import torch
import torch.nn as nn
from torchvision import datasets, models, transforms
from torchsummary import summary
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import time
import os
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
device(type='cuda')
batch_size = 256
num_epochs = 30
image_transforms = {
'train': transforms.Compose([transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])]),
'valid':transforms.Compose([transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])]),
'test':transforms.Compose([transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
}
dataset = './Datasets/'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'valid')
test_directory = os.path.join(dataset, 'test')
data = {
'train':datasets.ImageFolder(root=train_directory,
transform=image_transforms['train']),
'valid':datasets.ImageFolder(root=valid_directory,
transform=image_transforms['valid']),
'test': datasets.ImageFolder(root=test_directory,
transform=image_transforms['test'])
}
train_data_loader = torch.utils.data.DataLoader(data['train'],
batch_size=batch_size,
shuffle=True)
valid_data_loader = torch.utils.data.DataLoader(data['valid'],
batch_size=batch_size,
shuffle=True)
test_data_loader = torch.utils.data.DataLoader(data['test'],
batch_size=batch_size,
shuffle=False)
resnet50 = models.resnet50(pretrained=True).to(device)
print(resnet50)
/home/wsl_ubuntu/anaconda3/envs/xy_trans/lib/python3.8/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/wsl_ubuntu/anaconda3/envs/xy_trans/lib/python3.8/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
for param in resnet50.parameters():
param.requires_grad = False
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, len(os.listdir(valid_directory))),
nn.LogSoftmax(dim=1))
resnet50 = resnet50.to(device)
criterion = nn.NLLLoss()
optimizer = torch.optim.Adam(resnet50.parameters())
def train_and_validate(model, loss_criterion, optimizer, epochs=25):
"""
Function used to train and validate.
Parameters:
:param model: Model to train and validate.
:param loss_criterion: Loss Criterion to minimize.
:param optimizer: Optimizer for computing gradients.
:param epochs: Number of epochs (default=25)
"""
history = []
best_loss = 100000.0
best_epoch = None
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for _, (inputs, labels) in enumerate(train_data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
_, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for _, (inputs, labels) in enumerate(valid_data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_criterion(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
_, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
if valid_loss < best_loss:
best_loss = valid_loss
best_epoch = epoch
avg_train_loss = train_loss/len(data['train'])
avg_train_acc = train_acc/len(data['train'])
avg_valid_loss = valid_loss/len(data['valid'])
avg_valid_acc = valid_acc/len(data['valid'])
