【华为数据之道学习笔记】6-2数据服务生命周期管理
完整的数据服务生命周期包括服务识别与定义、服务设计与实现、服务运营三个主要阶段。
-
服务识别与定义: 业务与数据握手,识别服务的业务价值、准入条件与服务类型,减少数据服务的重复建设,提升数据服务的重用度。
-
服务设计与实现: 业务、数据、IT三方协同,使设计、开发、测试与部署快速迭代以实现服务的敏捷交付,缩短数据服务的建设周期。
-
服务运营: 通过统一数据服务中心及服务运营机制,保障服务SLA与持续优化。
1. 数据服务的识别与定义
针对数据需求,规范数据服务识别过程,列出数据服务识别过程需要了解的关键内容,明确数据服务的实现方式和准入条件,提高数据服务的可复用性,减少重复建设。
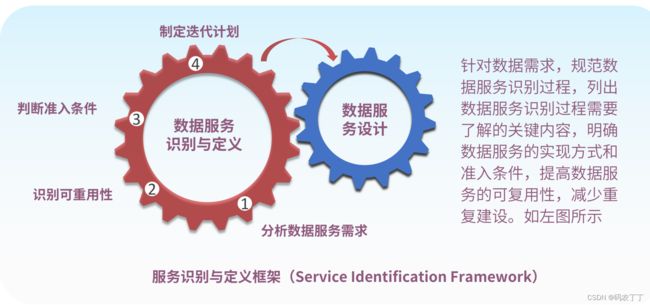
1)分析数据服务需求: 通过数据需求调研与需求交接,判断数据服务类型(面向系统或面向消费)、数据内容(指标/维度/范围/报表项)、数据源与时效性要求。
2)识别可重用性: 结合数据需求分析,通过数据服务中心匹配已有的数据服务,判断以哪种方式(新建服务、直接复用、服务变更)满足业务需求。对于已有数据服务,必须使用服务化方式满足需求,减少数据“搬家”。
3)判断准入条件 :判断服务设计条件是否已具备,包括数据Owner是否明确、元数据是否定义、业务元数据和技术元数据是否建立联接、数据是否已入湖等。
4)制定迭代计划: 根据数据服务需求制定敏捷交付计划,快速满足数据服务需求。
在数据服务的识别和定义中,要特别注意数据服务的可重用性。所有的数据服务都是需求驱动产生的,如果没有需求方,那么这个数据服务就没有存在的价值。但是,重复建设也就成了数据服务建设中最大的风险之一。数据供应方很容易基于不同的数据消费方开发出不同的数据服务,而他们的数据需求往往是相似的,但数据供应方可能
因为响应周期、客户(数据消费方)体验等压力,并没有花费精力去对来自各数据消费方的需求进行筛选和收敛, 这就导致所建设的数据服务往往只是满足某个特定客户(数据消费方)的需求。如果数据服务不具备可重用性,那么它与传统的数据集成的方式相比,就并不具备优越性,有时甚至会导致更大的重复投资。
因此,以数据服务需求分析为输入,通过服务可重用性判断已有数据服务对需求的满足情况,给出满足服务需求的策略,并结合准入条件的关键问题判断服务需求是否能够被快速满足。
通常可以从数据服务提供形式、数据服务提供内容两方面来判断服务的可重用性。
在数据服务识别和定义阶段还应重点关注的另一个要素是数据资产的可服务性,通常用于数据服务准入条件的判断,即某个数据资产是否已经具备对外提供服务的条件。
在进行数据可服务性(准入条件)判断时,至少应充分考虑以下因素:
-
数据Owner是否明确?
-
数据是否有明确的安全密级定义?
-
元数据是否定义?
-
业务元数据和技术元数据是否建立联接?
-
面向数字化运营分析场景时,数据是否已入湖?
