Java网络编程——通过JDBC API访问数据库
关系数据库仍然是目前最流行的数据库系统。如果没有特别说明,本帖所说的数据库就都指关系数据库。关系数据库中最主要的数据结构是表,表用主键来标识每一条记录,表与表之间可以存在外键参照关系。数据库服务器提供管理数据库的各种功能,包括:创建表,向表中插入、更新和删除数据,备份数据,以及管理事务等。数据库服务器的客户程序可以用任何一种编程语言编写,这些客户程序都向服务器发送SQL命令,服务器接收到SQL命令,完成相应的操作。例如,在下图中,客户程序为了查找姓名为Tom的客户的完整信息,向服务器发送了一条select查询语句,服务器执行这条语句,然后返回相应的查询结果。

Java程序也可以作为数据库服务器的客户程序,向服务器发送SQL命令。如果从头编写与数据库服务器通信的程序,那么显然,Java程序必须利用Socket建立与服务器的连接,然后根据服务器使用的应用层协议,发送能让服务器看得懂的请求信息,并且也要能看得懂服务器返回的响应结果。遗憾的是,目前的数据库服务器产品,如Oracle、SQLServer、MySQL和Sybase等,在应用层都有自定义的一套协议,而没有统一的标准。这意味着,对于一个已经能与Oracle服务器通信的Java程序,如果要改为与MySQL服务器通信,就必须重新编写通信代码。
为了简化Java程序访问数据库的过程,JDK提供了JDBC API。JDBC是Java DataBase Connectivity的缩写。如下图所示:
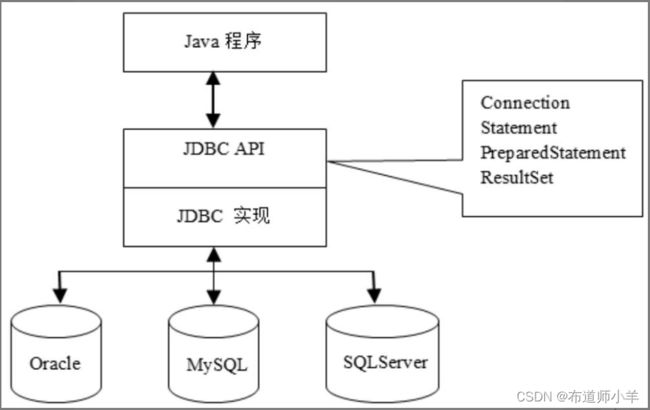
JDBC的实现封装了与各种数据库服务器通信的细节。Java程序通过JDBC API来访问数据库,有以下优点:
- (1)简化访问数据库的程序代码,无须涉及与数据库服务器通信的细节。
- (2)不依赖于任何数据库平台。同一个Java程序可以访问多种数据库服务器。
JDBC API主要位于java.sql包中,此外,在javax.sql包中包含了一些提供高级特性的API。
1、JDBC的实现原理
JDBC的实现封装了与各种数据库服务器通信的细节。如下图所示:
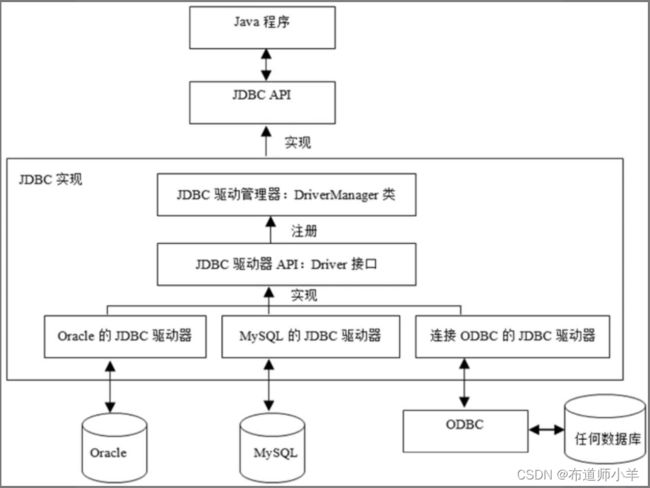
JDBC的实现包括3部分:
- JDBC驱动管理器:java.sql.DriverManager类,由JDK提供内置的实现,负责注册特定JDBC驱动器,以及根据特定驱动器建立与数据库的连接。
- JDBC驱动器API:由Oracle公司制定,其中最主要的接口是java.sql.Driver接口。
- JDBC驱动器:由数据库供应商或者其他第三方工具提供商创建,也被称为JDBC驱动程序。JDBC驱动器实现了JDBC驱动器API,负责与特定的数据库连接,以及处理通信细节。JDBC驱动器可以注册到JDBC驱动管理器中。Oracle公司很明智地让数据库供应商或者其他第三方工具提供商来创建JDBC驱动器,因为他们才最了解与特定数据库通信的细节,有能力对特定数据库的驱动器进行优化。
从上图可以看出,Oracle公司制定了两套API:
- JDBC API:Java应用程序通过它来访问各种数据库。
- JDBC驱动器API:当数据库供应商或者其他第三方工具提供商为特定数据库创建JDBC驱动器时,该驱动器必须实现JDBC驱动器API。
从上图中还可以看出,JDBC驱动器才是真正的连接Java应用程序与特定数据库的桥梁。Java应用程序如果希望访问某种数据库,就必须先获得相应的JDBC驱动器的类库,然后把它注册到JDBC驱动管理器中。
JDBC驱动器可分为以下4类:
- 第1类驱动器:JDBC-ODBC驱动器。ODBC(Open Database Connectivity,开放数据库互连)是微软公司为应用程序提供的访问任何一种数据库的标准API。JDBC-ODBC驱动器为Java程序与ODBC之间建立了桥梁,使得Java程序可以间接访问ODBC API。JDBC-ODBC驱动器是唯一由JDK提供内置实现的驱动器,属于JDK的一部分,在默认情况下,该驱动器就已经在JDBC驱动管理器中注册了。在JDBC刚刚发布后,JDBC-ODBC驱动器可以方便地用于应用程序的测试,但由于它连接数据库的速度比较慢,所以现在已经不提倡使用它了。
- 第2类驱动器:由部分Java程序代码和部分本地代码组成。用于与数据库的客户端API通信。在使用这种驱动器时,不仅需要安装相关的Java类库,还要安装一些与平台相关的本地代码。
- 第3类驱动器:完全由Java语言编写的类库。它用一种与具体数据库服务器无关的协议将请求发送给服务器的特定组件,再由该组件按照特定数据库协议对请求进行翻译,并把翻译后的内容发送给数据库服务器。
- 第4类驱动器:完全由Java语言编写的类库。它直接按照特定数据库的协议,把请求发送给数据库服务器。
一般说来,这几类驱动器访问数据库的速度由快到慢,依次为:第4类、第3类、第2类、第1类。第4类驱动器的速度最快,因为它把请求直接发送给数据库服务器,而第1类驱动器的速度最慢,因为它要把请求转发给ODBC,然后由ODBC把请求发送给数据库服务器。
大部分数据库供应商都为它们的数据库产品提供第3类或第4类驱动器。许多第三方工具提供商也开发了符合JDBC标准的驱动器产品,它们往往支持更多的数据库平台,具有很好的运行性能和可靠性。
2、JDBC API简介
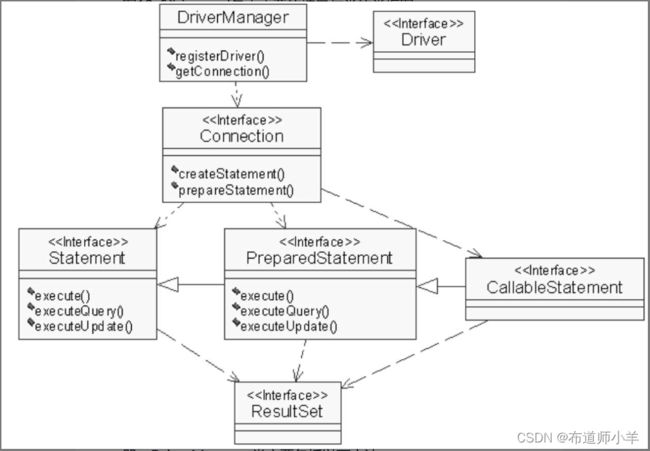
JDBC API主要位于java.sql包中,关键的接口与类如下所述:
- Driver接口和DriverManager类:前者表示驱动器,后者表示驱动管理器。
- Connection接口:表示数据库连接。
- Statement接口:负责执行SQL语句。
- PreparedStatement接口:负责执行预准备的SQL语句。
- CallableStatement接口:负责执行SQL存储过程。
- ResultSet接口:表示SQL查询语句返回的结果集。
下图为java.sql包中主要的接口与类的类框图:
2.1、Driver接口和DriverManager类
所有JDBC驱动器都必须实现Driver接口,JDBC驱动器由数据库厂商或第三方提供。在编写访问数据库的Java程序时,必须把特定数据库的JDBC驱动器的类库加入classpath中。
DriverManager类用来建立和数据库的连接以及管理JDBC驱动器。DriverManager类主要包括以下方法:
- registerDriver(Driver driver):在DriverManger类中注册JDBC驱动器。
- getConnection(String url,String user,String pwd):建立和数据库的连接,并返回表示数据库连接的Connection对象。
- setLoginTimeOut(int seconds):设定等待建立数据库连接的超时时间。
- setLogWriter(PrintWriter out) :设定输出JDBC日志的PrintWriter对象。
2.2、Connection接口
Connection接口代表Java程序和数据库的连接,Connection接口主要包括以下方法:
- getMetaData():返回表示数据库的元数据的DatabaseMetaData对象。元数据包含了描述数据库的相关信息。
- createStatement():创建并返回Statement对象。
- prepareStatement(String sql):创建并返回PreparedStatement对象。
2.3、Statement接口
Statement接口提供了3个执行SQL语句的方法:
- execute(String sql):执行各种SQL语句。该方法返回一个boolean类型的值,如果为true,则表示所执行的SQL语句具有查询结果,可通过Statement的getResultSet()方法获得这一查询结果。
- executeUpdate(String sql):执行SQL的insert、update和delete语句。该方法返回一个int类型的值,表示数据库中受该SQL语句影响的记录的数目。
- executeQuery(String sql):执行SQL的select语句。该方法返回一个表示查询结果的ResultSet对象,例如:

