awk 命令详解
1. 编写 awk 脚本基础
1.1 Hello,World
通过演示“Hello,World”这个程序来介绍一种程序设计语言。通过演示这个程序在 awk 中如何工作将证明 awk 是如何的不寻常。实际上,有必要演示几种打印“Hello,World”的不同方法。
在第一个例子中,我们创建了一个文件,命名为 test,它只包含一个句子。这 个例子是一个包含 print 语句的脚本:
[root@ufo666 ~]# echo 'this line of data is ignored' > test
[root@ufo666 ~]# awk '{print "Hello,world"}' test
Hello,world
这个脚本只有一条包含在大括号中语句。这个操作对每个输入行执行 print 语句。在 test 文件中只包含一行,因此, print 操作只执行一次。注意这个输入行将被读入但没有被输出。
现在让我们看另外一个例子,这里使用一个包含“Hello,World.”行的文件。
[root@ufo666 ~]# echo 'this line of data is ignored' > test
[root@ufo666 ~]# awk '{print}' test
this line of data is ignored
在这个例子中,“this line of data is ignored”出现在输入文件中,得到了相同的结果。因为其中的 print 语句没有参数,只简单的输出每个输入行。如果文件中有其他的输入行,他们同样可以被输出。
这两个例子都说明了 awk 是输入驱动的。也就是说,除非有可以在其上操作的输入行,否则将什么也不能做。当调用 awk 程序时,它将读入所提供的脚本,并检查其中的指令的语法。然后 awk 将对每个输入行执行脚本中的指令。因此,如果没有来自文件中的输入行,以上的 print 语句将不做任何事情。
为了验证这一点,可以输入第一个例子中的命令行,但忽略文件名。你将发现由于 awk 期望得到来自键盘的输入,所以它将一直等待直到对它提供了输入:
[root@ufo666 ~]# awk '{print}'
666 <-- 键盘输入
666 <-- 回车
777 <-- 键盘输入
777 <-- 回车
这个方法的实现和 BEGIN 模式是相关的, BEGIN 模式用于指定的第一个输入行读入之前要执行动作。
[root@ufo666 ~]# awk 'BEGIN{print "Hello,World"}'
Hello,World
Awk 打印这个消息,然后退出程序。如果一个程序只有一个 BEGIN模式,并且没有其他的语句, awk 将不处理任何输入文件。
1.2 awk 程序设计模型
awk 程序是由所谓的主输入(main input) 循环组成的。一个循环是一个例程,它将一直重复执行直到有一些存在的条件终止它。你不必写这个循环,他是现成的,它作为一个框架存在,在这个框架中你编写的代码就能够执行。
主输入循环执行的次数和输入的行数相同,当没有其他输入行读入是循环将终止。所编写的执行操作将应用于每个输入行,而且一次一行。
awk 允许你编写两个特殊的例程,他们在任何输入被读取前和所有输入都被读取后执行。他们是与 BEGIN 和 END 规则相关的过程。换句话说,在主输入循环执行前和主输入循环钟之后你可以做一些处理。BEGIN 和END 过程是可选的。

1.3 模式匹配
当 awk 读入一行时,它试图匹配脚本中的每个模式匹配规则。只有与一个特定的模式相匹配的输入行才能成为操作对象。如果没有指定操作,与模式相匹配的输入行将被打印出来(执行打印语句是一个默认操作)。
[root@ufo666 ~]# echo -e "AAA\nBBB" | awk '/AAA/'
AAA
[root@ufo666 ~]# echo -e "AAA\nBBB" | awk '/AAA/{print "123456"}'
123456
[root@ufo666 ~]# echo -e "AAA\nBBB" | awk '/[AB]/{print "123456"}'
123456
123456
[root@ufo666 ~]# echo '/[AB]/{print "123456"}' > test
[root@ufo666 ~]# echo -e "AAA\nBBB" | awk -f test
123456
123456
[root@ufo666 ~]# echo -e "AAA\nBBB" > ufo
[root@ufo666 ~]# awk -f test ufo
123456
123456
# 大括号之前的正则,格式相对比较固定,一般不对整体范围取反,含义比较混乱。以下并不是 A-C 之外的正则。
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '!/A/,!/C/{print $0}'
BBB
CCC
DDD
# 多行模式的单行简写法
[root@ufo666 ~]# echo -e "AAA\nBBB" | awk '/A/{print "123456"};/B/{print "123456"}'
123456
123456
1.4 程序脚本的注释
在写脚本时添加注释是一个好的习惯。注释以字符“#”开始,以换行符结束。
注意:如果以命令行的方式提供 awk 程序,而不是将它写入一个文件中,那么在程序的任何地方都不能用单引号,否则 shell 将对它进行解释而导致错误。当我们开始编写脚本时,我们将用注释来对脚本进行描述:
[root@ufo666 ~]# cat test
# 12345
/[AB]/{print "123456"}