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
epoch_end = time.time()
print("Epoch : {:03d}, Training: Loss - {:.4f}, Accuracy - {:.4f}%, \n\t\tValidation : Loss - {:.4f}, Accuracy - {:.4f}%, Time: {:.4f}s".format(epoch, avg_train_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start))
torch.save(model, dataset+'_model_'+str(epoch)+'.pt')
return model, history, best_epoch
summary(resnet50, input_size=(3, 224, 224), batch_size=batch_size, device='cuda')
=================================================================
Layer (type:depth-idx) Param #
=================================================================
├─Conv2d: 1-1 (9,408)
├─BatchNorm2d: 1-2 (128)
├─ReLU: 1-3 --
├─MaxPool2d: 1-4 --
├─Sequential: 1-5 --
| └─Bottleneck: 2-1 --
| | └─Conv2d: 3-1 (4,096)
| | └─BatchNorm2d: 3-2 (128)
| | └─Conv2d: 3-3 (36,864)
| | └─BatchNorm2d: 3-4 (128)
| | └─Conv2d: 3-5 (16,384)
| | └─BatchNorm2d: 3-6 (512)
| | └─ReLU: 3-7 --
| | └─Sequential: 3-8 (16,896)
| └─Bottleneck: 2-2 --
| | └─Conv2d: 3-9 (16,384)
| | └─BatchNorm2d: 3-10 (128)
| | └─Conv2d: 3-11 (36,864)
| | └─BatchNorm2d: 3-12 (128)
| | └─Conv2d: 3-13 (16,384)
| | └─BatchNorm2d: 3-14 (512)
| | └─ReLU: 3-15 --
| └─Bottleneck: 2-3 --
| | └─Conv2d: 3-16 (16,384)
| | └─BatchNorm2d: 3-17 (128)
| | └─Conv2d: 3-18 (36,864)
| | └─BatchNorm2d: 3-19 (128)
| | └─Conv2d: 3-20 (16,384)
| | └─BatchNorm2d: 3-21 (512)
| | └─ReLU: 3-22 --
├─Sequential: 1-6 --
| └─Bottleneck: 2-4 --
| | └─Conv2d: 3-23 (32,768)
| | └─BatchNorm2d: 3-24 (256)
| | └─Conv2d: 3-25 (147,456)
| | └─BatchNorm2d: 3-26 (256)
| | └─Conv2d: 3-27 (65,536)
| | └─BatchNorm2d: 3-28 (1,024)
| | └─ReLU: 3-29 --
| | └─Sequential: 3-30 (132,096)
| └─Bottleneck: 2-5 --
| | └─Conv2d: 3-31 (65,536)
| | └─BatchNorm2d: 3-32 (256)
| | └─Conv2d: 3-33 (147,456)
| | └─BatchNorm2d: 3-34 (256)
| | └─Conv2d: 3-35 (65,536)
| | └─BatchNorm2d: 3-36 (1,024)
| | └─ReLU: 3-37 --
| └─Bottleneck: 2-6 --
| | └─Conv2d: 3-38 (65,536)
| | └─BatchNorm2d: 3-39 (256)
| | └─Conv2d: 3-40 (147,456)
| | └─BatchNorm2d: 3-41 (256)
| | └─Conv2d: 3-42 (65,536)
| | └─BatchNorm2d: 3-43 (1,024)
| | └─ReLU: 3-44 --
| └─Bottleneck: 2-7 --
| | └─Conv2d: 3-45 (65,536)
| | └─BatchNorm2d: 3-46 (256)
| | └─Conv2d: 3-47 (147,456)
| | └─BatchNorm2d: 3-48 (256)
| | └─Conv2d: 3-49 (65,536)
| | └─BatchNorm2d: 3-50 (1,024)
| | └─ReLU: 3-51 --
├─Sequential: 1-7 --
| └─Bottleneck: 2-8 --
| | └─Conv2d: 3-52 (131,072)
| | └─BatchNorm2d: 3-53 (512)
| | └─Conv2d: 3-54 (589,824)
| | └─BatchNorm2d: 3-55 (512)
| | └─Conv2d: 3-56 (262,144)
| | └─BatchNorm2d: 3-57 (2,048)
| | └─ReLU: 3-58 --
| | └─Sequential: 3-59 (526,336)
| └─Bottleneck: 2-9 --
| | └─Conv2d: 3-60 (262,144)
| | └─BatchNorm2d: 3-61 (512)
| | └─Conv2d: 3-62 (589,824)
| | └─BatchNorm2d: 3-63 (512)
| | └─Conv2d: 3-64 (262,144)
| | └─BatchNorm2d: 3-65 (2,048)
| | └─ReLU: 3-66 --
| └─Bottleneck: 2-10 --
| | └─Conv2d: 3-67 (262,144)
