UI自动化测试-selenium元素定位
在使用Selenium和WebDriver进行UI自动化测试时,我们首先需要对元素定位,那么如何来定位元素呢?
HTML
在进行元素定位之前,我们要对html代码有所了解。

如上为百度首页的一段html代码,html文档有如下结构
- 由标签对组成 如
- 标签有各种属性,如id,name,class,type,value 就像人有各种属性,如身份证(id),姓名(name),职业(class)等
- 标签对之间有文本 如新闻
- 标签有层级关系 如div内嵌套div,嵌套input标签
那么如果把页面元素看成人的话,如何找到一个人呢?
我们可以根据这个人的属性如身份证号-id,姓名-name等找到这个人,也可以根据这个人的位置找到这个人,也可以根据这个人的相关属性如先找到这个人的兄弟姐妹父母再根据他们找到这个人。理解了这些,就可以来进行元素定位了。
页面元素查看
利用F12开发者工具,可以帮助我们定位元素。
打开页面,按F12在元素页面,点击左侧查看元素按钮,再点击一个元素,可以看到跟这个元素有关的信息。
可以看到百度一下这个按钮属性为
input为这个元素的标签,type,value,id,class都是这个元素的属性。
中间的输入框属性为

八种元素定位方式
元素定位方式一共有8种,它们都是采用driver.find_element或者driver.find_elements为前缀,然后跟上自己独特的关键字。
其中前者用来定位唯一的元素,后者用来定位一组元素,返回的是一个列表。
在八种元素定位方式中,最常用,能解决100%问题的,是xpath的定位方式。
id定位
HTML文档规定,每个元素的id是唯一的,通过元素的id属性来定位元素。
driver.find_element_by_id("kw")
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 通过元素的id属性来定位——id是唯一的
search=driver.find_element_by_id("kw")
search.send_keys("selenium")
name定位
通过元素的name属性来定位元素,name属性不是绝对唯一的(一个页面内可能存在多个元素的name属性是相同的)
如果name属性的值是唯一的,用find_element_by_name定位元素,返回值是一个值
driver.find_element_by_name("wd")
class定位
通过元素的class属性来定位元素,class属性不是绝对唯一的(一个页面内可能存在多个元素的class属性是相同的)
如果class属性的值s_ipt是唯一的,用find_element_by_class_name定位元素,返回值是一个值
driver.find_element_by_class_name("s_ipt")
如果class属性的值s_ipt不是唯一的,用find_elements_by_class_name定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表
search=driver.find_elements_by_class_name("s_ipt")
对于返回一组元素时,我们可以采用下标如search[1]来定位,但是一般不推荐这种方式。
tag定位
通过元素的标签名tag来定位元素,如div,input, 标签名不是绝对唯一的(一个页面内可能存在多个相同的标签名)
如果标签名是唯一的,用find_element_by_tag_name定位元素,返回值是一个值
driver.find_element_by_tag_name("input")
如果标签名不是唯一的,用find_elements_by_tag_name定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表
driver.find_elements_by_tag_name("input")
通过链接元素文本模糊匹配
对于有href属性的元素,我们可以根据元素的text(标签中间的文字)来匹配如:
新闻
driver.find_element_by_partial_link_text("新闻")
对于这种方法,只需要匹配text的部分内容即可,因为partial的意思就是部分。
通过链接元素文本精准匹配
如果文本内容是唯一的,用find_element_by_link_text定位元素,这种方法匹配text的全部内容。
driver.find_element_by_link_text("新闻")
xpath定位
这种方式是最常用的方法,可以定位到页面的每一个元素,所以必须掌握。
XPath 是一门在 XML 文档中查找信息的语言,XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。我们只需要知道,可以用Xpath来定位元素就可以了。
方法为
driver.find_element_by_xpath("xpath表达式")
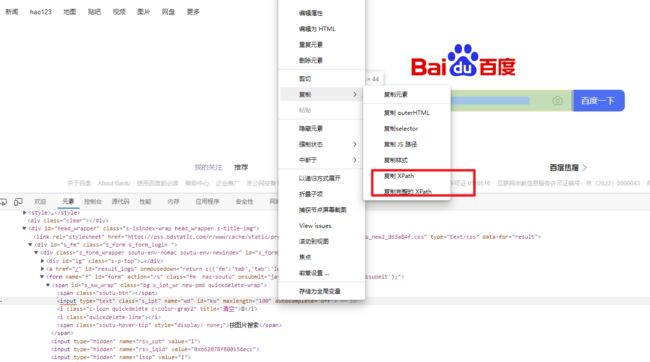
F12元素页面选中一行,点击右键,复制xpath,即可把元素的xpath提取出来,如
//*[@id="kw"] 解释:不管标签是什么,找id为kw的元素
点击复制完整xpath,也可以生成xpath表达式。
/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input
完整xpath从html文档根节点开始查找,这种查找方式效率非常低,不建议使用。
复制的方式很简单,但是结果不是我们想要的。没事儿,我们有更方便的方法来自己写xpath表达式。
xpath路径表达式的写法

