标准库中的string类(中)+仅仅反转字母+字符串中的第一个唯一字符+字符串相加——“C++”“Leetcode每日一题”
各位CSDN的uu们好呀,今天,继续小雅兰西嘎嘎的学习,标准库中的string类,下面,让我们一起进入西嘎嘎string的世界吧!!!
string类的常用接口说明
Leetcode每日一题
string类的常用接口说明
标准库中的string类(上)——“C++”-CSDN博客
string类对象的容量操作
max_size

max_size:能开的最大的大小空间!
int main()
{
string s1;
string s2("hello world");
cout << s1.max_size() << endl;
cout << s2.max_size() << endl;
return 0;
}
不同的编译器下 这个值都是不一样的!所以没有什么参考意义!
它说能开这么大的空间,但是实际上,真的能开这么大的空间吗?答案是不一定的!
reserve
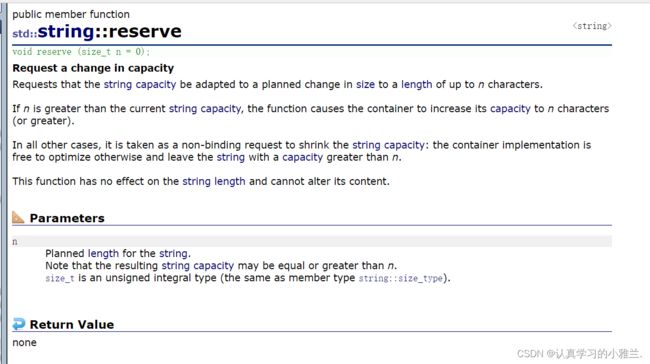 reserve 保留
reserve 保留
reverse 反转 逆置
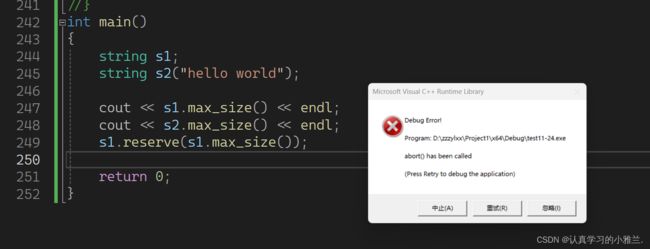 抛异常了!
抛异常了!
try
{
string s1;
string s2("hello world");
// 实践中没有参考和使用的价值
cout << s1.max_size() << endl;
cout << s2.max_size() << endl;
s1.reserve(s1.max_size());
}
catch (const exception& e)
{
cout << e.what() << endl;
}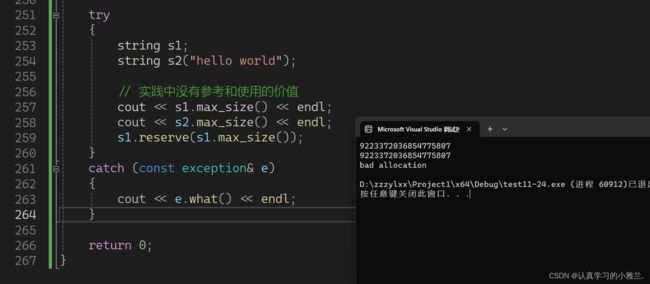
虽然这个东西没有什么价值,可是也不能把它删掉,现在的编译器只能向前兼容,因为怕之前有人用这个功能写了一个什么东西,本来用的好好的,结果编译器一更新,反而报错了!
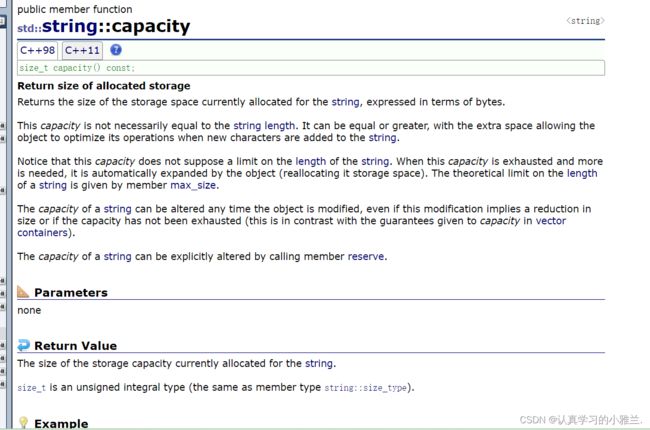