| | └─BatchNorm2d: 3-68 (512)
| | └─Conv2d: 3-69 (589,824)
| | └─BatchNorm2d: 3-70 (512)
| | └─Conv2d: 3-71 (262,144)
| | └─BatchNorm2d: 3-72 (2,048)
| | └─ReLU: 3-73 --
| └─Bottleneck: 2-11 --
| | └─Conv2d: 3-74 (262,144)
| | └─BatchNorm2d: 3-75 (512)
| | └─Conv2d: 3-76 (589,824)
| | └─BatchNorm2d: 3-77 (512)
| | └─Conv2d: 3-78 (262,144)
| | └─BatchNorm2d: 3-79 (2,048)
| | └─ReLU: 3-80 --
| └─Bottleneck: 2-12 --
| | └─Conv2d: 3-81 (262,144)
| | └─BatchNorm2d: 3-82 (512)
| | └─Conv2d: 3-83 (589,824)
| | └─BatchNorm2d: 3-84 (512)
| | └─Conv2d: 3-85 (262,144)
| | └─BatchNorm2d: 3-86 (2,048)
| | └─ReLU: 3-87 --
| └─Bottleneck: 2-13 --
| | └─Conv2d: 3-88 (262,144)
| | └─BatchNorm2d: 3-89 (512)
| | └─Conv2d: 3-90 (589,824)
| | └─BatchNorm2d: 3-91 (512)
| | └─Conv2d: 3-92 (262,144)
| | └─BatchNorm2d: 3-93 (2,048)
| | └─ReLU: 3-94 --
├─Sequential: 1-8 --
| └─Bottleneck: 2-14 --
| | └─Conv2d: 3-95 (524,288)
| | └─BatchNorm2d: 3-96 (1,024)
| | └─Conv2d: 3-97 (2,359,296)
| | └─BatchNorm2d: 3-98 (1,024)
| | └─Conv2d: 3-99 (1,048,576)
| | └─BatchNorm2d: 3-100 (4,096)
| | └─ReLU: 3-101 --
| | └─Sequential: 3-102 (2,101,248)
| └─Bottleneck: 2-15 --
| | └─Conv2d: 3-103 (1,048,576)
| | └─BatchNorm2d: 3-104 (1,024)
| | └─Conv2d: 3-105 (2,359,296)
| | └─BatchNorm2d: 3-106 (1,024)
| | └─Conv2d: 3-107 (1,048,576)
| | └─BatchNorm2d: 3-108 (4,096)
| | └─ReLU: 3-109 --
| └─Bottleneck: 2-16 --
| | └─Conv2d: 3-110 (1,048,576)
| | └─BatchNorm2d: 3-111 (1,024)
| | └─Conv2d: 3-112 (2,359,296)
| | └─BatchNorm2d: 3-113 (1,024)
| | └─Conv2d: 3-114 (1,048,576)
| | └─BatchNorm2d: 3-115 (4,096)
| | └─ReLU: 3-116 --
├─AdaptiveAvgPool2d: 1-9 --
├─Sequential: 1-10 --
| └─Linear: 2-17 524,544
| └─ReLU: 2-18 --
| └─Dropout: 2-19 --
| └─Linear: 2-20 2,570
| └─LogSoftmax: 2-21 --
=================================================================
Total params: 24,035,146
Trainable params: 527,114
Non-trainable params: 23,508,032
=================================================================
trained_model, history, best_epoch = train_and_validate(resnet50, criterion, optimizer, num_epochs)
torch.save(history, dataset+'_history.pt')
Epoch: 1/30
Epoch : 000, Training: Loss - 2.1844, Accuracy - 21.0000%,
Validation : Loss - 1.4458, Accuracy - 87.0000%, Time: 23.0077s
Epoch: 2/30
Epoch : 001, Training: Loss - 1.4131, Accuracy - 71.6667%,
Validation : Loss - 0.8001, Accuracy - 85.0000%, Time: 11.8903s
Epoch: 3/30
Epoch : 002, Training: Loss - 0.8666, Accuracy - 87.5000%,
Validation : Loss - 0.4689, Accuracy - 97.0000%, Time: 12.4398s
Epoch: 4/30
Epoch : 003, Training: Loss - 0.5742, Accuracy - 88.1667%,
Validation : Loss - 0.3205, Accuracy - 96.0000%, Time: 11.9200s
Epoch: 5/30
Epoch : 004, Training: Loss - 0.3776, Accuracy - 93.1667%,
Validation : Loss - 0.2615, Accuracy - 97.0000%, Time: 11.8079s
Epoch: 6/30
Epoch : 005, Training: Loss - 0.2893, Accuracy - 94.1667%,
Validation : Loss - 0.2209, Accuracy - 95.0000%, Time: 11.7730s