# 12345
[root@ufo666 ~]# echo -e "AAA\nBBB" | awk -f test
123456
123456
1.5 记录和字段
awk 假设它的输入是有结构的,而不只是一串无规则的字符。在最简单的情况下,它将每个输入行作为一条记录,而将由空格或制表符分隔的单词作为字段 (用来分隔字段的字符被称为分隔符)。
注意:连续的两个或多个空格和/或制表符被作为一个分隔符。
[root@ufo666 ~]# echo -e "AAA BBB CCC DDD" | awk '/A/{print $1,$2,$3,$4}'
AAA BBB CCC DDD
1.6 字段和引用的分离
awk 允许使用字段操作符$来指定字段。在该操作符后面跟着一个数字或变量,用于标识字段的位置。”$1”表示第一个字段,”$2”表示第二个字段等等。“$0”表示整个输入记录。NF 是每行字段的总数量。
# “\t”是表示一个实际的制表符的转义序列,它应由单引号或 双引号包围着。
[root@ufo666 ~]# echo -e "AAA\tBBB\tCCC\tDDD" | awk -F"\t" '/A/{print $1,$2,$3,$4}'
AAA BBB CCC DDD
[root@ufo666 ~]# echo -e "AAA\tBBB\tCCC\tDDD" | awk -F"A" '/A/{print $1,$2,$3,$4}'
BBB CCC DDD
# 读取倒数第二个字段
[root@ufo666 ~]# echo -e "AAA\tBBB\tCCC\tDDD" | awk -F"\t" '/A/{print $(NF-1)}'
CCC
[root@ufo666 ~]# echo -e "AAA\tBBB\tCCC\tDDD" | awk '/A/{print $1"---"$2"---"$3"---"$4}'
AAA---BBB---CCC---DDD
# 每个 print 包含一个换行
[root@ufo666 ~]# echo -e "AAA\tBBB\tCCC\tDDD" | awk '/A/{print $1"---"$2; print $3"---"$4}'
AAA---BBB
CCC---DDD
也可以通过定义系统变量 FS 来改变字段分隔符。因为这个必须在读取第一个输入行之前执行,所以必须在由 BEGIN 规则控制的操作中指定这个变量。也可以通过指定选项 F 来改变字段分隔符。
[root@ufo666 ~]# echo -e "AAA\tBBB,\tCCC\tDDD" | awk 'BEGIN{FS=","};/A/{print $0; print $1"---"$2}'
AAA BBB, CCC DDD
AAA BBB--- CCC DDD
通过正则来匹配输入范围:
# ! 取反, 不能对整体范围取反,常见的是单行取反。
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '/A/{print $0}'
AAA
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '!/A/{print $0}'
BBB
CCC
DDD
# 匹配范围,一旦第一个匹配到开始点,就会寻找第二个停止点,循环往复。(多行的正则匹配语法)
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '/A/,/C/{print $0}'
AAA
BBB
CCC
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD\nAAA\nBBB" | awk '/A/,/C/{print $0}'
AAA
BBB
CCC
AAA
BBB
# 如果没有字符F,直接巡检匹配到行的结束
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '/A/,/F/{print $0}'
AAA
BBB
CCC
DDD
第N个字段匹配或不匹配某个字串时,打印输出。
[root@ufo666 ~]# echo -e "AAA SSS \nBBB\nCCC\nDDD" | awk '$2~/SSS/{print $0}'
AAA SSS
[root@ufo666 ~]# echo -e "AAA SSS \nBBB\nCCC\nDDD" | awk '$2!~/SSS/{print $0}'
BBB
CCC
DDD
通过行号来匹配输入范围,常见用法是正则在大括号之前,行号在大括号之中。NR表示总的输入行号,它会在每个文件中自动递增。FNR表示当前正在处理的文件中的行号,它在每个文件中从1开始递增。
awk '{print "NR:", NR, "FNR:", FNR, $0}' A文件 B文件
NR: 1 FNR: 1 A文件Line 1
NR: 2 FNR: 2 A文件Line 2
NR: 3 FNR: 1 B文件Line 3
NR: 4 FNR: 2 b文件Line 4
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '{if(NR==2) print $0;}'
BBB
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '{if(NR > 2) print $0;}'
CCC
DDD
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk '{if(NR > 2 || NR == 1) print $0;}'