这个表格总结了xpath路径的写法,这样可能还是看不明白,接下来会进行介绍。
检验xpath写的对不对
在介绍xpath写法之前,我们先来看看如何检验xpath写的对不对。
在F12元素页面,按ctrl+F,输入xpath回车,可以定位到元素,右侧显示定位到的元素个数。
如果为0,说明xpath写的有问题,没有找到元素。
为1,说明xpath写对了,唯一定位到了元素。
为多个,说明定位到了多个元素,xpath表达式还需要优化。

标签+元素属性
我们可以采用标签加元素属性的方式来写xpath表达式
以百度搜索输入框为例
我们可以通过标签+元素属性方式来定位
//标签名[@属性名称=值]
//input[@id='kw'] 解释:以相对路径查找标签input中id为kw的元素
当我们以//开头时,表示相对路径,任何一个元素都可以以这种方式开头查找。input为这个元素的标签名,用中括号括起,并@id这个属性,id的值为kw,用字符串表示。
我们也可以用name属性来写。
//input[@name='wd']
用class来写
//input[@class='s_ipt']
元素的任何一个属性,只要是唯一的,都可以写,这种写法,能解决大多数定位问题。
组合属性
如果单属性定位不到,可以组合属性
组合属性定位://标签名[@属性名称=值 and @属性名称=值 and @属性名称=值]
如
//input[@id='kw' and @name='wd' ] 解释:相对路径查找input标签中id为kw同时name为wd的元素
text精准定位
还记得text吗?在标签之间的文字就是text,我们可以用text来进行模糊匹配。
新闻
//a[text()='新闻'] 解释:相对路径查找a标签中text为新闻的元素
这种方法需要写上全部text内容字符串。
contains方法模糊定位
//a[contains(text(),'新闻')] 解释:相对路径查找a标签中text包含新闻的元素
contains意思为包含,即写在这里的text可以是部分内容,只要text包含新闻这两个字的元素,都会被找出来。
contains也可以用于属性如
//input[contains(@name,'wd')] 解释:相对路径查找input标签中name属性包含wd的元素
只要这个属性的name包含wd,就会被匹配上。
contains方法特别适合于动态属性的定位,即某些元素的属性值动态变化的元素。
除了contains,还可以用另外两种
starts-with 例子: //input[starts-with(@id,'ctrl')] 解释:匹配以 ctrl开始的属性值
ends-with 例子://input[ends-with(@id,'userName')] 解释:匹配以 userName 结尾的属性值
xpath方法说了这么多,你掌握了吗?看起来很复杂,其实写多了就会了。
CSS定位
学会了xpath,这种定位方法可以不学,但为了显示出我们定位方式的全面,还是简单介绍一下吧。
这种方法使用CSS 选择器定位元素
driver.find_element_by_css_selector('css表达式')
好了,具体CSS表达式怎么写,感兴趣的可以自己百度。
没有find_element_by_*?
当我学会了xpath,信心满满开始写代码,发现没有了find_element_by_*。
如下的代码提示里没有上面介绍的方法?我不会白学了吧?

其实Selenium 4.0已经不再支持find_elements_by_*方法,而是开始使用
driver.find_element()/driver.find_elements() 解释:前者定位一个元素,后者定位一组元素
道理是一样的,只是这种方法,我们需要导入一个By包
from selenium.webdriver.common.by import By
继续输入,可以发现,还是我们介绍的那些定位方式,只不过写法稍微变了,需要给这个方法传入两个参数。
driver.find_element(By.ID,'kw')
driver.find_element(By.XPATH,"//input[contains(@name,'wd')]")

看来还是没有白学。
总结
好了,本文介绍了html文档的结构,元素定位的八种方式,如何在F12开发者工具查看元素,校验xpath。相信学习了这些方法,你一定可以定位到任何想要定位的元素了!
欢迎交流,拜拜。