capacity
try
{
string s1;
string s2("hello world");
cout << s1.capacity() << endl;
cout << s2.capacity() << endl;
}
catch (const exception& e)
{
cout << e.what() << endl;
}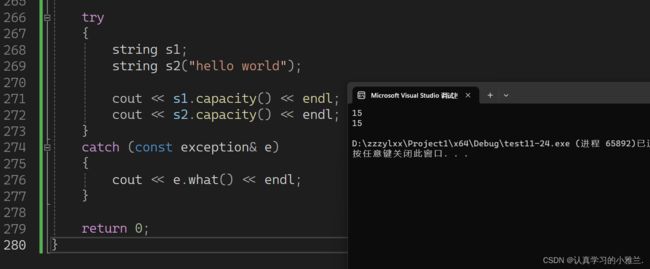 容量都是15!
容量都是15!
但是实际上,空间不是开了15,而是开了16!
为什么开了16呢?因为在这个地方,容量不是指的开的多大的空间,它是指的我到底能存多少有效字符!为什么这两个东西不同呢?空间是多大和到底能存储多少个有效字符为什么不是等价的呢?因为有‘\0’,在结尾处标识的这个‘\0’不算有效字符!
现在capacity是15,代表我能存储15个有效字符,但是我空间必须得多开一个,用来放'\0'!
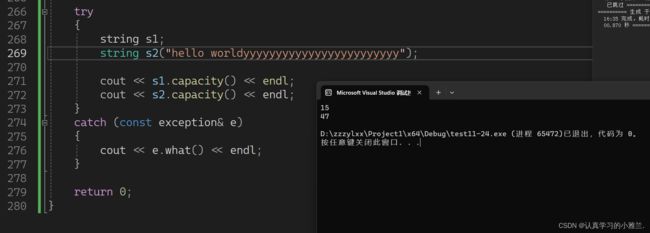
现在,这个capacity的值就变了!实际上开的空间大小是48!!!
下面,我们可以来检测一下string的扩容机制:
int main()
{
try
{
string s1;
string s2("hello worldxxxxxxxxxxxxx");
size_t old = s1.capacity();
cout << old << endl;//检测string的扩容机制
for (size_t i = 0; i < 500; i++)
{
s1.push_back('x');
if (old != s1.capacity())
{
cout << s1.capacity() << endl;
old = s1.capacity();
}
}
}
catch (const exception& e)
{
cout << e.what() << endl;
}return 0;
}
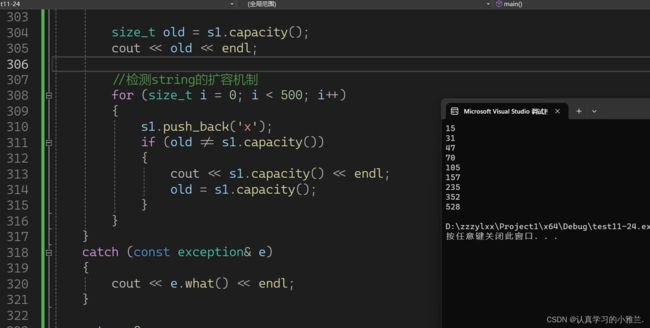
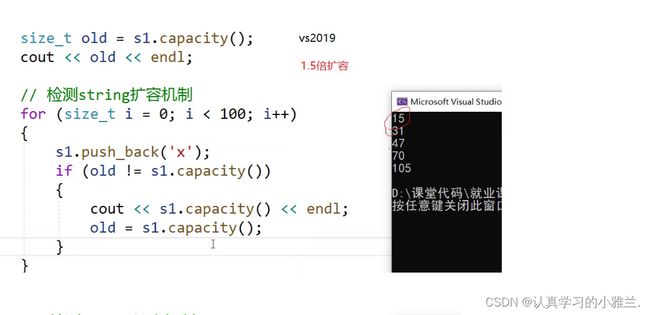

