机器学习——特征选择(一)
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、简介
特征选择,又称变量选择、属性选择或变量子集选择,是选择相关特征子集用于模型构造的过程。简要地说,通过检测相关特征。摒弃冗余特征,获得特征子集,从而以最小的性能损失更好地描述问题。
特征选择和降维都是防止数据过拟合的有效手段。但是两者又有本质上的区别。降维本质上是从一个维度空间映射到另一个维度空间,在映射的过程中特征值会相应地变化。特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后不改变其值,但是选择后的特征维数肯定比选择前小。特征选择注重别除无用特征。
sklearn.feature_selection 模块提供了特征选择方法,如下所示。
| 方法 | 说明 |
| VarianceThreshold | 删除方差小的特征 |
| SelectKBest | 返回K个最佳特征,移除那些除了评分最高的K个特征之外的所有特征 |
| SelectPercentile | 按指定百分比返回表现最佳的特征 |
特征选择的方法有包装法、过滤法和嵌人法等。
- 包装法(wrapper)。根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- 过滤法(filter)。按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阚值的个数,选择特征。
- 嵌入法(embedded)。使用某此机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。嵌人法类似于过滤法,但是嵌入法通过训练来确定特征的优劣。
2、包装法
包装法具有递归特征消除和交叉验证递归特征消除两种方法。
2.1 递归特征消除
递归特征消除(Recursive Feature Elimination, RFE)是常见的特征选择方法。其工作原理是:递归删除特征,并在剩余的特征上构建模型,使用模型准确率来判断哪些特征(或特征组合)对预测结果贡献较大。
Sklearn提供了RFE函数,以实现递归消除特征法。格式如下:
RFE(estimator=svc, n_features_to_select=no_features, step=1)【参数说明】
- estimator = svc:指定有监督型学习器,该学习器具有fit方法,通过coef_属性或者feature_importances_属性来提供feature重要性信息
- n_features_to_select = no_features:指定保留的特征数
- step = 1:控制每次迭代过程中删去的特征数
示例:
from sklearn.feature_selection import RFE
from sklearn.svm import LinearSVC#线性支持向量机
from sklearn.datasets import load_iris
from sklearn import model_selection
from sklearn.model_selection import GridSearchCV
iris = load_iris()
X = iris.data
y = iris.target
#特征提取
estimator = LinearSVC()
selector = RFE(estimator = estimator, n_features_to_select = 2)
X_t = selector.fit_transform(X,y)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y,
test_size = 0.25,random_state = 0,stratify = y)
X_train_t, X_test_t, y_train_t, y_test_t = model_selection.train_test_split(X_t,y,
test_size = 0.25,random_state = 0, stratify = y)
#训练和测试
clf = LinearSVC()
clf_t = LinearSVC()
clf.fit(X_train, y_train)
clf_t.fit(X_train_t, y_train_t)
#print(clf.score(X_test,y_test))
print('original dataset: test score =%s'%(clf.score(X_test, y_test)))
print('selected dataset: test score =%s'%(clf_t.score(X_test_t,y_test_t)))【运行结果】
![]()
【结果分析】
原模型的性能在递归特征消除后确实下降了,这是因为递归特征消除自身的原因。虽然该方法可以较好地进行手动特征选择,但是原模型在去除特征后的数据集上的性能表现要差于其在原数据集上的表现,这是因为去除的特征中包含有效信息。
2.2 交叉验证递归特性消除
交叉验证递归特性消除(Recursive Feature Elimination with Cross ValidationRFECV)通过交叉验证来找到最优的特征数量,实现特征选择。该方法分如下两个阶段
(1) RFE 阶段。进行递归特征消除,对特征进行重要性评级。具体步骤如下:
- 以初始的特征集作为所有可用的特征。
- 使用当前特征集进行建模,然后计算每个特征的重要性。
- 删除最不重要的一个(或多个)特征,更新特征集。
- 跳转到步骤2,直到完成所有特征的重要性评级。
(2) CV阶段在完成特征评级后,通过交叉验证,选择最佳数量的特征。具体步骤如下:
- 根据 RFE 阶段确定的特征重要性,依次选择不同数量的特征。
- 对选定的特征集进行交叉验证
- 确定平均分最高的特征数量,完成特征选择。
RFEGV用于选取单模型特征的效果相当不错,但是它有如下两个缺陷:
- 计算量大。
- 随着预估器的改变,最佳特征组合也会改变
Sklearn提供了RFECV函数,以实现交叉验证递归消除,格式如下:
RFEECV(estimator=svc, step=1, cv=StratifiedKFold(2))【参数说明】
- estimator=svc:指定用于递归构建模型的有监督型学习器。
- step=1:控制每次迭代过程中删去的特征个数为1。
- cv=StratifiedKFold(2):指定交叉验证次数。
示例:
#新版本sklearn2.0中grid_score_函数删除
import matplotlib.pyplot as plt
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import RFECV
from sklearn import svm
from sklearn.datasets import make_classification
