基于OpenCV的驾驶疲劳检测与预警系统设计
收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、研究背景与意义
- 二、相关技术分析
- 2.1 PyTorch
- 2.2 GUI
- 2.3 BERT模型
- 2.4 HOG算法
- 2.5 PERCLOS介绍
- 2.6 OpenCV
- 2.7 YOLOv5
- 三、训练设计
- 3.1图像集检测
- 3.2 YOLOv5训练
- 3.3 bert模型训练过程
- 四、系统详细设计
- 4.1总体功能结构设计
- 4.2面部疲劳状态检测流程
- 五、系统实现
- 5.1 app实现打开
- 5.2喝水检测
- 5.3玩手机检测
- 5.4抽烟检测
- 5.5疲劳状态检测
- 四、 文章目录
概要
随着交通工具的普及和道路网络的发展,交通事故已成为一个严重的社会问题。其中,驾驶疲劳是导致交通事故的主要原因之一。因此,开发一种有效的驾驶疲劳检测与预警系统对于提高交通安全水平具有重要意义。
本课题在选用的技术方面使用HOG算法,bert模型,以及YOLOv5进行疲劳训练检测,同时导入OpenCV视频模块进行设计。运用了dlib 库进行了面部欧式距离的节点进行设计, 使用PERCLOS模块进行疲劳程度的划分和检测。在计算眼部的疲劳程度中,使用了闭眼内的帧除以整个循环内的帧,并设置不同阈值来判断疲劳状态。运用PERCLOS设置状态,利用Hog算法检测面部68个节点。与此同时运用YOLOv5对抽烟、喝水、玩手机三种不同的状态进行训练,并且将其进行定义标签。最后将计算结果和训练结果写入GUI中进行检测和设置,在链接视频时使用OpenCV进行实时检测,然后利用前期的计算结果进行实时检测。
通过实验证明,本研究设计的驾驶疲劳检测与预警系统具有较高的准确性和可行性,可以有效地检测驾驶员的疲劳状态并及时发出警报,避免潜在的交通事故发生,对提高交通安全水平具有重要的理论和实践意义。
【关键词】疲劳驾驶;OpenCV检测;眼部检测;PERCLOS
一、研究背景与意义
自二十一世纪以来,汽车工业发展迅速,越来越多的家庭购买汽车,汽车已成为人们日常生活中不可或缺的交通工具,但这也导致交通事故数量呈几何级增长。而在众多的交通肇事原因中,驾驶员疲劳驾驶是其中一个重要原因,驾驶疲劳是指驾驶员由于长时间驾驶或睡眠不足造成的反应能力下降,主要表现为驾驶员困倦、打瞌睡、驾驶操作失误等,但这可通过科技手段进行提前预警和预防。如果不能够及时地从疲劳状态中清醒过来,就容易导致交通事故的发生,严重危害驾驶人和其他道路用户的生命安全。美国每年发生多达10万起由驾驶疲劳引起的交通事故,导致40万人受伤,1550人死亡。在欧洲,英国交通实验室调查表明,在道路交通事故中,约有10%由驾驶疲劳所致。法国国家事故报告指出,因疲劳瞌睡导致的碰撞占了人身伤害事故的14.9%和死亡事故的20.6%。在德国高速公路上导致人员伤亡的交通事故中,大约有25%是由疲劳驾驶引起的,这个数据由德国保险公司协会推算得出。日本的事故统计显示,约有1.0%至1.5%的事故是由驾驶疲劳造成的。对驾驶疲劳检测的研究正在成为世界范围内的一个热门问题。因此,人们迫切希望能够有一种能够实时检测驾驶员疲劳程度,并且在安全隐患增加之前可以及时发现驾驶员处于疲劳驾驶且对其进行预警的系统,那么这种系统将会是预防由疲劳驾驶而引的交通肇事的有效手段[1]。
