无约束优化问题求解笔记(1)
目录
- 1. 迭代求解的基本流程与停止准则
-
- 1.1 迭代求解的基本流程
- 1.2 停止准则
- 1.3 收敛阶
- 2. 线搜索方法
-
- 2.1 精确线搜索
- 2.2 非精确搜索
-
- **Goldstein 准则**
- **Wolfe 准则**
- 2.3 线搜索算法的收敛性
1. 迭代求解的基本流程与停止准则
1.1 迭代求解的基本流程
优化问题的解通常无法直接而精确地求得,因而退而求其数值近似解.数值求解通常通过一个迭代过程来完成,在迭代时必须保证下一个点仍在可行集中,对约束优化问题而言这经常是很大的障碍,但是对于无约束优化问题 f ( x ) f(x) f(x) 而言却没有这个障碍,因为无约束优化问题的可行集是全空间 R n \mathbb{R}^n Rn,也就是说任意方向都是其可行方向,那么如何才能最快地获取近似解呢?这便是本笔记中要学习的问题.
通常的迭代过程可以叙述如下:先选取一个初始近似值 x 0 x_0 x0,然后在近似解的周围按某种方式搜索一个新的点 x 1 x_1 x1 使得
f ( x 1 ) < f ( x 0 ) f(x_1) < f(x_0) f(x1)<f(x0), 将此过程不断进行下去,直至得到最优解的一个可接受的近似值为止. 用数学表达式的来描述这个过程可以如下表示: x k + 1 = x k + α k d k , s.t. f ( x k + 1 ) < f ( x k ) \begin{aligned}x_{k+1}=x_k+\alpha_kd_k,&&\text{s.t.}f(x_{k+1}) < f(x_k)\end{aligned} xk+1=xk+αkdk,s.t.f(xk+1)<f(xk)其中, d k d_k dk 称为该迭代算法的搜索方向, α k > 0 \alpha_k>0 αk>0 称为搜索步长. 上述的迭代过程包含如下两个基本问题:
(1.1.1) 如何最佳地选择下降方向 d k ; d_k; dk;
(1.1.2) 如何最佳地选择步长 α k . \alpha_k. αk.
上述两个问题可以同时进行,但更多的方法是先选择方向再选择步长. 为了使得 f ( x k + 1 ) < f ( x k ) f(x_{k+1})
∇ f ( x k ) T d k < 0. \nabla f(x_k)^Td_k<0. ∇f(xk)Tdk<0.称满足该条件的方向 d k d_k dk 称为下降方向.
下降方向的选择对算法的性能有决定性的作用.其中给定下降方向后选择步长的问题称为线搜索问题.
1.2 停止准则
迭代算法往往不能在有限次达到精确解,但实际中无须求得精确解,因此需要设置停止参数来节省计算资源,即当 x k x_k xk 与精确解 x ∗ x^∗ x∗ 的误差 ∥ x k − x ∗ ∥ 2 ∥x_k − x^∗∥_2 ∥xk−x∗∥2 小于某个给定的精度时就终止迭代,但由于优化问题的解 x ∗ x^∗ x∗ 是未知的,所以实际上无法通过
∥ x k − x ∗ ∥ 2 ∥x_k − x^∗∥_2 ∥xk−x∗∥2 来确定迭代过程在什么时候终止.一般情况下,人们采取如下两种终止指标:
(1.2.1) 用 ∥ x k + 1 − x k ∥ 2 \|x_{k+1}-x_k\|_2 ∥xk+1−xk∥2 的大小或 ∣ f ( x k + 1 ) − f ( x k ) ∣ |f(x_{k+1})-f(x_k)| ∣f(xk+1)−f(xk)∣ 的大小来作为终止指标. 直观上说就是连续两次的迭代对解的改善很小时即可终止迭代.
(1.2.2) 另一种更常用的终止准则基于如下事实:当 f f f 一阶可微时,极小点 x ∗ x^* x∗ 满足 ∇ f ( x ∗ ) = 0 \nabla f(x^*)=0 ∇f(x∗)=0. 所以如果 ∇ f ( x k ) \nabla f(x_k) ∇f(xk) 已经足够小,那么在 x k x_k xk 的邻近,无论沿那个方向 d d d 做迭代, f ( x ) f(x) f(x) 的进一步下降的幅度都将非常小. 这表明,沿着这个方向继续迭代下去的改善已经微乎其微了,可以终止. 所以根据此事实,通常使用 ∥ ∇ f ( x k ) ∥ 2 ≤ ϵ \|\nabla f(x_k)\|_2\leq\epsilon ∥∇f(xk)∥2≤ϵ来作为迭代算法的终止条件,其中 ϵ > 0 ϵ > 0 ϵ>0 为一个给定的常数,称为停止阈值.
但是上述终止条件并不能够保证 x k x_k xk 一定是 f f f 的近似极小值点,因为平稳点(满足 ∇ f ( x ∗ ) = 0 \nabla f(x^*)=0 ∇f(x∗)=0 的点)并一定是极小值,例如 f ( x ) = x 3 f(x)=x^3 f(x)=x3 在 x = 0 x=0 x=0 处的一阶导数为0,但显然 x = 0 x=0 x=0 不是 f ( x ) = x 3 f(x)=x^3 f(x)=x3 的极小值点.但当在 f f f 是二阶可微且其 Hessian 矩阵 ∇ 2 f ( x ∗ ) ∇^2f(x^∗) ∇2f(x∗) 是正定或 f f f 为凸函数的情形下,满足 ∇ f ( x ∗ ) = 0 ∇f(x∗)=0 ∇f(x∗)=0 的 x ∗ x^* x∗ 却是 f f f 的局部极小点的充分必要条件.