AAA
CCC
DDD
# 如何打印倒数第2行?
# 可以利用数组存储每一行内容,直接输出倒数第二行,但是效率比较低,要先存储所有行。
awk '{lines[NR] = $0} END{print lines[NR-1]}'
1.7 字段的划分:完整的问题
可以使用3个完全不同的方法使 awk 分隔字段。
第一个方法是用空白字符来分隔字段。要实现这种方法,可将FS设置为一个空格。在这种情况下,记录的前导空白字符和结尾空白字符 (空格、制表符) 将被忽略。并且字段空格或制表位来分隔。因为 FS 的默认值为一个空格,所以这也是通常情况下 awk 将记录划分为字段的方法。(默认连续的空白或制表符被认为是一个字段分隔符)
第二个方法是使用其他单个字符来分隔字段。例如, awk 程序经常使用“:”作为分隔符来访问 UNIX /etc/passwd 文件。当FS表示任何单个字符时,在这个字符出现的任何地方都将分隔出另外一个字段。如果出现两个连续的分隔符,在它们之间的字段值为空串。
最后一种方法是,如果你设置了不止一个字符作为字段分隔符,它将被作为一个正则表达式来解释。也就是说,字段分隔符将是与正则表达式匹配的“最左边最长的非空的不重叠的”字符。
# 默认分隔符(空格,制表符),FS内置变量决定。
[root@ufo666 ~]# echo -e "AAA SSS BBB\tDDD\t\tEEE" | awk '{print $1,$2,$3,$4,$5}'
AAA SSS BBB DDD EEE
[root@ufo666 ~]# echo -e " \tAAA SSS BBB\tDDD\t\tEEE \t " | awk '{print $1,$2,$3,$4,$5}'
AAA SSS BBB DDD EEE
# 使用指定个数的字符整体作为分隔符
[root@ufo666 ~]# echo -e " \tAAA SSS BBB\tDDD\t\tEEE \t " | awk -F"\t+" '{print $1,$2}'
AAA SSS BBB
[root@ufo666 ~]# echo -e " \tAAA SSS BBB\tDDD\t\tEEE \t " | awk -F"\t{n=2}" '{print $1,$2}'
AAA SSS BBB DDD EEE
[root@ufo666 ~]# echo -e ":;AAA::BBB;:CCC" | awk -F":" '{print $1;print $1,$2;print $1,$2,$3;print $1,$2,$3,$4;print $1,$2,$3,$4,$5}'
;AAA
;AAA
;AAA BBB;
;AAA BBB; CCC
# 指定多个分隔符
[root@ufo666 ~]# echo -e ":;AAA::BBB;:CCC" | awk -F"[:;]" '{print $1;print $1,$2;print $1,$2,$3;print $1,$2,$3,$4;print $1,$2,$3,$4,$5}'
AAA
AAA
AAA BBB
1.8 表达式
可以使用表达式来存储、操作和检索数据,这些操作与 sed 中的有很大的区别,但这是大多数程序设计语言所具有的共同特性。一个表达式通过计算返回一个值。表达式由数字和字符串常量、变量、操作符、函数和正则表达式组成。
常量有两种类型:字符串型或数字型(“red”或1)。字符串在表达式中必须用引号括起来。在字符串中可以使用以下列出的转义序列。


变量是引用值的标识符。定义变量只需要为它定义一个名字并将数据赋给它即 可。变量名只能由字母、数字和下划线组成。而且不能以数字开头。变量名的 大小写很重要: Salary 和 salary 是两个不同的变量,变量不必进行说明,你 不必告诉 awk 什么类型的数据存储在一个变量中。每个变量有一个字符串型值 和数字型值, awk 能够根据表达式的前后关系来选择合适的值(不包含数字的 字符串值为0)。变量不必初始化。 awk 自动将它们初始化为空字符串,如果作 为数字,它的值为0。下面的表达式表示将一个值赋给x:
x=1
x 是变量的名字、=是一个赋值操作符,1是一个数字常量。下面的表达式表示将字符串“Hello”赋给z:
z="Hello"
空格是字符串连接操作符,表达式:
z="Hello" "World"
将两个字符串连接在一起,并将结果“HelloWorld”赋给变量z。
