MySQL数据库基础
0. 数据库介绍
0.1 关于数据库
数据结构:实现数据增删改查的具体方式
数据库:是一类管理数据的软件,实现数据库的软件内部就用到了很多数据结构,数据库这类软件主要是能够“管理数据”(对数据进行保存,且能够支持对数据的增删改查)。
数据库存储介质: 磁盘和内存
0.2 数据库分类
数据库大体可以分为关系型数据库 和 非关系型数据库
1、关系型数据库(RDBMS):
是指采用了关系模型来组织数据的数据库。 简单来说,关系模型指的就是二维表格模型,而一个 关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。(这样的数据库都是按照“表格”的形式来组织数据的,其中每一个表格的每一行,每一列都有着不同的含义。)
基于标准的SQL,只是内部一些实现有区别。常用的关系型数据库如:
1. Oracle:甲骨文产品,适合大型项目,适用于做复杂的业务逻辑,如ERP、OA等企业信息系 统。收费。
2. MySQL:属于甲骨文,不适合做复杂的业务。开源免费,使用表的结构来组织数据;
3. SQL Server:微软的产品,安装部署在windows server上,适用于中大型项目。收费。
2、非关系型数据库: (往往按照“键值对”,或文档的方式来组织的,且文档对于“要求”没有表格那么严重。)
不规定基于SQL实现。现在更多是指NoSQL数据库,如:
1. 基于键值对(Key-Value):如 memcached、redis
2. 基于文档型:如 mongodb
3. 基于列族:如 hbase
4. 基于图型:如 neo4j
作用:实际开发中一个复杂的网站或系统,往往背后会有很多的“存储介质”,很可能是关系型数据库和非关系型数据库一同搭配使用的;
3、关系型数据库与非关系型数据库的区别详细情况如下图所示:
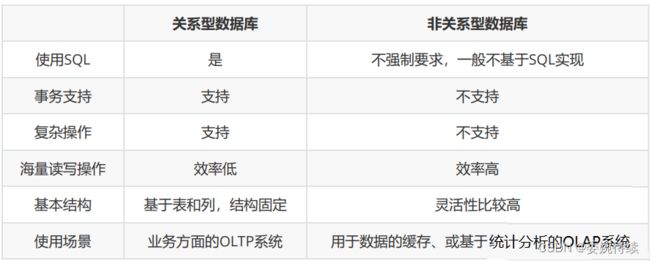
注:OLTP(On-Line Transaction Processing)是指联机事务处理,OLAP(On-Line Analytical Processing)是指联机分析处理。
注:我们接下来的操作都是基于mysql数据库上进行的;
0.3 细说mysql
Mysql:是一个“客户端-服务器结构的程序。二者可以在同一个主机上运行,也可以在不同主机上运行。
0.3.1 关于c\s结构
1、c/s结构:
主动发起通信的一方,称为“客户端”;被动接受通信的一方,称为“服务器”
客户端c:client,客户端给服务器发送的数据,称为请求,request
服务器s:sever, 服务器给客户端返回的数据,身为响应,response
客户端程序和服务器之间,数据交互的方式,最主要的就是通过“网络”。
2、服务器的特点:
- 被动的一方
- 一个服务器一般来说能给很多的客户端提供服务。
- 服务器一般会7*24小时运行。(永不停歇)
0.3.2 mysql安装后续
Mysql安装好之后,代表着安装了mysql客户端和服务器(客户端和服务器都在一个电脑上);
1、关于查看客户端:
以上两个都是客户端,点击进入到窗口后,输入密码,当显示下图截图是,则服务器连接成功。
2、关于查看mysql服务器连接
服务器程序:一般是不带界面的,对于windows来说,往往是可以在服务窗口中可以看到的,如上图所示;


数据库服务器是mysql的本体;而mysql客户端只是一个和用户交互的界面,只是让用户能够通过客户端,向服务器发送指令,即指挥服务器进行一系列操作。
1. 数据库的操作
我们着重学习使用mysql编程语言来进行操作指令;
1.1 显示当前的数据库
SHOW DATABASES;

上图的数据库,有的是系统自带的(维护系统内部的相关信息),有的是我们创建的。
1.2 创建数据库
1、详细语法如下:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
语法说明:
大写的表示关键字
[] 是可选项
CHARACTER SET: 指定数据库采用的字符集
COLLATE: 指定数据库字符集的校验规则
2、操作实例:
eg:create database mydream;
//创建一个mydream数据库;
//说明:当我们如上图所示创建mydream数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ ci
//如果我们要创建的mydream数据库如果存在的话,当前不会被创建;如果不存在的话,就会创建一个默认字符集为utf8的数据库;