给定停止阈值 ϵ > 0 ϵ > 0 ϵ>0,在迭代算法中,如果在某一次满足 ∥ ∇ f ( x k ) ∥ 2 ≤ ϵ ∥∇f(xk)∥2 ≤ ϵ ∥∇f(xk)∥2≤ϵ,那么算法终止,无需进一步迭代.此时称该算法是 ϵ − ϵ- ϵ−有限终止的.如果对任意 ϵ > 0 ϵ > 0 ϵ>0 算法总是 ϵ − ϵ- ϵ− 有限终止的,则称该算法是阈值有限终止的.根据阈值有限终止的定义,可以证明阈值有限终止条件等价于如下二者之一成立:
- 存在 k ≥ 0 使得 ∥ ∇ f ( x k ) ∥ 2 = 0 ∥∇f(x_k)∥_2 = 0 ∥∇f(xk)∥2=0,
- ∥ ∇ f ( x k ) ∥ 2 > 0 , ∀ k ≥ 0 , 且 lim ‾ k → ∞ ∥ ∇ f ( x k ) ∥ 2 = 0. \|\nabla f(x_{k})\|_{2}>0,\forall k\geq0,\text{且}\underline{\lim}_{k\to\infty}\|\nabla f(x_{k})\|_{2}=0. ∥∇f(xk)∥2>0,∀k≥0,且limk→∞∥∇f(xk)∥2=0.
反之,阈值有限终止不成立等价于存在 ϵ 0 > 0 ϵ_0 > 0 ϵ0>0,使得 ∥ ∇ f ( x k ) ∥ 2 ≥ ϵ 0 , ∀ k ≥ 0 ∥∇f(x_k)∥_2 ≥ ϵ_0, ∀k ≥ 0 ∥∇f(xk)∥2≥ϵ0,∀k≥0.
1.3 收敛阶
衡量一个迭代算法的性能的指标主要有, 误差要小,计算量要快,并且对计算空间的要求小.误差用以描述迭代算法的近似程度,一般情况下用如下的收敛阶来刻画:
定义 1.1 (收敛性及收敛阶) 设 { x k } \{x_k\} {xk} 是计算某个优化问题所生成的迭代点列, x ∗ x^* x∗ 是优化问题的解,如果 lim k → ∞ ∥ x k − x ∗ ∥ 2 = 0 \lim_{k\to\infty}\|x_k-x^*\|_2=0 limk→∞∥xk−x∗∥2=0,则称 { x k } \{x_k\} {xk} 收敛于 x ∗ x^* x∗.此外,如果存在 q > 0 q>0 q>0 和 μ ≥ 0 \mu\geq0 μ≥0,使得,当 x k ≠ x ∗ x_k\neq x^* xk=x∗ 时,有 lim k → ∞ ∥ x k + 1 − x ∗ ∥ 2 ∥ x k − x ∗ ∥ 2 q = μ , \lim_{k\to\infty}\frac{\|x_{k+1}-x^*\|_2}{\|x_k-x^*\|_2^q}=\mu, k→∞lim∥xk−x∗∥2q∥xk+1−x∗∥2=μ,
- 当 q = 1 q = 1 q=1 且 µ ∈ ( 0 , 1 ) µ ∈ (0, 1) µ∈(0,1) 时,称之为线性收敛的.当 µ = 0 µ = 0 µ=0时,则称之为超线性收敛的.
- 当 q > 1 , µ > 0 q > 1, µ> 0 q>1,µ>0 时- 称算法是 q − q- q−阶收敛的,特别地对应于 p = 2 , 3 p = 2, 3 p=2,3 时,分别称之为平方的与立方的收敛的.
衡量一个迭代算法的优劣的另一个常用的方法是所谓的二次终止性,其基本思想是如果目标函数是一个二次函数
f ( x ) : = 1 2 x T G x + b T x + c , f(x):=\frac{1}{2}x^{T}Gx+b^{T}x+c, f(x):=21xTGx+bTx+c,其中 G ∈ S + n , b ∈ R n , c ∈ R , G\in\mathbb{S}_+^n,\:b\in\mathbb{R}^n,c\in\mathbb{R},\: G∈S+n,b∈Rn,c∈R, 若利用该迭代算法能从任意初值出发经过有限次迭代达到最小点,那么称该算法具有二次终止性.二次终止性的意义在于, 对于二次可微的目标函数 f f f,根据 Taylor 展开, f f f 在极小点邻近可以用一个二次函数来逼近,因此具有二次终止性的算法在极小点邻近将有较理想的收敛速度.
2. 线搜索方法
已知搜索方向而求搜索步长的过程称为线搜索过程.下面对精确搜索算法和非精确搜索算法讨论步长的选择以及迭代算法的收敛性.
