Stable Diffusion学习指南【模型篇】
模型作为机器学习后的结晶,可以说是对绘图画面影响最大的因素之一,一款好的模型即使不写提示词,出的图都会比绞尽脑汁编写咒语出的图更精美。但当我们兴致勃勃的下载了一堆模型后,往往会被一堆看不懂的文件后缀给乱花了眼,为什么模型要划分这么多类型、不同模型间有什么区别、新手如何判断一款模型的好坏?
今天我将带你深入学习Stable Diffusion模型的类型、差异以及使用技巧,同时也能帮助你建立对开源模型的基础认知框架,全篇没有干货都是感情,快来看看吧~
Stable Diffusion学习指南系列文章:
01 Stable Diffusion学习指南【初识篇】
02 Stable Diffusion学习指南【安装篇】
03 Stable Diffusion学习指南【文生图篇】
模型的概念
先来看看模型在Stable Diffusion中到底是什么概念?在维基百科中对模型的定义非常简单:用一个较为简单的东西来代表另一个东西。换句话说,模型代表的是对某一种事物的抽象表达。
在AIGC领域,研发人员为了让机器表现出智能,使用机器学习的方式让计算机从数据中汲取知识,并按照人类所期望的方向执行各种任务。对于AI绘画而言,我们通过对算法程序进行训练,让机器来学习各类图片的信息特征,而在训练后沉淀下来的文件包,我们就将它称之为模型。用一句话来总结,模型就是经过训练学习后得到的程序文件。
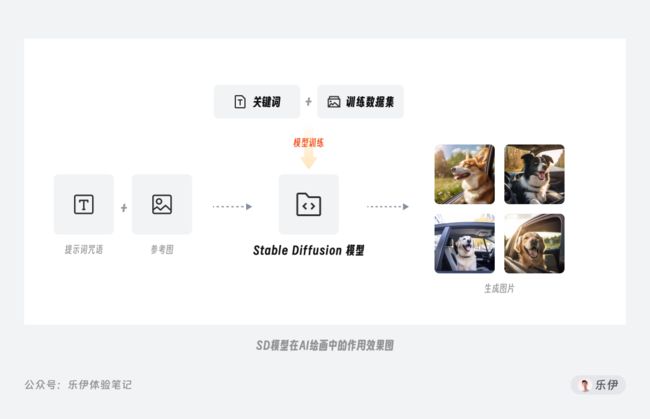
和我们此前使用的资料数据库完全不同,模型中储存的不是一张张可视的原始图片,而是将图像特征解析后的代码,因此模型更像是一个储存了图片信息的超级大脑,它会根据我们所提供的提示内容进行预测,自动提取对应的碎片信息进行重组,最后输出成一张图片。当然,模型的实际运行原理要比这复杂的多,但作为使用者我们无需深入学习复杂的技术算法,了解其大概概念即可。
重新认识下官方模型
在之前的文章里,我为大家简单介绍了Stable Diffusion模型的构成和运行原理,而在今天正式介绍模型类型之前,有必要带你重新认识下这款意义重大的官方模型。
不知你是否产生过这样的疑惑:如今市面上有如此多丰富的绘图模型,为什么Stable Diffusion官方模型还会被大家津津乐道?当然除了它本身能力强大外,更重要的是从零训练出这样一款完整架构模型的成本非常高。根据官方统计,Stable Diffusion v1-5 版本模型的训练使用了256个40G的 A100 GPU(专用于深度学习的显卡,对标3090以上算力),合计耗时15万个GPU小时(约17年),总成本达到了60万美元。除此之外,为了验证模型的出图效果,伴随着上万名测试人员每天170万张的出图测试,没有海量的资源投入就不可能得到如今的Stable Diffusion。这样一款模型能被免费开源,不得不说极大地推进了AI绘画技术的发展。

按理说这么大成本训练出来的模型,绘图效果应该非常强大吧?但实际体验过的朋友都知道,对比开源社区里百花齐放的绘图模型,官方模型的出图效果绝对算不上出众,甚至可以说有点拉垮,这是为什么呢?

这里我们用ChatGPT来对比就很好理解了。ChatGPT的底层大模型是GPT模型,包括出道即巅峰的GPT3.5和后来火爆全网的GPT4,这些模型虽然包含了海量的基础知识,但并不能直接拿来使用,还需要经过人工微调和指导才能应用在实际生活中,而ChatGPT就是在聊天领域的应用程序。同理,Stable Diffusion作为专注于图像生成领域的大模型,它的目的并不是直接进行绘图,而是通过学习海量的图像数据来做预训练,提升模型整体的基础知识水平,这样就能以强大的通用性和实用性状态完成后续下游任务的应用。
用更通俗的话来说,官方大模型像是一本包罗万象的百科全书,虽然集合了AI绘图所需的基础信息,但是无法满足对细节和特定内容的绘图需求,所以想由此直接晋升为专业的绘图工具还是有些困难。
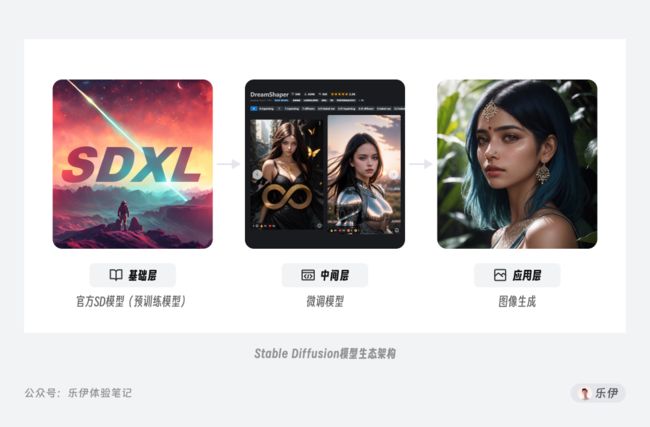
Stable Diffusion官方模型的真正价值在于降低了模型训练的门槛,因为在现有大模型基础上训练新模型的成本要低得多。对众多炼丹爱好者来说,只需在官方模型基础上加上少量的文本图像数据,并配合微调模型的训练方法,就能得到应用于特定领域的定制模型。一方面训练成本大大降低,只需在本地用一张民用级显卡训练几小时就能获得稳定出图的定制化模型,另一方面,针对特定方向训练模型的理解和绘图能力更强,实际的出图效果反而有了极大的提升。
常见模型解析
了解了官方模型的价值,下面我们再来正式介绍下平时使用的几种模型。根据模型训练方法和难度的差异,我们可以将这些模型简单划分为2类:一种是主模型,另一种则是用于微调主模型的扩展模型。
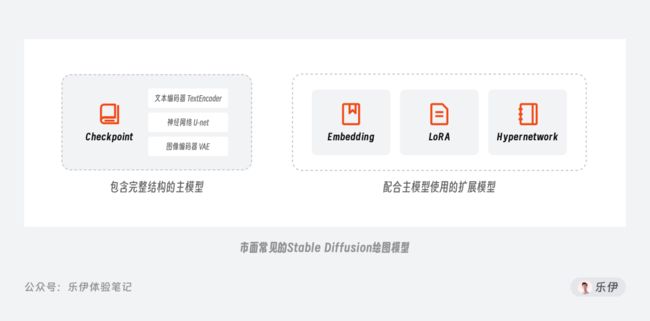
主模型指的是包含了TextEncoder(文本编码器)、U-net(神经网络)和VAE(图像编码器)的标准模型Checkpoint,它是在官方模型的基础上通过全面微调得到的。但这样全面微调的训练方式对普通用户来说还是比较困难,不仅耗时耗力,对硬件要求也很高,因此大家开始将目光逐渐转向训练一些扩展模型,比如Embedding、LoRA和Hypernetwork,通过它们配合合适的主模型同样可以实现不错的控图效果。
我们可以将主模型理解为一本面向特定科目的教材,而扩展模型则是针对教材内容进行补充的辅导资料或习题册。
我在下表中整理了常见模型的功能和特点差异,下面挨个为大家介绍。

