机器学习——特征提取
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、简介
数据具有多种数据类型,除了数字化的信号数据(声音、图像等),还有大量符号化的文本。但是,机器学习模型无法处理符号化的文本,只能接收数值型和布尔型数据,需要对数据进行特征提取。特征提取又称特征抽取,是将任意数据(如字典、文本或图像)转换为机器学习的特征向量。
sklearn的feature_extraction模块用于特征提取,具体方法如下:
| 方法 | 说明 |
| feature_extraction.DictVectorizer | 将特征值映射列表转换为向量 |
| feature_extraction.FeatureHasher | 特征哈希 |
| feature_extraction.text | 文本特征抽取 |
| feature_extraction.image | 图像特征抽取 |
| feature_extraction.text.CountVectorizer | 将文本转换为每个词出现次数的向量 |
| feature_extraction.text.TfidfVectorizer | 将文本转换为TF-IDF值的向量 |
2、字典特征提取
当数据以字典这种数据结构存储时,可以使用sklearn提供的DictVectorizer实现特征提取,具体语法:
sklearn.feature_extraction.DictVectorizer(sparse = True)【参数说明】
- sprse = True 表示返回稀疏矩阵,只将矩阵中非零值按文职表示出来,不表示零值
示例:
from sklearn.feature_extraction import DictVectorizer
def dictvecl():
#定义一个字典列表,表示多个数据样本
data = [{'city': '上海', 'tem':100},
{'city': '北京', 'tem':60},
{'city': '深圳', 'tem':30}]
#转换器
DictTransform = DictVectorizer()
#调用fir_transform方法,传入字典,返回sparse矩阵
data_new = DictTransform.fit_transform(data)
print(DictTransform.get_feature_names_out())
print(data_new)
return None
if __name__ == '__main__':
dictvecl()【说明】
获取特征名:
旧版本:tf_feature_names = tf_vectorizer.get_feature_names()新版本:tf_feature_names = tf_vectorizer.get_feature_names_out()
3、文本特征提取
文本可以提取的特征如下:
- 字数。统计文本的字(单词)数。
- 非重复字数。统计文本中不重复的字(单词)数。
- 长度。文本占用的存储空间(包含空格、标点符号、字母等)。
- 停用词数。between,but、about、very等词的数。
- 标点符号数。文本中包含的标点符号数。
- 大写单词数。文本中包含的大写单词数。
- 标题式单词数。文本中标题式单词(首字母大写,其他字母小写的单词)数。
- 单词的平均长度。文本中单词长度的平均值。
Sklearn提供了 Count Vectorizer与 TfidfVectorizer两个特征提取方法。Count Vectorizer只考虑词在文本中出现的频率,适用于主题较多的数据集;而TfidfVectorizer 采用TF-IDF 模型,适用于主题较少的数据集。
当一个词在多个文档中出现的频率都很高时,该词具有较低的权重;当一个词在特定的文档中出现的频率很高,而在其他文档中出现的频率很低时,该词具有较高的权重,因为这个词很可能是该特定文档中独有的词,具有较好的类别区分能力,能较好地描述该文档。
3.1 CountVectorizer
关键词通常在文章中反复出现,通过统计文章中每个词的词频并排序,可以初步获取部分关键词。
sklearn 提供了CountVectorizer方法用于文本特征提取:
sklearn.feature_extraction.text.CountVectorizer(stop_words)【参数说明】stop_words:停用词表(可以自己创建)
示例:
from sklearn.feature_extraction.text import CountVectorizer
texts = ['orange banana aplple grape','banana apple apple','grape','orange apple']
#实例化一个转换器
cv = CountVectorizer()
#调用fit_transform
cv_fit = cv.fit_transform(texts)
print(cv.vocabulary_)
print(cv_fit.shape)
print(cv_fit)
print(cv_fit.toarray())【运行结果】

3.2 TfidfVectorizer
TF-IDF(Term Frequency - Inverse Document Frequency,词频与逆文档频率)模型是一种用于信息检索与数据挖掘的常用加权技术,是衡量一个词的重要程度的统计指标,用于评估词对于文件的重要程度。
TF-IDF综合考虑了词的稀有程度。在TF-IDF 计算方法中,一个词的重要程度正比于其在文档中出现的次数,并且反比于包含它的文档数。如果包含该词的文档越多,就说明它应用越广泛,越不能体现文档的特色;反之,如果包含该词的文档越少,就说明该词越具有类别区分能力。
IDF的计算步骤如下。
(1) 计算TF。
TF算法统计文本中某个词的出现次数(即词频),计算公式如下:
TF=某个词在单独文档中出现次数/单独文档总词数
(2)计算IDF。
IDF算法用于计算某词频的逆权重系数(即逆文档频率),计算公式:
IDF=log(总样本数/(包含该词的所有文档数+1)
(3)计算TF-IDF。
TF-IDF= TF*IDF
3.2.1计算示例:
一个文档的总词数是100个,“苹果”出现了3次,则“苹果”一词在该文档中的词频就是3/100=0.03。若“苹果”一词在1000个文档中出现过,而全部文档的总词数是10 000 000个,其逆文档频率就是lg(10 000 000/1000)=4。最终,TF-IDF的值就是0.03X4=0.12。
3.2.2算法示例
TF-IDF模型除了考量某一词在当前训练文本中出现的频率之外,同时关注包含该词的其他训练文本数。相比之下,训练文本的数量越多,TfidfVectorizer 就越有优势。
函数的语法如下:
TfidfVectorizer(stop_words, sublinear_tf, max_df)【参数说明】
- stop_words:停用词表。
- sublinear_tf:取值为True或 False,指定计算TF值采用的策略。
- max_df:文档频率阈值。
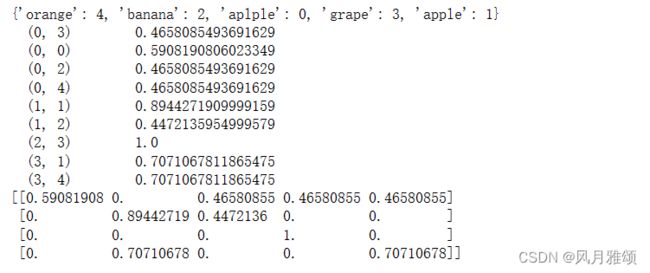
from sklearn.feature_extraction.text import TfidfVectorizer
texts = ['orange banana aplple grape','banana apple apple','grape','orange apple']
cv = TfidfVectorizer()
cv_fit = cv.fit_transform(texts)
print(cv.vocabulary_)
print(cv_fit)
print(cv_fit.toarray())【运行结果】