2.1 精确线搜索
设迭代的当前状态为 x k x_k xk,要求下一个点 x k + 1 = x k + α k d k x_{k+1}=x_k+\alpha_kd_k xk+1=xk+αkdk. 当迭代方向 d k d_k dk 为已知,并且迭代方式是目标函数值减小的方向,即 ϕ ( α ) : = f ( x k + α d k ) \phi(\alpha):=f(x_k+\alpha d_k) ϕ(α):=f(xk+αdk) 满足
ϕ ′ ( 0 ) = ∇ f ( x k ) T d k < 0 \begin{align} \phi^{\prime}(0)=\nabla f(x_k)^Td_k<0\end{align} ϕ′(0)=∇f(xk)Tdk<0时,选择合适的步长 α k \alpha_k αk,使得 ϕ ( α ) : = f ( x k + α k d k ) \phi(\alpha):=f(x_k+\alpha_kd_k) ϕ(α):=f(xk+αkdk) 尽可能小.最好的 α k \alpha_k αk 是如下优化问题 min α > 0 ϕ ( α ) \begin{align}\min_{\alpha>0}\phi(\alpha)\end{align} α>0minϕ(α)的解.这种给定搜索方向 d k d_k dk,根据(2)来选取 α k \alpha_k αk 的搜索方法称为精确线搜索. 此时由于 α k \alpha_k αk 是最优步长, 那么必然有 d d t f ( x k + t d k ) ∣ t = α k = 0 \frac d{dt}f(x_k+td_k)|_{t=\alpha_k}=0 dtdf(xk+tdk)∣t=αk=0 ,从而精确线搜索的迭代点列 x k + 1 = x k + α k d k x_{k+1}=x_k+\alpha_kd_k xk+1=xk+αkdk 满足 ∇ f ( x k + 1 ) T d k = 0. \begin{align} \nabla f(x_{k+1})^Td_k=0.\end{align} ∇f(xk+1)Tdk=0.一般情况下,满足(3)的解 x k + 1 x_{k+1} xk+1 不能够解析求得,这时候便需要采用搜索法求近似值X.其基本思想是先确定极小点所在的区间 [ a , b ] [a, b] [a,b],然后通过如下的方式缩小搜索区间:设搜索的第 i i i 步所得到的区间是 [ a i , b i ] [ai, bi] [ai,bi],取 p i , q i p_i, q_i pi,qi 满足 a i ≤ p i < q i ≤ b i a_i ≤ p_i < q_i ≤ b_i ai≤pi<qi≤bi, 然后按如下规则缩小区间:
-
若 ϕ ( p i ) ≤ ϕ ( q i ) \phi(p_i) ≤ \phi(q_i) ϕ(pi)≤ϕ(qi),则令 a i + 1 = a i a_{i+1} = a_i ai+1=ai, b i + 1 = q i b_{i+1} = q_i bi+1=qi
-
若 ϕ ( p i ) > ϕ ( q i ) \phi(p_i) > \phi(q_i) ϕ(pi)>ϕ(qi),则令 a i + 1 = p i a_{i+1} = p_i ai+1=pi, b i + 1 = b i b_{i+1} = b_i bi+1=bi
如果 ϕ \phi ϕ 为 [ a , b ] [a, b] [a,b] 上单峰函数,也就是一元拟凸函数时,搜索法总能在有限步找到最小值点具有任意精度的近似点.
2.2 非精确搜索
精确搜索在每一步迭代都要求解一个一元函数的极小问题,该极小化问题可以通过确定搜索区间,并在搜索区间里采用搜索算法来求近似值,但由于每一次迭代都需要这么做,所以精确搜索的运算量是相当大的.
正如名字一样,非精确搜索并不要求计算 min α ≥ 0 f ( x k + α d k ) \min_{\alpha\geq0}f(x_k+\alpha d_k) minα≥0f(xk+αdk).,而是沿着给定的方向 d k d_k dk, 找合适的 α k \alpha_k αk,使得 f ( x + α k d k ) f(x+\alpha_kd_k) f(x+αkdk) 较之 f ( x k ) f(x_k) f(xk) 有较好的下降.
沿着下降方向 d k d_k dk, 当步长 α \alpha α 足够小时,函数值 f ( x k + α d k ) f(x_k+\alpha d_k) f(xk+αdk) 一定下降.然而,如果 α \alpha α 取得太小,下降的幅度太小,导致要经过很多次迭代才能收敛到 α ∗ \alpha^* α∗.但如果步长太大,有可能 f ( x k + α d k ) f(x_k+\alpha d_k) f(xk+αdk) 反而增加,也不是好的选择. 所以,正确的方法是:要保证 f ( x k + α d k ) f(x_k+\alpha d_k) f(xk+αdk) 有一定程度的下降,且 α α α不能太小.
Goldstein 准则
为了保证搜索过程中 ϕ ( α ) : = f ( x k + α d k ) \phi(\alpha):=f(x_k+\alpha d_k) ϕ(α):=f(xk+αdk) 有一定比例的下降,搜索步长 α > 0 \alpha>0 α>0 应该满足 ϕ ( α ) ≤ ϕ ( 0 ) + ρ 1 ϕ ′ ( 0 ) α . \phi(\alpha)\leq\phi(0)+\rho_1\phi^{\prime}(0)\alpha. ϕ(α)≤ϕ(0)+ρ1ϕ′(0)α.其中 0 ≤ ρ 1 ≤ 1 0\leq\rho_1\leq1 0≤ρ1≤1 是预先给定的参数. 这样得到的 α k \alpha_k αk 保证 f ( x k + 1 ) f(x_{k+1}) f(xk+1) 有较好幅度的下降.