3.1 Checkpoint
先来看看第一种模型:Checkpoint模型,又称Ckpt模型或大模型。Checkpoint 翻译为中文叫检查点,之所以叫这个名字,是因为模型训练到关键位置时会进行存档,有点类似我们玩游戏时的保存进度,方便后面进行调用和回滚,比如官方的v1.5模型就是从v1.2的基础上调整得到的。

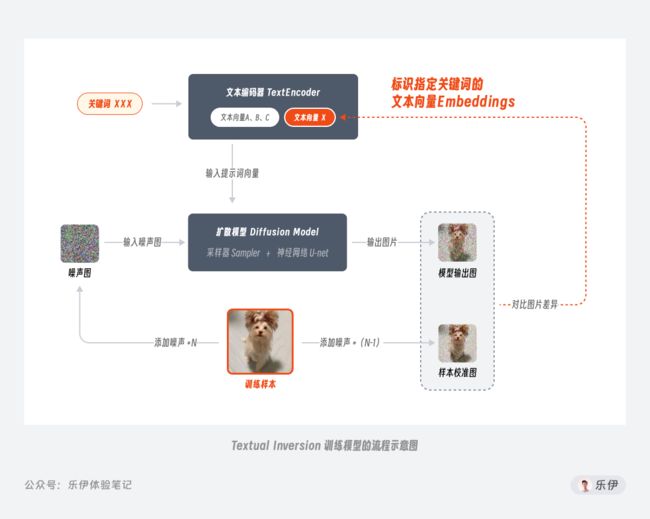
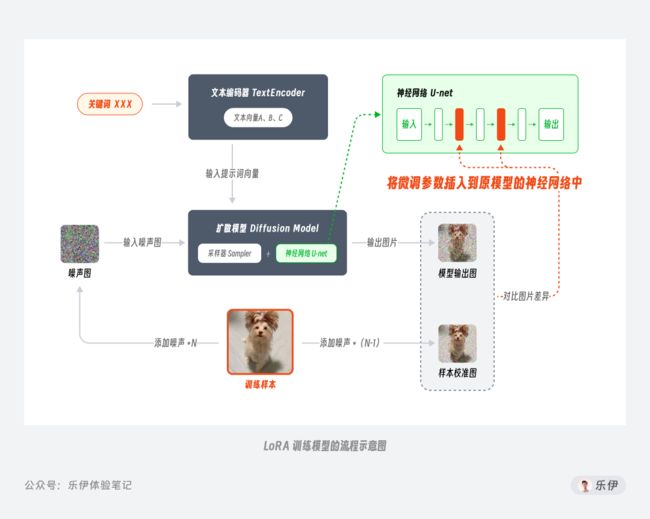
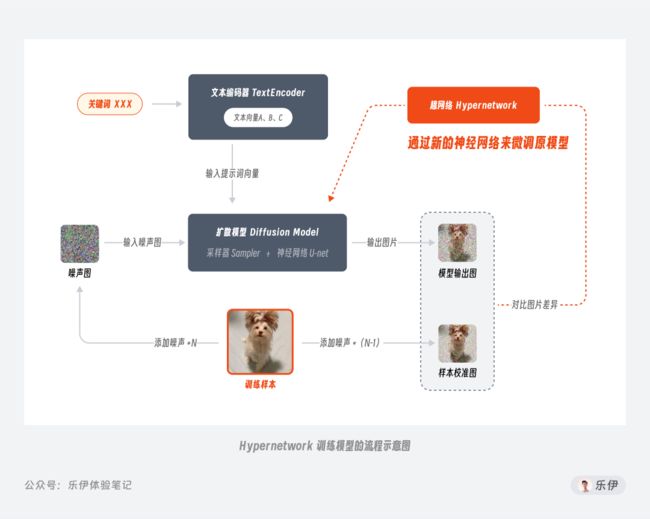
Checkpoint模型的常见训练方法叫Dreambooth,该技术原本由谷歌团队基于自家的Imagen模型开发,后来经过适配被引入Stable Diffusion模型中,并逐渐被广泛应用。为了方便大家更好的理解各个模型之间的差异,我针对每种模型的训练过程整理了以下的示意图,下面是Dreambooth训练模型的过程:

简单介绍下Dreambooth训练模型的过程:
-
第一步:先为训练样本添加N步噪声得到【噪声图】
-
第二步:再为训练样本添加N-1步噪声得到【样本校准图】,这样比上面的【噪声图】会稍微清晰一点的
-
第三步:将【噪声图】和由【关键词XXX】生成的文本向量都输入到扩散模型中,得到【模型输出图】
-
第四步:将【模型输出图】和【样本校准图】进行对比,并根据差异值来微调扩散模型直到它可以将【关键词XXX】和【训练样本】之间进行关联
-
第五步:通过这样的训练方式,后续我们在输入【关键词XXX】时,模型就会绘制一张类似【训练样本】的图片了。
通过上面的训练过程我们不难看出,Dreambooth训练模型是通过微调整个网络参数来得到一个完整的新模型。因此Ckpt模型可以很好的学习一个新概念,无论是用来训练人物、画风效果都很好。但缺点是训练起来成本较高,正常来说从官方模型通过Dreambooth训练出一款Ckpt模型,预计需要上万张图片,并且模型的文件包都比较大(至少都是在GB级别),常见的模型大小有2G、4G、7G等,使用起来不够灵活。
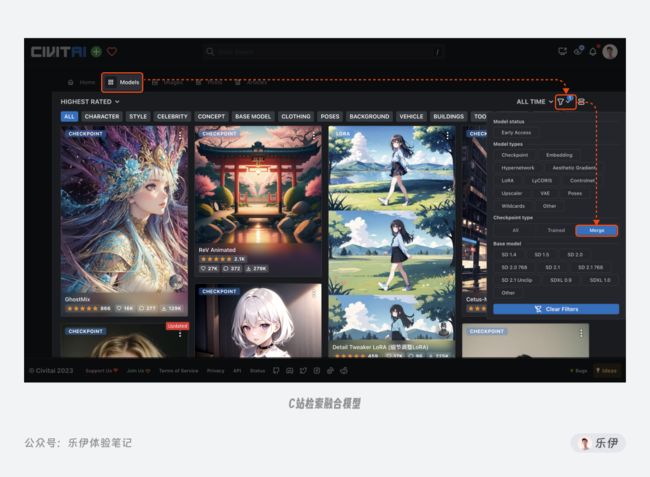
需要注意的是:并非模型体积越大,其绘图质量就越好。我们在模型社区里有时候会看到高达十几GB的Ckpt模型,但并非意味着这些模型就十分强大,因为除了通过Dreambooth训练,还可以通过模型融合的方法得到Ckpt模型,但如果作者没有对模型进行优化处理,融合后的模型中会夹杂着大量的垃圾数据,这些数据除了占用宝贵的硬盘空间外没有任何作用。关于模型融合的乱象是目前模型社区中不可忽视的问题,我会在文章结尾进行展开说明。
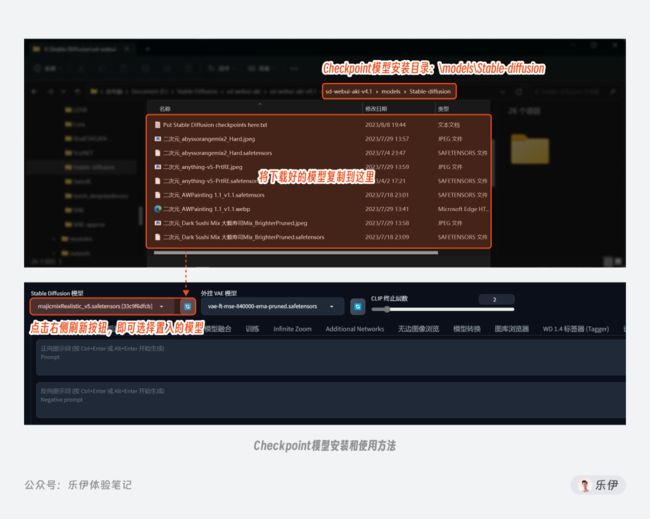
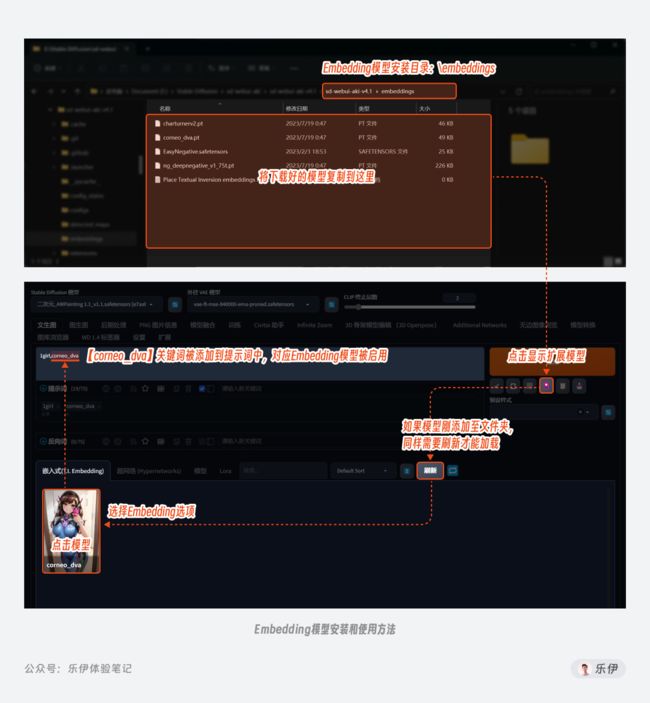
使用Checkpoint模型的方法也很简单,我们下载好模型文件后,将其存放到Stable Diffusion安装目录下\models\Stable-diffusion文件夹中。如果你是在WebUI打开的情况下添加的新模型,需要点击右侧的刷新按钮进行加载,这样就能选择新置入的模型了。
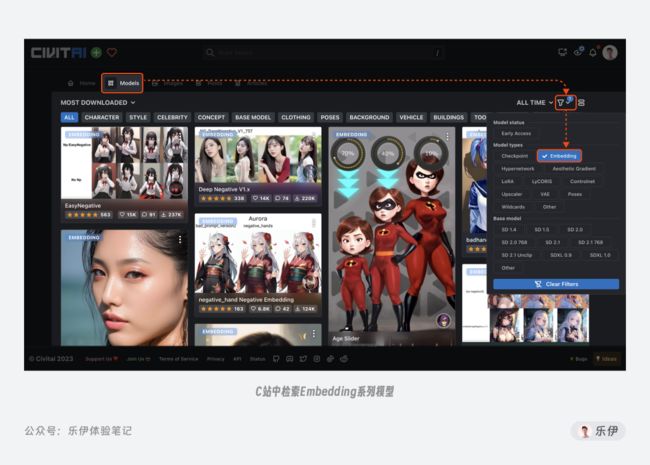
3.2 Embeddings
介绍完了主模型,下面我们再看看各种扩展模型,首先是最轻量的Embeddings模型。
虽然Ckpt模型包含的数据信息量很多,但动辄几GB的文件包使用起来实在不够轻便。比如有的时候我们只想训练一款能体现人物特征的模型来使用,如果每次都将整个神经网络的参数进行一次完整的微调未免有太过兴师动众,而这个时候就需要Embeddings闪亮登场了。
Embeddings又被称作嵌入式向量,在之前初识篇的文章里我给大家介绍了Stable Diffusion模型包含文本编码器、扩散模型和图像编码器3个部分,其中文本编码器 TextEncoder的作用是将提示词转换成电脑可以识别的文本向量,而Embedding模型的原理就是通过训练将包含特定风格特征的信息映射在其中,这样后续在输入对应关键词时,模型就会自动启用这部分文本向量来进行绘制。
训练Embeddings模型的过程,由于是针对提示文本部分进行操作,所以该训练方法叫做Textual Inversion文本倒置,平时在社区中提到Embeddings和Textual Inversion时,指的都是同一种模型。
如果你此前下载过Embeddings模型包,会惊讶的发现它们普遍都非常非常小,有的可能只有几十KB大小。为什么模型之间会有如此大的体积差距呢?类比来看,Ckpt像是一本厚厚的字典,里面收录了图片中大量元素的特征信息,而Embeddings就像是一张便利贴,它本身并没有存储很多信息,而是将所需的元素信息提取出来进行标注。在这个基础上,我们也能将Embeddings模型简单理解为封装好的提示词文件,通过将特定目标的描述信息整合在Embeddings中,后续我们只需一小段代码即可调用,效果要比手动输入要方便快捷上许多。像我们平时头疼的避免错误画手、脸部变形等信息都可以通过调用Embeddings模型来解决,比如最出名的EasyNegative模型。

以守望先锋里人气角色 D.VA为例。对于该角色我们都有统一的外貌共识,比如蓝色紧身衣、棕色头发、脸上的花纹等,这些信息如果单纯通过提示词描述往往很难表达准确,而有了Embedding就轻松多了。可以看到调用了D.VA的Embedding模型后,即使是不同画风的主模型也都能实现比较准确的角色形象还原。

当然,Embedding也有自己的局限性。由于没有改变主模型的权重参数,因此它很难教会主模型绘制没有见过的图像内容,也很难改变图像的整体风格,因此通常用来固定人物角色或画面内容的特征。使用方法也很简单,只需将下载好的模型放置到Stable Diffusion安装目录下\embeddings文件夹中,使用时点击对应的模型卡片,对应的关键词就会被添加到提示词输入框中,这时再点击生成按钮便会自动启用模型的控图效果了。
3.3 LoRA
虽然Embeddings模型非常轻量,但大部分情况下都只能在主模型原有能力上进行修正,有没有一种模型既能保持轻便又能存储一定的图片信息呢?这就不得不提我们大名鼎鼎的LoRA模型了。