目前,驾驶疲劳的检测方法主要可分为四类。(1)第一类是基于驾驶员生理信号的方法[2,3]。这种生理信号包括脑电图(EEG)、心电图仪(ECG)和眼电图(EOG)。这些方法通常会产生良好的疲劳检测性能。然而,如何方便地获得干净的信号是实际应用中需要解决的问题[4,6]。(2)第二类是基于驾驶员操作行为的方法。文献报道,驾驶疲劳可以通过驾驶员的操作来检测,如方向盘操作[7,8]。当驾驶员陷入疲劳时,他会降低方向盘的握力或降低控制方向盘的能力[9]。(3)第三类是基于车辆状态的方法。车辆轨迹和车道偏离信息也是检测疲劳的额外有用信息[10]。轨迹和车道信息都与控制方向盘相关;因此,它们也反映了驾驶员的操作,但是是非接触的。(4)第四类是基于驾驶员生理反应的方法。疲劳可以通过眨眼和打哈欠等生理行为来检测,其中最有效的方法是基于眼睛状态的检测[11-14]。
二、相关技术分析
本课题主要基于OpenCV、YOLOv5等技术进行驾驶疲劳检测和预警系统的开发和实现。使用HOG算法以及YOLOv5识别脸部和行为表现,同时导入OpenCV视频模块进行设计。运用了dlib 库的HOG算法检测面部68个节点,然后对眼睛和嘴巴的相关欧氏距离进行计算,使用PERCLOS模块进行疲劳程度的划分和检测并划分不同疲劳状态。与此同时运用YOLOv5对抽烟、喝水、玩手机三种不同的状态进行训练[15],并且将其进行定义标签。最后将计算结果和训练结果写入GUI中进行检测和设置,在链接视频时使用OpenCV进行实时检测。
2.1 PyTorch
PyTorch是由Facebook AI研究院开发的一个开源的深度学习框架,它使用动态计算图的方式来构建模型,简化了模型的构建和调试过程。在基于OpenCV的驾驶疲劳检测与预警系统设计中,PyTorch可以用于训练深度学习模型,如卷积神经网络(Convolutional Neural Network,CNN),用于分析驾驶员的面部表情和眼部状态,以判断其是否疲劳。
2.2 GUI
GUI(Graphical User Interface)即图形用户界面,是指通过图形化的方式来显示计算机程序的用户界面,使得用户可以通过鼠标、键盘等操作来与计算机交互。在基于OpenCV的驾驶疲劳检测与预警系统设计中,GUI可以用来展示检测结果和预警信息,方便驾驶员及时了解自己的状态。
2.3 BERT模型
BERT(Bidirectional Encoder Representations from Transformers)模型是一种基于Transformer的预训练语言模型,由Google研究人员提出。在基于OpenCV的驾驶疲劳检测与预警系统设计中,BERT模型可以用于对驾驶员的语音进行识别和情感分析,以判断其是否疲劳。
2.4 HOG算法
HOG(Histogram of Oriented Gradients)算法是一种常用的特征提取方法,它通过计算图像中像素梯度的方向和强度来提取特征。在基于OpenCV的驾驶疲劳检测与预警系统设计中,HOG算法可以用于检测驾驶员的眼部和面部特征,以判断其是否疲劳。
2.5 PERCLOS介绍