关于字符集的若干知识点:
字符集::是计算机存储的是二进制编码数据;
编码:是用数字表示字符.
Q:问一个汉字在计算机里,需要用几个字节来保存?
A:现在常用的中文编码方式主要有两种:
(1).gbk: windows简体中文版默认使用的字符编码,一个汉语占用两个字节.
(2).utf8是一种更加通用的编码方式,一个utf8字符可能是n个字节,若用来表示汉字,一般是三个字节.
(3)Gbk,utf8,Unicode三者对于同一个汉字,会有三种不同的数字表示,且char使用unicode没有问题,但是string就无法使用unicode,java string默认使用的是utf8;
当使用多个汉字用unicode进行传输时,由于多个unicode一串凑在一起后,就会出现区分不出来的问题,所以会造成一种误差。Utf8就是为了解决unicode出现的问题而出现的。
eg:
创建一个使用utf8mb4字符集的mydream01数据库,如果有则不创建,mysql语言如下:
CREATE DATABASE IF NOT EXISTSmydream01CHARACTER SET utf8mb4说明:
MySQL的utf8编码不是真正的utf8,没有包含某些复杂的中文字符。
MySQL真正的utf8是使用utf8mb4,故此建议大家都使用utf8mb4
数据库创建成功示意图:

1.3 使用数据库
use 数据库名;
//我们在接下来进行表操作之前一定要先执行该操作来选择我们的那一个数据库;
1.4 删除数据库库
DROP DATABASE 数据库名;
说明:数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除
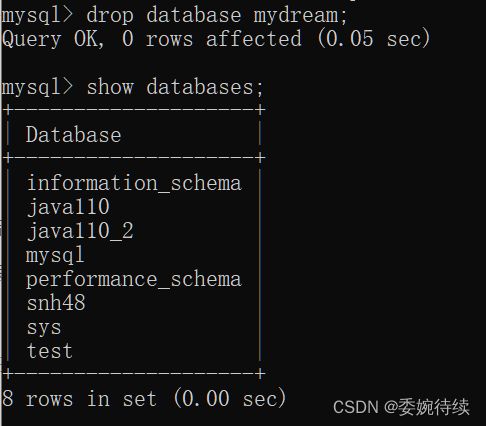
eg:drop database mydream;
结果如下:
//一旦删除了该数据,该数据可能就没了,因为无法恢复。
2.常用数据类型
2.1 数值类型
具体参照下图:

2.2 字符串类型

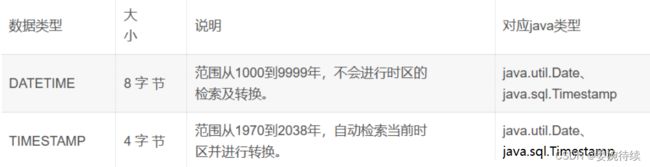
2.3 日期类型
3. 表的操作
需要操作数据库中的表时,需要先使用该数据库:
3.1 查看表结构
desc 表名;
//一个表里面有那些列,列的名字和类型
eg:
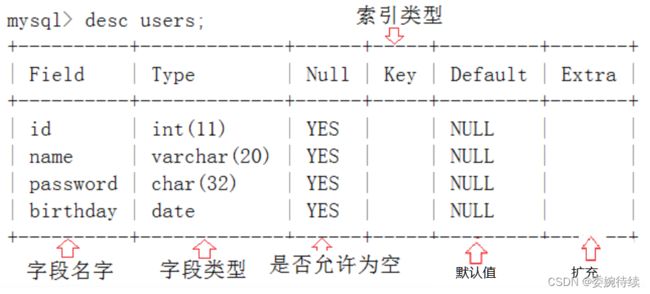
Null:在sql中表示的含义,就是这个单元格里面啥都没有,空着的。
3.2 创建表
create table 表名 (列名 类型,列名 类型,列名 类型,列名 类型......);
//创建表的时候,必须描述出表包含那些列,每一列的类型,每一列的名字->关系型数据库的基本要求
1、首先要选中我们要操作的数据库,如果没有进行库操作,直接进行创建表操作,结果如下:

没有选中database,即没有选中数据结构。
2、正确的创建表的操作:

此时成功的创建了一个chengyuan表;
结果展示:

3.3 查看当前库里的表
操作指令:show tables;
//表示查看当前选中的库里面的表的相关信息;
结果展示:

3.4 删除表
操作指令:drop table 表名;
//删除表可能引起的后果比删除数据库更大,所以对于删除操作要谨慎使用;
操作及结果展示:

4. 番外
4.1 关于数据库和表
1、Mysql适用硬盘来存储数据。
2、Mysql存储数据的组织方式:
2.1 数据库database:逻辑上的数据集合,一个mysql服务器上可以有很多个这样的数据集合。(实际开发中,会把一些有关联的数据,放到一起,就构成了数据集合)
2.2 数据表(table):一个数据库中,还能存储不同的数据,每组数据都使用数据表来存储,相当于表格。 一个表里有很多行,(row)每一行都是一条记录/(数据),每一行又包含很多列,每一列称为一个“字段”(field)每一行也有很多列。一般来说关系型数据库的结构都是这样的。
ps:本次的内容就到这里了,如果感兴趣的话就请一件三连哦!!!