Epoch: 7/30
Epoch : 006, Training: Loss - 0.2247, Accuracy - 95.0000%,
Validation : Loss - 0.2052, Accuracy - 96.0000%, Time: 11.8106s
Epoch: 8/30
Epoch : 007, Training: Loss - 0.1790, Accuracy - 96.3333%,
Validation : Loss - 0.1859, Accuracy - 95.0000%, Time: 11.8970s
Epoch: 9/30
Epoch : 008, Training: Loss - 0.1688, Accuracy - 96.6667%,
Validation : Loss - 0.1819, Accuracy - 96.0000%, Time: 11.7606s
Epoch: 10/30
Epoch : 009, Training: Loss - 0.1302, Accuracy - 97.3333%,
Validation : Loss - 0.1788, Accuracy - 94.0000%, Time: 11.7755s
Epoch: 11/30
Epoch : 010, Training: Loss - 0.1205, Accuracy - 97.0000%,
Validation : Loss - 0.1410, Accuracy - 98.0000%, Time: 11.6803s
Epoch: 12/30
Epoch : 011, Training: Loss - 0.1158, Accuracy - 97.3333%,
Validation : Loss - 0.1378, Accuracy - 98.0000%, Time: 11.6497s
Epoch: 13/30
Epoch : 012, Training: Loss - 0.0967, Accuracy - 98.0000%,
Validation : Loss - 0.1727, Accuracy - 96.0000%, Time: 11.7946s
Epoch: 14/30
Epoch : 013, Training: Loss - 0.0874, Accuracy - 98.1667%,
Validation : Loss - 0.1780, Accuracy - 95.0000%, Time: 11.9912s
Epoch: 15/30
Epoch : 014, Training: Loss - 0.0901, Accuracy - 97.8333%,
Validation : Loss - 0.1570, Accuracy - 96.0000%, Time: 12.9568s
Epoch: 16/30
Epoch : 015, Training: Loss - 0.0746, Accuracy - 98.1667%,
Validation : Loss - 0.1415, Accuracy - 96.0000%, Time: 12.2158s
Epoch: 17/30
Epoch : 016, Training: Loss - 0.0719, Accuracy - 98.3333%,
Validation : Loss - 0.1419, Accuracy - 95.0000%, Time: 12.5166s
Epoch: 18/30
Epoch : 017, Training: Loss - 0.0780, Accuracy - 98.0000%,
Validation : Loss - 0.1261, Accuracy - 98.0000%, Time: 12.3080s
Epoch: 19/30
Epoch : 018, Training: Loss - 0.0710, Accuracy - 98.1667%,
Validation : Loss - 0.1370, Accuracy - 97.0000%, Time: 11.9036s
Epoch: 20/30
Epoch : 019, Training: Loss - 0.0686, Accuracy - 98.3333%,
Validation : Loss - 0.1563, Accuracy - 97.0000%, Time: 11.8692s
Epoch: 21/30
Epoch : 020, Training: Loss - 0.0649, Accuracy - 98.8333%,
Validation : Loss - 0.1606, Accuracy - 96.0000%, Time: 12.0231s
Epoch: 22/30
Epoch : 021, Training: Loss - 0.0528, Accuracy - 99.0000%,
Validation : Loss - 0.1435, Accuracy - 96.0000%, Time: 11.9158s
Epoch: 23/30
Epoch : 022, Training: Loss - 0.0606, Accuracy - 98.1667%,
Validation : Loss - 0.1376, Accuracy - 97.0000%, Time: 11.8283s
Epoch: 24/30
Epoch : 023, Training: Loss - 0.0606, Accuracy - 98.8333%,
Validation : Loss - 0.1445, Accuracy - 96.0000%, Time: 11.7824s
Epoch: 25/30
Epoch : 024, Training: Loss - 0.0530, Accuracy - 99.1667%,
Validation : Loss - 0.1682, Accuracy - 94.0000%, Time: 11.7249s
Epoch: 26/30
Epoch : 025, Training: Loss - 0.0528, Accuracy - 98.8333%,
Validation : Loss - 0.1614, Accuracy - 93.0000%, Time: 12.2925s
Epoch: 27/30
Epoch : 026, Training: Loss - 0.0583, Accuracy - 98.6667%,
Validation : Loss - 0.1518, Accuracy - 94.0000%, Time: 12.1458s
Epoch: 28/30