不同的编译器下,扩容机制也是不一样的!
但是扩容的代价是非常大的,所以:确定需要多少空间,提前开好空间即可!
s1.reserve(500);
但是不一定是开500,也有可能比500大!!!
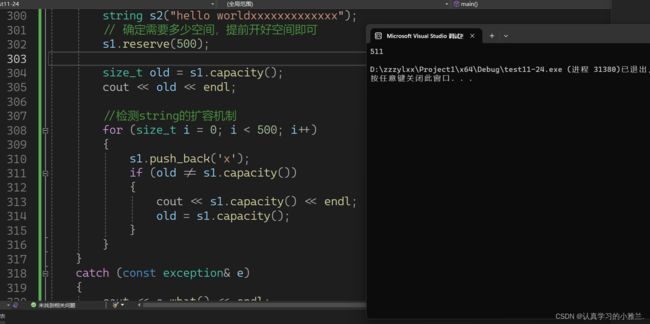 但是开了511!
但是开了511!

研究这个其实也是没有意义的!因为不同的编译器下所做的不同,VS下就进行了对齐!!!
所以有的时候,尤其是一些和空间、容量相关的代码,在不同的平台下,所运行的结果不同,这是可以理解的!!!
| 函数名称 | 功能说明 |
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty(重点) | 检测字符串释放为空串,是返回true,否则返回false |
| clear(重点) | 清空有效字符 |
| reserve(重点) | 为字符串预留空间 |
| resize(重点) | 将有效字符的个数该成n个,多出的空间用字符c填充 |
注意:
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一 致,一般情况下基本都是用size()。
- clear()只是将string中有效字符清空,不改变底层空间大小。
- resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
- reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
resize

reserve是用来扩容的,那么它会不会缩容呢?
int main()
{
string s1;
cout << s1.capacity() << endl;
s1.reserve(10);
cout << s1.capacity() << endl;
string s2("hello worldxxxxxxxxxxxxx");
cout << s2.capacity() << endl;
s2.reserve(10);
cout << s2.capacity() << endl;
return 0;
}
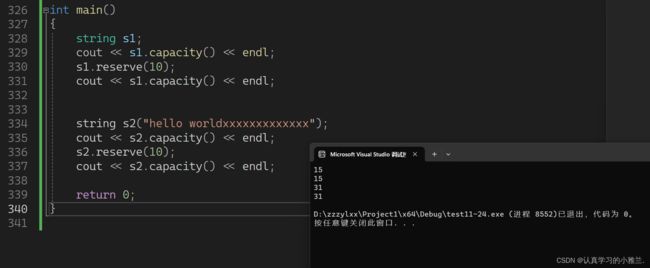
不管是有数据还是没数据,reserve都是不会缩容的!可以理解为reserve仅仅是用来扩容的!
缩容的代价比较大!!!
但是:在不同的编译器下,所产生的结果仍然是不一样的!在Linux下,就会缩容;在VS下,就不会缩容!
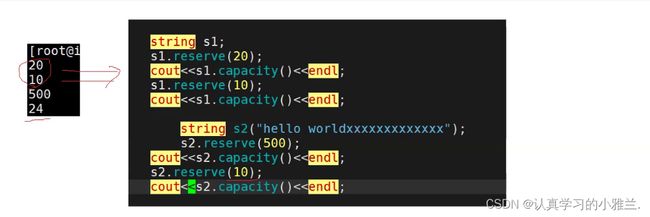
在Linux下,确实会缩容,但是这个缩容又比较“怪异”,如果是有数据的情况下,缩容后的容量比现有的size还要小,不会删除数据,最小缩到size!!!
综上所述:reserve只影响空间(容量),不影响数据!
可是:resize就不一样了!它既影响容量,也影响数据!

