spring data jpa+springboot
spring data jpa+springboot
spring data jpa 真的真的很方便,添加依赖后自带restful风格接口!
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-restartifactId>
dependency>

JPA使用详解
一文读懂spring data jpa
文章目录
- spring data jpa+springboot
-
- 入门简介:
- springboot整合jpa
-
- 1.新建项目
- 2.配置
- 3.创建实体类
- 4.创建dao层
- 5.测试(自带方法)
-
- 5.1增
- 5.2 查
- 5.3 删
- 5.4 分页查询
- 自定义jpa操作
-
-
- 1.自定义方法
- 2.自己写sql来自定义操作
- 自定义更新操作
-
入门简介:

@Entity
作用:指定当前类是实体类。
@Table
作用:指定实体类和表之间的对应关系。
属性:
name:指定数据库表的名称
@Id
作用:指定当前字段是主键。
@GeneratedValue
作用:指定主键的生成方式。。
属性:
strategy :指定主键生成策略。
@Column
作用:指定实体类属性和数据库表之间的对应关系
属性:
name:指定数据库表的列名称。
unique:是否唯一
nullable:是否可以为空
inserttable:是否可以插入
updateable:是否可以更新
columnDefinition: 定义建表时创建此列的DDL
secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字搭建开发环境[重点]
springboot整合jpa
1.新建项目
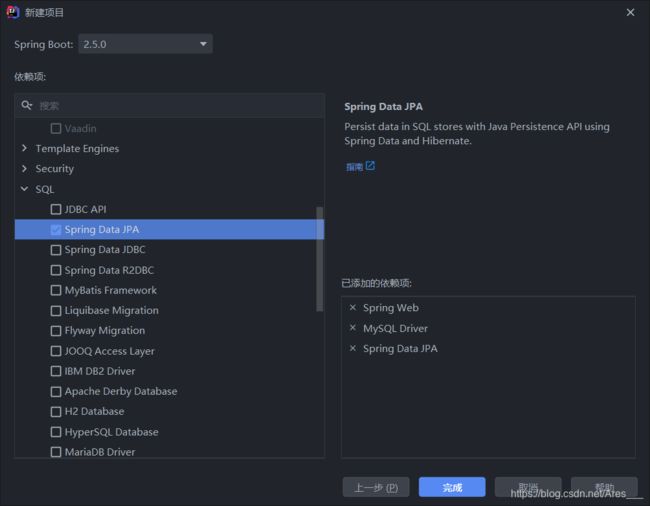
2.配置
#配置数据库
spring.datasource.url=jdbc:mysql://localhost:3306/wangze
spring.datasource.username=root
spring.datasource.password=123456
#配置jpa
#1.jpa数据库
spring.jpa.database=mysql
#2.在控制台打印sql
spring.jpa.show-sql=true
#3.jpa数据库平台
spring.jpa.database-platform=mysql
#4.当对象改变更新表
spring.jpa.hibernate.ddl-auto=update
#5.指定方言!!!重要!!!
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
#.....
3.创建实体类
package com.example.jpademo.model;
import javax.persistence.*;
/**
* @author: 王泽
* 用@entity标注的类必须要有主键@id
*/
@Entity(name = "t_book") //标记为实体类并且在数据库中创建的表叫t_book
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) //自动生成主键
private long id;
@Column(name = "bookname") //可以配置一系列数据库配置
private String name;
private String author;
//省略setget
set,get
}
这时候就可以发现表已经创建,并且控制台打印了sql语句
Hibernate: create table t_book (id bigint not null auto_increment, author varchar(255), bookname varchar(255), primary key (id)) engine=InnoDB
4.创建dao层
package com.example.jpademo.dao;
import com.example.jpademo.model.Book;
import org.springframework.data.jpa.repository.JpaRepository;
public interface BookDao extends JpaRepository<Book, Long> {
}
5.测试(自带方法)
5.1增
@Autowired
BookDao bookDao;
@Test
void contextLoads() {
Book book = new Book();
book.setName("三国演义");
book.setAuthor("罗贯中");
bookDao.save(book);
}
结果:
Hibernate: insert into t_book (author, bookname) values (?, ?)

