可学习的下采样层(LDS Layer),该层group为输入通道数,可达到降参降计算量的作用,且Tiny模型仅包含三个LDS Layer,并不会对GPU的利用率造成较大影响.
PP-HGNet的激活函数为Relu,常数级操作可保证该模型在硬件上的推理速度。
9.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《【改进YOLOv8】车道抛洒物检测系统:融合RT-DETR骨干网络HGNetv2》
10.参考文献
[1]杨丹,戴芳.运动目标检测的ViBe算法改进[J].中国图象图形学报.2018,(12).
[2]石建盛.甘肃高速公路高清视频监控系统设计及其实现[J].甘肃科技.2017,(11).DOI:10.3969/j.issn.1000-0952.2017.11.029 .
[3]赵渊,彭济根,高义.基于SLIC超像素分割的图分割算法[J].工程数学学报.2016,(5).DOI:10.3969/j.issn.1005-3085.2016.05.001 .
[4]潘至尊,刘承祥,肖海俊.基于运动检测的目标跟踪算法研究[J].数字技术与应用.2014,(6).
[5]贾建英.浅谈视频图像序列运动目标的检测方法[J].信息通信.2014,(3).
[6]林韩辉.4G移动通信技术特征及应用分析[J].软件导刊.2014,(7).
[7]武瑛.形态学图像处理的应用[J].计算机与现代化.2013,(5).DOI:10.3969/j.issn.1006-2475.2013.05.021 .
[8]袁国武,陈志强,龚健,等.一种结合光流法与三帧差分法的运动目标检测算法[J].小型微型计算机系统.2013,(3).DOI:10.3969/j.issn.1000-1220.2013.03.047 .
[9]杜岳涛,张学智.视频图像序列中运动目标区域检测算法研究[J].计算机与数字工程.2012,(8).DOI:10.3969/j.issn.1672-9722.2012.08.036 .
[10]魏西.摄像机运动情况下的运动目标检测技术研究[J].科技信息.2011,(3).DOI:10.3969/j.issn.1001-9960.2011.03.030