美元符号($)是引用字段操作符。下面的表达式表示把当前输入记录的第一个字段的值赋予变量w:
w=$1
多种操作符可以用在表达式中。以下列出了算术操作符。

一旦变量被赋予了一个值,那么就可以用这个变量名来引用这个值。下面的表达式表示将变量x的值和1相加并将结果赋给变量y:
y=x+1
即计算x的值,使它加1,并将结果赋给变量y。语句:
print y
打印y的值。如果下面的一系列语句将出现在脚本中:
x=1
y=x+1
print y
那么y的值为2。我们可以将这3个语句减少为两个:
x=1
print x + 1
注意, print 语句后面的x的值却仍为1。我们没有变量x的值,我们只是将它和1相加并打印结果。换句话说,如果第三个语句是 print x,那么将输出1。实际上,如果我们想将x的值增加,我们可以用赋值操作符+=。这个操作符组合了两个操作符:它将1和x的值相加并将结果赋给x。以下列出了 awk 表 达式中的赋值操作符。

下面的例子用于计算一个文件中空行的目录。
#统计空行数
/^$/{
print x += 1
}
虽然这里没有为变量x赋初值。但在遇到第一个空行之前它的值一直为0。表达式 x+=1 在每次遇到空行时进行求值并将x的值增加 1。print 语句打印表达式返回的值。因为我们在遇到每个空行时都执行 print 语句,所以我们得到了空行数的一个连续值。
表达式可以表示为不同形式,有些和其他相比更简洁。表达式x+=1 比等价的表 达式: x=x+1 更简洁。但这两个都没有下面这个表达式简洁:
++X
“++”是递增操作符(“--”是递减操作符)。表达式每计算一次变量的值就增加1。递增和递减操作符可以出现在操作数的任何一边,与前缀或后缀操作符一样。位置不同可以得到不同的计算结果。
++x 在返回结果前递增x的值(前缀)
x++ 在返回结果后递增x的值(后缀)
例如,如果将以上例子写为:
/^$/{
print x++
}
当遇到第一个空行时,表达式返回的值为“0“,遇到第二个空行时返回值为 “1”,依此类推。如果将递增操作符放置与x的前面,当表达式第一次计算 后,返回的值为“1”。
下面我们在上例中使用递增表达式。另外,在每次遇到空行时不要再打印空行的数值,而是计算所有空行的值后才打印空行的总数。在END 模式中放置 print 语句,当读完最后一个空行后打印x的值。
#统计空行数
/^$/{
++x
END{
print x
}
1.9 系统变量
awk 中有许多系统变量或内置变量。awk 有两种类型的系统变量。第一种类型定义的变量默认值可以改变,例如默认的字段和记录分隔符。第二种类型定义的变量的值可用于报告或数据处理中。例如当前记录中字段的数量,当前记录的数量等。这些可以由 awk 自动更新,例如,当前记录的编号和输入文件名。
有一组默认值会影响对记录和字段的输入和输出的识别。系统变量 FS 定义字段分隔符。它的默认值为一个空格,这将提示 awk 可以用若干个空格或制表符来分隔字段。FS可以被设置为任何单独的字符或一个正则表达式。FS等效的输出是 OFS,它的默认值为一个空格。
awk 将变量 NF 定义为当前输入记录的字段个数。改变 NF 的值会有副作用。当 $0(字段)和NF被改变时将产生令人费解的相互作用,尤其是当 NF 减小时。增加NF值会创建新的(空的)字段,并重新建立$0,字段由 OFS的值来分隔。在 NF 减小的情况下, gawk 和 mawk 重新建立记录,超过新的NF值 的字段被设置为一个空字符。Bell Labs awk 没有改变$0。
awk 还定义了记录分隔符 RS 为一个换行符。RS 有一点例外,它是 awk 仅仅注意 =它的值的首字符的唯一变量。和RS输出等价的是 ORS,它的默认值也是一个换行符。
awk 设置变量 NF 为当前输入记录的编号。它可以用来给列表中的记录编号。变量FILENAME 中包含了当前输入文件的名称。当应用多个输入文件时,变量 FNR 被用来表示与当前输入文件相关的当前记录的代码。
通常情况下,因为希望在读入第一个输入行之前设置字段和记录分隔符的值。所以可以在 BEGIN 过程中定义它们。然而,也可以在脚本的任何位置重定义它们的值,在 POSIX awk 中为 FS 赋值不影响当前的输入行,它仅影响下一个输入行。
最后, POSIX 增加了一个新的变量 CONVFMT,它用来控制数字到字符串的转换。例如:
"得分结果是:" (5.5+3.2)