PERCLOS(Percentage of Eye Closure)是一种基于眼睑闭合程度的疲劳度量指标。在基于OpenCV的驾驶疲劳检测与预警系统设计中,PERCLOS可以用于检测驾驶员的眼睑闭合程度,以判断其是否疲劳。
该函数用于检测视频流中人脸的疲劳程度。具体地,该函数通过检测人脸的眼睛和嘴巴的状态来评估人脸的疲劳程度。眼睛状态是通过计算眼睛的长宽比(eyear)来判断,如果长宽比小于某个阈值,则认为眼睛闭合,表示人处于疲劳状态。嘴巴状态是通过计算嘴巴的开口程度(mouthar)来判断,如果嘴巴开口程度小于某个阈值,则认为人处于疲劳状态。通过这些判断,可以评估人脸的疲劳程度,并做出相应的处理,例如提醒驾驶员休息或者调整工作强度等。
其中,PERCLOS是一种衡量眼睛疲劳的指标,它是指眼睛长宽比小于某个阈值的时间占总时间的比例。通常情况下,PERCLOS大于20%表示人处于疲劳状态。
2.6 OpenCV
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。在基于OpenCV的驾驶疲劳检测与预警系统设计中,OpenCV可以用于图像和视频的读取、处理和显示,以及特征提取和模型训练等任务。
2.7 YOLOv5
YOLOv5是一种基于深度学习的目标检测算法,可以快速准确地检测图像中的目标。在基于OpenCV的驾驶疲劳检测与预警系统设计中,YOLOv5可以用于检测驾驶员的面部和眼部特征,以判断其是否疲劳。
三、训练设计
3.1图像集检测
本课题利用YOLOv5训练,在数据集中进行近百张进行图像的训练,如图3-1所示。在训练过程中,使用了PyTorch进行了图形的自动检测,同时利用OpenCV库进行检测。

图3-1图像集
3.2 YOLOv5训练
该函数通过使用预训练的YOLO深度学习模型来检测视频流中的行为[16],并对其进行分类。在代码中,使用了PyTorch框架和OpenCV库。该函数首先加载深度学习模型,然后对视频流中的每一帧图像进行检测。检测结果包括目标的位置坐标、类别和概率等信息。接着,使用非极大值抑制算法对检测结果进行筛选,并根据坐标信息计算目标的尺寸和中心位置等信息。最后,根据目标的运动轨迹和行为特征,对目标进行分类。
利用letterbox函数实现了对图像进行缩放和裁剪的功能,以适应模型输入的要求。该函数将输入图像调整为指定的大小,并在图像周围添加一个灰色的边框,以保持图像的宽高比不变。该函数还提供了一些参数,例如自动调整图像大小、是否按比例缩放等选项,以适应不同的输入图像。其中weights变量指定了模型的权重文件路径,opt_device指定了使用的设备(如果为空字符串,则默认使用CPU),imgsz指定了输入图像的大小,opt_conf_thres和opt_iou_thres则分别指定了置信度和IOU的阈值。接下来,代码使用set_logging函数进行日志记录,使用select_device函数选择设备,使用attempt_load函数加载模型权重文件,并使用check_img_size函数检查输入图像的大小。如果需要进行半精度推理,则设置half变量为True,并将模型转换为FP16格式。最后,代码获取模型的类别名称和颜色信息,用于可视化输出结果。