int main()
{
string s1("hello world");
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << s1 << endl;
s1.resize(100);
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << s1 << endl;
return 0;
}
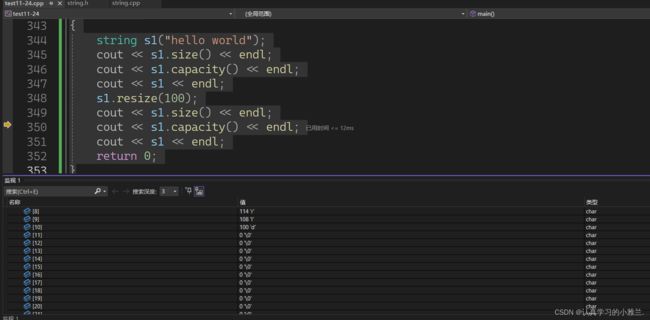
int main()
{
string s1("hello world");
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << s1 << endl;
//> capacity
//s1.resize(100);
s1.resize(100, 'x');
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << s1 << endl;
// size < n < capacity
string s2("hello world");
cout << s2.size() << endl;
cout << s2.capacity() << endl;
cout << s2 << endl;
s2.resize(12);
cout << s2.size() << endl;
cout << s2.capacity() << endl;
cout << s2 << endl;
return 0;
}当size < n < capacity时,在VS下,也不会缩容!
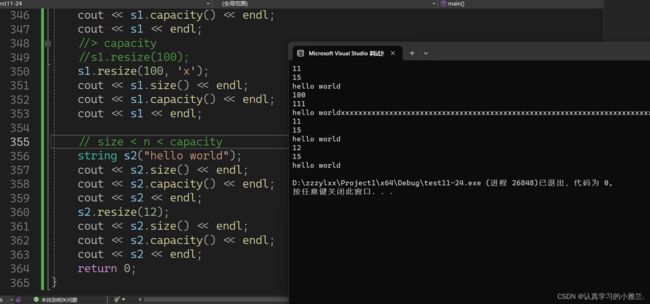
int main()
{
string s1("hello world");
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << s1 << endl;
//> capacity 扩容+尾插
//s1.resize(100);
s1.resize(100, 'x');
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << s1 << endl;
// size < n < capacity 尾插
string s2("hello world");
cout << s2.size() << endl;
cout << s2.capacity() << endl;
cout << s2 << endl;
s2.resize(12);
cout << s2.size() << endl;
cout << s2.capacity() << endl;
cout << s2 << endl;
// n < size 删除数据,保留前n个
string s3("hello world");
cout << s3.size() << endl;
cout << s3.capacity() << endl;
cout << s3 << endl;
s3.resize(10);
cout << s3.size() << endl;
cout << s3.capacity() << endl;
cout << s3 << endl;
return 0;
} 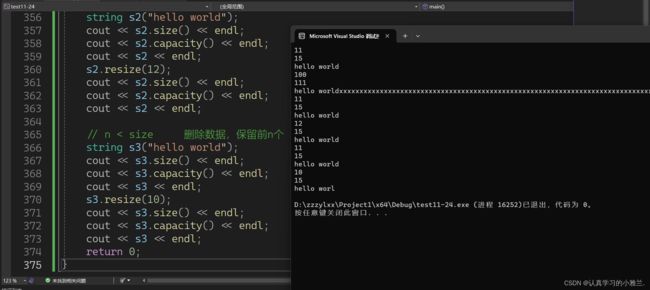
那在Linux下,又是不是这样呢?
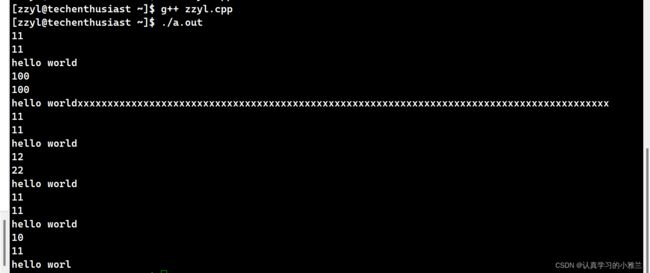
我们会发现,在Linux下,resize也是不会缩容的!!!