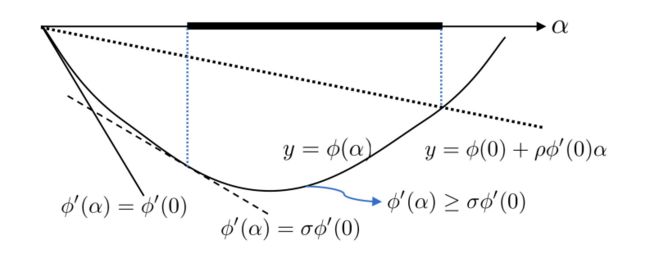
同时,为了避免 α k \alpha_k αk 取值太小而导致 ϕ \phi ϕ 下降太慢,还要求 α \alpha α 满足: ϕ ( α ) ≥ ϕ ( 0 ) + ρ 2 ϕ ′ ( 0 ) α , \begin{aligned}\phi(\alpha)\geq\phi(0)+\rho_2\phi'(0)\alpha,\end{aligned} ϕ(α)≥ϕ(0)+ρ2ϕ′(0)α,其中 0 ≤ ρ 2 ≤ 1 0\leq\rho_2\leq1 0≤ρ2≤1 是另一个预先给定的参数. 将此条件前一条结合起来,便可以得到如下的Goldstein 准则: ϕ ( 0 ) + ρ 2 ϕ ′ ( 0 ) α ≤ ϕ ( α ) ≤ ϕ ( 0 ) + ρ 1 ϕ ′ ( 0 ) α , \phi(0)+\rho_2\phi^{\prime}(0)\alpha\leq\phi(\alpha)\leq\phi(0)+\rho_1\phi^{\prime}(0)\alpha, ϕ(0)+ρ2ϕ′(0)α≤ϕ(α)≤ϕ(0)+ρ1ϕ′(0)α,其直观意义如图 2.1所示.

显然,落在图 2.1中黑色区间内的 α \alpha α 均满足 Goldstein 准则, 这比找 ϕ \phi ϕ 的最小值点要容易得多.由于 ϕ ′ ( 0 ) < 0 \phi^{\prime}(0)<0 ϕ′(0)<0, 所以,为了使得满足上式的 α \alpha α 存在, 必须 0 < ρ 1 ≤ ρ 2 ≤ 1 0<\rho_1\leq\rho_2\leq1 0<ρ1≤ρ2≤1.为了容易求出 α \alpha α,通常取 ρ 1 < ρ 2 \rho_1<\rho_2 ρ1<ρ2. 为简计,我们取 0 < ρ ≤ 1 / 2 0<\rho\leq1/2 0<ρ≤1/2, 并令 ρ 1 = ρ , ρ 2 = 1 − ρ \rho_1=\rho,\:\rho_2=1-\rho ρ1=ρ,ρ2=1−ρ.这样 Goldstein 准则可以写成
f ( x k ) + α ( 1 − ρ ) ∇ f ( x k ) T d k ≤ f ( x k + α d k ) ≤ f ( x k ) + α ρ ∇ f ( x k ) T d k , \begin{align}f(x_k)+\alpha(1-\rho)\nabla f(x_k)^Td_k\leq f(x_k+\alpha d_k)\leq f(x_k)+\alpha\rho\nabla f(x_k)^Td_k,\end{align} f(xk)+α(1−ρ)∇f(xk)Tdk≤f(xk+αdk)≤f(xk)+αρ∇f(xk)Tdk,其中 0 < ρ ≤ 1 / 2. 0<\rho\leq1/2. 0<ρ≤1/2.
命题 2.2.1 (Goldstein 搜索的存在性) 设 f f f 在 R n \mathbb{R}^n Rn 上连续且有下界,在 x k x_k xk 处可微且 ∇ f ( x k ) T d k < 0 , ρ ∈ ( 0 , 1 / 2 ] \nabla f(x_k)^Td_k<0,\:\rho\in(0,1/2] ∇f(xk)Tdk<0,ρ∈(0,1/2], 那么满足 G o l d s t e i n Goldstein Goldstein 准则的 α > 0 \alpha>0 α>0 一定存在.
证. 记 ϕ ( α ) : = f ( x k + α d k ) \phi(\alpha):=f(x_k+\alpha d_k) ϕ(α):=f(xk+αdk). 则 ϕ \phi ϕ 是 R 上一阶可微且有下界的函数, ϕ ′ ( 0 ) = \phi^{\prime}(0)= ϕ′(0)= ∇ f ( x k ) T d k < 0 \nabla f(x_k)^Td_k<0 ∇f(xk)Tdk<0.记
ψ ( α ) : = ϕ ( 0 ) + α ( 1 − ρ ) ϕ ′ ( 0 ) − ϕ ( α ) . \begin{aligned}\psi(\alpha):=\phi(0)+\alpha(1-\rho)\phi'(0)-\phi(\alpha).\end{aligned} ψ(α):=ϕ(0)+α(1−ρ)ϕ′(0)−ϕ(α).
将 ϕ \phi ϕ在 α = 0 \alpha=0 α=0 点做 Taylor 展开,得 ψ ( α ) = − α ρ ϕ ′ ( 0 ) + o ( α ) \psi(\alpha)=-\alpha\rho\phi^{\prime}(0)+o(\alpha) ψ(α)=−αρϕ′(0)+o(α).由于 ϕ ′ ( 0 ) = ∇ f ( x k ) T d k < 0 \phi^{\prime}(0)=\nabla f(x_k)^Td_k<0 ϕ′(0)=∇f(xk)Tdk<0 所以,当 α > 0 \alpha>0 α>0 充分小时,有 ψ ( α ) > 0. \psi(\alpha)>0. ψ(α)>0.
