使用 KubeRay 和 Kueue 在 Kubernetes 中托管 Ray 工作负载
在 KubeCon CN 2023 的「 Open AI + 数据 | Open AI + Data」专题中,火山引擎软件工程师胡元哲分享了《使用 KubeRay 和 Kueue 在 Kubernetes 中托管 Ray 工作负载|Sailing Ray workloads with KubeRay and Kueue in Kubernetes议题。以下是本次演讲的文字稿。
本文将从 Ray 为何得到 AI 研究者们的青睐,在字节如何使用 KubeRay 来托管 Ray 应用,Kueue 如何管理和调度 RayJob 三个方面进行介绍。
什么是 Ray
Ray 起源于 UC Berkeley 的 RISElab 实验室,其定位是一个通用的分布式编程框架,能帮助用户将自己的程序快速分布式化。Ray Core 提供了 low level 的分布式语法,如 remote func、remote class,上层 Ray AIR 提供了 AI 场景的相关库。
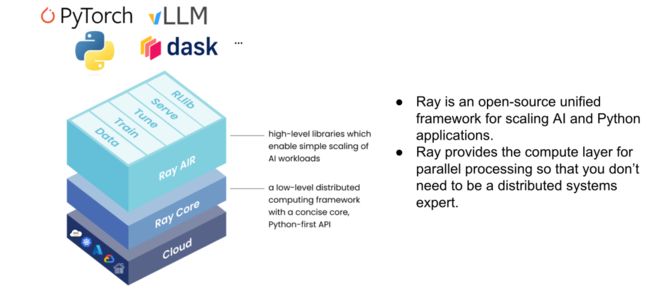
Ray 的GitHub repo 如今已有 27K star,其发起者也成立了 Anyscale 公司来管理开源社区以及商业化。在 Anyscale 刚举办的 Ray Summit 2023 上,相关数据显示 Ray 已被 OpenAI/Uber/Amazon/字节跳动/蚂蚁金服等众多企业所使用。基于 Ray,Anyscale 也推出了自己的 LLM 相关商业化产品,并以成本和易用性等方向作为卖点。
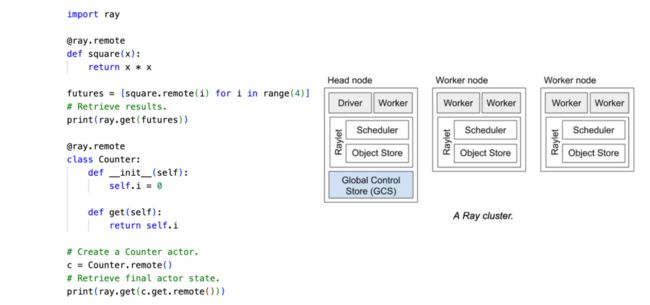
上图右侧展示了 Ray cluster 的基本架构:
-
每个框是一个 Ray 的节点,节点是虚拟的概念,比如在 K8s 集群上,每个节点就对应一个 pod。
-
所有的节点中,有一个节点的角色不同,就是最左边的 head 节点,它可以理解成整个 Ray cluster 的调度中心,head 节点上有 GCS 存储集群节点的信息、作业信息、actor 的信息等等,head 节点上还有 dashboard 等组件。
-
除了 head 节点以外的都是 worker 节点,worker 节点主要是承载具体的工作负载。
-
每个节点上有一个 raylet 守护进程,raylet 也是一个本地调度器,负责 task 的调度以及 worker 的管理,同时 raylet 中还有 object store 组件,负责节点之间 object 的传输,整个 Ray cluster 中的所有 object store 构成一个大的分布式内存。
为了提供简洁的分布式编程体验,Ray Core 内部做了非常多工作,比如 actor 调度和 object 的生命周期管理等,上图左侧展示了如何使用 Ray Core 编写一个简单的分布式程序,square 函数和 Counter 类通过 Ray 的语法糖,变成了一些在远程运行的对象,其计算过程会被异步调用并存储在 object store 中,最后通过 ray.get 来获取到本地。

除了 Ray Core 提供的底层分布式能力,其上层 Ray AI Runtime(Ray AIR)针对算法场景也实现了一系列工具:
-
ray.data 集合了数据读写、流式处理、shuffle 等功能,给离线推理、数据预处理等场景提供了灵活 API 和异构的调度功能
-
ray.train 和 ray.tune 可以将 xgboost、pytorch 等训练代码快速改写成基于 Ray 的分布式训练应用
-
ray.serve 是一套在线服务的部署调用框架,支持复杂模型编排,可以灵活扩缩实例
可以说,Ray 的生态打破了过去 AI 工程中每个模块都是固定范式的传统——
在过去,提到数据处理,大家会想到 Spark;提到训练,会想到 Torch DDP、MPI;提到推理,会想到 deployment、service;而 Ray 能够给予你足够的自由度和想象力,可以将 AI 的 pipeline 糅合在一个框架甚至一串代码中实现,其强大异构调度能力以及友好的上手调试感受。这也是很多 AI 从业者越来越多地选择 Ray 的原因。
字节跳动 KubeRay+Ray 应用实践
KubeRay 简介
KubeRay 是由字节跳动技术团队牵头,由 AnyScale、蚂蚁金服、微软等公司共同参与建设的开源 Ray 部署集成工具集,目前已成为在 Kubernetes 集群上部署 Ray 应用的事实标准。
如果不使用 KubeRay,直接在物理机来托管 Ray 集群会有什么问题呢?