at
int main()
{
try
{
string s1("hello world");
cout << s1[11] << endl;
cout << s1[20] << endl;
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
}
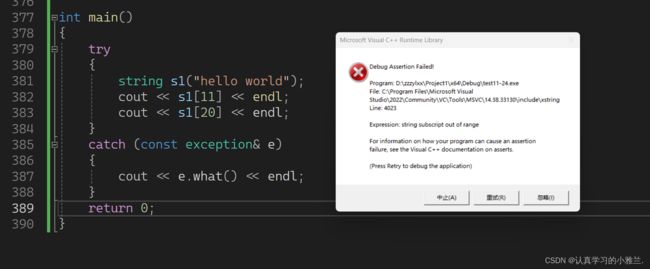 在C语言中,数组越界访问是不会报错的,可是在西嘎嘎中,就报错了!
在C语言中,数组越界访问是不会报错的,可是在西嘎嘎中,就报错了!
at和[]的功能是一样的!!!
int main()
{
try
{
string s1("hello world");
cout << s1[11] << endl;
//cout << s1[20] << endl;
cout << s1.at(20) << endl;
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
}
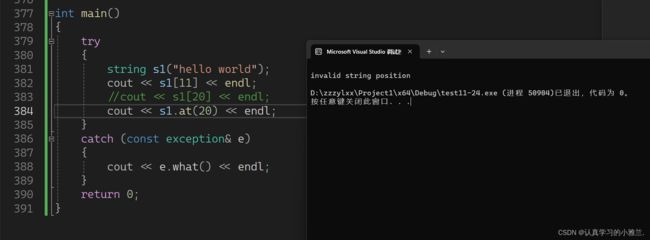 一个是偏暴力一点的检查,一个是偏温柔一点的检查!
一个是偏暴力一点的检查,一个是偏温柔一点的检查!
一般是用[]比较多,也就是偏暴力一点!
 剩下的back和front是C++11的新特性!
剩下的back和front是C++11的新特性!
string类对象的修改操作
- 增 +=(push_back/append)/insert
- 删 erase
- 查 []
- 改 []/at/迭代器
| 函数名称 | 功能说明 |
| push_back | 在字符串后尾插字符c |
| append | 在字符串后追加一个字符串 |
| opeator+= | 在字符串后追加字符串str |
| C str | 返回C格式字符串 |
| find+npos | 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置 |
| rfind | 从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
注意:
- 在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
- 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
append

int main()
{
string s1("hello");
s1.push_back(' ');
s1.append("world");
cout << s1 << endl;
return 0;
}
int main()
{
string s1("hello");
s1.push_back(' ');
s1.append("world");
cout << s1 << endl;
string s2 = "xxxx";
const string& s3 = "xxxxxxxx";
s2.append(++s1.begin(), --s1.end());
cout << s2 << endl;
return 0;
} 
但是,不管是push_back还是append,都不是西嘎嘎最喜欢用的,西嘎嘎最喜欢用的是这个:
operator+=
int main()
{
string s1("hello");
s1.push_back(' ');
s1.append("world");
cout << s1 << endl;string s2 = "xxxx";
const string& s3 = "xxxxxxxx";
s2.append(++s1.begin(), --s1.end());
cout << s2 << endl;s1 += '!';
s1 += "xxxxx";
s1 += s2;
cout << s1 << endl;
return 0;
}

Leetcode每日一题
仅仅反转字母
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
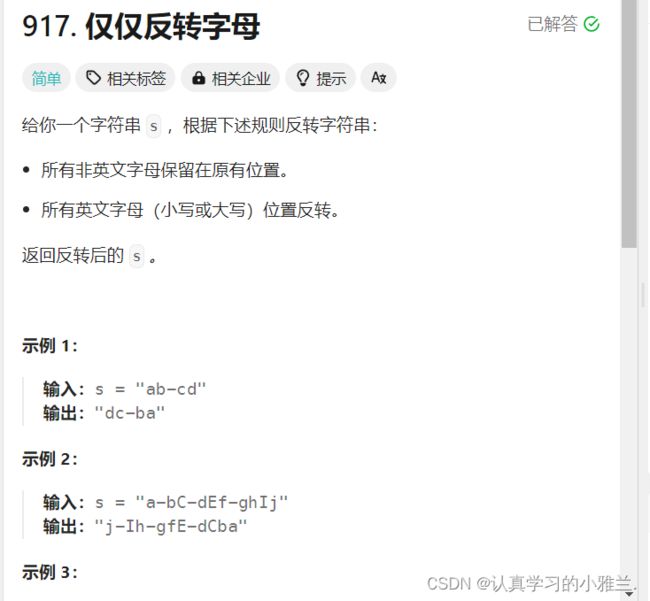