由于 ϕ \phi ϕ 有下界,于是 ϕ ( 0 ) − ϕ ( α ) \phi(0)-\phi(\alpha) ϕ(0)−ϕ(α) 有界,且由于 ϕ ′ ( 0 ) = ∇ f ( x k ) T d k < 0 \phi^{\prime}(0)=\nabla f(x_k)^Td_k<0 ϕ′(0)=∇f(xk)Tdk<0,于是有当 α → ∞ \alpha \to \infty α→∞时, α ( 1 − ρ ) ϕ ′ ( 0 ) → − ∞ \alpha(1-\rho)\phi^{\prime}(0)\to-\infty α(1−ρ)ϕ′(0)→−∞.所以,当 α 足够大时,有 ψ ( α ) < 0 \psi(\alpha)<0 ψ(α)<0. 从而存在 α > 0 α>0 α>0, 使得 ψ ( α ) = 0. \psi(\alpha)=0. ψ(α)=0. 从而
ϕ ( 0 ) + α ( 1 − ρ ) ϕ ′ ( 0 ) = ϕ ( α ) ≤ ϕ ( 0 ) + α ρ ϕ ′ ( 0 ) . \phi(0)+\alpha(1-\rho)\phi^\prime(0)=\phi(\alpha)\leq\phi(0)+\alpha\rho\phi^\prime(0). ϕ(0)+α(1−ρ)ϕ′(0)=ϕ(α)≤ϕ(0)+αρϕ′(0).其中最后一个不等号用到了Goldstein 准则中 ρ ≤ 1 2 \rho \le\frac{1}{2} ρ≤21 的推导.
Wolfe 准则
Goldstein 准则的基本思想是使得 α α α 不太小,同时 ϕ ( α ) \phi(\alpha) ϕ(α) 较之 ϕ ( 0 ) \phi(0) ϕ(0) 有一定程度的下降. 基于这个思想还可以提出其他类似的准则,Wolfe 用条件 f ( x k + α d k ) T d k ≥ σ ∇ f ( x k ) T d k f(x_k+\alpha d_k)^Td_k\geq\sigma\nabla f(x_k)^Td_k f(xk+αdk)Tdk≥σ∇f(xk)Tdk, 其中 0 < σ < 1 0<\sigma<1 0<σ<1,来避免 α \alpha α 太小,并结合 ϕ ( α ) ≤ ϕ ( 0 ) + ρ 1 ϕ ′ ( 0 ) α \phi(\alpha)\leq\phi(0)+\rho_1\phi^{\prime}(0)\alpha ϕ(α)≤ϕ(0)+ρ1ϕ′(0)α,其中 0 ≤ ρ 1 ≤ 1 0\leq\rho_1\leq1 0≤ρ1≤1 是预先给定的参数,而提出了如下的 Wolfe 准则
ϕ ( α ) ≤ ϕ ( 0 ) + α ρ ϕ ′ ( 0 ) , ϕ ′ ( α ) ≥ σ ϕ ′ ( 0 ) . \begin{aligned}\phi(\alpha)\leq\phi(0)+\alpha\rho\phi'(0),\quad\phi'(\alpha)\geq\sigma\phi'(0).\end{aligned} ϕ(α)≤ϕ(0)+αρϕ′(0),ϕ′(α)≥σϕ′(0).其中 0 < ρ , σ < 1 0<\rho,\:\sigma<1 0<ρ,σ<1. Wolfe准则如下图所示:
由于去掉了 Goldstein 准则的第二个条件,所以不必限制 ρ < 1 / 2. \rho<1/2. ρ<1/2.
同时为了避免 α \alpha α 使得 ϕ ′ ( α ) = ∇ f ( x k + α d k ) T d k \phi^{\prime}(\alpha)=\nabla f(x_k+\alpha d_k)^Td_k ϕ′(α)=∇f(xk+αdk)Tdk 取正值且朝着增长的方向离开 ϕ ( α ) \phi(\alpha) ϕ(α) 的最小值点太远,可以考虑如下的强 Wolfe 准则: ϕ ( α ) ≤ ϕ ( 0 ) + α ρ ϕ ′ ( 0 ) , ∣ ϕ ′ ( α ) ∣ ≤ − σ ϕ ′ ( 0 ) . \begin{aligned}\phi(\alpha)&\le\phi(0)+\alpha\rho\phi'(0),\quad|\phi'(\alpha)|\le-\sigma\phi'(0).\end{aligned} ϕ(α)≤ϕ(0)+αρϕ′(0),∣ϕ′(α)∣≤−σϕ′(0).其中 0 < ρ , σ < 1 0<\rho,\sigma<1 0<ρ,σ<1.
命题 2.2.2 (Wolfe 搜索的存在性) 设 f f f 在 R n \mathbb{R}^n Rn 上一阶可微且有下界, ∇ f ( x k ) T d k < 0 \nabla f(x_k)^Td_k<0 ∇f(xk)Tdk<0, 0 < ρ ≤ σ < 1 0<\rho\leq\sigma<1 0<ρ≤σ<1,那么满足强 Wolfe 准则的 α > 0 \alpha>0 α>0 一定存在.