2. 数据服务的设计与实现
在服务设计与实现阶段,要定义服务契约和数据契约,重点明确服务契约所涉及的服务责任主体、处理逻辑,并以数据契约规范服务的数据格式与数据的安全要求。
通过服务契约与数据契约,可以有效地管理在数据交互中可能存在的安全风险,数据供应方可以将一些安全要求通过契约实现。例如,对某些高密级控制属性进行屏蔽。同时,供应方能够通过契约了解哪些消费者获取了数据以及使用的数量和频率等。
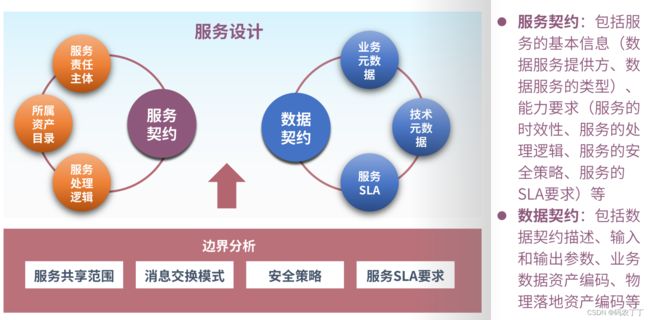
服务契约:包括服务的基本信息(数据服务提供方、数据服务的类型)、能力要求(服务的时效性、服务的处理逻辑、服务的安全策略、服务的SLA要求)等。
数据契约:包括数据契约描述、输入和输出参数、业务数据资产编码、物理落地资产编码等。
数据服务设计中应强调数据服务的颗粒度,数据服务颗粒度的大小直接影响着服务的可重用性,细粒度的服务更容易被重用。但是,如果我们只考虑可重用性,将导致产生大量颗粒度很小的数据服务,这将对系统的整体性能带来严重的影响,因此必须在服务粒度设计上维护一种平衡。
数据服务颗粒度通常应考虑以下原则。
-
业务特性: 将业务相近或相关、数据粒度相同的数据设计为一个数据服务。
-
消费特性: 将高概率同时访问、时效性要求相同的数据设计为一个数据服务。
-
管理特性: 综合考虑企业在数据安全管理策略方面的要求。
-
能力特性: 将单一能力模型设计为一个服务。
基于上述原则,可以形成一些具体的用于指导实际执行的参考规范,如下所示。
-
同一种提供形式下,一个数据只能设计在一个数据服务中。
-
按主题(业务对象)将相同维度的数据设计为一个数据服务。如果同一个主题下的指标数量过多,则需要考虑按“高概率同时使用、业务关联度紧密”的原则再进行划分。
-
将同一个逻辑实体的数据设计为一个数据服务。
-
将单一功能的算法、应用模型设计为一个服务。
为确保服务设计后能快速、有序落地,要建立数据服务的开发、测试、部署流程,通过技术、自动化工具、管理协同机制,确保数据服务敏捷交付,缩短数据服务建设周期。
服务开发、测试、部署中应重点构建以下能力。
-
服务需求接收与管理: 明确数据管理部门、IT部门、业务代表的具体职责,通过三方共同协作,解决需求理解不透彻导致开发过程反复的问题。
-
构建自助式开发平台: 通过简单配置的方式实现数据服务的开发,降低数据服务的开发门槛,缩短数据服务的开发周期。
-
代码自动审查: 通过自动化手段校验服务开发代码的性能及不规范等问题,阻断代码提交,直到问题解决,做到事前规避。
-
数据自动验证: 构建数据自动测试能力,实现数据服务的数据量差异、字段差异、数据准确性差异的验证。
-
功能自动测试: 构建功能自动化测试能力,自动对数据服务SLA、查询出入参数进行自动检查,构建容错机制。
-
服务部署: 数据服务不涉及对数据的修改,采用实时部署的方式可缩短数据服务的实现周期,提升数据服务的敏捷响应能力。
3. 数据服务的变更与下架
随着业务需求的不断变化,数据服务需要随之进行调整,因此在建设中也应做好数据服务的变更管理和下架管理。
(1)数据服务变更管理
可参考以下因素:
-
服务变更内容: 包括数据服务的时效性、出入参数、服务处理逻辑、数据安全策略等。
-
服务变更影响: 业务连续性影响、变更成本影响等。
(2)数据服务的下架管理
因为数据服务是基于用户需求产生的,而业务需求是动态变化的,因此需要持续将调用量很少甚至为零的数据服务从市场中下架,确保数据消费者总能拿到“最好的”数据服务。通常,数据服务的下架有两种情况:一种是由服务消费方主动提出的数据服务下架申请,可以称为“主动下架”;另一种是通过运营度量策略判断需要下架的数据服务(例如,三个月内无服务调用、重复的数据服务等),可以称为“被动下架”。
企业应制定针对不同场景的数据服务下架流程,确保数据服务下架前进行充分的影响度评估,并具备面向所有相关方的消息通知能力,确保实际下架前各消费方的知情权。另外,还应构建一定的自动化实施能力,在各方就数据服务下架达成一致后,系统自动执行数据服务下架动作。