#使用内置函数生成数据集(1000个样本,25个特征,3个有效特征,共8类)
X,y = make_classification(n_samples = 1000, n_features = 25, n_informative = 3,
n_redundant = 2, n_repeated = 0, n_classes = 8,
n_clusters_per_class= 1, random_state = 0)
#创建RFECV,用正确分类比例进行评分
svc = svm.SVC(kernel = 'linear')
rfecv = RFECV(estimator = svc, step = 1, cv = StratifiedKFold(2), scoring = 'accuracy')
rfecv.fit(X, y)
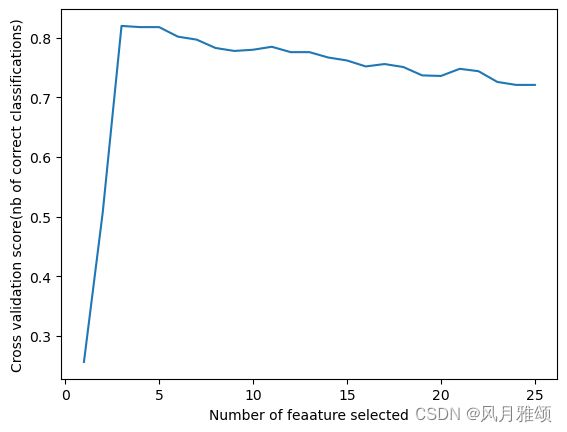
print('Optimal number of features: %d' % rfecv.n_features_)#给出被选出的特征的数量
#绘制特征数与交叉验证得分关系图
plt.figure()
plt.xlabel('Number of feaature selected')
plt.ylabel('Cross validation score(nb of correct classifications)')
plt.plot(range(1, len(rfecv.cv_results_['mean_test_score']) + 1),
rfecv.cv_results_['mean_test_score'])
#plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show()【运行结果】
Optimal number of features: 3
2.3 注意
版本sklearn2.0中grid_score_函数删除
- cv_results_['mean_test_score']平均分
- cv_results_['params']参数
更换cv_results_函数俩获得评分和参数。
3、过滤法
过滤法有移除低方差特征法和单变量特征选择两种方法。其中,单变量特征选择根据问题类型不同,其消除的指标不同。对于分类问题,采用卡方检验、f_classif等指标。对于回归问题,采用皮尔森相关系数指标。
3.1 移除低方差特征
从方差的大小考虑,特征方差小是指某个特征的大多数样本的值比较相近,特征方差大是指某个特征很多样本的值有比较大的差别。移除低方差特征又称为方差选择法,用于删除低方差的一些特征。
Sklearn提供VarianceThreshold函数实现此功能,其基本语法如下:
sklearn.feature _selection.VarianceThreshold(threshold) 【参数说明】参数 threshold为移除方差的阈值。在默认情况下,它取值为0,表示移除所有方差为0的特征,也就是移除所有取值相同的特征,保留所有非零方差特征。
示例:
from sklearn.feature_selection import VarianceThreshold
import numpy as np
var = VarianceThreshold(threshold = 1.0)
data = np.array([[0,2,0,3],[0,1,4,3],[0,1,1,3]])
print('data\n',data)
print('data.shape\n', data.shape)
data_new = var.fit_transform(data)
print('data_new\n',data_new)
print('data_new.shape\n', data_new.shape)【运行结果】

3.2 单变量特征选择
单变量特征选择法又称为相关系数法,它通过计算每个变量的指标,根据重要程度剔除不重要的指标,选择最佳特征。Sklearn 提供了SelectKBest 和 SelectPercentile 两个函数实现单变量特征选择。其中,SelectKBest保留评分最高的K个特征,SelectPercentile保留指定百分比的高分特征。
SelectKBest的语法如下:
sklearn.feature_selection.SelectKBest (score_func=f_classif, k=10)【参数说明】
- score_func=f_classif:指定评分函数为f_classif(默认值),只适用于分类函数。
- k=10:评分最高的10个特征。
SelectPercentile的语法如下:
SelectPercentile(score_ func=f_classif, percentile=90)
【参数说明】
- score_func=f_classif:指定评分函数为f_classif(默认值),只适用于分类函数。
- percentile=90:指定保留百分比为90%。
(1)SelectKBest 示例
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2#差方分析,适用于分类问题,
#要求特征是计数或二元变量(正值)
iris = load_iris()
X,y = iris.data, iris.target
print(X.shape)
#对样本进行一次chi2测试来选择最佳的两相特征
X_new = SelectKBest(chi2, k = 2).fit_transform(X,y)
#SelectKBest(选择chi2评分函数,k=2 选择最优两个)
print(X_new.shape)(2)SelectPercentile示例:
from sklearn.feature_selection import SelectPercentile, f_classif
def test_SelectKBest():
X = [[1,2,3,4,5],[5,4,3,2,1,],[3,3,3,3,3],[1,1,1,1,1]]
y = [1,0,1,0]
print('before transform:',X)
selector = SelectPercentile(score_func = f_classif, percentile = 90)
selector.fit(X,y)
print('scores_:', selector.scores_)
print('pvalues_:', selector.pvalues_)
print('selected index:', selector.get_support(True))
#如果为true,则返回被选出的特征下标,如果选择False,则
#返回的是一个布尔值组成的数组,该数组只是那些特征被选择
print('after transform:', selector.transform(X))
#调用test_SelectKBest函数
test_SelectKBest()【运行结果】