证. 记 ψ ( α ) : = ϕ ( 0 ) + α ρ ϕ ′ ( 0 ) − ϕ ( α ) \psi(\alpha):=\phi(0)+\alpha\rho\phi^{\prime}(0)-\phi(\alpha) ψ(α):=ϕ(0)+αρϕ′(0)−ϕ(α).如命题 2.2.1的证明所得,对充分小的 α > 0 \alpha>0 α>0, 有 ψ ( α ) > 0 \psi(\alpha)>0 ψ(α)>0,且存在 α > 0 \alpha>0 α>0,使得 ψ ( α ) = 0 \psi(\alpha)=0 ψ(α)=0.记 α m i n : = min { α > 0 ∣ ψ ( α ) = 0 } . \alpha_{\mathrm{min}}:=\min\{\alpha>0|\psi(\alpha)=0\}. αmin:=min{α>0∣ψ(α)=0}.那么, α min > 0 , ψ ( 0 ) = ψ ( α min ) = 0 , \alpha_{\min }> 0, \psi( 0) = \psi( \alpha_{\min }) = 0, αmin>0,ψ(0)=ψ(αmin)=0,且 ψ ( α ) > 0 , ∀ α ∈ ( 0 , α m i n ) \psi( \alpha) > 0, \forall\alpha\in ( 0, \alpha_{min} ) ψ(α)>0,∀α∈(0,αmin). 利用微分中值定理,存在 α ~ ∈ ( 0 , α min ) \tilde{\alpha}\in(0,\alpha_{\min}) α~∈(0,αmin),使得 ψ ′ ( α ~ ) = 0 \psi^{\prime}(\tilde{\alpha})=0 ψ′(α~)=0,即 ρ ϕ ′ ( 0 ) − ϕ ′ ( α ~ ) = 0 \rho\phi^{\prime}(0)-\phi^{\prime}(\tilde{\alpha})=0 ρϕ′(0)−ϕ′(α~)=0.
由于 ρ ≤ σ \rho\leq\sigma ρ≤σ,所以 ∣ ϕ ′ ( α ~ ) ∣ = ρ ∣ ϕ ′ ( 0 ) ∣ ≤ − σ ϕ ′ ( 0 ) . |\phi^{\prime}(\tilde{\alpha})|=\rho|\phi^{\prime}(0)|\leq-\sigma\phi^{\prime}(0). ∣ϕ′(α~)∣=ρ∣ϕ′(0)∣≤−σϕ′(0). 而 ψ ( α ~ ) > 0 \psi(\tilde{\alpha})>0 ψ(α~)>0 表明 ϕ ( α ~ ) < ϕ ( 0 ) + α ~ ρ ϕ ′ ( 0 ) \phi(\tilde{\alpha})<\phi(0)+\tilde{\alpha}\rho\phi^{\prime}(0) ϕ(α~)<ϕ(0)+α~ρϕ′(0). 所以 α ~ \tilde{\alpha} α~ 满足强Wolfe 条件.
2.3 线搜索算法的收敛性
接下来的内容是给出精确线搜索,以及非精确线搜索 Goldstein 准则和 Wolfe 准则所产生的迭代点列 { x k } \{x_k\} {xk} 的收敛性. 记 l e v f ( x 0 ) ( f ) : = { x ∈ R n ∣ f ( x ) ≤ f ( x 0 ) } . \begin{aligned}\mathbf{lev}_{f(x_0)}(f):=\{x\in\mathbb{R}^n|f(x)\leq f(x_0)\}.\end{aligned} levf(x0)(f):={x∈Rn∣f(x)≤f(x0)}.
命题 2.3.1 设 f ∈ C 1 ( R n ) f\in C^1(\mathbb{R}^n) f∈C1(Rn) 有下界,其梯度向量 ∇ f ( x ) \nabla f(x) ∇f(x) 在凸集 D ⊂ R n D\subset\mathbb{R}^n D⊂Rn 上一致连续, x 0 ∈ D x_0\in D x0∈D 使得 l e v f ( x 0 ) ( f ) ⊂ D \mathbf{lev}_{f(x_0)}(f)\subset D levf(x0)(f)⊂D.设以 x 0 x_0 x0 为初始点,当 ∇ f ( x k ) ≠ 0 \nabla f(x_k)\neq0 ∇f(xk)=0 时,采用如下搜索方向和搜索步长:
- 搜索方向: d k d_k dk 与 − ∇ f ( x k ) -\nabla f(x_k) −∇f(xk) 之间的夹角 θ k \theta_k θk 为一致锐角,即 ∃ μ ∈ ( 0 , π / 2 ) \exists\mu\in(0,\pi/2) ∃μ∈(0,π/2), 使得
0 ≤ θ k ≤ π 2 − μ , ∀ k = 0 , 1 , ⋯ ; \begin{align} 0\leq\theta_k\leq\frac\pi2-\mu,\quad\forall k=0,1,\cdots;\end{align} 0≤θk≤2π−μ,∀k=0,1,⋯; - 搜索步长:精确搜索,或满足 G o l d s t e i n Goldstein Goldstein 准则或 W o l f e Wolfe Wolfe 准则所得的迭代点列 { x k } \{x_k\} {xk} 满足:存在 k ≥ 0 k\geq0 k≥0 使得 ∥ ∇ f ( x k ) ∥ 2 = 0 \|\nabla f(x_k)\|_2=0 ∥∇f(xk)∥2=0,或者 lim k → ∞ ∥ ∇ f ( x k ) ∥ 2 = 0. \lim_{k\to\infty}\|\nabla f(x_k)\|_2=0. limk→∞∥∇f(xk)∥2=0.