LoRA是 Low-Rank Adaptation Models的缩写,意思是低秩适应模型。LoRA原本并非用于AI绘画领域,它是微软的研究人员为了解决大语言模型微调而开发的一项技术,因此像GPT3.5包含了1750亿量级的参数,如果每次训练都全部微调一遍体量太大,而有了lora就可以将训练参数插入到模型的神经网络中去,而不用全面微调。通过这样即插即用又不破坏原有模型的方法,可以极大的降低模型的训练参数,模型的训练效率也会被显著提升。
相较于Dreambooth全面微调模型的方法,LoRA的训练参数可以减少上千倍,对硬件性能的要求也会急剧下降,如果说Embeddings 像一张标注的便利贴,那LoRA就像是额外收录的夹页,在这个夹页中记录了更全面图片特征信息。
由于需要微调的参数量大大降低,LoRA模型的文件大小通常在几百MB,比Embeddings丰富了许多,但又没有Ckpt那么臃肿。模型体积小、训练难度低、控图效果好,多方优点加持下LoRA收揽了大批创作者的芳心,在开源社区中有大量专门针对LoRA模型设计的插件,可以说是目前最热门的模型之一。
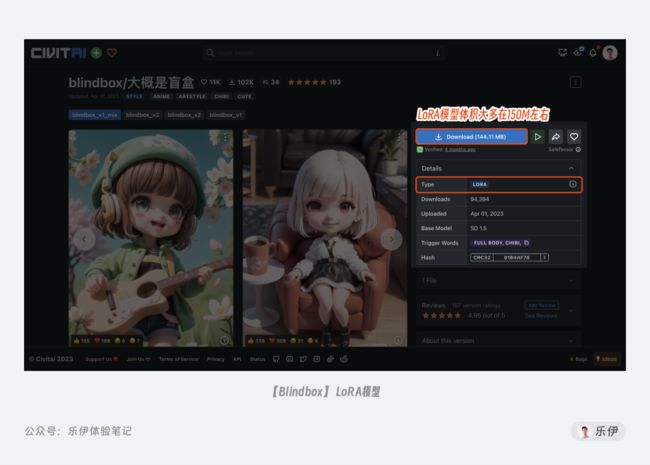
那LoRA模型具体有哪些应用场景呢?总结成一句话就是固定目标的特征形象,这里的目标既可以是人也可以是物,可固定的特征信息就更加保罗万象了,从动作、年龄、表情、着装,到材质、视角、画风等都能复刻。因此LoRA模型在动漫角色还原、画风渲染、场景设计等方面都有广泛应用。
安装LoRA模型的方法和前面大同小异,将模型保存在\models\Lora文件夹即可,在实际使用时,我们只需选中希望使用的LoRA模型,在提示词中就会自动加上对应的提示词组。
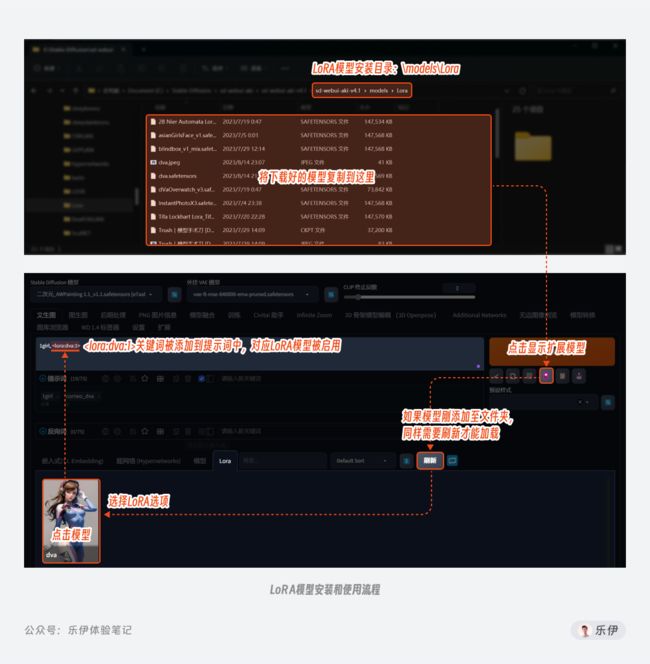
不同的是这里我们可以自行设置Lora在对画面的影响权重,关于控制权重的强调语法大家可以看之前的提示词篇教程,此外作者在模型介绍中大多也会提供推荐的权重数值作为参考。
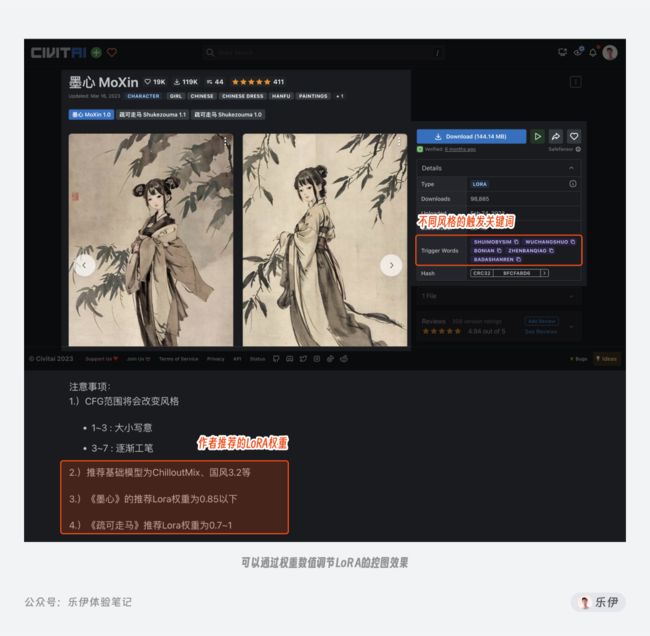
需要注意的是,有些LoRA模型的作者会在训练时加上一些强化认知的触发词,我们在下载模型时可以在右侧看到trigger word,非常建议大家在使用LoRA模型时加上这些触发词,可以进一步强化LoRA模型的效果。但触发词不是随便添加的,每一个触发词可能都代表着一类细化的风格。当然有的模型详情中没有触发词,这个时候我们直接调用即可,模型会自动触发控图效果。
有的trigger word触发词下面还有一栏Tag标签,这里表示的意思是模型在社区中所属的类目,只是方便大家查找和定位,和我们实际使用Stable Diffusion并没有什么关系,无视即可。
3.4 Hypernetwork
接着,我们再来了解下 Hypernetwork模型 。它的原理是在扩散模型之外新建一个神经网络来调整模型参数,而这个神经网络也被称为超网络。
因为Hypernetwork训练过程中同样没有对原模型进行全面微调,因此模型尺寸通常也在几十到几百MB不等。它的实际效果,我们可以将其简单理解为低配版的LoRA,虽然超网络这名字听起来很厉害,但其实这款模型如今的风评并不出众,在国内已逐渐被lora所取代。因为它的训练难度很大且应用范围较窄,目前大多用于控制图像画风。所以除非是有特定的画风要求,否则还是建议大家优先选择LoRA模型来使用。
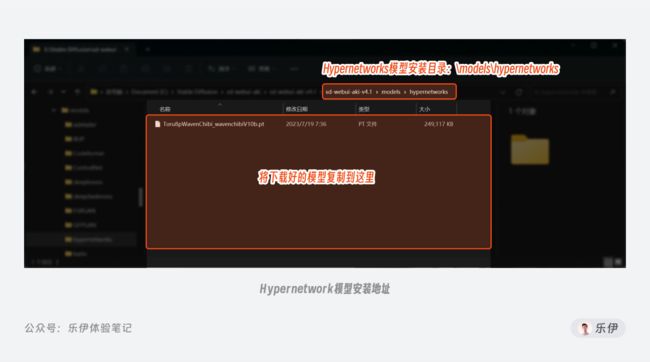
下面是Hypernetwork的安装地址,使用流程与LoRA基本相同,这里就不再重复演示了。
3.5 VAE
最后就是VAE模型了,在初识篇中我们有对它进行过简单介绍,它的工作原理是将潜空间的图像信息还原为正常图片。作为ckpt模型的一部分,VAE模型并不像前面几种模型用于控制图像内容,而是对主模型的图像修复。
我们在使用网络上分享的ckpt模型绘图时,有时候会发现图像的饱和度很低,呈现出灰色质感,但是加上VAE模型后图像色彩就得到了修正。因此很多人便以为VAE是一种调色滤镜模型,可以增强图像的显示效果,但其实这样的理解并不准确。

导致图像发灰的真正原因是主模型本身的VAE文件损坏,因此从潜空间恢复成正常图片时会存在图像信息缺失的问题,加上现在社区中很多模型都是从其他热门模型融合而来,如果初始模型的VAE文件有问题,就会导致融合后模型都出现图像发灰的情况,最典型的就是融合模型Anything4.5。