首先,head 和 worker 需要直接通过 ip 和 port 连接,集群的拉起、节点的增删会比较复杂,可恢复能力也较弱。其次,RayJob submit 脚本提交作业的模式在大规模生产环境下很难管理,除此之外,也没有 K8s 生态可以给予你的监控、报警、Ingress、HPA/VPA 等能力。

KubeRay 采用了经典的 operator 设计,提供了 RayCluster,RayJob,RayService 这三个 CRD:
-
RayCluster:负责 Ray 集群的搭建
-
RayJob:负责提交作业到一个伴生集群中,并同步状态
-
RaySevice:负责将 RayServe 应用快速部署到云原生环境中
在 operator 实现中,cluster 的 controller 更侧重集群的拉起、恢复、与 Ray autoscaler 配合等,Job Service 的 controller 侧重作业提交和状态更新,并且它俩分别对应了离线和在线两个典型场景。
除此之外 KubeRay 还提供了 APIServer 等 client 库来负责 CRD 的增删改差,方便对接上层平台。
RayCluster
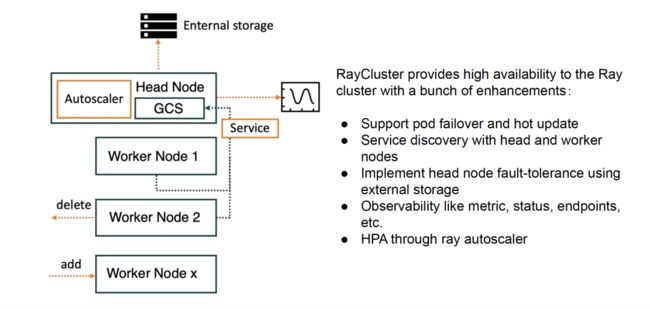
如果说 Ray 本身提供了 actor 重启、task 重试等能力来增强代码的高可用性,那么 KubeRay 就是真正让 Ray 在集群维度成为真正高可用的应用。
首先 RayCluster CRD 提供了 pod 的恢复能力以及集群粒度的热更新,可以非常方便地管理集群;其次 head 和 worker 通过 service 进行连接,通过将集群 metadata 挂到远程存储中,配合 service 可以做到无感知的 head 节点恢复,同时 Ray autoscaler 可以实现基于集群负载动态伸缩集群规模,有效缩减成本。当然 Cluster CRD 还提供了 metric, 集群状态等的透出。
RayJob

RayJob 是生产环境管理 Ray 作业的解决方案,支持批式调度器,创建伴生 Ray 集群或者选择已有的 Ray 集群,提交作业,并更新作业状态,最后删除 Ray 集群。在字节跳动,我们优化了作业状态机转移,增加了超时、等待节点数等功能。
RayService

RayService 把 CRD 中的 serve 配置部署到集群上,并通过 service 把 serve agent 的端口透出,实现了 Ray serve 的云原生化。它支持热更新 Serve 配置,通过 pending cluster 的滚动更新实现 Serve 无感知迁移。
Ray 在字节跳动的托管

在字节跳动,我们给用户提供了丰富的 Ray 相关生态。首先站内所有的 Ray 集群都由 KubeRay 去管理,我们基于开源版本做了相关适配和增强来支持大规模作业提交以及一些额外特性;我们在平台层支持用户创建常驻 Ray 集群用来调试作业,也支持 single-job 形式让平台托管创建 RayJob;除此之外还提供了平台鉴权、historyserver、notebook 等周围的能力。
如今字节跳动内部的相关业务包含了图计算、离线推理、大模型、并行计算等方向,涵盖了离线、在线等场景。
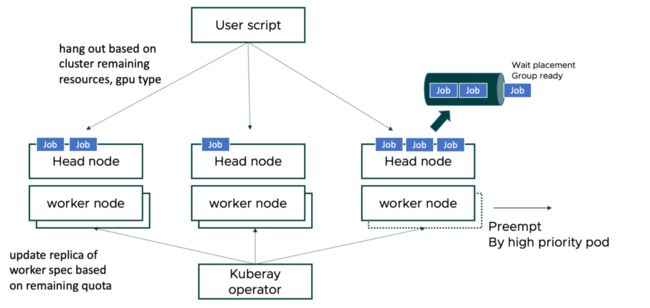
上图展示了站内某业务在使用常驻集群的场景,其需求是希望尽量利用不同 K8s 集群上的低优 spot 资源提供给用户用于运行、调试作业,同时希望大多数作业感知不到外界资源的抖动。
我们的方案是在每个 K8s 集群中创建一个大资源量的低优 pod 组成的 Ray 集群,operator 层面会基于每天 quota 的规律性浮动,并配合 Ray autoscaler 主动调整集群规模,尽量减少被 K8s 去主动驱逐 pod 的情况。
同时在上层,用户的脚本会感知每个大集群的剩余资源量决定分发到哪个集群去执行。每个集群内部我们实现了一个简单的排队功能,收到作业请求后先将作业放入 dashboard 内部的队列中,通过 placement group 来实现资源 gang 调度,确保作业需要的 GPU、CPU 资源到位后才开始真正运行作业。

