【目标检测实验系列】通过全局上下文注意力机制Global Context Block(GC)融合到YOLOv5案例,吃透简单即插即用注意力机制代码修改要点,举一反三!(超详细改进代码流程)
1. 文章主要内容
本篇博客主要涉及简单的即插即用注意力机制融合到YOLOv5整个过程。通过详细的分析各个文件,吃透如何将注意力机制单独拎出来,插到网络结构任何位置中,举一反三。(通读本篇博客需要10分钟左右的时间)。
另外,GC与YOLOv5的C3融合教程见博客:【目标检测实验系列】YOLOv5创新点改进实验:融合Global Context Block全局注意力机制,增强Backbone的特征提取能力,模型高效涨点
2. 即插即用注意力机制(GC)融合到YOLOv5
2.1 GC源代码解析
GC的原理见我上面的那篇博客,这里我们首先贴出C3GC的源代码。(需要注意到,我们将C3GC源代码放在一个叫做C3GC.py文件中,如果没有,请自行建立或者参考我上面的那篇博客)
import torch
import torch.nn as nn
from models.common import Bottleneck
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
def constant_init(module, val, bias=0):
if hasattr(module, 'weight') and module.weight is not None:
nn.init.constant_(module.weight, val)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
def kaiming_init(module,
a=0,
mode='fan_out',
nonlinearity='relu',
bias=0,
distribution='normal'):
assert distribution in ['uniform', 'normal']
if hasattr(module, 'weight') and module.weight is not None:
if distribution == 'uniform':
nn.init.kaiming_uniform_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
else:
nn.init.kaiming_normal_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
def last_zero_init(m):
if isinstance(m, nn.Sequential):
constant_init(m[-1], val=0)
m[-1].inited = True
else:
constant_init(m, val=0)
m.inited = True
class CB2d(nn.Module):
def __init__(self, inplanes, pool='att', fusions=['channel_add', 'channel_mul']):
super(CB2d, self).__init__()
assert pool in ['avg', 'att']
assert all([f in ['channel_add', 'channel_mul'] for f in fusions])
assert len(fusions) > 0, 'at least one fusion should be used'
self.inplanes = inplanes
self.planes = inplanes // 4
self.pool = pool
self.fusions = fusions
if 'att' in pool:
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusions:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1)
)
else:
self.channel_add_conv = None
if 'channel_mul' in fusions:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1)
)
else:
self.channel_mul_conv = None
self.reset_parameters()
def reset_parameters(self):
if self.pool == 'att':
kaiming_init(self.conv_mask, mode='fan_in')
self.conv_mask.inited = True
if self.channel_add_conv is not None:
last_zero_init(self.channel_add_conv)
if self.channel_mul_conv is not None:
last_zero_init(self.channel_mul_conv)
def spatial_pool(self, x):
batch, channel, height, width = x.size()
if self.pool == 'att': # iscyy
input_x = x
input_x = input_x.view(batch, channel, height * width)
input_x = input_x.unsqueeze(1)
context_mask = self.conv_mask(x)
context_mask = context_mask.view(batch, 1, height * width)
context_mask = self.softmax(context_mask)
context_mask = context_mask.unsqueeze(3)
context = torch.matmul(input_x, context_mask)
context = context.view(batch, channel, 1, 1)
else:
context = self.avg_pool(x)
return context
def forward(self, x):
context = self.spatial_pool(x)
if self.channel_mul_conv is not None:
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = x * channel_mul_term
else:
out = x
if self.channel_add_conv is not None:
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out
class C3GC(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1,
e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion #iscyy
super(C3GC, self).__init__()
c_ = int(c2 * e) # hidden channels
self.gc = CB2d(c1)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
# self.m = nn.Sequential(*[CB2d(c_) for _ in range(n)])
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
out = torch.cat((self.m(self.cv1(self.gc(x))), self.cv2(self.gc(x))), dim=1)
out = self.cv3(out)
return out
class GCBottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.gc = CB2d(c1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.gc(self.cv1(x))) if self.add else self.cv2(self.gc(self.cv1(x)))