这种情况下一般都需要修复VAE才能使主模型恢复正常,但修复模型是个技术活,如果将所有模型都修复一遍未免成本过高,因此在WebUI中提供了外置VAE的选项,只要在绘图时选择正常的VAE模型,在图像生成过程中就会忽略主模型里内置损坏的VAE而使用外置模型,而这才是图像色彩被修正的真正原因。

但更换外置VAE并非是长久之计,有些模型在挂载外置VAE后反而会出现图像模糊或者错乱线条的情况(当然也是模型本身有问题)。此外,还有个问题是很多人将社区中现有的一些VAE重命名后加入自己模型来使用,这就会导致我们经常下载了多个重复的VAE模型,造成极大的资源浪费。我们可以在秋叶启动器中查看各个模型的Hash哈希值,它类似于模型的身份证号,无论是时间、创作者、训练机器的改变都会导致哈希值不同。因此如果2个模型的哈希值相同,说明它们本质上是同一个模型文件,只是修改了名字。
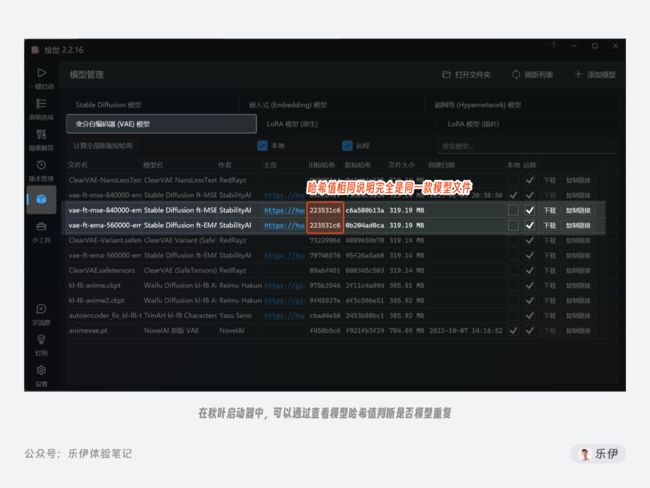
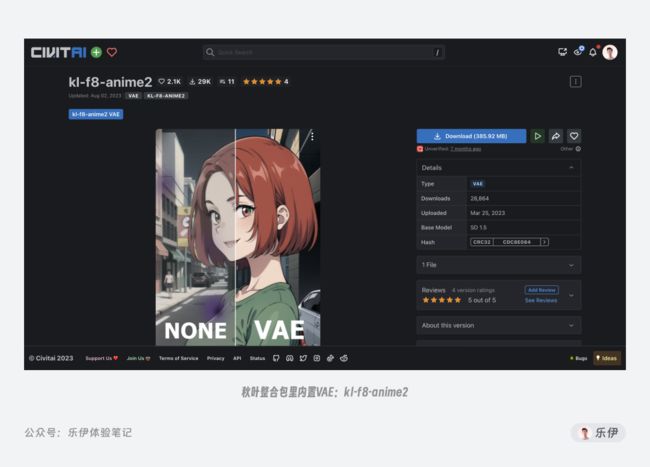
好在社区中目前大部分新训练的ckpt模型中VAE都比较正常,而对于有问题的模型,作者一般在介绍页中会附上他们推荐的VAE模型,当然也有一些可以通用的VAE,比如秋叶整合包里内置的【kl-f8-anime2】。
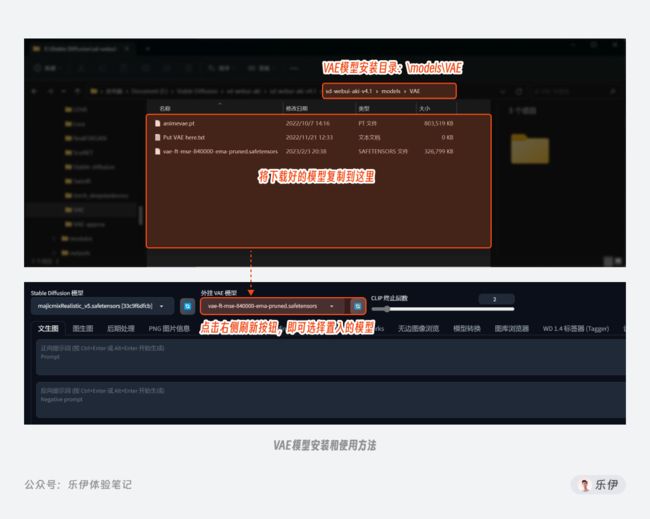
VAE模型的放置位置是在\models\VAE,因为是辅助Checkpoint大模型来使用,所以可以将大模型对应的VAE修改为同样的名字,然后在选项里勾选自动,这样在切换Checkpoint模型时VAE就会自动跟随变换了。
模型的功能类型
介绍了不同模型的特点和差异后,我们再回过头来看看目前社区模型的功能类型,从控图方向大致可以分为三类:固定对象特征、固定图像风格和概念艺术表达
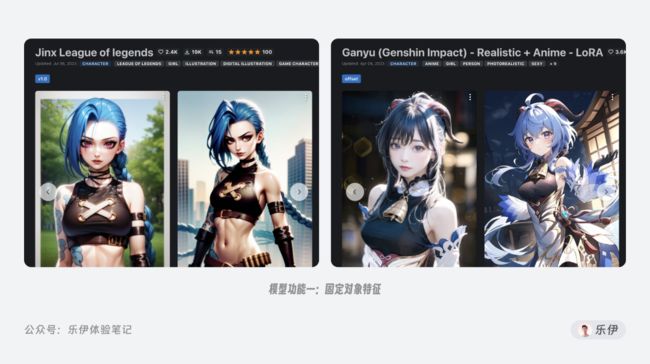
固定对象特征:这里的对象既可以指人,也可以指物。以人物角色为例,模型在训练时只需学习人物的大致特征,比如外貌、服饰、发型、表情等,这些特征相对来说比较明确,比如金克丝标志性的蓝色麻花辫和萝莉身材、甘雨的兽角和蓝色头发等。因此,训练特定对象的模型训练起来相对更加简单。
固定图像风格:相较于明确的对象,图像画风包含更多的信息。最常见的如摄影风格、二次元卡通风格、2.5D风格等,这些绘图风格除了主体内容,还包括颜色、线条、光影、笔触等多方面的环境信息,且不同特征信息之间相互关联,共同组合成最终的图片。因此模型需要学习的内容更多也更加复杂。
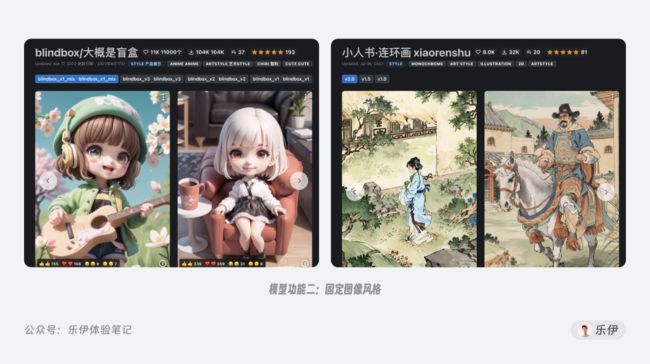
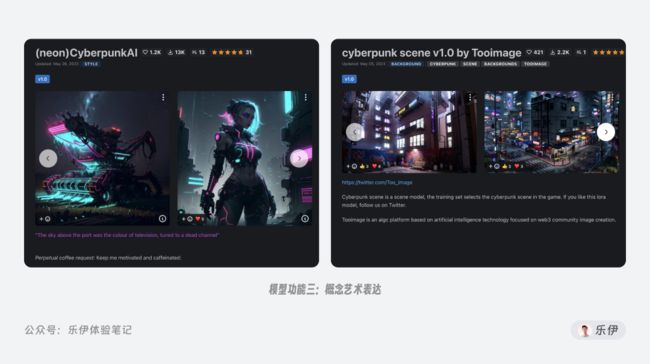
概念艺术表达:概念艺术指的是将某一类比较抽象的事物通过具象化的表现手法进行展示,最典型的就是一直很火的赛伯朋克。这类艺术作品充斥着霓虹灯、机械科技、黑客等特征元素,但又没有具体的画风限制,既可以是二次元的卡通动漫风格,也可以是真实的人物场景。对于这类没有具体的对象特征,但又能被划分为同类型的艺术概念,模型在学习和理解上又上升了一层难度,目前在开源社区中可以完美表达这类概念模型比较少见,且基本都是Ckpt和LoRA模型。
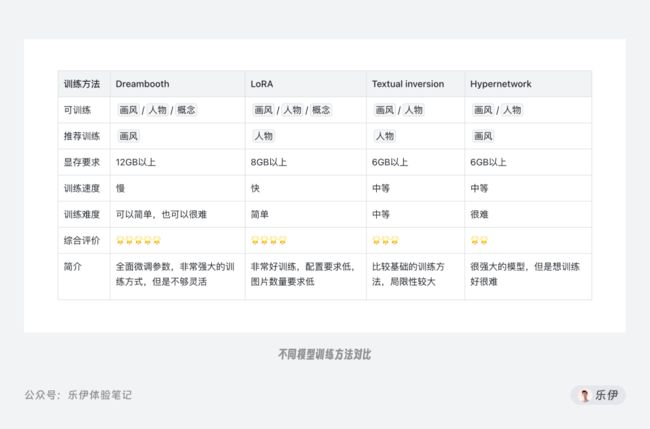
当然,还有基于服饰、背景、人物动作、产品概念等更多模型功能的细分,这里的分类仅方便初学者对模型功能建立初步的认知。下图中整理了常见模型训练方法在功能类型和训练要求上的差异对比,大家可以作为模型学习的知识扩展,关于具体训练方法我自己目前学习的还不够深入,这里就先不做过多拓展啦~
模型的挑选和使用
在此前的文章里有给大家安利用于下载模型的社区网站,今天再给大家补充下如何挑选和使用合适的模型:
5.1 让人迷惑的文件后缀
之前如果大家有尝试过自行安装Stable Diffusion模型,肯定遇到过被文件后缀弄混淆的情况,因为我们通常都习惯用后缀名来判断文件类型,比如后缀是*.psd的一般都是PS文件、*.fig则是Figma文件、*.pptx指的是Powerpoint文件等。
但Stable Diffusion模型的文件后缀包括了*.ckpt、*.pt、*.pth、*.safetensors等各种类型,甚至WebUI中还可以保存成*.png和*.webp格式。如果你单纯想靠文件后缀来判断模型类型往往会被弄的一头雾水,因为这几种都是标准的模型格式,在Stable Diffusion中并没有基于模型类型设置对应的文件后缀。比如*.ckpt后缀的文件既可能是Checkpoint模型、也可能是LoRA模型或者VAE模型。
而不同文件后缀的区别在于:*.ckpt、*.pt、*.pth等后缀名表示的是基于pytorch深度学习框架构建的模型,因为模型保存和加载底层用到的是Pickle技术,所以存在可被用于攻击的程序漏洞,因此这几款模型后缀的文件中可能会潜藏着病毒代码。为了解决安全问题,*.safetensors后缀名的模型文件逐渐普及开来,这类模型的加载速度更快也更安全,这一点在safe后缀名上也能看出来。
但我们需要知道的是,这几种后缀名的模型差异仅限于保存数据的形式,内部数据实际上是没有太大区别的,因此不同模型间也可以通过工具进行格式转换。
平时我们使用时尽量选择*.safetensors后缀的模型,并且在秋叶整合包中也有【允许加载不安全的模型】的开关选项,大家平时保持默认关闭状态即可。
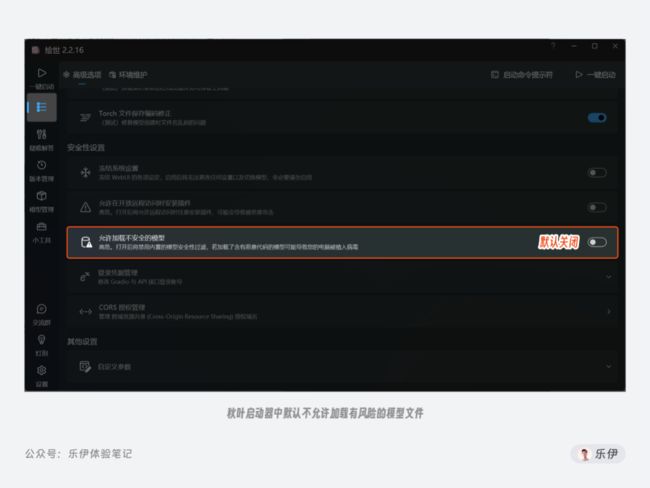
当我们需要区分模型类型时,可以使用秋叶大佬开发的Stable Diffusion模型在线解析工具,只需将模型文件拖入网页,即可快速分析出模型类型,并会贴心的附上安装地址提示和使用方法,并且该工具完全运行在本地,数据并不会上传到云端。
Stable Diffusion模型在线解析地址:https://spell.novelai.dev/