这里的数字表达式5.5+3.2(结果是8.7)的值,必须在它被用于字符串的连接之前转换为一个字符串。CONVFMT 控制这种转换,它的默认值为“%.6g“,这是一个用于浮点型数据的 printf 风格的格式说明。例如,将 CONVFMT 改变为 “%d”,将使所有的数字作为整数转变为字符串。在 POSIX标准之前, awk 使 用 OFMT 来实现这个功能。OFMT可以做相同的工作,但是控制执行 print 语句时进行数据的转换。POSIX 委员会想将输出转换的任务从简单的字符串转换中 独立出来。注意,证书转换为字符串时总是作为整数看待,而不管 CONVFMT 和 OFMT 的值是什么。
当读入最后一行后, NF 的值是读入的输入记录的个数。它可用于 END 过程中来产生总结报告。
1.10 处理多行记录
我们所有的例子中用到的输入文件其记录都是由单独一行组成的。在这一部分,我们将演示如何读入一个记录,而记录中的每个字段都由单独一行组成。
为了处理这种包括多行数据的记录,我们可以将字段分隔符定义为换行符,换 行符用“\n”来表示,并将记录分隔符设置为空字符串,它代表一个空行。
[root@ufo666 ~]# cat test
John Robinson
Koren Inc.
978 Commonwealth Ave.
Boston
MA 01760
696-0987
[root@ufo666 ~]#
[root@ufo666 ~]# awk 'BEGIN{FS="\n";RS=""}{print $1,$NF}' test
John Robinson 696-0987
FS:输入行字段分隔符
RS:输入行的记录分符
OFS:输出行字段分隔符
ORS:输出行的记录分符
NF:每行字段的总数
NR:单个文件输入时,累计的总行数
FNR:多个文件输入时,累计的总行数
[root@ufo666 ~]# echo -e "AAA BBB CCC DDD" | awk 'BEGIN{OFS="\n"}{print $1,$2,$3,$4}'
AAA
BBB
CCC
DDD
[root@ufo666 ~]# echo -e "AAA\nBBB\nCCC\nDDD" | awk 'BEGIN{FS="\n";RS=""};{print $3}'
CCC
1.11 关系操作符和布尔操作符
关系操作符和布尔操作符用于在两个表达式之间进行比较。


注意:关系操作符“==(相等)”和赋值操作符“=(等于)”是不同的。用 “=”代替“==”来检测相等性是一个普通的错误。
[root@ufo666 ~]# echo -e "AAA BBB CCC DDD" | awk '/A/{print $3}'
CCC
[root@ufo666 ~]# echo -e "AAA BBB CCC DDD" | awk '$1~/A/{print $3}'
CCC
[root@ufo666 ~]# echo -e "AAA BBB CCC DDD" | awk '$1~AAA{print $3}'
CCC
正则表达式经常用斜杠包围。这经常被作为正则表达式常量。然而,也常常不局限于正则表达式常量。当使用关系操作符 ~(匹配)或 !~ (不 匹配)时,右边的表达式可以是 awk 中的任意表达式。
[root@ufo666 ~]# echo -e "AAA BBB CCC DDD" | awk 'BEGIN{x="A"};$1~x{print $3}'
CCC
说明:当调用 match()、split ()、sub()个 gsub ()函数时,也可以使用字符串代替正则表达式常量。
使用布尔操作符可以将一系列的比较组合起来。

给定两个或多个表达式,只有当给定的表达式之一的值为真(非零或非空)时,使用操作符||的等个表达式的值才为真。而只有当&&操作符连接的两个表达式的值都为真时结果才为真。&&比||的优先级别高,但是可以用圆括号来改变优先规则。
shell 使用$*变量来扩展通过命令行传递的所有变量(这里可以使用$1来传递第一个变量,但是传递所有的变量将具有更大的灵活性)。
[root@ufo666 ~]# cat test
#! /bin/bash
x=$*
echo "$*"
echo "$*" | awk '{x1=$1;print x1}'
echo -e "AAA BBB CCC DDD" | awk '$1~x1{print $3}'
[root@ufo666 ~]#
[root@ufo666 ~]# sh test A B C