- executeBatch():批量执行一批SQL语句。
2.4、PreparedStatement接口
PreparedStatement接口继承了Statement接口。PreparedStatement用来执行预准备的SQL语句。在访问数据库时,可能会遇到这样的情况:某条仅仅参数不同的SQL语句被多次执行,例如:

以上SQL语句的格式如下:
![]()
在这种情况下,使用PreparedStatement,而不是Statement来执行SQL语句,具有以下优点:
- 简化程序代码。
- 提高访问数据库的性能。PreparedStatement执行预准备的SQL语句,数据库只需对这种SQL语句编译一次,然后就可以多次执行。而每次用Statement来执行SQL语句时,数据库都需要对该SQL语句进行编译。
PreparedStatement的使用步骤如下:
- (1)通过Connection的prepareStatement()方法生成PreparedStatement对象。以下SQL语句中NAME的值和AGE的值都用“?”代替,它们表示两个可被替换的参数。

- (2)调用PreparedStatement的setXXX方法,给参数赋值。

预准备SQL语句中的第1个参数为String类型,因此调用PreparedStatement的setString()方法,第2个参数为int类型,因此调用PreparedStatement的setInt()方法。这些setXXX()方法的第1个参数表示预准备SQL语句中的“?”的位置,第2个参数表示替换“?”的具体值。 - (3)执行如下SQL语句。

2.4、ResultSet接口
ResultSet接口表示select查询语句得到的结果集,结果集中的记录的行号从1开始。调用ResultSet对象的next()方法,可以使游标定位到结果集中的下一条记录。调用ResultSet对象的getXXX()方法,可以获得一条记录中某个字段的值。ResultSet接口提供了以下常用的getXXX()方法。
- getString(int columnIndex):返回指定字段的String类型的值,参数columnIndex代表字段的索引位置。
- getString(String columnName):返回指定字段的String类型的值,参数columnName代表字段的名字。
- getInt(int columnIndex):返回指定字段的int类型的值,参数columnIndex代表字段的索引位置。
- getInt(String columnName):返回指定字段的int类型的值,参数columnName代表字段的名字。
- getFloat(int columnIndex):返回指定字段的float类型的值,参数columnIndex代表字段的索引位置。
ResultSet提供了getString()、getInt()和getFloat()等方法。程序应该根据字段的数据类型来决定调用哪种getXXX()方法。此外,程序既可以通过字段的索引位置来指定字段,也可以通过字段的名字来指定字段。
对于以下的select查询语句,结果集存放在一个ResultSet对象中:

如果要访问String类型的NAME字段,那么可以采用以下两种方式:

对于ResultSet的getXXX()方法,指定字段的名字或者指定字段的索引位置各有优缺点。指定索引位置具有较好的运行性能,但程序代码的可读性差,而指定字段的名字虽然运行性能差一点,但程序代码具有较好的可读性。
如果要遍历ResultSet对象中所有记录,那么可以采用下面的循环语句:

3、JDBC API的基本用法
在Java程序中,通过JDBC API访问数据库包括以下步骤:
- (1)获得要访问的数据库的驱动器的类库,把它放到classpath中。
- (2)在程序中加载并注册JDBC驱动器。以下分别给出了加载JDBC-ODBC驱动器、SQL Server驱动器、Oracle驱动器和MySQL驱动器的代码。
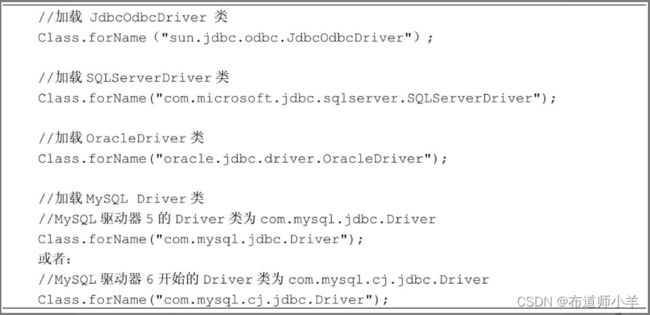
以上驱动器的Driver类在被加载的时候,能自动创建本身的实例,然后调用DriverManager.registerDriver()方法注册,例如对于MySQL的驱动器类com.mysql.cj.jdbc.Driver,当Java虚拟机加载这个类时,会执行它的如下静态代码块。

所以在Java应用程序中,只要通过Class.forName()方法加载MySQL Driver类即可,不必再注册驱动器的Driver类。 - (3)建立与数据库的连接。

getConnection()方法中有3个参数,dburl表示连接数据库的JDBC URL,user和password分别表示连接数据库的用户名和口令。
JDBC URL的一般形式为:
![]()
drivertype表示驱动器的类型。driversubtype是可选的参数,表示驱动器的子类型。parameters通常用来设定数据库服务器的IP地址、端口号和数据库的名称。以下给出了几种常用的数据库的JDBC URL形式。
如果通过JDBC-ODBC Driver连接数据库,那么采用如下形式:
jdbc:odbc:datasource
对于Oracle数据库连接,采用如下形式:
jdbc:oracle:thin:@localhost:1521:sid
对于MySQL数据库连接,采用如下形式:
jdbc:mysql://localhost:3306/STOREDB
- (4)创建Statement对象,准备执行SQL语句:
Statement statement = connection.createStatement();
- (5)执行SQL语句:
String sql="select ID,NAME,AGE,ADDRESS from CUSTOMERS where AGE>20";
ResultSet rs = statement.executeQuery(sql);
- (6)遍历ResultSet对象中的记录:
while (rs.next()){
long id = rs.getLong(1);
String name = rs.getString(2);
int age = rs.getInt(3);
String address = rs.getString(4);
}
(7)依次关闭ResultSet、Statement和Connection对象:
rs.close();
statement.close();
connection.close();
提示:从JDK7开始,ResultSet、Statement和Connection接口都继承了AutoCloseable接口。这意味着只要在try代码块中创建这些接口的实例,即使程序没有显式关闭它们,Java虚拟机也会在程序退出try代码块后自动关闭它们。不过,开发人员在编程时仍然要养成及时关闭这些资源的习惯,这可以提供程序代码的灵活性和安全性。
3.1、处理字符编码的转换
假定操作系统使用中文字符编码GB2312,而MySQL使用字符编码ISO-8859-1。当Java程序向数据库的表中插入数据时,需要把字符串的编码由GB2312转换为ISO-8859-1。
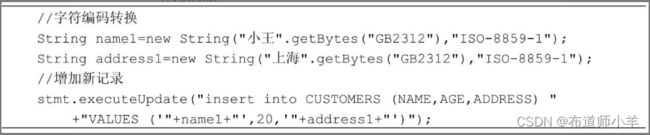
从表中读取数据时,则需要把字符串的编码由ISO-8859-1转换为GB2312。
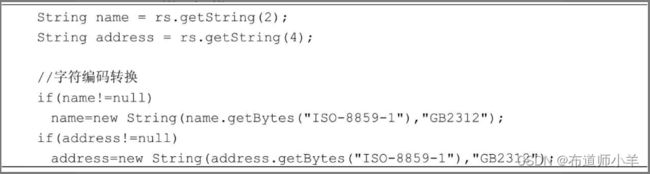
在程序中处理字符编码转换很烦琐。假如运行程序的操作系统与数据库使用同样的字符编码,就不需要字符编码转换了。对于MySQL,可以在连接数据库的URL中把字符编码也设为GB2312。

4.2、把连接数据库的各种属性放在配置文件中
不管连接哪一种数据库系统,都需要获得以下属性:
- 数据库驱动器的Driver类。
- 连接数据库的URL。
- 连接数据库的用户名。
- 连接数据库的口令。
为了提高程序的可移植性,可以把以上属性放到一个配置文件中,程序从配置文件中读取这些属性。如果程序日后需要改为访问其他数据库,那么只需要修改配置文件,而不需要改动程序代码。
假定在db.conf配置文件中具有以下内容:

下面的PropertyReader是一个实用类,它从db.conf文件中读取各种属性:
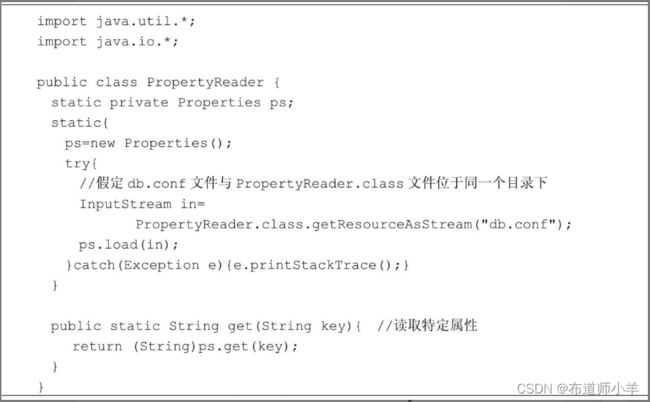
4.3、管理Connection、Statement和ResultSet对象的生命周期
一个Connection对象可以创建一个或一个以上的Statement对象。不过,大多数数据库系统都限制了一个Connection对象允许同时打开的Statement对象的数目。这个限制数目可通过DatabaseMetaData类的getMaxStatements()方法来获取。
提示:Connection、Statement和ResultSet对象被创建后,就处于打开状态,只有在这个状态下,程序才可以通过它们来访问数据库。当程序调用了它们的close()方法,它们就被关闭,或者说进入了关闭状态。这些对象被关闭后就不能再用来访问数据库。
一个Statement对象可以执行多条SQL语句。但一个Statement对象同一时刻只能打开一个ResultSet对象。在以下代码中,一个Statement对象先后打开两个结果集,这是合法的:

当第2次执行stmt.executeQuery()方法时,该方法会自动把第1个ResultSet对象关闭。为了提高程序代码的可阅读性,建议显式地关闭不再使用的ResultSet对象:
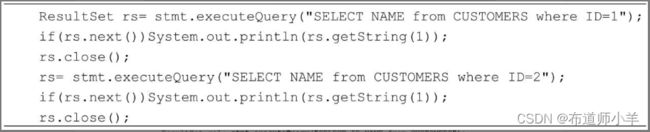
以下程序代码试图查询拥有订单的客户的所有订单信息:

以上第1个while循环用来遍历第1个rs1对象,在这个while循环中又调用stmt.executeQuery()方法得到一个rs2对象,stmt.executeQuery()方法会自动关闭第1个rs1对象。因此当再次执行第1个while循环的循环条件中的rs1.next()方法时,该方法会抛出SQLException。

正确的做法是用两个Statement对象来分别同时打开两个ResultSet对象:

以上代码的打印结果如下:

以上代码尽管能正常运行,但是需要多次向数据库提交SQL语句。程序频繁地访问数据库,这是降低程序运行性能的重要原因。为了减少程序向数据库提交SQL语句,可以使用表连接查询语句。以下程序代码只需要向数据库提交一条查询语句,就能完成同样的任务,它具有更好的运行性能:
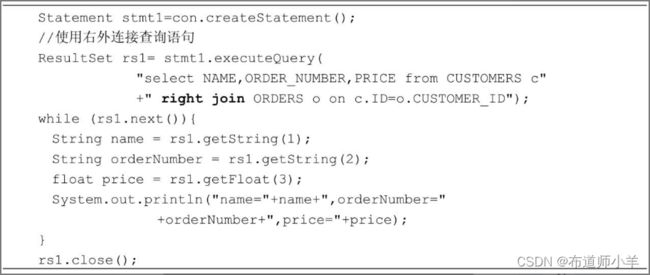
ResultSet、Statement和Connection都有close()方法,它们的作用如下:
- ResultSet的close()方法:释放结果集占用的资源。当ResultSet对象被关闭后,就不允许程序再访问它曾经包含的查询结果,不允许调用它的next()和getXXX()等方法。
- Statement的close()方法:释放Statement对象占用的资源。关闭Statement对象时,与它关联的ResultSet对象也被自动关闭。当Statement对象被关闭后,就不允许通过它执行任何SQL语句。
- Connection的close()方法:释放Connection对象占用的资源,断开数据库连接。关闭Connection对象时,与它关联的所有Statement对象也被自动关闭。当Connection对象被关闭后,就不允许通过它创建Statement对象。
由于ResultSet、Statement和Connection都会占用较多系统资源,因此当程序用完这些对象后,应该立即调用它们的close()方法关闭它们。当关闭Connection对象时,与它关联的所有Statement对象以及ResultSet对象也被自动关闭,但通常这3种对象的生命周期不一样,在一般情况下,ResultSet对象的生命周期最短,Statement对象的生命周期略长一些,Connection对象的生命周期最长。为了避免潜在的错误,提高程序代码的可读性,应该养成在程序中显式关闭ResultSet、Statement和Connection对象的习惯。
3.4、执行SQL脚本文件
Statement接口的execute(String sql)方法能够执行各种SQL语句。该方法返回一个boolean类型的值,如果返回值为true,就表明执行的SQL语句具有查询结果集,此时可以调用Statement的getResultSet()方法获得相应的ResultSet对象。
如下图所示,ResultSet对象包含的结果集是由行与列构成的二维表:
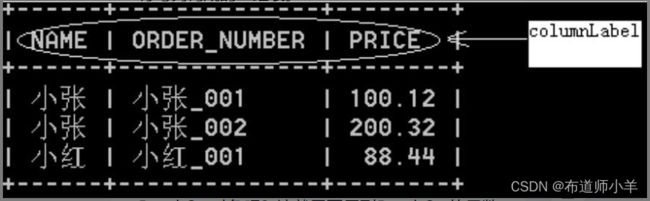
能否编写一个通用方法,它能遍历任何一个ResultSet对象呢?这就需要用到ResultSet的元数据,用ResultSetMetaData类表示,它用来描述一个结果集。ResultSetMetaData类具有以下方法:
- getColumnCount():返回结果集包含的列数。
- getColumnLabel(int i):返回结果集中第i列的字段名字。结果集中第1列字段的索引为1。
- getColumnType(int i):返回结果集中第i列的字段的SQL类型。结果集中第1列字段的索引为1。该方法返回一个int类型的数字,表示SQL类型。在java.sql.Types类中定义了一系列表示SQL类型的静态常量,它们都是int类型的数据。例如Types.VARCHAR表示SQL中的VARCHAR类型,Types.BIGINT表示SQL中的BIGINT类型。
下面的SQLExecutor类能够执行schema.sql脚本文件中的所有SQL语句。如果执行的SQL语句为查询语句,就会调用showResultSet()方法打印结果集。

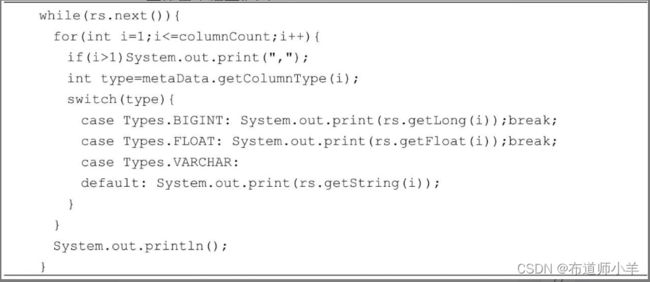
以上showResultSet()方法借助于ResultSetMetaData类,就能遍历任何一个结果集。对于结果集中每一行的每个字段,都通过rs.getString(i)方法获得字段值,如果字段不是字符串类型,那么rs.getString(i)方法会把它转换为字符串再将其返回。
以下程序代码在一个switch语句中罗列了结果集的各个字段可能的SQL类型,然后调用ResultSet对象的相应的getXXX()方法来获得字段值。
3.5、处理SQLException
JDBC API中的多数方法都会声明抛出SQLException。SQLException类具有以下获取异常信息的方法:
- getErrorCode():返回数据库系统提供的错误编号。
- getSQLState():返回数据库系统提供的错误状态。
当数据库系统执行SQL语句失败,就会返回错误编号和错误状态信息。下面的ExceptionTester类演示了如何处理SQLException:

运行以上程序,将打印如下信息:

以上错误信息实际上是由数据库系统产生的,JDBC实现把这些错误信息存放到SQLException对象中。
SQLException还有一个子类SQLWarning,它表示访问数据库时产生的警告信息。警告不会影响程序的执行流程,程序也无法在catch语句中捕获到SQLWarning。程序可通过Connection、Statement和ResultSet对象的getWarnings()方法来获得SQLWarning对象。SQLWarning采用串联模式,它的getNextWarning()方法返回后续的SQLWarning对象。
3.6、输出JDBC日志
在默认情况下,JDBC实现不会输出任何日志信息。在程序开发阶段,为了便于调试访问数据库的代码,可以让JDBC实现输出日志。只要在程序开头通过DriverManager类的静态setLogWriter(Writer o)方法设置日志输出目的地,就能启用这一功能。
以下代码使得JDBC实现把日志输出到控制台:
DriverManager.setLogWriter(new PrintWriter(System.out,true));
到了产品发布阶段,为了提高程序的运行性能,建议禁用输出日志的功能。
3.7、获得新插入记录的主键值
许多数据库系统能够自动为新插入记录的主键赋值。在MySQL中,只要把表的主键定义为auto_increment类型,那么当新插入的记录没有被显式设置主键值时,数据库就会按照递增的方式给主键赋值。CUSTOMERS表的ID主键就是auto_increment类型。
![]()
下面的GetKey类演示如何在程序中获得数据库系统自动生成的主键值:
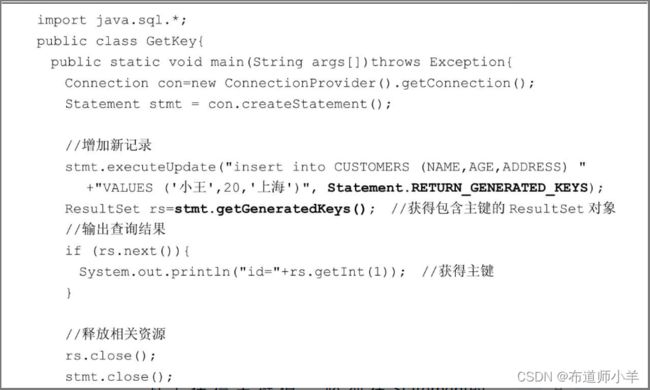
为了获得主键值,必须在Statement的executeUpdate()方法中设置Statement.RETURN_GENERATED_KEYS参数,接着通过Statement的getGeneratedKeys()方法就能得到包含主键值的ResultSet对象。
3.8、设置批量抓取属性
以下代码查询CUSTOMERS表中的所有记录:

假如CUSTOMERS表中有100000条记录,那么Statement对象的executeQuery()方法返回的ResultSet对象中是否会立即存放这100000条记录呢?假如ResultSet对象中存放了这么多记录,那将消耗多大内存空间啊。幸运的是,ResultSet对象实际上并不会包含这么多数据,只有当程序遍历结果集时,ResultSet对象才会到数据库中抓取相应的数据。ResultSet对象抓取数据的过程对程序完全是透明的。
那么,是否每当程序访问结果集中的一条记录时,ResultSet对象都到数据库中抓取一条记录呢?按照这种方式抓取大量记录需要频繁地访问数据库,显然效率很低。为了减少访问数据库的次数,JDBC希望ResultSet接口的实现能支持批量抓取,即每次从数据库中抓取多条记录,都把它们存放在ResultSet对象的缓存中,让程序慢慢享用。在Connection、Statement和ResultSet接口中都提供了以下方法:
- setFetchSize(int size):设置批量抓取的数目。
- setFetchDirection(int direction):设置批量抓取的方向。参数direction有3个可选值:ResultSet.FETCH_FORWARD(单向)| ResultSet.FETCH_REVERSE(双向)| ResultSet.FETCH_UNKNOWN(未知);
其中Connection接口中的setFetchXXX()方法决定了由它创建的所有Statement对象的默认抓取属性,Statement接口中的setFetchXXX()方法决定了由它创建的所有ResultSet对象的默认抓取属性,而ResultSet接口中的setFetchXXX()方法仅仅决定当前ResultSet对象的抓取属性。
另外要注意的是,setFetchXXX()方法仅仅向JDBC驱动器提供了批量抓取的建议,JDBC驱动器有可能会忽略这个建议。
3.9、检测驱动器使用的JDBC版本
如果程序使用JDBC 4.0版本的API,而JDBC驱动器仅仅实现了JDBC 3.0或者更低版本的驱动器API,那么该驱动器就不可能实现JDBC 4.0中的所有接口。在这种情况下,当程序调用一些实际上未实现的接口时会出错。在程序中,可以通过DatabaseMetaData类的getJDBCMajorVersion()和getJDBCMinorVersion()方法来检测驱动器所用的JDBC版本。
3.10、元数据
在SQL中,用来描述数据库及其组成部分的数据被称为元数据(Meta Data)。元数据可以提供数据库结构和表的详细信息。在开发应用软件时,通常开发人员已经事先知道了数据库的结构,因此元数据的作用不是非常大。而对于数据库工具软件,这些软件必须能够连接任何未知的数据库,因此必须依靠元数据来了解数据库的结构。下图展示了一个名为DataGram管理工具的界面,从图中可以看出,该工具不仅能够列出数据库中所有表的名字,还能显示每张表的结构。
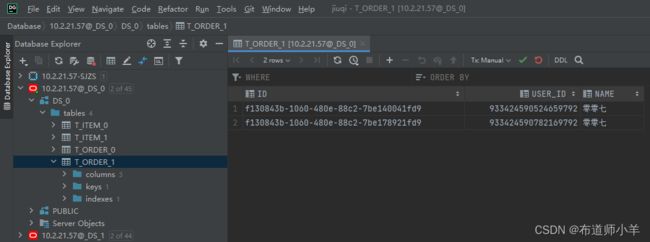
在JDBC API中,DatabaseMetaData和ResultSetMetaData接口分别表示数据库和结果集的元数据。Connection接口的getMetaData()方法返回一个DatabaseMetaData对象,表示所连接数据库的元数据。ResultSet接口的getMetaData()方法返回一个ResultSetMetaData对象,表示相应结果集的元数据。
提示:ParameterMetaData接口也是元数据接口,它用于描述预准备SQL语句中的参数,PreparedStatement的getParameterMetaData()方法返回一个ParameterMetaData对象。
介绍DatabaseMetaData接口的用法,该接口主要包括以下方法:
(1)getTables()方法:返回数据库中符合参数给定条件的所有表。该方法的完整的定义如下。

getTables()方法的各个参数的含义如下:
- ·catalog:指定表所在的目录,如果不限制表所在的目录或者底层数据库不支持目录,则把参数设为null。
- schemaPattern:指定表所在的Schema,如果不限制表所在的Schema或者底层数据库不支持Schema,则把参数设为null。
- tableNamePattern:指定表名必须匹配的字符串模式。如果把该参数设为null,则表示不对表名作任何限制。
- types:指定表的类型。表的类型可以包括:“TABLE”“VIEW”“SYSTEM TABLE”“GLOBAL TEMPORARY”“LOCAL TEMPORARY”“ALIAS”和“SYNONYM”等。以下getTables()方法返回数据库中的所有视图和表的信息。

getTables()方法返回一个ResultSet对象,对于JDBC 4.0,这个ResultSet对象包括10个字段(即10列),以下是部分字段的含义: - TABLE_CAT:第1个字段,表示表的目录,可以为null。
- TABLE_SCHEM:第2个字段,表示表的Schema,可以为null。
- TABLE_NAME:第3个字段,表示表的名字。
- TABLE_TYPE:第4个字段,表示表的类型。
- REMARKS:第5个字段,表示表的注释。
(2)getJDBCMajorVersion()和getJDBCMinorVersion()方法:返回int类型的数值,分别表示驱动器使用的JDBC的主版本号和次版本号。例如JDBC3.1的主版本号为3,次版本号为1。
(3)getMaxConnections():返回int类型的数值,表示数据库允许同时建立的连接的最大数目。如果对此没有限制或者未知,则返回0。
(4)getMaxStatements():返回int类型的数值,表示一个Connection对象允许同时打开的Statement对象的最大数目。如果对此没有限制或者未知,则返回0。
(5)supportsXXX():判断驱动器或者底层数据库系统是否支持某种特性。例如supportsOuterJoins()方法判断数据库是否支持外连接,supportsGroupBy()方法判断数据库是否支持group by语句。
下面的ShowDB类演示了DatabaseMetaData类的用法。
4、可滚动以及可更新的结果集
ResultSet对象所包含的结果集中往往有多条记录,如下图所示,ResultSet用游标(相当于指针)来定位记录。
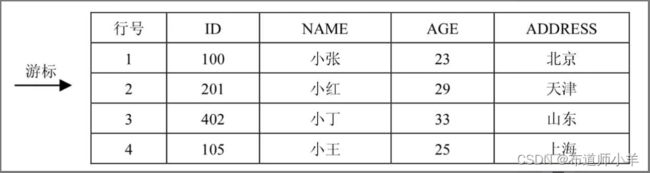
在默认情况下,结果集的游标只能从上往下移动。只要调用ResultSet对象的next()方法,就能使游标下移一行,当到达结果集的末尾,next()方法就会返回false,否则返回true。此外,在默认情况下,只能对结果集执行读操作,不允许更新结果集的内容。
提示:结果集的开头指第1条记录的前面位置,这是游标的初始位置。结果集的末尾指最后一条记录的后面位置。
在实际应用中,我们往往希望能在结果集中上下移动游标,并且希望能更新结果集的内容。为了获得可滚动或者可更新的ResultSet对象,需要通过Connection接口的以下方法构造Statement或者PreparedStatement对象:

以上type和concurrency参数决定了由Statement或PreparedStatement对象创建的ResultSet对象的特性。type参数有以下可选值:
- ResultSet.TYPE_FORWARD_ONLY:游标只能从上往下移动,即结果集不能滚动。这是默认值。
- ResultSet.TYPE_SCROLL_INSENSITIVE:游标可以上下移动,即结果集可以滚动。当程序对结果集的内容做了修改时,游标对此不敏感。
- ResultSet.TYPE_SCROLL_SENSITIVE:游标可以上下移动,即结果集可以滚动。当程序对结果集的内容做了修改时,游标对此敏感。比如当程序删除了结果集中的一条记录时,游标位置会随之发生变化。
concurrency参数有以下可选值:
- CONCUR_READ_ONLY:结果集不能被更新。
- CONCUR_UPDATABLE:结果集可以被更新。
例如,按照以下方式创建的结果集可以滚动,但不能被更新:

