Java 内存模型(JMM)探寻原理,深度讲解
目录
一. 前言
二. 为什么会有内存模型
2.1. 硬件内存架构
2.2. 缓存一致性问题
2.3. 处理器优化和指令重排序
三. 并发编程的问题
四. Java 内存模型(JMM)
4.1. Java 运行时内存区域与硬件内存的关系
4.2. Java 线程与主内存的关系
4.3. 线程间通信
五. 主内存和工作内存
六. Java 内存模型的实现
6.1. 原子性
6.2. 可见性
6.3. 有序性
七. 总结
一. 前言
网上有很多关于 Java 内存模型的文章,在《深入理解Java虚拟机》和《Java并发编程的艺术》等书中也都有关于这个知识点的介绍。但是,很多人读完之后还是搞不清楚,甚至有的人说自己更懵了。本文,就来整体的介绍一下 Java 内存模型,目的很简单,让你读完本文以后,就知道到底Java 内存模型是什么,为什么要有 Java 内存模型,Java 内存模型解决了什么问题等。
二. 为什么会有内存模型
要想回答这个问题,我们需要先弄懂传统计算机硬件内存架构。光用文字可能说不清楚,下面通过几张图来帮助理解。
2.1. 硬件内存架构
 传统计算机内存架构
传统计算机内存架构
1. CPU
去过机房的同学都知道,一般在大型服务器上会配置多个 CPU,每个 CPU 还会有多个核,这就意味着多个 CPU 或者多个核可以同时(并发)工作。如果使用 Java 起了一个多线程的任务,很有可能每个 CPU 都会跑一个线程,那么你的任务在某一刻就是真正并发执行了。
2. CPU 寄存器(CPU Register)
CPU Register 也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
3. CPU 高速缓存(CPU Cache Memory)
CPU Cache Memory 也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
4. 主存(Main Memory)
Main Memory 就是主存,主存比 L1、L2 缓存要大很多。
注意:部分高端机器还有 L3 三级缓存。
2.2. 缓存一致性问题
由于主存与 CPU 处理器的运算能力之间有数量级的差距,所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再将运算结果同步到主存中。
使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
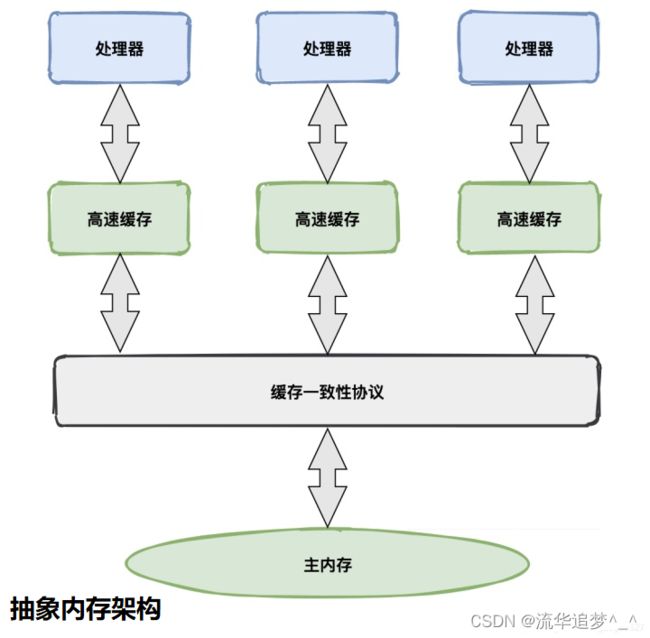 抽象内存架构
抽象内存架构
在多 CPU 的系统中(或者单 CPU 多核的系统),每个 CPU 内核都有自己的高速缓存,它们共享同一主内存(Main Memory)。当多个 CPU 的运算任务都涉及同一块主内存区域时,CPU 会将数据读取到缓存中进行运算,这可能会导致各自的缓存数据不一致。
因此需要每个 CPU 访问缓存时遵循一定的协议,在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI 和 Dragon Protocol 等。
2.3. 处理器优化和指令重排序
为了提升性能在 CPU 和主内存之间增加了高速缓存,但在多线程并发场景可能会遇到缓存一致性问题。那还有没有办法进一步提升 CPU 的执行效率呢?答案是:处理器优化。
为了使处理器内部的运算单元能够最大化被充分利用,处理器会对输入代码进行乱序执行处理,这就是处理器优化。
除了处理器会对代码进行优化处理,很多现代编程语言的编译器也会做类似的优化,比如像 Java 的即时编译器(JIT)会做指令重排序。

处理器优化其实也是重排序的一种类型,这里总结一下,重排序可以分为三种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义放入前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
三. 并发编程的问题
上面讲了一堆硬件相关的东西,有些同学可能会有点懵,绕了这么大圈,这些东西跟 Java 内存模型有啥关系吗?不要急咱们慢慢往下看。
熟悉 Java 并发的同学肯定对这三个问题很熟悉:可见性问题、原子性问题、有序性问题。如果从更深层次看这三个问题,其实就是上面讲的缓存一致性、处理器优化、指令重排序造成的。

缓存一致性问题其实就是可见性问题,处理器优化可能会造成原子性问题,指令重排序会造成有序性问题,你看是不是都联系上了。