A B C
A
CCC
[root@ufo666 ~]# echo -e "AAA BBB\nCCC DDD" | awk 'BEGIN{x="A"};$1~x1 && $2 ~ "BBB"{print $1,$2}'
AAA BBB
1.12 格式化打印
到现在为止,我们编写的许多脚本可以很好地实现对数据的操作,但没有对输 出进行适当的格式化。这是因为基本的 print 语句所能做的工作有限。因为 awk 的大多数功能是产生报告,因此以整齐的样式产生格式化报告是很重要 的。
awk提供的printf可以代替print 语句,printf是借用了C程序设计语言。Printf语句和print语句一样可以打印一个简单的字符串。
[root@ufo666 ~]# awk 'BEGIN { printf ("Hello,world\n")}'
Hello,world
首先可以看出,printf和print 的主要区别是printf没有提供自动换行功能。必须明确地为它指定“\n”。
Printf语句的完整语法由两部分组成:
printf ( for mat-expression [, ar guments] )
其中的圆括号是可选的。第一部分是一个用来描述格式的表达式,通常以引号括起的字符串常量的形式提供。第二部分是一个参数列表,例如变量名列表,它和格式说明符相对应。格式说明符如下:


[root@ufo666 ~]# awk 'BEGIN {
> str = "hello";
> dec = 1234;
> float = 12.345;
> hex = 0x1A;
> oct = 077;
>
> printf("String: %s\n", str);
> printf("Decimal: %d\n", dec);
> printf("Float: %.2f\n", float); # 精度为2位小数
> printf("Hexadecimal: %x\n", hex);
> printf("Octal: %o\n", oct);
> }'
String: hello
Decimal: 1234
Float: 12.35
Hexadecimal: 1a
Octal: 77
Print语句输出数值的默认精度可以通过设置系统变量OFMT来改变。例如,可以将OFMT设置为 “%.2f”。
1.13 向脚本传递参数
在awk 中,一个容易引起混乱的地方就是想脚本传递参数。参数将值赋给一个变量,这个变量可以在awk脚本中访问。这个变量可以在命令行上设置,放在脚本的后面,文件名前面。
awk scriptfile var=value inputfile
每一项都必须作为单一的参数来解释。因此,在等号的两边不允许出现空格。也可以用这个方法传递多个参数。例如,如果想在命令行定义变量high和low,可以用下面的代码调用awk :
awk -f scriptfile high=100 low=60 datafile
在脚本中,这两个变量可以作为 awk 的任何变量来访问。如果要将这以脚本写入一个shell脚本的实现中,则可以以数值的形式传递shell的命令行参数(shell按位置提供了命令行参数变量:$1表示第一个参数,$2表示第二个参数,依此类推)。例如,参阅前面命令的shell脚本:
awk -f scriptfile "high=$1" "low=$2" datafile
awk 'BEGIN{"high=$1";"low=$2"}{...}' datafile
awk '{...}' "high=$1" "low=$2" datafile
另外,环境变量或命令的输出结果也可以作为变量的值来传递。这里有两个例子:
awk '{ ... }' directory=$cwd file1 ...
awk '{ ... }' directory=`pwd` file1 ...
“$cwd” 返回变量 cwd 的值。第二个例子使用反引号来执行 pwd 命令,并将它的结果赋予变量directory (这是非常方便的)。
也可以使用命令行参数定义系统变量。
[root@ufo666 ~]# echo -e "150 75 90\n85 120" | awk '{print NR,$0}' OFS="---"
1---150 75 90
2---85 120
命令行参数的一个重要限制是它们在 BEGIN 过程中是不可用的。也就是说,直到首行输入完成以后它们才可用。为什么?