class Solution {
public:
bool isLetter(char ch)
{
if(ch >= 'a' && ch <= 'z')
return true;
if(ch >= 'A' && ch <= 'Z')
return true;
return false;
}
string reverseOnlyLetters(string S) {
if(S.empty())
return S;
size_t begin = 0, end = S.size()-1;
while(begin < end)
{
while(begin < end && !isLetter(S[begin]))
++begin;
while(begin < end && !isLetter(S[end]))
--end;
swap(S[begin], S[end]);
++begin;
--end;
}
return S;
}
}; 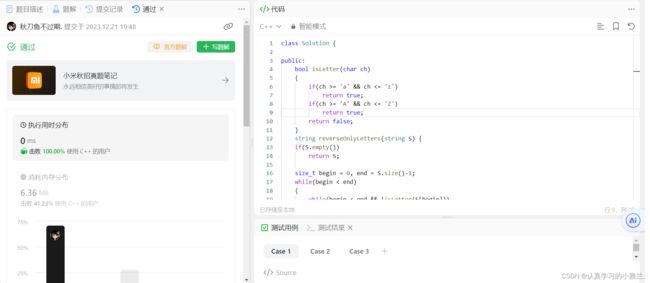
字符串中的第一个唯一字符

class Solution {
public:
int firstUniqChar(string s) {
int count[26]={0};
for(auto ch:s)
{
count[ch-'a']++;
//'a'的ASCII码值是97
//计数
}
//找第一个只出现一次的
//再次遍历,拿到每个字符
for(size_t i=0;i 
另一种写法:
class Solution {
public:
int firstUniqChar(string s) {
// 统计每个字符出现的次数
int count[256] = {0};
int size = s.size();
for(int i = 0; i < size; ++i)
count[s[i]] += 1;
// 按照字符次序从前往后找只出现一次的字符
for(int i = 0; i < size; ++i)
if(1 == count[s[i]])
return i;
return -1;
}
};
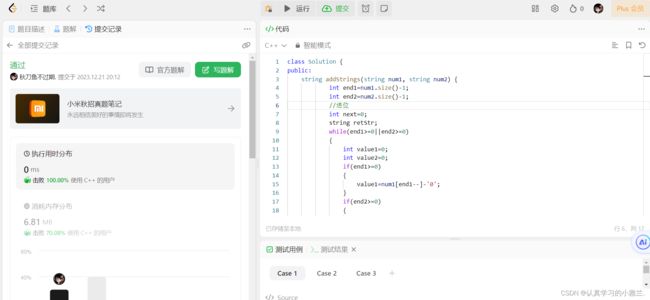
字符串相加

“大数运算”
class Solution {
public:
string addStrings(string num1, string num2) {
int end1=num1.size()-1;
int end2=num2.size()-1;
//进位
int next=0;
string retStr;
while(end1>=0||end2>=0)
{
int value1=0;
int value2=0;
if(end1>=0)
{
value1=num1[end1--]-'0';
}
if(end2>=0)
{
value2=num2[end2--]-'0';
}
int ret=value1+value2+next;
next=ret/10;
ret=ret%10;
retStr+=('0'+ret);
}
if(next==1)
{
retStr+='1';
}
reverse(retStr.begin(),retStr.end());
return retStr;
}
};
好啦,小雅兰今天的string类的使用以及Leetcode每日一题的内容就到这里啦,下篇博客继续string类的使用!!!加油!!!奥利给!!!