YOLOv5中用于预测目标检测模型的函数是model.forward()。输入是一个图像,输出是检测到的目标的信息。首先,将输入的图像通过letterbox函数调整到指定大小,然后转换为PyTorch张量,并进行归一化处理。接着,将张量输入到模型中进行推理,得到预测结果。最后,通过非极大值抑制算法对预测结果进行筛选,得到最终的检测结果。
在 YOLOv5 中,检测到的目标会被先缩放回原始图像大小,然后将其置信度和类别信息存储在一个列表中。最后,返回一个包含所有目标信息的列表,其中每个元素包含目标的标签信息、置信度和位置信息。
3.3 bert模型训练过程
数据准备:首先准备大量的图片然后进行模型训练,并且配合语言文字的数值,利用Transformer图像导入,根据图像集进行训练,训练的过程中,划分模型的五个层次,并且对每个图像形成数值指标,然后形成文字和图像的检测双结合,通过该模型训练,可以将大量的图像进行自动文字识别。
对于图像的训练,可以采用CNN来提取图像特征,然后将这些特征输入到BERT模型中进行训练。具体来说,可以将图像作为输入,经过一系列卷积操作和池化操作后得到固定尺寸的特征向量,然后将这些特征向量与BERT模型中的文本输入进行拼接,得到一个输入向量序列。这个序列可以通过多层Transformer编码器进行处理,最终输出对应的预测结果。
对于文字的训练,BERT模型采用了一种叫做“Masked Language Model”的预训练任务。在这个任务中,模型会随机遮盖掉一些输入的单词,然后尝试预测这些被遮盖掉的单词。这个任务可以让模型学习到单词之间的关系和上下文信息,从而提高模型在自然语言处理任务中的性能。
同时,BERT模型还采用了另外一个预训练任务叫做“Next Sentence Prediction”。在这个任务中,模型需要判断两个给定的句子是否是相邻的。这个任务可以帮助模型学习到句子之间的关系和语义信息,从而更好地理解自然语言。
总体来说,BERT模型是一种可以同时处理文本和图像的模型,但是在训练过程中通常是分别进行的。在图像和文字的训练中,都采用了预训练任务来提高模型的性能。也就是说本文的训练过程中图像加入卷积神经网络算法进行训练,最终输出抽烟,喝水,打哈欠的特征。
训练完成之后,由图3-2和图3-3所示,可以看到YOLOv5的训练结果,其中包含face面部特征、喝水drink、抽烟somke、玩手机phone。
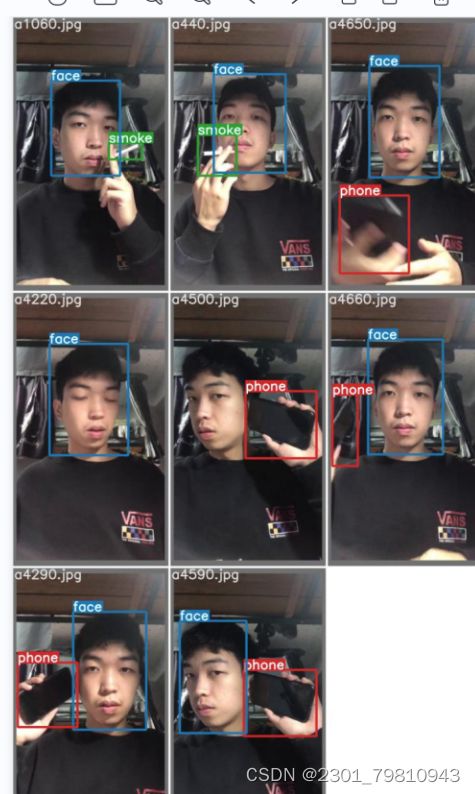
图3-2抽烟玩手机训练结果

图3-3喝水训练结果
下面可以看到训练过程中的混淆矩阵,其中,行是预测类别(y轴),列是真实类别(x轴);矩阵中Aij的含义是:第j个类别被预测为第i个类别的概率。
四、系统详细设计
4.1总体功能结构设计
本文采用HOG算法、BERT模型和YOLOv5进行驾驶疲劳训练检测[15],并利用OpenCV视频模块进行设计。在库的应用中,使用dlib库进行面部欧式距离的节点设计,并使用PERCLOS模块进行疲劳程度的划分和检测。在计算眼部疲劳程度时,使用闭眼帧数除以总帧数,当阈值大于0.6时为梦游状态,小于0.12时为疲劳状态。利用HOG算法检测面部68个节点,面部节点库为dlib,计算节点的方法是进行平均值除以绝对值的计算。同时,使用YOLOv5进行训练,将抽烟、喝水和玩手机三种不同的状态进行定义标签,标签名为Lab。最后将计算结果和训练结果写入GUI中进行检测和设置,在链接视频时利用OpenCV进行实时检测并使用前期的计算结果进行实时检测。在图像集方面,使用近千张图像进行检测,图4-1为整体结构图。