[root@ufo666 ~]# echo -e "150 75 90\n85 120" | awk 'BEGIN{print n}{ if(n == 1) print "666666"}' n=1
666666
666666
如果你现在还记着BEGIN过程即“在处理输入之前所要做的”,你将会理解为什么在BEGIN过程中的参数n返回值为空,因此print 语句将打印一个空行。如果第一个参数是一个文件而不是一个变量赋值。该文件会知道BEGIN过程执行后才被打开。
以这种方法对参数求值的后果是不能用BEGIN过程测试或检验命令行提供的参数。只有当输入一行后它们才能够使用。要了解这种局限性,可以通过编写规则并使用它的过程来检验参数的赋值。另一个方法是在调用awk 之前在shell脚本中测试命令行参数。
awk提供了一个解决这个问题的方法,即在任何输入被读入前定义参数。用-v选项指定要在执行BEGIN过程之前得到变量赋值(也就是,在读入第一个输入行之前)。-v选项必须在一个命令行脚本前说明。例如:下列命令使用-v选项为多行记录设置记录分隔符。
[root@ufo666 ~]# echo -e "150 75 90\n85 120" | awk -F"\n" -v x="666" '{ print x }'
666
666
和C程序语言类似,awk也提供系统变量 ARGC 和 ARGV。因为这需要了解数组,后边会讲到。
1.14 信息的检索
awk程序可以用于检索数据库中的信息,数据库实际上是各种类型的文本文件。文本文件的结构化越好,对其处理就越容易工作。
[root@ufo666 ~]# cat test
#! /bin/bash
awk '$1 == 150{print $0}' x=$1
[root@ufo666 ~]#
[root@ufo666 ~]# echo -e "150 75\n150 120" | sh test 150
150 75
150 120
在shell命令行中的第一个参数($1)被赋给变量 x,这个变量作为参数传递给awk程序。传递给awk程序的参数在脚本之后说明。(这显的有些混乱,因为在awk程序中$1代表每个输入行的第一个字段,而在shell脚本中$1代表命令行提供的第一个参数。)
2. 条件、循环和数组
2.1 条件语句
条件语句用于在执行操作之前做一个测试。模式匹配规则本质上就是影响主输入循环的条件表达式。在条件语句以if开头,并计算放在圆括号中的表达式。语法是:
if ( expression )
action1
[else
action2]
如果条件表达式expression的值为真(非零或非空),就执行action1。当存在else 语句时,如果条件表达式的值为假(零或空),则执行action2。一个条件表达式可能包含算术运算符、关系操作符、或布尔操作符。也许最简单的条件表达式是测试一个变量是否是一个非零值。
[root@ufo666 ~]# echo "666" |awk -v x=0 '{if (x) print $0}'
[root@ufo666 ~]#
[root@ufo666 ~]# echo "666" |awk -v x=1 '{if (x) print $0}'
666
[root@ufo666 ~]# echo "666" |awk -v x=1 '{if (x == 1) print $0}'
666
[root@ufo666 ~]# echo "666" |awk -v x=1 '{if (x ~ 1) print $0}'
666
如果X是零,print语句将不执行。如果X是一个非零值,将打印X的值。也可以测试X是否等于另一个值:
如果操作时由多个语句组成的,要用一对大括号将操作括起来。
if ( expression ) {
statement1
statement2
}
awk 对大括号和语句的位置没有特殊的要求(和sed不同)。左大括号放在条件表达式后面,可以与条件表达式位于一行也可以在下一行。第一条语句可以紧跟左大括号或从下一行开始,右大括号放在最好一条语句的后面,可以与最后一条语句位于同一行也可以在下一行。在大括号的前后允许有空格或制表符。
右大括号和else后面的换行时可选的。
if ( expression ) action1
[else action2]
如果在action1后面加一个分号表示结束,action1后面的换行也是可选的。
if ( expression ) action1;[else action2]
如果在同一行上用分号分隔多个语句,同样需要使用大括号。
[root@ufo666 ~]# echo -e "90\n80\n75\n20" | awk '{avg=$1;if (avg >= 90) grade = "A"
else if (avg >= 80) grade = "B"
else if (avg >= 70) grade = "C"
else if (avg >= 60) grade = "D"
else grade = "F"
print grade}'
A
B
C
F
2.2 条件操作符
Awk 中提供的条件操作符可以在C语言中找到,它的形式为:
expr ? action1 : action2
简单if/else条件可以用条件操作符改写成:
grade = (avg >= 65)? "Pass" : "Fail"
这种形式更简洁而且适合于上面所示的简单的条件。但是这样做将导致程序不易阅读。
2.3 循环
循环是一种用于重复执行一个或多个操作的结构。在awk 中循环结构可以用while、do或For语句来指定。
While循环的语法是:
while (condition)
action
Do 循环是while 循环的一个变型。Do 循环的语法为:
do
action
while (condition)