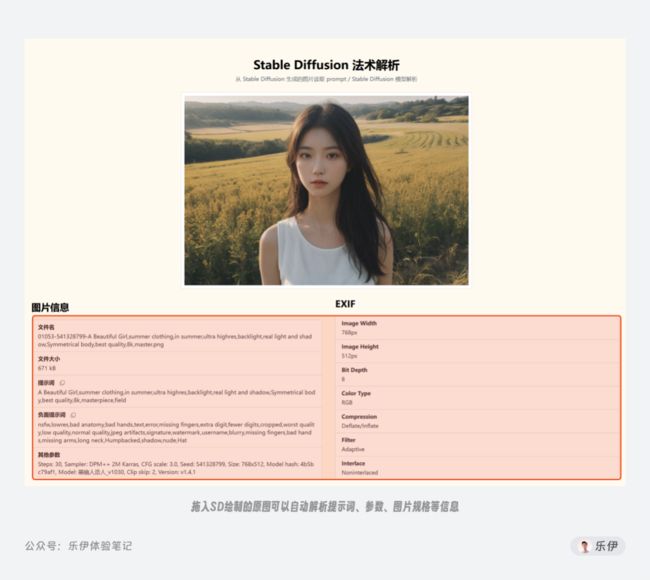
除了解析模型类型,该网站还有个非常好用的功能,就是可以读取Stable Diffusion生成图片的相关信息。只需将由Stable Diffusion绘制的原图拖入页面中,即可解析出之前所使用的提示词、设置参数等信息,需要注意的是上传的图片必须是没有经过编辑的AI绘画原图。
5.2 如何判断模型质量
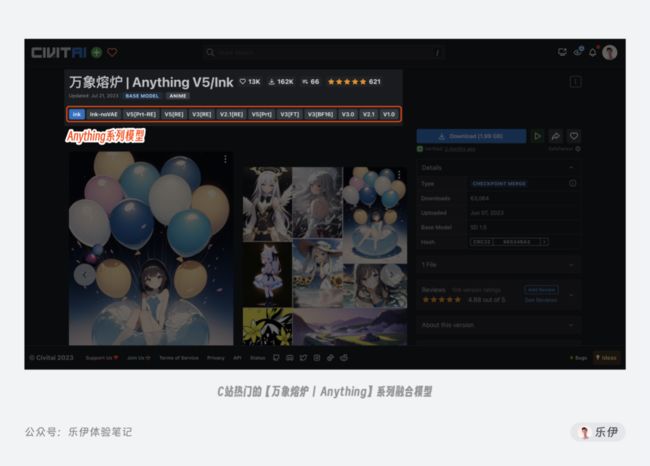
对大部分刚接触Stable Diffusion的AI绘画爱好者来说,往往都是将出图好看作为判断模型好坏的唯一标准。但随着魔法水平的提升,你会发现社区中很多热门模型的绘图效果似乎都差不多,这是由于模型融合导致的同质化问题,有些模型基于相似程度甚至可以归为一个系列,比较常见的有橘子系列、蜡笔系列、Anything系列、Cf3系列模型等。
除此还有前面提到的垃圾数据,也是很多融合模型都存在的问题。如今,大多数开源模型平台都没有人工审核标准,导致乱七八糟的模型层出不穷,这个时候就需要魔法师拥有自行判断模型标准的能力。下面基于錾制千秋大佬整理的模型判断标准,给大家提供几点参考建议。
一般来说,业内可以被称得上优秀的模型至少需要满足以下几个条件:出图结果准确、没有乱加细节、图像正常、文件健康
-
出图结果准确:即模型对提示词识别的准确程度,优质模型能正确辨别提示内容中的重要内容并给予呈现
-
没有乱加细节:这里指的是图像中出现提示词没有提及的内容,当然这种情况无法完全避免,只能说越少越好。比如有的模型在作者刻意引导下只靠简单词汇就能绘制非常精美的人像图,但这些人物可以说千篇一律,风格完全被固定死,即使加上了LoRA也无法改变人物特征,会极大的影响提示内容的控图效果。
-
图像正常:图像的美感因人而异,但至少应保证出图结果稳定且正常,比如出图结果中没有线条错乱、五官扭曲等情况。
-
文件健康:这里就是前面提到的模型中没有额外的垃圾数据,且VAE文件正常,无需使用外置模型。
关于最新的SDXL
7月26日,Stability AI官网宣布开源了迄今为止最强的绘图模型—Stable Diffusion XL 1.0,很多人都在惊叹Midjourney的免费版平替要来了,为什么这款新模型会引起如此多热议,相较于之前版本又有哪些区别呢?
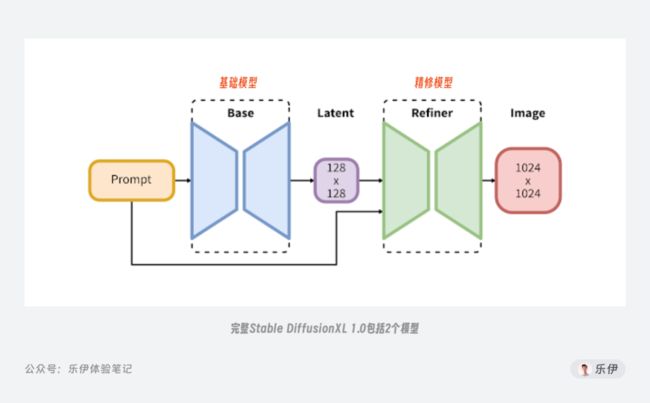
自去年8月Stable Diffusion V1发布至今,Stability已陆续推出过V1.X、V2.X、XL 0.9等多个版本,但除了一开始开源的初代版本外,后续版本似乎都没有像XL 1.0这样引起如此多热议,XL0.9也只是支持在ComfyUI上使用,而XL 1.0算是真正意义上大多数用户可以体验的全新旗舰版模型。完整的Stable DiffusionXL 1.0包含2个部分:Base版基础模型和Refiner版精修模型。前者用于绘制图像,后者用于对图像进行优化,添加更多细节。
下面先来了解下下本次Stable DiffusionXL 1.0发布后最让人关注的几点信息:
6.1 迄今为止最大的开源绘图模型
Stable DiffusionXL 1.0是目前世界上最大参数级的开放绘图模型,基础版模型使用了35亿级参数,而精修版模型使用了66亿级参数,要知道清华的LLM—ChatGLM也才6亿的参数量。巨量级参数带来的是出图兼容性大幅提升,Stable DiffusionXL 1.0几乎可以支持任意风格的模型绘制,并且图像精细度和画面表现力也都得到了显著提升。