出了问题总是要解决的,那有什么办法呢?首先想到简单粗暴的办法,干掉缓存让 CPU 直接与主内存交互就解决了可见性问题,禁止处理器优化和指令重排序就解决了原子性和有序性问题,但这样一夜回到解放前了,显然不可取。
所以技术前辈们想到了在物理机器上定义出一套内存模型,规范内存的读写操作。内存模型解决并发问题主要采用两种方式:限制处理器优化和使用内存屏障。
四. Java 内存模型(JMM)
同一套内存模型规范,不同语言在实现上可能会有些差别。接下来着重讲一下 Java 内存模型实现原理。
4.1. Java 运行时内存区域与硬件内存的关系
了解过 JVM 的同学都知道,JVM 运行时内存区域是分片的,分为栈、堆等,其实这些都是 JVM 定义的逻辑概念。在传统的硬件内存架构中是没有栈和堆这种概念。
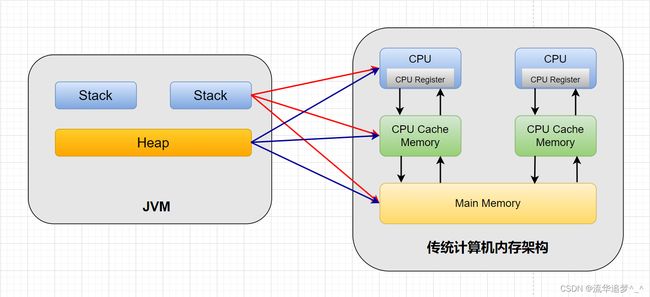
从图中可以看出栈和堆既存在于高速缓存中又存在于主内存中,所以两者并没有很直接的关系。
4.2. Java 线程与主内存的关系
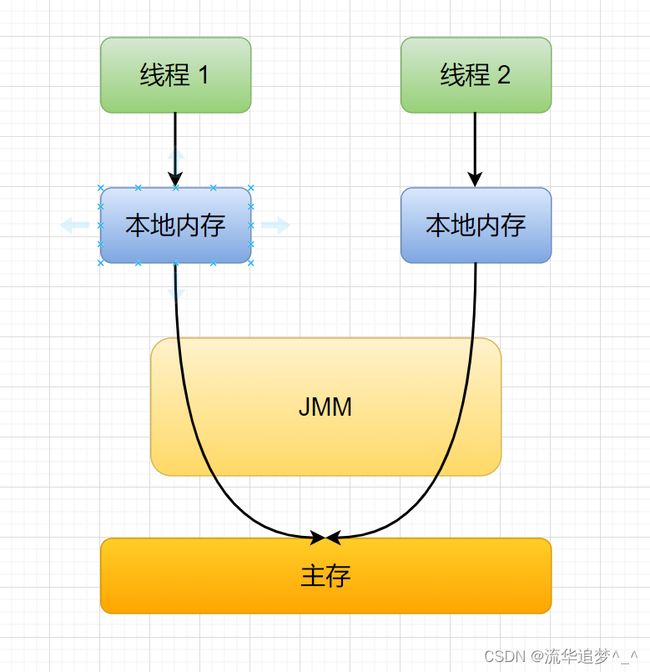
Java 内存模型是一种规范,定义了很多东西:
- 所有的变量都存储在主内存(Main Memory)中。
- 每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的拷贝副本。
- 线程对变量的所有操作都必须在本地内存中进行,而不能直接读写主内存。
- 不同的线程之间无法直接访问对方本地内存中的变量。
看文字比较枯燥,看下面这张图:
 JMM控制
JMM控制
4.3. 线程间通信
如果两个线程都对一个共享变量进行操作,共享变量初始值为 1,每个线程都变量进行加 1,预期共享变量的值为 3。在 JMM 规范下会有一系列的操作。

为了更好的控制主内存和本地内存的交互,Java 内存模型定义了八种操作来实现:
- lock:锁定。作用于主内存的变量,把一个变量标识为一条线程独占状态。
- unlock:解锁。作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read:读取。作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的 load 动作使用
- load:载入。作用于工作内存的变量,它把 read 操作从主内存中得到的变量值放入工作内存的变量副本中。
- use:使用。作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign:赋值。作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store:存储。作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的 write 的操作。
- write:写入。作用于主内存的变量,它把 store 操作从工作内存中一个变量的值传送到主内存的变量中。
注意:工作内存也就是本地内存的意思。
五. 主内存和工作内存
由于 CPU 和主内存间存在数量级的速率差,想到了引入多级高速缓存的传统硬件内存架构来解决,多级高速缓存作为 CPU 和主内存间的缓冲提升了整体性能。解决了速率差的问题,却又带来了缓存一致性问题。
数据同时存在于高速缓存和主内存中,如果不加以规范势必造成灾难,因此在传统机器上又抽象出了内存模型。
Java 语言在遵循内存模型的基础上推出了 JMM 规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
为了更精准控制工作内存和主内存间的交互,JMM 还定义了八种操作:lock、unlock、read、 load、use、assign、store、write。
前面介绍过了计算机内存模型,这是解决多线程场景下并发问题的一个重要规范。那么具体的实现是如何的呢,不同的编程语言,在实现上可能有所不同。
我们知道,Java 程序是需要运行在 Java 虚拟机上面的,Java 内存模型(Java Memory Model,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java 程序在各种平台下对内存的访问都能保证效果一致的机制及规范。