5.2 查
//findall查所有
@Test
void test1(){
final List<Book> list = bookDao.findAll();
System.out.println(list);
}
//运行结果:
Hibernate: select book0_.id as id1_0_, book0_.author as author2_0_, book0_.bookname as bookname3_0_ from t_book book0_
[Book{id=1, name='三国演义', author='罗贯中'}]
//根据id查询
@Test
void test02(){
final Optional<Book> byId = bookDao.findById(2L);
System.out.println(byId);
}
//运行结果:
Hibernate: select book0_.id as id1_0_0_, book0_.author as author2_0_0_, book0_.bookname as bookname3_0_0_ from t_book book0_ where book0_.id=?
Optional[Book{id=2, name='红楼梦', author='曹雪芹'}]
5.3 删
//删除id为1的book
@Test
void test03(){
bookDao.deleteById(1L);
}
//运行结果
Hibernate: select book0_.id as id1_0_0_, book0_.author as author2_0_0_, book0_.bookname as bookname3_0_0_ from t_book book0_ where book0_.id=?
Hibernate: delete from t_book where id=?

5.4 分页查询
使用jpa分页查询非常方便!!
先增加些数据
INSERT INTO t_book(author, bookname) VALUES('罗贯中','三国演义'),('吴承恩','西游记'),('施耐庵','水浒传'),('鲁迅','狂人日记');
分页测试:
@Test
void test04(){
PageRequest pageRequest = PageRequest.of(1, 3);
Page<Book> page = bookDao.findAll(pageRequest);//返回book对象,不要选错
System.out.println("总记录数:"+page.getTotalElements());
System.out.println("总页数"+page.getTotalPages());
System.out.println("查到的数据"+page.getContent());
System.out.println("每页记录数"+page.getSize());
System.out.println("....还有好多参数可以自己来测试");
}
//结果
Hibernate: select count(book0_.id) as col_0_0_ from t_book book0_
总记录数:9
总页数3
查到的数据[Book{id=5, name='水浒传', author='施耐庵'}, Book{id=6, name='狂人日记', author='鲁迅'}, Book{id=7, name='三国演义', author='罗贯中'}]
每页记录数3
自定义jpa操作
上面我们用的都是自带的方法,可能不能满足我们的需求
解决方案:1.不写sql自定义方法 2.写sql
1.自定义方法
注意:我们必须按照jpa的命名规范来定义方法
开发者可以在接口中自己声明相关的方法,只需要方法名称符合规范即可,在Spring Data中,只要按照既定的规范命名方法,Spring Data Jpa就知道你想干嘛,这样就不用写SQL了,那么规范是什么呢?参考下图:

public interface BookDao extends JpaRepository<Book, Long> {
//根据author查询book
List<Book> getBookByAuthorEquals(String author);
}
测试类:
@Test
void test05(){
System.out.println(bookDao.getBookByAuthorEquals("鲁迅"));
}
结果:
Hibernate: select book0_.id as id1_0_, book0_.author as author2_0_, book0_.bookname as bookname3_0_ from t_book book0_ where book0_.author=?
[Book{id=6, name='狂人日记', author='鲁迅'}, Book{id=10, name='呐喊', author='鲁迅'}]
2.自己写sql来自定义操作
因为有命名规范的要求,还是会有操作不能完成,这时候我们可以自定义sql来完成需求!
//查id最大的book
@Query(nativeQuery = true,value = "select * from t_book where id=(select max(id)from t_book)") //是否使用原生sql
Book maxIdBook();
@Test
void test06(){
System.out.println(bookDao.maxIdBook());
}
结果:
Hibernate: select * from t_book where id=(select max(id)from t_book)
Book{id=10, name='呐喊', author='鲁迅'}
自定义更新操作
自定义需要处理事务
//更新
@Query("update t_book set bookname=:name where id=:id")
@Modifying //支持dml语言
void updataBookById(String name,Long id);
处理事务:service中
@Service
public class BookService {
@Autowired
BookDao bookDao;
@Transactional
public void updataBookById(String name,Long id){
bookDao.updataBookById(name, id);
}
}
测试:
@Autowired
BookService bookService;
@Test
void test07(){
bookService.updataBookById("王泽",5L);
}
![]()
spring data jpa 还有很多用法,想了解的建议结合源码分析