# 注意到这里的self.gc有两个,就分别对应于C3GC结构图的两个分支,如果想要只融合一个分支便删掉一个self.gc即可。
我们将C3GC源代码中的CB2d类拿出来做单独的分析,因为这个类是GC注意力机制的核心代码,也是我们待会要用到的,如下所示:
import torch
import torch.nn as nn
from models.common import Bottleneck
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
def constant_init(module, val, bias=0):
if hasattr(module, 'weight') and module.weight is not None:
nn.init.constant_(module.weight, val)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
def kaiming_init(module,
a=0,
mode='fan_out',
nonlinearity='relu',
bias=0,
distribution='normal'):
assert distribution in ['uniform', 'normal']
if hasattr(module, 'weight') and module.weight is not None:
if distribution == 'uniform':
nn.init.kaiming_uniform_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
else:
nn.init.kaiming_normal_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
def last_zero_init(m):
if isinstance(m, nn.Sequential):
constant_init(m[-1], val=0)
m[-1].inited = True
else:
constant_init(m, val=0)
m.inited = True
class CB2d(nn.Module):
def __init__(self, inplanes, pool='att', fusions=['channel_add', 'channel_mul']):
super(CB2d, self).__init__()
assert pool in ['avg', 'att']
assert all([f in ['channel_add', 'channel_mul'] for f in fusions])
assert len(fusions) > 0, 'at least one fusion should be used'
self.inplanes = inplanes
self.planes = inplanes // 4
self.pool = pool
self.fusions = fusions
if 'att' in pool:
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusions:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1)
)
else:
self.channel_add_conv = None
if 'channel_mul' in fusions:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1)
)
else:
self.channel_mul_conv = None
self.reset_parameters()
def reset_parameters(self):
if self.pool == 'att':
kaiming_init(self.conv_mask, mode='fan_in')
self.conv_mask.inited = True
if self.channel_add_conv is not None:
last_zero_init(self.channel_add_conv)
if self.channel_mul_conv is not None:
last_zero_init(self.channel_mul_conv)
def spatial_pool(self, x):
batch, channel, height, width = x.size()
if self.pool == 'att': # iscyy
input_x = x
input_x = input_x.view(batch, channel, height * width)
input_x = input_x.unsqueeze(1)
context_mask = self.conv_mask(x)
context_mask = context_mask.view(batch, 1, height * width)
context_mask = self.softmax(context_mask)
context_mask = context_mask.unsqueeze(3)
context = torch.matmul(input_x, context_mask)
context = context.view(batch, channel, 1, 1)
else:
context = self.avg_pool(x)
return context
def forward(self, x):
context = self.spatial_pool(x)
if self.channel_mul_conv is not None:
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = x * channel_mul_term
else:
out = x
if self.channel_add_conv is not None:
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out
类CB2d的def init()方法中需要传入一个inplanes参数,这个就是我们要传入的输入通道数,非常重要。此外,类CB2d的输出通道与输入通道保持一致,这里可以根据forward方法来明确。forward方法传入的x和返回的out的维度是一样。(out = out + channel_add_term说明:两个tensor相加(add),维度必须保持一致)。
2.2 建立一个yolov5-gc.yaml文件
我们来到第二步,先建立好一个yaml文件,注意到这里我将CB2d(也就是全局上下文注意力机制GC)放到到Backbone部分第一个C3结构的前面。(通过本文的详细分析,大家都可以随心所欲单独的放到网络结构的任何位置)。先看yaml的源代码:
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8 小目标
- [30,61, 62,45, 59,119] # P4/16 中目标
- [116,90, 156,198, 373,326] # P5/32 大目标
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 output_channel, kernel_size, stride, padding
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 1, CB2d, []],
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
这是我调试过后的源代码,是可以正确运行的。我们拿出添加的这个代码如下:
[-1, 1, CB2d, []],
首先,我们得明白这四个参数的意思,分开来讲:
第一个是from:-1代表这层的输入来自于上层的输出,重要的来了,我们要明白的是这层的输入通道数就是来自上层的输出通道数。
第二个是number:1代表这层结构重复一次。
第三个是module:代表要插入模块类的名字。
第四个是args:代表要插入模块类init要传入的参数,这里我选择为空,大家不要急,下面我会给详细的解释。
2.3 结合yaml、CB2d文件分析yolo.py文件(重点!!!)