提到 Java 内存模型,一般指的是 JDK 5 开始使用的新的内存模型,主要由 JSR-133: JavaTM Memory Model and Thread Specification 描述。感兴趣的可以参看下这份 PDF 文档:http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf
Java 内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要在自己的工作内存和主存之间进行数据同步进行。
而 JMM 就是作用于工作内存和主存之间的数据同步过程。他规定了如何做数据同步以及什么时候做数据同步。
这里面提到的主内存和工作内存,读者可以简单的类比成计算机内存模型中的主存和缓存的概念。特别需要注意的是,主内存和工作内存与 JVM 内存结构中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,无法直接类比。《深入理解Java虚拟机》中认为,如果一定要勉强对应起来的话,从变量、主内存、工作内存的定义来看,主内存主要对应于 Java 堆中的对象实例数据部分。工作内存则对应于虚拟机栈中的部分区域。
所以,JMM 是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
六. Java 内存模型的实现
了解 Java 多线程的朋友都知道,在 Java 中提供了一系列和并发处理相关的关键字,比如volatile、synchronized、final、concurrent 包等。其实这些就是 Java 内存模型封装了底层的实现后提供给程序员使用的一些关键字。
在开发多线程的代码的时候,我们可以直接使用 synchronized 等关键字来控制并发,从来就不需要关心底层的编译器优化、缓存一致性等问题。所以,Java 内存模型,除了定义了一套规范,还提供了一系列原语,封装了底层实现后,供开发者直接使用。
本文并不准备把所有的关键字逐一介绍其用法,关于各个关键字的用法,可以参见《Java 之 volatile 详解》、《深入理解 synchronized 原理》、《Java 之 final 详解》、《Java 中的全部锁》、《J.U.C家族》、《JUC之Lock及核心AQS》、《JUC之Atomic原子类》等文章。本文还有一个重点要介绍的就是,我们前面提到,并发编程要解决原子性、有序性和一致性的问题,我们就再来看下,在 Java 中,分别使用什么方式来保证。
6.1. 原子性
在 Java 中,为了保证原子性,提供了两个高级的字节码指令 monitorenter 和 monitorexit。在《深入理解 synchronized 原理》一文中,介绍过这两个字节码,在 Java 中对应的关键字就是synchronized。
因此,在 Java 中可以使用 synchronized 来保证方法和代码块内的操作是原子性的。
6.2. 可见性
Java 内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值的这种依赖主内存作为传递媒介的方式来实现的。
Java 中的 volatile 关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次用之前都从主内存刷新。因此,可以使用 volatile 来保证多线程操作时变量的可见性。
除了 volatile,Java 中的 synchronized 和 final 两个关键字也可以实现可见性。只不过实现方式不同,这里不再展开了。
6.3. 有序性
在 Java 中,可以使用 synchronized 和 volatile 来保证多线程之间操作的有序性。实现方式有所区别:volatile 关键字会禁止指令重排。synchronized 关键字保证同一时刻只允许一条线程操作。
至此,就已经简单地介绍完了 Java 并发编程中解决原子性、可见性以及有序性可以使用的关键字。读者可能发现了,好像 synchronized 关键字是万能的,他可以同时满足以上三种特性,这其实也是很多人滥用 synchronized 的原因。
但是 synchronized 是比较影响性能的,虽然编译器提供了很多锁优化技术,但是也不建议过度使用。
七. 总结
读到此处的同学们,相信你应该已经了解了什么是 Java 内存模型、Java 内存模型的作用以及Java 中内存模型做了什么事情等。关于 Java 内存模型的有关知识,如果还想继续深入,可以参考《深入理解Java虚拟机》和《Java并发编程的艺术》两本书。