证.记 g k : = ∇ f ( x k ) g_k:=\nabla f(x_k) gk:=∇f(xk).不妨设 g k ≠ 0 , ∀ k = 0 , 1 , ⋯ g_k\neq0,\quad\forall k=0,1,\cdots gk=0,∀k=0,1,⋯, 我们证明 lim k → ∞ ∥ g k ∥ 2 = 0 \lim_{k\to\infty}\|g_k\|_2=0 limk→∞∥gk∥2=0.为简计,设搜索方向 d k d_k dk 是单位向量: ∥ d k ∥ 2 = 1 \|d_k\|_2=1 ∥dk∥2=1. 则可以证明如下几点:
(i) 根据迭代的定义, { f ( x k ) } \{f(x_k)\} {f(xk)} 单调下降且有下界故收敛,于是 f ( x k ) − f ( x k + 1 ) → 0 ( k → ∞ ) ; f( x_k) - f( x_k+ 1) \to 0\quad ( k\to \infty) ; f(xk)−f(xk+1)→0(k→∞);
(ii) 由微分中值定理可知,存在 θ k ∈ ( 0 , 1 ) \theta_k\in(0,1) θk∈(0,1), 使得 f ( x k ) − f ( x k + β d k ) = − β ∇ f ( x k + θ k β d k ) T d k . \begin{aligned}f(x_k)-f(x_k+\beta d_k)=-\beta\nabla f(x_k+\theta_k\beta d_k)^Td_k.\end{aligned} f(xk)−f(xk+βdk)=−β∇f(xk+θkβdk)Tdk.,由于 ∇ f ( x ) \nabla f(x) ∇f(x) 在 D D D 上一致连续,故
∣ ∇ f ( x k + θ k β d k ) T d k − ∇ f ( x k ) T d k ∣ ≤ ∥ ∇ f ( x k + θ k β d k ) − ∇ f ( x k ) ∥ 2 = o ( 1 ) , \begin{aligned}|\nabla f(x_k+\theta_k\beta d_k)^Td_k-\nabla f(x_k)^Td_k|\le\|\nabla f(x_k+\theta_k\beta d_k)-\nabla f(x_k)\|_2=o(1),\end{aligned} ∣∇f(xk+θkβdk)Tdk−∇f(xk)Tdk∣≤∥∇f(xk+θkβdk)−∇f(xk)∥2=o(1),,其中高阶无穷小 o ( 1 ) o(1) o(1) 对 k k k 是一致的,即 ∀ ϵ > 0 \forall\epsilon> 0 ∀ϵ>0,存在与 k k k 无关的 δ > 0 \delta> 0 δ>0,当 0 < β < δ 0< \beta< \delta 0<β<δ 时, ∣ o ( β ) ∣ / β < ϵ |o(\beta)|/\beta<\epsilon ∣o(β)∣/β<ϵ 对所有 k k k 成立.
(iii) 且由一致锐角条件有:
− g k T d k = ∥ g k ∥ 2 cos θ k ≥ ∥ g k ∥ 2 cos ( π 2 − μ ) = ∥ g k ∥ 2 sin μ . -g_k^Td_k=\|g_k\|_2\cos\theta_k\geq\|g_k\|_2\cos(\frac{\pi}{2}-\mu)=\|g_k\|_2\sin\mu. −gkTdk=∥gk∥2cosθk≥∥gk∥2cos(2π−μ)=∥gk∥2sinμ.,于是 g k T d k ≥ ∥ g k ∥ 2 sin μ g_k^Td_k\geq\|g_k\|_2\sin\mu gkTdk≥∥gk∥2sinμ
利用反证法:若命题的结论不成立, 则存在 ϵ > 0 \epsilon>0 ϵ>0 及子列 { g k } k ∈ K \{g_k\}_{k\in\mathcal{K}} {gk}k∈K,使得 ∥ g k ∥ 2 ≥ ϵ , ∀ k ∈ K \|g_k\|_2\geq\epsilon,\mathrm{~}\forall k\in\mathcal{K} ∥gk∥2≥ϵ, ∀k∈K.这里仅以精确搜索为例来说明矛盾,类似地也可以导出 Goldstein准则和 Wolfe准则的矛盾.