重点是yolo.py文件,我们首先将如下的代码添加到yolo.py文件(具体位置,大家仔细查看,有一个大块部分都是这种格式,随便找个地方放进去就行)中去:
elif m is CB2d:
c1 = ch[f]
args = [c1]
首先elif这个代码就是如果m是CB2d类的话,就执行下面的代码。然后着重分别分析下面的代码:
第二行代码,将ch[f]赋值给c1,那么ch[f]是啥,其实ch[f]来自于上层的输出通道数,在本博客当中,上层是[-1, 1, Conv, [128, 3, 2]], 即为普通卷积层,这个层的输入输出通道数一样。但请注意,这里的通道数可不是128,我们来看看上层Conv输出的通道数,也就是看看上层的输入通道数,大家看一下下面的代码:
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, C3GC, ODConv, nn.ConvTranspose2d, CNeB, CSPStage, C3_P, C3_Res2Block, CSPNeXtLayer,
C3CA, EAP, C3BottleNeck, nn.ConvTranspose2d, DilationSPP, C3CABlock, CoordConv, CAConv, C3NCB, RepLKDeXt, SPPCSPC, GSConv, VoVGSCSP,
C3EMA, C3LSK, C3_Faster_EMA, C3ECA, C3SE, C3CBAM, Conv_BN_HSwish, MobileNetV3_InvertedResidual, GCBottleneck):
c1, c2 = ch[f], args[0] # c1:3, c2:64
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8) # c2:32
其中很重要的一段代码:
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8) # c2:32
这里明确的指出Conv的输出通道数c2是要通过args[0] 参数传进来的,在本文中就是128,那么通过if条件判断,会乘上一个gw的参数。这个gw参数即为yaml文件中的[‘width_multiple’],在本文中是0.5,所以c2为128*0.5也就是64。同时这个c2作为下层CB2d的输入通道数,我们再回到如下这段代码来:
elif m is CB2d:
c1 = ch[f]
args = [c1]
这个时候我们就知道,ch[f]即为64,也就是c1为64,然后通道args传入到CB2d类的init方法中,init方法中的inplanes就得到了64。所以呢,我们yaml文件中,后面的args参数就啥也不要传,因为这里已经将c1传入进去了。
2.4 启动的效果
一切准备就行,我们运行成功的效果图如下:
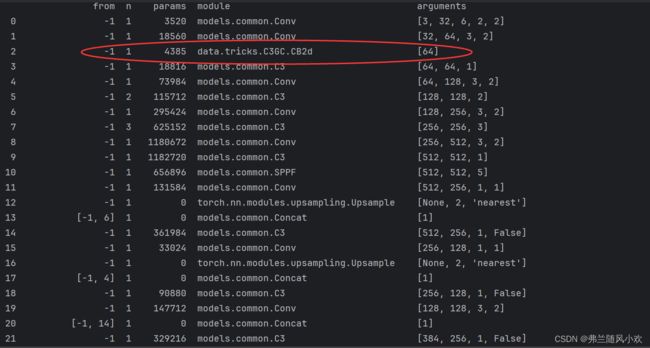
咱们的全局注意力机制就完美的放到网络结构中去了,如果能熟练掌握此教程,举一反三应该问题不大。
3. 总结
本篇博客主要介绍了通过全局上下文注意力机制Global Context Block(GC)融合到YOLOv5案例,吃透简单即插即用注意力机制的修改详细流程。另外,在修改过程中,要是有任何问题,评论区交流;如果博客对您有帮助,请帮忙点个赞,收藏一下;后续会持续更新本人实验当中觉得有用的点子,如果很感兴趣的话,可以关注一下,谢谢大家啦!