如今的Stable DiffusionXL甚至可以支持生成清晰的文本,这是目前市面上绝大多数绘图模型都无法做到的。此外,对人体结构的理解也被加强,像之前一直被诟病的手脚错误等问题都得到了显著改善。
6.2 原生出图的分辨率超级加倍
在之前版本的Stable Diffusion模型中,由于是采用512或768尺寸的图片进行训练,因此当初始图像超过这个尺寸就会出现多人多头的情况,但小尺寸图像又无法体现画面中的细节内容,因此此前的做法都是先生成小图,再通过高清修复等方式绘制大图。
但XL1.0 采用了1024 x1024分辨率的图片进行训练,这就保证了日后我们以同样尺寸绘制图像时再也不用担心多人多头的问题,可以直接绘制各种精美的大尺寸图片(如果显卡算力跟得上的话~)。并且通过Refiner精修模型的二次优化,原生图像表现力也得到了显著提升。

6.3 更加智能的提示词识别
此前我们在绘制图像时通常需要添加“masterpiece”等限定词来提升画面表现力,而如今XL1.0只需短短几个词便能生成非常精美的图片。
更重要的是,新版XL对自然语言的识别能力大大增强。此前我们都是通过词组方式来填写提示词,对于图像中需要突出展示的内容我们也是手动添加括号来增强对应关键词的权重。而日后我们可能更多情况下都会使用自然语言,也就是连贯的句子来描述图像信息,Stable Diffusion会自动识别关键内容给予呈现。简单来说,我们编写咒语的门槛会大大降低,只需简单的自然语言描述就能获得目标图像。