图4-1整体功能结构图
4.2面部疲劳状态检测流程
用于疲劳检测,通过检测眼睛和嘴巴的开合程度来判断是否疲劳。具体实现过程如下:导入需要的库和模块,包括距离计算模块、视频文件处理模块、人脸关键点处理模块[17]、数据处理模块等;定义了一个函数 eye_aspect_ratio(eye),用于计算眼睛长宽比。该函数接收一个包含眼睛坐标的列表参数 eye,首先计算出眼睛上下和左右两侧的距离,然后计算眼睛长宽比,最后返回该长宽比值;在主程序中,首先设置了一些参数,比如阈值、视频源等;接着通过 dlib 库中的人脸检测器和关键点检测器,获取人脸区域和眼睛、嘴巴等关键点坐标;计算眼睛和嘴巴的开合程度,根据阈值判断是否闭眼或打哈欠;如果连续几帧都检测到闭眼或打哈欠,则认为出现疲劳,播放警报声并记录时间;程序通过多线程的方式进行,一边检测疲劳,一边播放视频;检测结束后,程序会输出疲劳次数和警报次数。
代码中定义了一个计算嘴部长宽比(mouth aspect ratio, MAR)的函数mouth_aspect_ratio(mouth),其中输入参数 mouth 是一个包含嘴部关键点坐标的 numpy 数组。具体实现过程中,首先通过 np.linalg.norm() 函数计算出嘴巴中心点到上下唇两端点的距离 A 和 B,并计算出嘴巴的宽度 C,然后通过以下公式计算即可得到嘴部长宽比mar。
mar= (A + B) / (2 *C)
接下来的代码使用了dlib库中的人脸检测器和面部标志物预测器,分别使用 dlib.get_frontal_face_detector() 和 dlib.shape_predictor() 函数初始化。其中人脸检测器可以检测图像中的人脸位置,面部标志物预测器可以预测出人脸的面部关键点坐标。最后,通过 face_utils.FACIAL_LANDMARKS_IDXS 字典获取左右眼和嘴巴的关键点索引,用于后续的面部关键点提取。
函数中使用了一个人脸检测器(detector)和一个人脸特征点检测器(predictor)。首先将视频流中的每一帧转换为灰度图像(gray),然后使用detector对该图像进行人脸检测,得到一个矩形框(rects),表示检测到的人脸。接着,对于每个矩形框,使用predictor对灰度图像中的脸部特征点进行检测,得到特征点的位置信息(shape)。然后,将这些位置信息转换为数组array的格式,提取左眼、右眼和嘴巴的坐标,并计算眼睛的长宽比(eyear)和嘴巴的开口程度(mouthar),用于评估人脸的疲劳程度。图4-2为眼部嘴巴疲劳状态检测流程。

图4-2眼部嘴巴疲劳状态检测
通过判断眼睛的开合程度来判断用户是否疲劳,如果连续多次眨眼,则认为用户进行了一次眨眼活动。设定条件循环语句
(1)如果连续50帧(帧是视频中的一帧图像)未检测到分心行为(比如看手机、抽烟等),则将label修改为平时状态。
(2)如果眼睛的开合程度小于设定好的阈值,则两个和眼睛相关的计数器加1,其中COUNTER表示连续多少帧眼睛开合程度小于阈值,Rolleye表示连续多少帧眼球的位置发生了变化。