例如,按照以下方式创建的结果集可以滚动,并且可以被更新:

值得注意的是,即使在创建Statement或PreparedStatement时把type和concurrency参数分别设为可滚动和可更新的,但实际上得到的结果集有可能仍然不被允许滚动或更新,这有两方面的原因:
- 底层JDBC驱动器有可能不支持可滚动或可更新的结果集。程序可以通过DatabaseMetaData类的supportsResultSetType()和supportsResultSetConcurrency()方法,来了解驱动器所支持的type和concurrency类型。
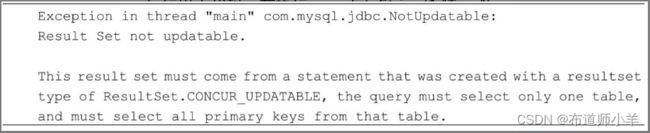
- 某些查询语句的结果集不允许被更新。例如JDBC规范规定,只有对一张表查询,并且查询字段包含表中的所有主键,这样的查询语句的结果集才可以被更新。以下程序代码中的查询语句涉及了表的连接查询。

运行以上代码,在执行rs.updateString(1,“Tom”)方法时会抛出以下异常:
Java程序可以通过ResultSet类的getType()和getConcurrency()方法,来了解查询结果集实际上支持的type和concurrency类型。例如:
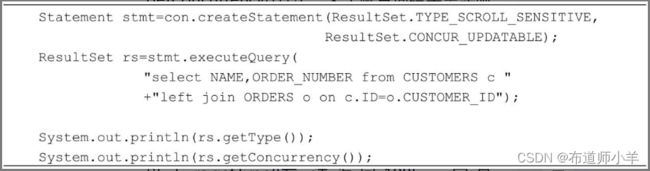
以上rs.getType()方法返回1005,它是ResultSet.TYPE_SCROLL_SENSITIVE的值,rs.getConcurrency()方法返回1007,它是ResultSet.CONCUR_READ_ONLY的值。由此看出,以上结果集允许滚动,但不允许更新。
ResultSet接口提供了一系列用于移动游标的方法:
- irst():使游标移动到第1条记录。
- last():使游标移动到最后一条记录。
- beforeFirst():使游标移动到结果集的开头。
- afterLast():使游标移动到结果集的末尾。
- previous():使游标从当前位置向上(或者说向前)移动一行。
- next():使游标从当前位置向下(或者说向后)移动一行。
- relative(int n):使游标从当前位置移动n行。如果n>0,就向下移动,否则就向上移动。当n为1时,等价于调用next()方法;当n为-1时,等价于调用previous()方法。
- absolute(int n):使游标移动到第n行。参数n指定游标的绝对位置。
在使用以上方法时,有以下注意事项:
- 除了beforeFirst()和afterLast()方法返回void类型,其余方法都返回boolean类型,如果游标移动到的目标位置到达结果集的开头或结尾,就返回false,否则返回true。
- 只有当结果集可以滚动时,才可以调用以上所有方法。如果结果集不可以滚动,则只能调用next()方法,当程序调用其他方法时,这些方法会抛出SQLException。
ResultSet接口的以下方法判断游标是否在特定位置:
- isFirst():判断游标是否在第1行。
- isLast():判断游标是否在最后一行。
- isBeforeFirst():判断游标是否在结果集的开头。
- isAfterLast():判断游标是否在结果集的末尾。
此外,ResultSet类的getRow()方法返回当前游标所在位置的行号。
对于可更新的结果集,允许对它进行插入、更新和删除的操作。以下结果集包含了CUSTOMERS表中的所有记录:

下面分别介绍如何在结果集中插入、更新和删除记录:
(1)插入记录:

ResultSet接口的moveToInsertRow()方法把游标移动到特定的插入行。值得注意的是,程序无法控制在结果集中添加新记录的位置,因此新记录到底插入哪一行对程序是透明的。ResultSet接口的insertRow()方法会向数据库中插入记录。ResultSet接口的moveToCurrentRow()方法把游标移动到插入前的位置,即调用moveToInsertRow()方法前所在的位置。
(2)更新记录:

ResultSet接口的updateRow()方法会更新数据库中的相应记录。
(3)删除记录:
![]()
ResultSet接口的deleteRow()方法会删除数据库中的相应记录。
5、行集
可滚动的ResultSet对象尽管便于用户操纵结果集,但是有一个很大的缺陷,那就是在结果集打开期间,必须始终与数据库保持连接。如果用户在通过图形界面操纵结果集的过程中,忽然离开电脑很长一段时间,那么该程序仍然占用着数据库连接。在多用户环境中,数据库连接是有限的系统资源,许多数据库系统为了防止超负荷,限制了并发连接数,程序可通过DatabaseMetaData类的getMaxConnections()方法来获得数据库允许的最大并发连接数。
为了更有效地使用数据库连接,JDBC API提供了另一个用于操纵查询结果的行集接口:javax.sql.RowSet。RowSet接口继承了ResultSet接口,因此RowSet接口也能操纵查询结果,此外,RowSet接口具有以下特性:
- 它的CachedRowSet子接口无须始终与数据库保持连接。
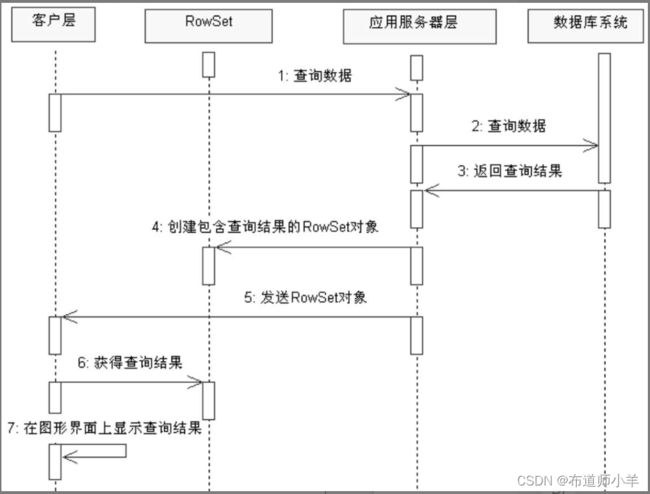
- RowSet对象的数据结构没有ResultSet对象那么庞大,并且RowSet对象不依赖于数据库连接,因此在分层的软件应用中,可以方便地把RowSet对象移动到其他层。如下图所示,在应用服务器层创建了一个RowSet对象,它包含了某种查询结果。该RowSet对象被传到客户层,在图形用户界面上展示给用户。
- RowSet对象表示的行集总是可以滚动的。
如下图所示,RowSet接口有若干子接口,它们都位于javax.sql.rowset包中:
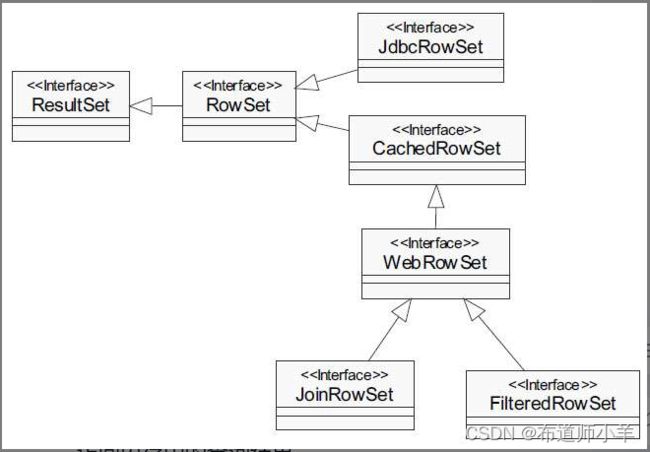
- CachedRowSet接口:被缓存的行集,查询结果被保存到内存中,允许在断开数据库连接的情况下访问内存中的查询结果。
- WebRowSet接口:被缓存的行集,并且行集中的查询结果可以被保存到一个XML文件中。这个XML文件可以被发送到Web应用的其他层,在其他层中再把XML文件中的查询结果加载到一个WebRowSet对象中。
- FilteredRowSet和JoinRowSet接口:被缓存的行集,并且支持对行集的轻量级操作。其中FilteredRowSet能够根据设置条件得到查询结果的子集;JoinRowSet能够将几个RowSet对象用SQL join语句进行连接。
- JdbcRowSet接口:ResultSet接口的瘦包装器,JdbcRowSet接口从RowSet接口中继承了get和set方法,从而将一个结果集转换为一个JavaBean。
Oracle公司希望数据库供应商为上述接口提供高性能的实现,此外,JDK为这些接口提供了参考实现,它们都位于com.sun.rowset包中,实现类都以Impl结尾,例如CachedRowSet接口的参考实现类为com.sun.rowset.CachedRowSetImpl。JDK自带了这些参考实现的类库。有了这些参考实现,即使数据库供应商不支持RowSet接口,也能在程序中使用它们。
6、调用存储过程
java.sql.CallableStatement接口用来执行数据库中的存储过程。Connection的prepareCall()方法创建一个CallableStatement对象。假设MySQL数据库中有一个名为demoSp的存储过程,它的定义如下:

以上存储过程有两个参数,第1个参数inputParam是VARCHAR类型,并且是输入(IN)参数,第2个参数inOutParam是INT类型,并且是输入输出(INOUT)参数。对于输入输出参数,调用者既可以向存储过程传入参数值,也可以在存储过程执行完毕后读取被更新的参数值。下面的ProcedureTester类演示了如何调用该存储过程:

创建CallableStatement对象的代码如下:
![]()
以上两个问号分别代表存储过程的两个参数。可通过以下两种方式为参数赋值:

第2个参数为输入输出参数,为了获得它的输出值,必须先通过CallableStatement 的registerOutParameter()方法注册参数的类型,然后就可以在存储过程执行完毕后通过相应的getXXX()方法获得它的输出值。
7、处理Blob和Clob类型数据
在数据库中有两种特殊的SQL数据类型:
- Blob(Binary large object):存放大容量的二进制数据。
- Clob(Character object):存放大容量的由字符组成的文本数据。
假设数据库的一张表中有一个名为FILE的字段,该字段为Blob类型,这张表的某条记录的FILE字段存放了100MB的数据。如何通过JDBC API来读取这个字段呢?很简单,只要调用ResultSet对象的getBlob()方法就可以了。

ResultSet对象的getBlob()方法返回一个Blob对象。值得注意的是,Blob对象中并不包含FILE字段的100MB数据。事实上这是行不通的,因为如果把数据库中100M或者更大的数据全部加载到内存中,则会导致内存空间不足。Blob对象实际上仅仅持有数据库中相应FILE字段的引用。
为了获取数据库中的Blob数据,可以调用Blob对象的getBinaryStream()方法获得一个输入流,然后从这个输入流中读取Blob数据。以下程序代码把数据库中的Blob数据拷贝到一个文件中。
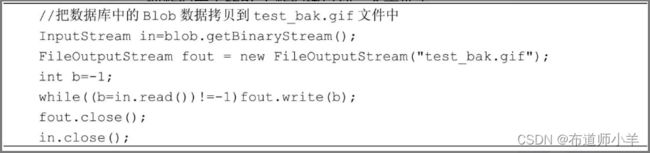
如下图所示,数据库中的Blob数据由输入流逐字节读入内存中,再由文件输出流逐个写到文件中。在数据运输路途上,内存中的Blob对象充当数据库中Blob数据与test_bak.gif文件之间的中转站。
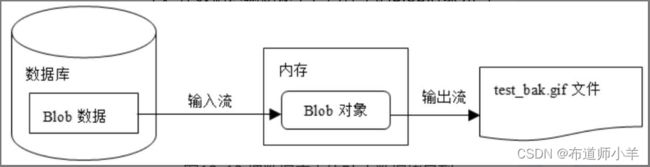
如果希望进一步提高性能,则可以调用InputStream的read(byte[] buff)和OuputStream的write(byte[] buff,int offset,int length)方法,批量读入和写出字节。

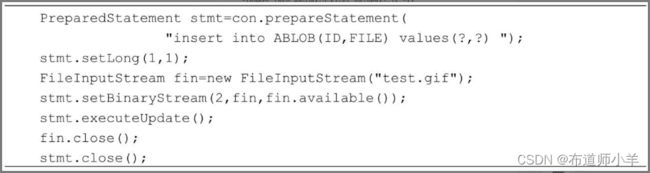
PreparedStatement的setBinaryStream()方法向数据库中写入Blob数据,该方法的定义如下:

以上InputStream类型的参数指定Blob数据源,参数length指定Blob数据的字节数。以下代码把test.gif文件中的二进制数据保存到数据库中。
MySQL 中的 Blob 数据被分为4种类型:TINYBLOB(容量为256字节)、BLOB(容量为64KB)、MEDIUMBLOB (容量为16MB)和LONGBLOB (容量为4GB)。在创建表时,应该根据实际要存放的数据的大小,选择合适的Blob类型。如果实际存放的数据的大小超过特定Blob数据类型的容量,那么多余的数据会被丢弃。
Clob数据的处理方式与Blob数据很相似。JDBC API中处理Clob数据的方法包括以下几种:
- ResultSet接口的getClob()方法:从结果集中获得Clob对象。
- Clob接口的getCharacterStream()方法:返回一个Reader对象,用于读取Clob数据中的字符。
- PreparedStatement接口的setCharacterStream()方法:向数据库中写入Clob数据。它的完整的定义如下:
void setCharacterStream(int parameterIndex, Reader reader, int length) throws SQLException;
以上Reader类型的参数指定Clob数据源,参数length指定Clob数据的字节数。
8、控制事务
事务指一组相互依赖的操作行为。只有事务中的所有操作成功,才意味着整个事务成功,只要有一个操作失败,就意味着整个事务失败。在数据库系统中,事务实际上是一组SQL语句,这些SQL语句通常会涉及更新数据库中的数据的操作。数据库系统会保证只有当事务执行成功时,才会永久保存事务对数据库所做的更新,如果事务执行失败,就会使数据库系统回滚到执行事务前的初始状态。
Java程序作为数据库系统的客户程序,需要告诉数据库系统,事务什么时候开始,事务包括哪些操作,以及事务何时结束。数据库系统就会处理由Java程序指定的事务。
8.1、事务的概念简介
数据库事务必须具备ACID特征,ACID是Atomic(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性)的英文缩写。下面解释这几个特性的含义:
- 原子性:指整个数据库事务是不可分割的工作单元。只有事务中所有的操作执行成功,才算整个事务成功;事务中任何一个SQL语句执行失败,已经执行成功的SQL语句也必须撤销,数据库状态应该退回执行事务前的状态。
- 一致性:指数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。例如对于银行转账事务,不管事务成功还是失败,应该保证事务结束后ACCOUNTS表中Tom和Jack的存款总额为2000元。
- 隔离性:指在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。
- 持久性:指只要事务成功结束,它对数据库所做的更新就必须被永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
事务的ACID特性是由关系数据库管理系统(RDBMS,也简称为数据库系统)来实现的。数据库管理系统采用日志来保证事务的原子性、一致性和持久性。日志记录了事务对数据库所做的更新,如果某个事务在执行过程中发生错误,就可以根据日志,撤销事务对数据库已做的更新,使数据库退回到执行事务前的状态。
数据库管理系统采用锁机制来实现事务的隔离性。当多个事务同时更新数据库中相同的数据时,只允许持有锁的事务更新该数据,其他事务必须等待,直到前一个事务释放了锁,其他事务才有机会更新该数据。
8.2、声明事务边界的概念
数据库系统的客户程序只要向数据库系统声明了一个事务,数据库系统就会自动保证事务的ACID特性。声明事务包含以下内容:
- 事务的开始边界。
- 事务的正常结束边界(COMMIT):提交事务,永久保存事务被更新后的数据库状态。
- 事务的异常结束边界(ROLLBACK):撤销事务,或者说回滚事务,使数据库退回到执行事务前的状态。
下图显示了数据库事务的生命周期。当一个事务开始后,要么以提交事务结束,要么以撤销事务结束:
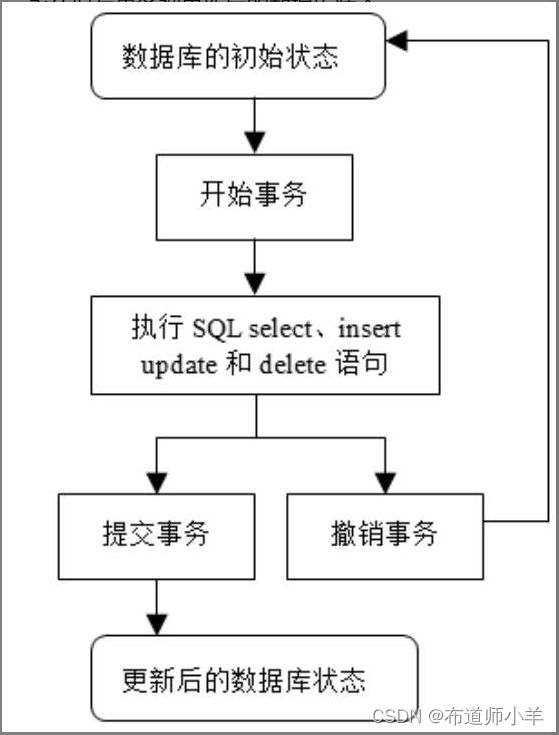
数据库系统支持两种事务模式:
- 自动提交模式:每个SQL语句都是一个独立的事务,当数据库系统执行完一个SQL语句后,会自动提交事务。
- 手工提交模式:必须由数据库的客户程序显式指定事务开始边界和结束边界。
在MySQL中,数据库表分为3种类型:INNODB、BDB和MyISAM。其中INNODB和BDB类型的表支持数据库事务,而MyISAM类型的表不支持事务。在MySQL中用create table语句新建的表被默认为MyISAM类型。如果希望创建INNODB类型的表,那么可以采用以下形式的DDL语句:

对于已存在的表,可以采用以下形式的DDL语句修改它的表类型:
![]()
提示:对于MySQL数据库,所谓INNODB类型的表支持事务,指支持把多条SQL语句声明为一个事务,并且支持对事务的撤销。所谓MyISAM类型的表不支持事务,指不支持把多条SQL语句声明为一个事务,并且不支持对事务的撤销。如果对MyISAM类型的表进行添加、更新和删除记录的SQL操作,每一条SQL语句都相当于一个独立的事务,执行完后就立刻提交,不能再撤销。
8.3、在mysql.exe程序中声明事务
每启动一个mysql.exe程序,就会得到一个单独的数据库连接。每个数据库连接都有1个全局变量@@autocommit,表示当前的事务模式,它有两个可选值:
- 0:表示手工提交模式。
- 1:默认值,表示自动提交模式。
如果要查看当前的事务模式,那么可使用如下SQL命令:select @@autocommit
如果要把当前的事务模式改为手工提交模式,那么可使用如下SQL命令:set autocommit=0
8.4、通过JDBC API声明事务边界
Connection接口提供了以下用于控制事务的方法:
- setAutoCommit(boolean autoCommit):设置是否自动提交事务。
- commit():提交事务。
- rollback():撤销事务。
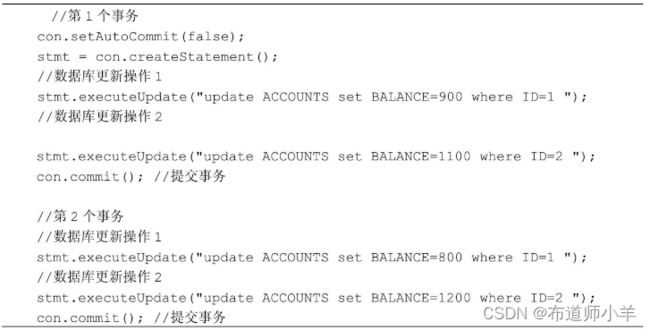
对于新建的Connection对象,在默认情况下采用自动提交事务模式。可以通过setAutoCommit(false)方法来设置手工提交事务模式,然后就可以把多条更新数据库的SQL语句作为一个事务,在所有操作完成后调用commit()方法来整体提交事务,倘若其中一项SQL操作失败,那么程序会抛出相应的SQLException,此时应该在捕获异常的代码块中调用rollback()方法撤销事务。示例如下:

当一个事务被提交后,再通过这个连接执行其他SQL语句,实际上就开始了一个新的事务,例如:
8.5、保存点
调用Connection的rollback()方法会撤销整个事务。如果只希望撤销事务中的部分操作,那么可以在事务中加入保存点。如下图所示:

某个事务包括5个操作,在操作1后面设置了保存点A,在操作3后面设置了保存点B。如果在执行完操作4后,把事务回滚到保存点B,那么会撤销操作4对数据库所做的更新。如果在执行完操作5后,把事务回滚到保存点A,那么会撤销操作5、操作4、操作3和操作2对数据库所做的更新。
Connection接口的setSavepoint()方法用于在事务中设置保存点,它有两种重载形式:
Savepoint setSavepoint() throws SQLException;
Savepoint setSavepoint(String var1) throws SQLException;
以上第1个不带参数的setSavepoint()方法设置匿名的保存点,第2个setSavepoint(String name)方法的name参数表示保存点的名字。这两个setSavepoint()方法都会返回一个表示保存点的Savepoint对象。
Connection接口的releaseSavepoint(Savepoint point)方法取消已经设置的保存点。Connection接口的rollback(Savepoint point)方法使事务回滚到参数指定的保存点。
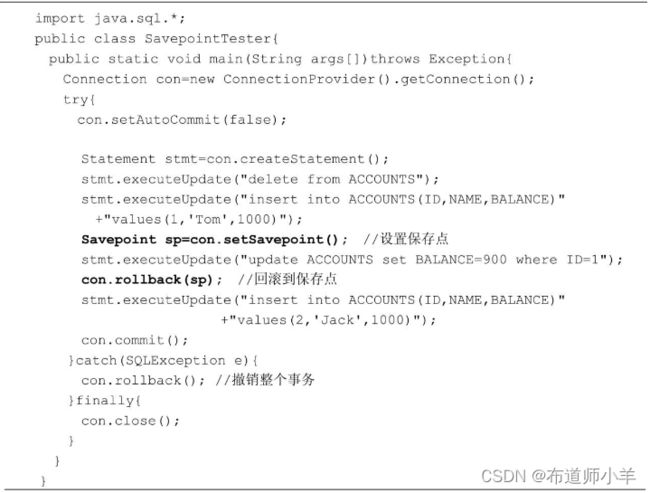
以上程序运行结束后,ACCOUNTS表中有两条记录,它们的BALANCE字段的值都为1000。由此可见,“update ACCOUNTS set BALANCE=900where ID=1”这条语句被撤销。
值得注意的是,并不是所有的JDBC驱动器都支持保存点,DatabaseMetaData接口的supportsSavepoints()方法判断驱动器是否支持保存点,如果返回false,就表示不支持保存点。如果JDBC驱动器不支持保存点,那么Connection接口的setSavepoint()方法会抛出以下异常。

8.6、批量更新
有时,程序需要向数据库插入、更新或删除大批量数据。例如以下SQL语句向ACCOUNTS表插入大批量数据:

从JDBC2.0开始,允许用批量更新的方式来执行大批量操作,它能提高操纵数据库的效率。在Statement接口中提供了支持批量更新的两个方法:
- addBatch(String sql):加入一条SQL语句。
- executeBatch():执行批量更新。前面已经讲过,Statement接口的executeUpdate(String sql)方法返回一个整数,表示数据库中受SQL语句影响的记录数。而executeBatch()方法则返回一个int数组,数组中的每个元素分别表示受每条SQL语句影响的记录数。
使用批量更新有以下注意事项:
- 必须把批量更新中的所有操作放在单个事务中。
- 批量更新中可以包括SQL update、delete和insert语句,还可以包括数据库定义语句,如CREATE TABLE和DROP TABLE语句等,但不能包括select查询语句,否则Statement的executeBatch()方法会抛出BatchUpdateException。
- 并不是所有的JDBC驱动器都支持批量更新,DatabaseMetaData接口的supportsBatchUpdates()方法判断驱动器是否支持批量更新,如果返回false,就表示不支持批量更新。如果JDBC驱动器不支持批量更新,那么Statement的executeBatch()方法会抛出BatchUpdateException。
以上BatchUpdateException是SQLException的子类,BatchUpdateException还有个getUpdateCounts()方法,返回一个int类型的数组,数组中的元素分别表示受已经执行成功的每条SQL语句影响的记录数。
8.7、设置事务隔离级别
在多用户环境中,如果多个事务同时操纵数据库中的相同数据,就会导致各种并发问题。为了避免这些并发问题,数据库提供了4种事务隔离级别:
- Serializable:串行化。
- Repeatable Read:可重复读。
- Read Commited:读已提交数据。
- Read Uncommited:读未提交数据。
数据库系统采用不同的锁类型来实现以上4种隔离级别,具体的实现过程对用户是透明的。用户应该关心的是如何选择合适的隔离级别。在4种隔离级别中,Serializable的隔离级别最高,Read Uncommited的隔离级别最低,下表列出了各种隔离级别所能避免的并发问题:
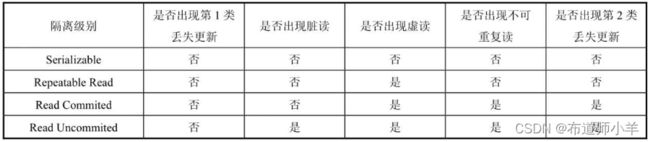
1.Serializable(串行化)
当数据库系统使用Serializable隔离级别时,一个事务在执行过程中完全看不到其他事务对数据库所做的更新。当两个事务操纵数据库中相同数据时,如果第1个事务已经在访问该数据,那么第2个事务只能停下来等待,直到第1个事务结束后才能恢复运行。因此这两个事务实际上以串行化方式运行。
2.Repeatable Read(可重复读)
当数据库系统使用Repeatable Read隔离级别时,一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,但是不能看到其他事务对已有记录的更新。
3.Read Committed(读已提交数据)
当数据库系统使用Read Committed隔离级别时,一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,而且能看到其他事务已经提交的对已有记录的更新。
4.Read Uncommitted(读未提交数据)
当数据库系统使用Read Uncommitted隔离级别时,一个事务在执行过程中可以看到其他事务没有提交的新插入的记录,而且能看到其他事务没有提交的对已有记录的更新。
隔离级别越高,越能保证数据库中数据的完整性和一致性,但是对并发性能的影响也越大,下图显示了隔离级别与并发性能的关系:
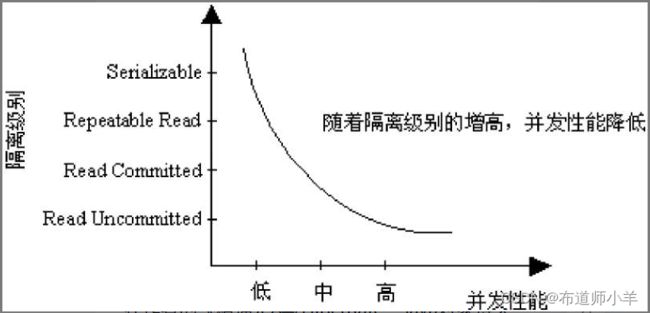
对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed,它能够避免脏读,而且具有较好的并发性能。尽管它会导致不可重复读、虚读和第2类丢失更新这些并发问题,但是在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁机制来控制。
Connection接口的setTransactionIsolation(int level)用来设置数据库系统使用的隔离级别,这种设置只对当前的连接有效。参数level有以下可选值:
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executor;
public interface Connection extends Wrapper, AutoCloseable {
int TRANSACTION_NONE = 0;
int TRANSACTION_READ_UNCOMMITTED = 1;
int TRANSACTION_READ_COMMITTED = 2;
int TRANSACTION_REPEATABLE_READ = 4;
int TRANSACTION_SERIALIZABLE = 8;
..........
}
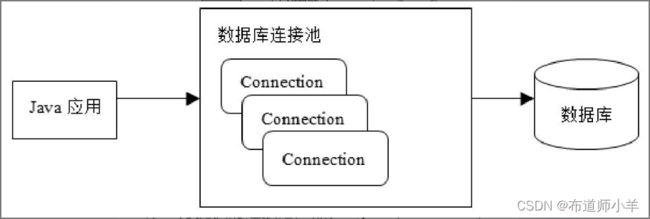
9、数据库连接池
建立一个数据库连接需要消耗大量系统资源,频繁地创建数据库连接会大大削弱应用访问数据库的性能。为了解决这一问题,数据库连接池应运而生。数据库连接池的基本实现原理是:事先建立一定数量的数据库连接,这些连接被存放在连接池中,当Java应用执行一个数据库事务时,只需从连接池中取出空闲的数据库连接;当Java应用执行完事务,再将数据库连接放回连接池。下图展示了数据库连接池的作用:
那么Java应用从何处获得数据库连接池呢?一种办法是从头实现自己的连接池,还有一种办法是使用第三方提供的连接池产品。Agroal、HikariCP、Vibur DBCP、Apache DBCP、C3P0、Proxool都是比较流行的开源连接池产品,详情可到产品官方网站进行了解。
各种连接池产品会使用不同的实现策略。总的说来,连接池需要考虑以下问题:
- (1)限制连接池中最多可以容纳的连接数目,避免过度消耗系统资源。
- (2)当客户请求连接,而连接池中所有的连接都已经被占用时,该如何处理?一种处理方式是让客户一直等待,直到有空闲连接,还有一种方式是为客户分配一个新的临时的连接。
- (3)当客户不再使用连接时,需要把连接重新放入连接池。
- (4)限制连接池中允许处于空闲状态的连接的最大数目。假定允许的最长空闲时间为10分钟,并且允许处于空闲状态的连接的最大数目为5,那么当连接池中有n个(n>5)连接处于空闲状态的时间超过10分钟时,就应该把其中n-5个连接关闭,并且从连接池中删除,这样才能更有效地利用系统资源。
9.1、创建连接池
下面的ConnectionPool是连接池的接口,它声明了取出连接、释放连接和关闭连接池的方法:
public interface ConnectionPool {
// 从连接池中取出连接
public Connection getConnection() throws SQlException;
// 把连接放回连接池
public void releaseConnection(Connection con) throws SQlException;
// 关闭连接池
public void close();
}
9.2、DataSource数据源
不同的连接池产品有不同的API。如果Java应用直接访问连接池的API,就会削弱Java应用与连接池之间的独立性,假如日后需要改用其他连接池产品,那么必须修改应用中所有访问连接池的程序代码。为了提高Java应用与连接池之间的独立性,Oracle公司制定了标准的javax.sql.DataSource 接口,它用于封装各种不同的连接池实现。凡是实现DataSource接口的连接池都被看作标准的数据源,可以作为JNDI资源发布到Java应用服务器(比如Java EE服务器)中。
下图展示了Java应用通过DataSource接口访问连接池的过程:
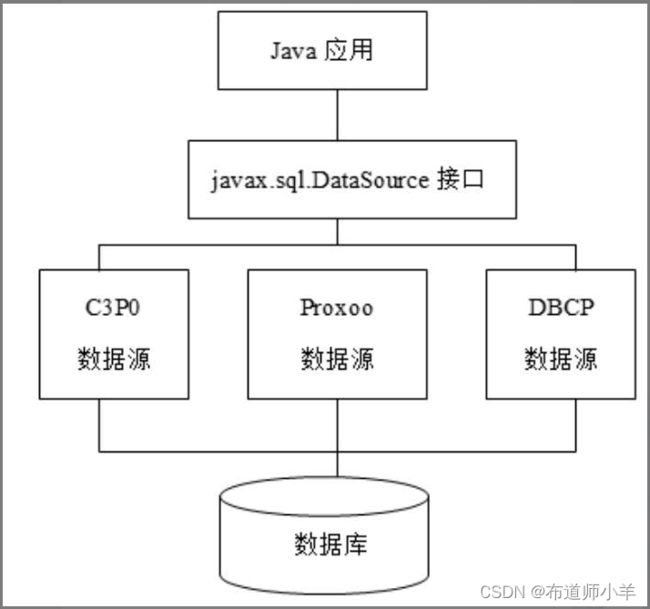
DataSource接口最主要的功能就是获得数据库连接,它的getConnection()方法提供这一服务:
package javax.sql;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.ConnectionBuilder;
import java.sql.SQLException;
import java.sql.SQLFeatureNotSupportedException;
import java.sql.Wrapper;
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String var1, String var2) throws SQLException;
PrintWriter getLogWriter() throws SQLException;
void setLogWriter(PrintWriter var1) throws SQLException;
void setLoginTimeout(int var1) throws SQLException;
int getLoginTimeout() throws SQLException;
default ConnectionBuilder createConnectionBuilder() throws SQLException {
throw new SQLFeatureNotSupportedException("createConnectionBuilder not implemented");
}
}
提示:DataSource接口并不强求其实现必须带有连接池,不过,多数DataSource实现都使用了连接池。
假定某种应用服务器发布了一个JNDI名字为“jdbc/SAMPLEDB”的数据源,Java应用通过JNDI API中的javax.naming.Context接口来获得这个数据源的引用。

得到了DataSource对象的引用后,就可以通过DataSource对象的getConnection()方法获得数据库连接对象Connection:
![]()
10、总结
大多数应用程序都需要访问数据库。据统计,在一个应用中,通过JDBC访问数据库的代码会占到30%左右。访问数据库的效率是决定程序的运行性能的关键因素之一。提高程序访问数据库的效率的总的原则是:减少建立数据库连接的次数,减少向数据库提交的SQL语句的数目,及时释放无用的Connection、Statement和ResultSet对象。
10.1、优化访问数据库代码的一些细节
1.选择合适的JDBC驱动器
一般说来,应该优先考虑使用第3类和第4类驱动器,它们具有更高的运行性能,只有在这两类驱动器不存在的情况下,才考虑用第1类和第2类驱动器作为替代品。
2.优化数据库连接
采用连接池来重用有限的连接,减少连接数据库的次数。
3.控制事务
如果事务中包含多个操作,则应该在手工提交模式下提交事务。此外,可通过Connection接口的setTransactionIsolation(int level)方法设置合适的事务隔离级别,如果希望应用程序有较好的并发性能,就要设置低一点的隔离级别。
4.优化Statement
如果一个SQL语句会被多次重复执行,那么应该使用PreparedStatement,而不是Statement。此外,对于大批量的更新数据库的操作,可以用Statement或者PreparedStatement来进行批量更新,与此相关的方法如下:
- addBatch(String):加入一个操作。
- executeBatch():执行批量更新操作。
5.优化ResultSet
优化ResultSet体现在以下几个方面:
- 通过ResultSet、Statement或者Connection的setFetchSize()方法,来设置合理的批量抓取数据库中数据的数目。
- 如果不需要对结果集滚动和更新,那么应该采用默认的不支持滚动和更新的结果集,因为这种类型的结果集占用较少的系统资源,运行速度更快。
- 在ResultSet的getXXX()或setXXX()方法中,指定字段的索引位置比指定字段的名字具有更好的性能,例如以下第1段程序代码的性能优于第2段代码。

- 优化查询语句,运用表连接把多个查询语句合并为一个查询语句,从而减少向数据库提交的查询语句的数目。
6.及时释放无用的资源
及时显式地关闭无用的ResultSet、Statement和Connection对象。
7.合理建立索引
索引是数据库中重要的数据结构,它的根本目的是提高查询效率。索引的使用要恰到好处,其使用原则如下:
- 为经常参与表连接,但是没有被指定为外键的字段建立索引。
- 为频繁参与排序或分组(即进行“group by”或“order by”操作)的字段建立索引。
- 在where条件表达式中,为具有多种取值的字段建立检索,不要为仅有少量取值的字段建立索引。假定CUSTONERS表具有NAME(姓名)字段和SEX(性别)字段,这两个字段都会经常出现在where条件表达式中。NAME字段有多种取值,而SEX字段只有“female”和“male”两种取值,因此只需为NAME字段建立索引,而没有必要为SEX字段建立索引。如果对仅有少量取值的字段建立索引,那么不但不会提高查询效率,还会严重降低更新数据的速度。
- 如果待排序的字段有多个,那么可以为这些字段建立复合索引(Compound Index)。