6.4 超丰富的艺术风格支持
旧版模型的默认绘图风格更倾向于真系系的照片摄影,而在最新的Stable Diffusion XL1.0中提供了更加丰富的艺术风格选项,可以通过提示词在十余种不同风格间自由切换,包括动漫、数字插画、胶片摄影、3D建模、折纸艺术、2.5D等距风、像素画等超多选项。
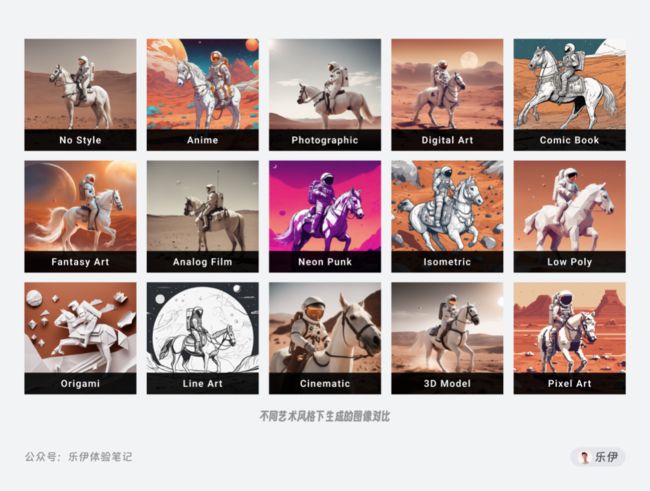
结合目前大模型的发展方向来看,模型的真正精髓应该是贵精不贵多,完美的Stable Diffusion模型应该是像Midjourney这样包罗万象、集百家之长的综合模型,而最新的XL1.0已经具备了这样的雏形,可以说代表了AI绘画领域的一个重要里程碑,配合丰富的开源插件生态,未来将有更多的玩法供广大魔法师们来探索。
目前Stable Diffusion XL1.0在硬件兼容性上还没有做到完美适配,对硬件要求也比较高,所以暂时不建议大家直接下载到本地使用。目前各大社区都在积极响应SDXL微调模型的训练活动,相信几个月后我们的模型库就会迎来一次重磅更新。
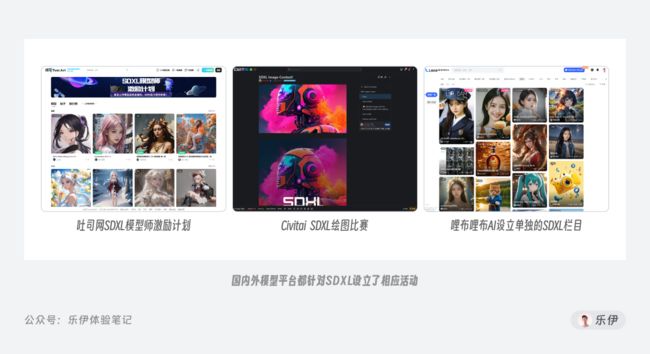
目前不少社区平台都上架了在线使用SD绘画的功能,这里也为大家整理了一些可以免费体验SDXL的资源链接,具体的使用和操作方法看平台引导即可。
Discord官方社区:
https://discord.com/channels/1002292111942635562/1002292398703001601/1128053246133547118
SD旗下的AI工具Clipdrop:https://clipdrop.co/stable-diffusion
哩布哩布AI:LiblibAI·哩布哩布AI-中国领先的AI创作平台
吐司网:https://tusi.art/
对模型社区的思考
先来说下现实问题,我自己最近在使用SD出图时,发现开源社区里很多所谓顶流的绘图模型并不好用,除了几套固定的肖像图外没有太多发挥空间,尤其是配合角色形象的扩展模型使用时,大部分人物特征都直接失效了。后面去查找了资料发现了一些通用问题,以下内容仅是我个人意见,仅作参考。
以目前最火热的模型平台Civitai为例,C站一直以资源丰富、创作自由而闻名,但现实问题是很多时候我们难以分辨模型的真实质量。用户能看到所谓的模型效果图往往是作者出了千百张图后从中选择的最优解,模型画廊里用户反馈的图片很多时候也是多模型组合产出的结果,可以提供的参考价值有限。

其次,很多模型平台的流量推送逻辑是基于模型的更新速度,更新频繁的模型往往能获得更高热度。但问题是需要频繁更新的模型大多都是融合速成得来,因此后期需要经常调整,真正优质的模型反而更新频率很低,因为作者在一开始已经将模型训练的十分出色了。
最后是很多模型平台在发起的模型创作激励活动,这类活动的初衷是为了奖励优秀的模型创作者,促进开源模型社区的发展,是一项刺激AIGC领域发展的有益活动。但很多创作者通过快速融合来批量生产罐头模型薅羊毛,甚至为了冲榜可以炼制成千上万张人脸,毕竟好看的小姐姐谁不喜欢呢?但问题是国内AI绘画领域群体存在明显的信息断层,大部分人对模型好坏的判断标准都仅限于可以出美女图,导致这类模型越来越多。
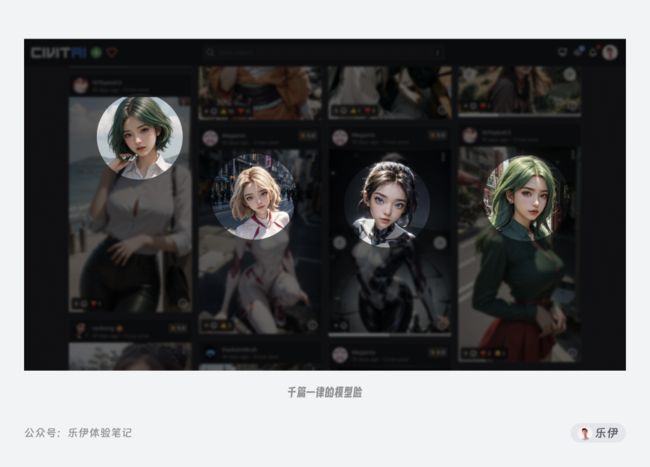
综合以上问题,最终导致如今的模型社区呈现出劣币驱逐良币的现象,同质化模型遍地开花,而很多真正兼容性强、训练优秀的模型却很难被发现。
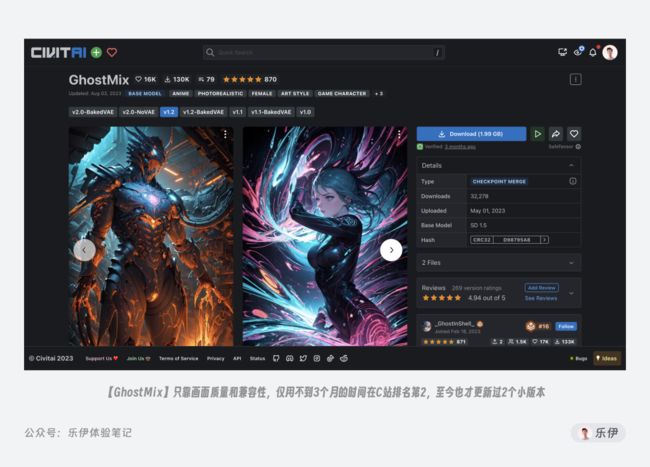
举个真实的例子,前面提到的GhostMix模型制作者GhostInShell,作为唯一一个在C站只发了一个ckpt模型就进入前十名的制作者,在非真人模型且不做任何擦边内容的前提下,纯靠模型的画面质量和极高的兼容性3个月内在C站上做到了历史全模型最高评价榜的第2名,下图中可以看到GhostMix模型超强的兼容性和精美的出图效果,且C站排名前十的非擦边模型Deliberate、ReV、DreamShaper都是类似的效果。
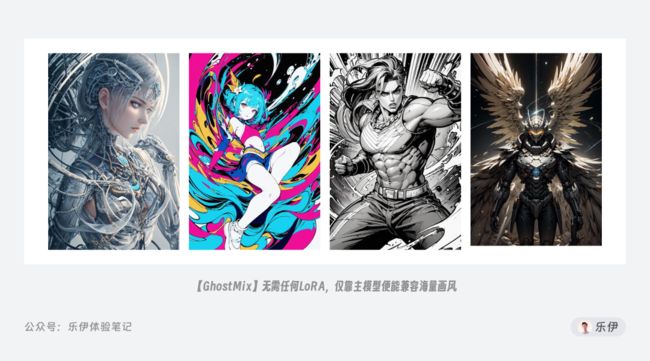
虽说如今国内模型圈的资源十分丰富,但距离百家争鸣的开源社区还有很长的路要走。如果所有人都在关注千篇一律的人像模型,迟早都会审美疲劳,而到那个时候又有谁愿意花费大精力训练优质模型呢?对此,我也希望国内社区平台可以规范优质模型的判断标准和激励制度,加强模型多维度能力的审核环节,流量扶持固然有助于新作品的曝光,但真正优秀的创作者也应被更多人看到。而我们作为魔法协会的一员,也需加强对相关知识的学习,共同维护健康良好的社区环境。
在今天的文章里没有涉及太多的实操案例,更多的是对目前模型知识的总结和反思,文中不少知识点都来自于开源社区中各位前辈的无私分享,非常感谢秋叶、錾制千秋、GhostInShell、落辰星等大佬为推动国内SD开源学习所做的努力。
希望通过这篇文章,可以帮助更多对Stable Diffusion感兴趣的朋友建立从原理层到应用层的知识框架,并对未来AI绘画模型的发展有更加体系化的认知,如果你有更多对SD模型的想法也欢迎在评论区给我留言。

如果你想学习更多AIGC相关知识或者有相关问题,欢迎加入我的粉丝交流群共同探讨