在用户结束调试之后,可以通过平台来托管创建 RayJob CR,KubeRay 会负责集群拉起、作业提交、结束销毁。作业运行过程中,Ray 集群的重要信息会以 event 的形式 dump 到远程存储,我们仿照了 spark history server 的设计思路,用户在作业运行结束之后可以通过 Ray UI 界面来直接查看历史的作业的日志、metric 等信息。
场景案例
场景一:图计算

在图计算场景,我们使用 Ray Core 来改造字节跳动内部的图计算引擎,每个图算子通过 Ray Actor 拉起,这些算子会基于初始化的 rank 利用 MPI 进行通信。通过 Ray 的分布式能力和 KubeRay 的编排能力,可以实现端到端的容错,如果 worker 挂掉,可以再次被拉起,从 Pmem 或者 SSD 存储中恢复 checkpoint 信息。
场景二:大规模离线推理

如图所示,上述作业同时包含数据读取处理和模型推理,同时需要消耗大量计算资源做分布式计算。相比在线推理,离线推理对延迟要求不高,但是对吞吐和资源利用率要求很高。我们使用 Ray dataset 的流式推理能力来处理这个场景,是因为相比 Spark,Ray 的编程更加灵活,同时将处理和推理放在异构 actor 并 pipeline,可以做流水线并行、模型并行等操作。我们还增加了 actor pool 扩缩、端到端容错的一些优化。
这些场景都已在 Anyscale 发表过博客,有兴趣可以查看:
-
www.anyscale.com/blog/how-bytedance-scales-offline-inference-with-multi-modal-llms-to-200TB-data
-
www.anyscale.com/blog/7-must-attend-ray-summit-sessions-rl-powered-traffic-control-infra-less-ml
Kueue 如何管理/调度 RayJob
随着作业规模的增大,如何有限资源下调度不同优先级的作业,让大家都能稳定有序去使用 GPU 等资源是一个非常重要的问题。除了字节跳动所给出的一些经验,在开源社区侧,另一位分享人殷纳(Kante Yin)也介绍了如何使用 Kueue 这样一个作业调度器去管理 RayJob 来解决这些问题。
作业管理和调度框架 Kueue

Kueue 是去年由 K8s 社区发起的作业管理和调度框架,提供作业层面的队列调度,支持入队优先级、抢占、资源配额等能力。相比其它拥有队列调度能力的开源组件,Kueue 从设计上希望更多复用 K8s 原生的调度能力,尽量不重复造轮子。Kueue 已经原生支持了 BatchJob、RayJob、TFJob 等作业类型。

从 Kueue 的架构来看,ResourceFalvor 提供了节点的抽象,它通过 nodeLabel 的方式与具体的 node 进行绑定。ClusterQueue 是资源池的抽象,定义这个集群总资源量,ClusterQueue 中存在多个 localQueue,它们之间的资源会共享。一个作业会被提交到一个具体的 localQueue 进行调度。不同 clusterQueue 可以通过 Cohort 的机制共享资源。
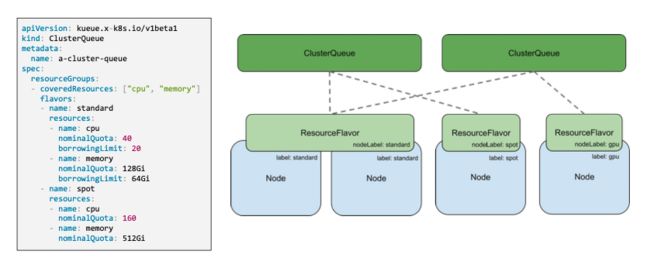

对于管理员,需要创建 ResouceFlavor、ClusterQueue、LocalQueue 来定义资源和机器之间的划分关系,以及资源池中的 quota 分配。

用户提交作业,需要指定自己作业所属于的 localQueue,job 在进入 Kueue 中会进入一个挂起状态,排队过程基于 quota,优先级等信息满足需求后放行,如果总当前资源不够,也有可能触发集群规模的 autoscale 机制。

KubeCon 活动现场还展示了相关 Demo:两个优先级不同的 queue 中,随着优先级和 quota 的变化,来触发多个 RayJob 的抢占和恢复流程。
分享人简介
胡元哲,火山引擎批式计算团队软件工程师,主要负责字节站内外 Ray、KubeRay 相关生态建设
殷纳,DaoCloud 高级软件工程师,Kubernetes SIG-Scheduling Maintainer & Kueue Approver