如果 { x k } x_k\} xk} 是精确搜索所得的点列,那么根据上述的前提(ii)和(iii)有: ∀ α > 0 \forall\alpha>0 ∀α>0 和 k ≥ 0 k\geq0 k≥0, f ( x k ) − f ( x k + 1 ) ≥ f ( x k ) − f ( x k + α d k ) = − α g k T d k + o ( α ) ≥ α ( ∥ g k ∥ 2 sin μ + o ( α ) α ) . \begin{aligned}f(x_k)-f(x_{k+1})\geq f(x_k)-f(x_k+\alpha d_k)=-\alpha g_k^Td_k+o(\alpha)\geq\alpha\Big(\|g_k\|_2\sin\mu+\frac{o(\alpha)}{\alpha}\Big).\end{aligned} f(xk)−f(xk+1)≥f(xk)−f(xk+αdk)=−αgkTdk+o(α)≥α(∥gk∥2sinμ+αo(α)).所以, ∀ k ∈ K \forall k\in\mathcal{K} ∀k∈K, 有
f ( x k ) − f ( x k + 1 ) ≥ α ( ϵ sin μ + o ( α ) α ) . \begin{aligned}f(x_k)-f(x_{k+1})\geq\alpha\Big(\epsilon\sin\mu+\frac{o(\alpha)}{\alpha}\Big).\end{aligned} f(xk)−f(xk+1)≥α(ϵsinμ+αo(α)).取 α > 0 \alpha>0 α>0 足够小,使得 o ( α ) α < ϵ ( sin μ ) / 2 \frac{o(\alpha)}\alpha<\epsilon(\sin\mu)/2 αo(α)<ϵ(sinμ)/2. 由于高价无穷小 o ( α ) o(\alpha) o(α) 对 k k k 是一致成立的,所以这样的 α \alpha α 与 k k k 无关.于是有
f ( x k ) − f ( x k + 1 ) ≥ 1 2 α ϵ sin μ . \begin{aligned}f(x_k)-f(x_{k+1})\geq\frac{1}{2}\alpha\epsilon\sin\mu.\end{aligned} f(xk)−f(xk+1)≥21αϵsinμ.又由于 k k k 是任意的,则这与 f ( x k ) − f ( x k + 1 ) → 0 ( k → ∞ ) f(x_{k})-f(x_{k+1})\to0(k\to\infty) f(xk)−f(xk+1)→0(k→∞) 矛盾.
实际上,如果函数 f f f 的光滑性能够被保证,一致锐角条件可以减弱,下面不加证明地给出下面的命题.(我就不贴上证明啦,看得我头疼~)
命题 2.2.4 (Zoutendijk) 设 f ∈ C 1 ( R n ) f\in C^1(\mathbb{R}^n) f∈C1(Rn) 有下界,梯度向量 ∇ f ( x ) \nabla f(x) ∇f(x) 在凸集 D ⊂ R n D\subset\mathbb{R}^n D⊂Rn 上 L i p s c h i t z Lipschitz Lipschitz 连续, x 0 ∈ D x_0\in D x0∈D 使得水平集 l e v f ( x 0 ) ( f ) ⊂ D \mathrm{lev}_{f(x_0)}(f)\subset D levf(x0)(f)⊂D.设以 x 0 x_0 x0 为初始点,当 ∇ f ( x k ) ≠ 0 \nabla f(x_k)\neq0 ∇f(xk)=0 时,采用如下搜索方向和搜索步长:
- 搜索方向: d k d_k dk 与 − ∇ f ( x k ) -\nabla f(x_k) −∇f(xk) 成锐角: ∇ f ( x k ) T d k < 0 \nabla f(x_k)^Td_k<0 ∇f(xk)Tdk<0, 且 ∥ d k ∥ 2 = 1 \|d_k\|_2=1 ∥dk∥2=1,
- 搜索步长:精确搜索或满足 W o l f e Wolfe Wolfe 准则
所得的迭代点列 { x k } \{x_k\} {xk} 满足:
∑ k = 0 ∞ ∥ ∇ f ( x k ) ∥ 2 2 cos 2 θ k < ∞ , \sum_{k=0}^\infty\|\nabla f(x_k)\|_2^2\cos^2\theta_k<\infty, k=0∑∞∥∇f(xk)∥22cos2θk<∞,其中 θ k \theta_k θk 表示 − ∇ f ( x k ) -\nabla f(x_k) −∇f(xk) 与搜索方向 d k d_k dk 的夹角,即 − ∇ f ( x k ) T d k = ∥ ∇ f ( x k ) ∥ 2 cos θ k . -\nabla f(x_k)^Td_k=\|\nabla f(x_k)\|_2\cos\theta_k. −∇f(xk)Tdk=∥∇f(xk)∥2cosθk.
推论 2.2.5 在命题 2.2.4的条件下,若 ∥ ∇ f ( x k ) ∥ 2 ≠ 0 , ∀ k ≥ 0 \|\nabla f(x_k)\|_2\neq0,~\forall k\geq0 ∥∇f(xk)∥2=0, ∀k≥0, 且满足条件 ∑ k = 1 ∞ cos 2 θ k = ∞ . \sum_{k=1}^\infty\cos^2\theta_k=\infty. ∑k=1∞cos2θk=∞., 则 lim ‾ k → ∞ ∥ ∇ f ( x k ) ∥ 2 = 0. \underline{\lim}_{k\to\infty}\|\nabla f(x_k)\|_2=0. limk→∞∥∇f(xk)∥2=0.
证. 设结论不成立,则存在 δ > 0 \delta> 0 δ>0, 使得 ∇ f ( x k ) ∥ 2 ≥ δ , ∀ k ≥ 0 \nabla f( x_k) \|_2\geq \delta, \forall k\geq 0 ∇f(xk)∥2≥δ,∀k≥0.于是
∑ k = 1 ∞ ∥ ∇ f ( x k ) ∥ 2 2 cos 2 θ k ≥ δ 2 ∑ k = 1 ∞ cos 2 θ k = ∞ , \begin{aligned}\sum_{k=1}^\infty\|\nabla f(x_k)\|_2^2\cos^2\theta_k&\ge\delta^2\sum_{k=1}^\infty\cos^2\theta_k=\infty,\end{aligned} k=1∑∞∥∇f(xk)∥22cos2θk≥δ2k=1∑∞cos2θk=∞,这与命题 2.2.4 的结论矛盾.