(3)如果连续EYE_AR_CONSEC_FRAMES(即设定的连续多少帧)都小于阈值,则表示进行了一次眨眼活动,这里使用TOTAL来记录眨眼的次数,并在label上显示[18]。然后将计数器COUNTER重置为0。用于检测用户是否打哈欠,如果连续3次检测到嘴巴开度小于阈值(即没有打哈欠),则重置嘴帧计数器mCOUNTER为0;如果检测到嘴巴开度大于阈值(即打哈欠),则mCOUNTER加1,同时Rollmouth也加1,表示打哈欠的嘴巴形状。如果打了5次哈欠,则会进行提醒,并播放声音。如果ActionCOUNTER大于0,则表示用户正在进行某个动作,此时不进行提醒。最后将ALARM_ON重置为False。图4-3为打哈欠阈值的设定。
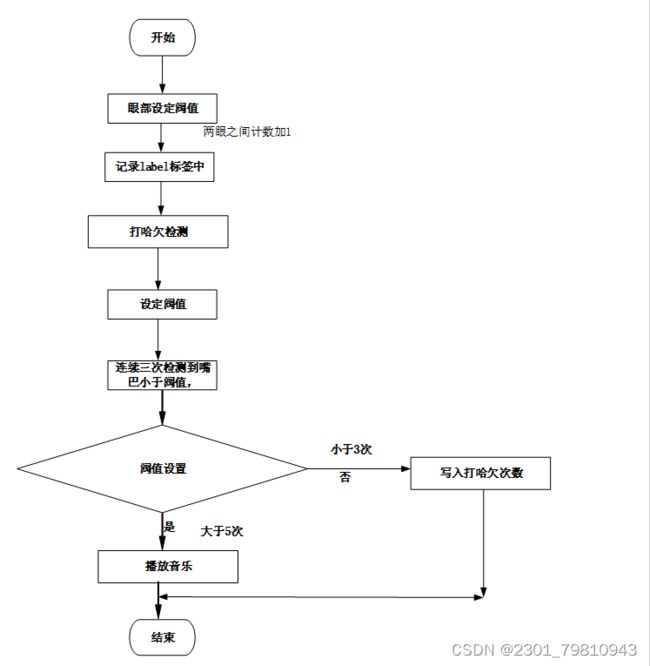
图4-3打哈欠阀值设定
五、系统实现
5.1 app实现打开
由于现代人使用应用程序的习惯比较广泛,因此本文在开发该系统时,使用了app实现打开,同时也可以使用正常的pycharm软件打开,为了方便用户的使用,本课题利用软件来运行系统。

图5-1app实现打开
5.2喝水检测
可以看到检测过程中,面部表情,以及drink检测,通过GUI界面检测的效果相对良好。

图5-2喝水检测
当喝水时间相对较长时,系统会进行提醒,出现请不要喝水的画面。
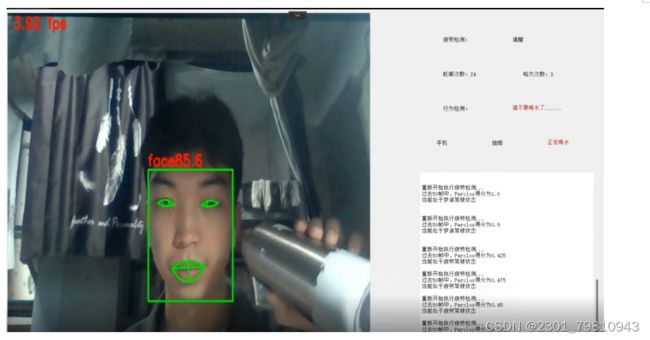
图5-3喝水检测提醒图像
5.3玩手机检测
通过该疲劳驾驶检测可以看到,正在玩手机,下面可以出现检测指标和结果,也就是说检测过程中会运行检测代码,检测代码调取模型训练参数。

图5-4玩手机检测
5.4抽烟检测
当用户进行抽烟时,系统根据代码中的提示进行模型的参数的调取,然后形成提醒。
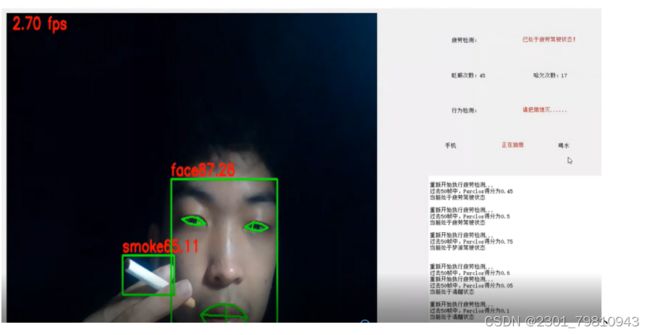
图5-5抽烟检测
5.5疲劳状态检测
用户处于疲劳状态,也就是眨眼次数和打哈欠次数较多时,那么处于疲劳状态,反之为清醒状态。
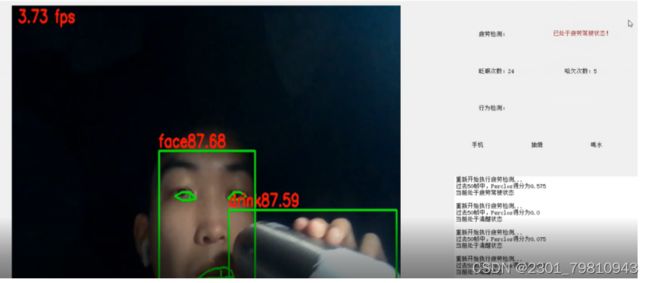
图5-6疲劳状态检测

图5-7清醒检测
四、 文章目录
目录
1绪论 1
1.1研究背景 1
1.2研究意义 1
1.3国内外研究现状 2
1.3.1国内现状 2
1.3.2国外现状 2
2相关技术分析 2
2.1 PyTorch 2
2.2 GUI 2
2.3 BERT模型 2
2.4 HOG算法 2
2.5 PERCLOS介绍 3
2.6 OpenCV 3
3训练设计 3
3.1图像集检测 3
3.2YOLOv5训练 4
3.3bert模型训练过程 5
4系统详细设计 10
4.1总体功能结构设计 10
4.2面部疲劳状态检测流程 10
4.3检测状态设置 12
4.3.1导入模块 12
4.3.2GUI界面标签设置 12
4.3.3检测状态提醒 13
5系统实现 14
5.1app实现打开 14
5.2喝水检测 14
5.3玩手机检测 15
5.4抽烟检测 15
5.5疲劳状态检测 16
6系统测试 17
6.1测试的目的 17
6.2测试的准则 17
6.3 测试用例及结果 17
7 总结与展望 17
参考文献 18