Epoch : 027, Training: Loss - 0.0407, Accuracy - 98.8333%,
Validation : Loss - 0.1408, Accuracy - 96.0000%, Time: 11.9303s
Epoch: 29/30
Epoch : 028, Training: Loss - 0.0671, Accuracy - 98.5000%,
Validation : Loss - 0.1508, Accuracy - 96.0000%, Time: 11.9089s
Epoch: 30/30
Epoch : 029, Training: Loss - 0.0443, Accuracy - 98.8333%,
Validation : Loss - 0.1763, Accuracy - 95.0000%, Time: 12.5318s
history = np.array(history)
plt.plot(history[:, 0], color='red', marker='o')
plt.plot(history[:, 1], color='blue', marker='x')
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0,1)
plt.savefig(dataset+'_loss_curve.png')
plt.show()
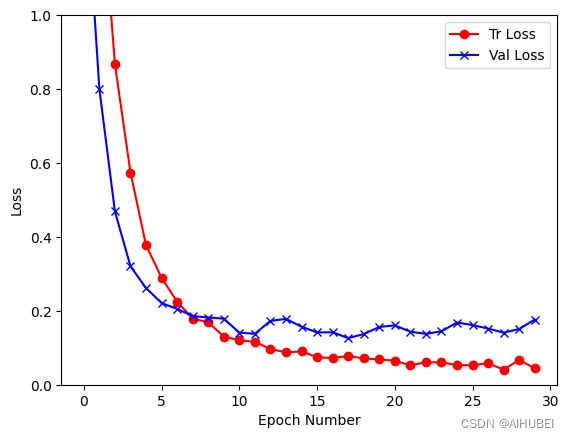
history = np.array(history)
plt.plot(history[:, 2], color='red', marker='o')
plt.plot(history[:, -1], color='blue', marker='x')
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0,1)
plt.savefig(dataset+'_loss_curve.png')
plt.show()
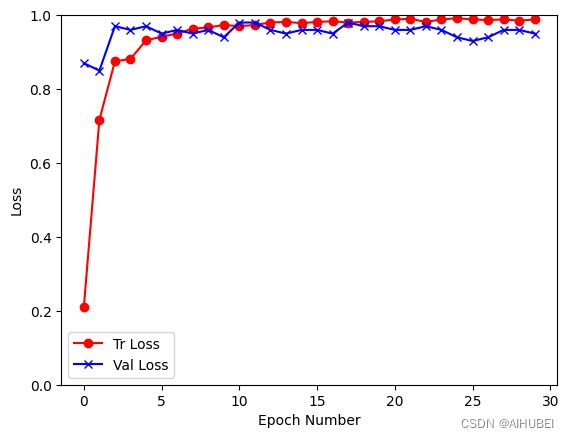
def computeTestSetAccuracy(model, loss_criterion):
'''
Function to compute the accuracy on the test set
Parameters
:param model: Model to test
:param loss_criterion: Loss Criterion to minimize
'''
test_acc = 0.0
test_loss = 0.0
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(test_data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_criterion(outputs, labels)
test_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
test_acc += acc.item() * inputs.size(0)
print("Test Batch number: {:03d}, Test: Loss: {:.4f}, Accuracy: {:.4f}".format(j, loss.item(), acc.item()))
avg_test_loss = test_loss/len(data['test'])
avg_test_acc = test_acc/len(data['test'])
print("Test accuracy : " + str(avg_test_acc))
idx_to_class = {v: k for k, v in data['train'].class_to_idx.items()}
print(idx_to_class)
{0: 'bear', 1: 'chimp', 2: 'giraffe', 3: 'gorilla', 4: 'llama', 5: 'ostrich', 6: 'porcupine', 7: 'skunk', 8: 'triceratops', 9: 'zebra'}
def predict(model, test_image_name):
'''
Function to predict the class of a single test image
Parameters
:param model: Model to test
:param test_image_name: Test image
'''
transform = image_transforms['test']
test_image = Image.open(test_image_name)
plt.imshow(test_image)
test_image_tensor = transform(test_image)
if torch.cuda.is_available():
test_image_tensor = test_image_tensor.view(1, 3, 224, 224).cuda()
else:
test_image_tensor = test_image_tensor.view(1, 3, 224, 224)
with torch.no_grad():
model.eval()
out = model(test_image_tensor)
ps = torch.exp(out)
topk, topclass = ps.topk(3, dim=1)
cls = idx_to_class[topclass.cpu().numpy()[0][0]]
score = topk.cpu().numpy()[0][0]
for i in range(3):
print("Predcition", i+1, ":", idx_to_class[topclass.cpu().numpy()[0][i]], ", Score: ", topk.cpu().numpy()[0][i])
model = torch.load("./Datasets/_model_{}.pt".format(best_epoch))
predict(model, './Datasets/skunk-3716043_1280.jpg')
Predcition 1 : skunk , Score: 0.99803644
Predcition 2 : porcupine , Score: 0.001755606
Predcition 3 : bear , Score: 8.1849976e-05