右圆括号后面的换行是可选的。条件表达式在循环的顶部进行计算,如果为真,就执行循环体action部分。如果表达式不为真,则不执行循环体。通常情况下,条件表达式的值为真并执行循环体,在循环体中改变某一值,直到最后条件表达式的值为假并推出循环。例如,如果希望执行一个循环体4次,可以编写下面的循环语句:
Do后面的换行是可选的。如果action后面使用分号,则换行也是可选的。这个结构的主要部分是action后面的条件表达式condition。因此,循环体至少执行一次。
For 语句是同while循环一样,能够得到相同结果的一个更紧凑的语法形式。尽管它看起来比较困难,但其语法使用更简单并能保证提供一个循环所需要的所有元素。For循环的语法为:
for ( set_counter ; test_counter ; increment_counter )
action
右圆括号后面的换行是可选的。For循环由3个表达式组成:
- set_counter:设置计数器变量的初值。
- test_counter:描述在循环开始时要测试的条件。
- increatment_counter:每次在循环的底部递增计数器,且恰好在重新测试test_counter之前。
# 下面来看使用for循环打印输入行的每一个字段。
for ( i = 1; i <=NF; i++ )
print $i
# 也可以编写一个循环按从最后一个字段到第一个字段的次序来打印。
for ( i = NF; i >= 1; i-- )
print $i
# 用一个for 循环来计算每行的平均值。
total = 0
for (i = 1; i <= NF; ++i)
total += $i
avg = total / NF
# 求阶乘
fact = number
for (x = number - 1 ; x > 1; x--)
fact *= x
2.4 影响流控制的其他语句
在一个循环中有两个语句可以影响控制流,break 和 continue。Break 语句顾名思义就是退出本层循环,这样将不再继续执行循环。Continue 语句在到达循环底部之前终止当前的循环,结束本次循环,并从循环的顶部开始一个新的循环。
y="666666"
for ( x = 1; x<= NF; ++x )
if ( y == $x ) {
print x,$x
break
}
-----------------------------
y="666666"
for ( x = 1; x<= NF; ++x )
if ( y == $x ) {
print x,$x
continue
}
有两个语句能影响主输入循环,next 和 exit。Next语句能够导致读入下一个输入行,并返回到脚本的底部。这可以避免对当前输入行执行其他的操作过程。Next语句的典型应用是可以连续从文件读取内容,忽略脚本的其他的操作直到文件被读完。系统变量 FILRNAME 提供了当前文件的名字。因此,可以如下编写模式:
FILENAME =="acronyms"{
action
next
}
{ print }
这使得对文件acronyms的每行都执行action指定的操作。当完成操作后,输入下一个新行。只有当从不同的文件输入内容时控制才执行print 语句。
Exit语句使主输入循环退出并将控制移到END规则,如果END存在的话。如果没有定义END规则,或在END中应用exit 语句,则终止脚本的执行。
Exit语句可以使用一个表达式作为参数,该表达式将作为awk 的退出状态返回。如果没有提供表达式,那么将返回0,如果为exit语句设置一个初值,然后在END中再次调用没有参数的exit,则使用第一个值,例如:
awk '{
...
exit 5
}
END { exit }'
这里,awk 的退出状态是5。
注意:一些awk不允许你在用户定义的函数中用next语句。
2.5 数组
数组是可以用来存储一组数据的变量。通常这些数据之间具有某种关系。数组中的每一个元素通过它们在数组中的下标来访问。每个下标都用方括号括起来。下面的语句表示为数组中的一个元素赋值。
array[subscript] = value
在awk中不必指明数组的大小,只需要为数组指定标识符。向数组元素赋值是最容易完成的。例如,下面的例子中为数组flavor的一个元素指定了一个字符串”cherry”。
flavor[1] = "cherry"
这个数组元素的下标是“1”。下面的语句将打印字符串“Cherry"。
print flavor[1]
可以用循环向数组中写入或取出元素。例如,如果数组flavor有5个元素,可以编写以下循环来打印每个元素:
flavor_count = 5
for (x = 1; x <= flavor_count ; ++x)
print flavor[x]
在awk 中,数组的一个应用方式是存储每个记录的值,用记录的编号作为数组的下标。假设我们想跟踪计算出的每个学生的平均成绩,并且计算出一个班的平均成绩。每读入一个记录我们将做下面的工作:
student_avg[NR] = avg
系统变量NR作为数组的下标是因为对于每个记录它是递增的。当读入第一个记录时,avg的值被放置到student_avg[1];对于第二个记录,它的值被放置到student_avg[2];以此类推。
2.6 关联数组
在awk 中,所有的数组都是关联数组。关联数组的独特之处在于它的下标可以是一个字符或一个数值。关联数组在数组的下标和元素之间建立了一种“关联”。对于数组中的每个元素都有两个相关的值:元素的下标和元素的值。
关联数组是 awk 中一个独特的特征,它的一个强大功能就是可以使用字符串作为一个数据的下标。例如,可以使用下面的赋值语句来将输入行的第一个字段作为第二个字段的下标:
array[$1] = $2
有一个特殊的循环语法可以访问关联数组的所有元素,但是,访问数组中的条目的顺序是随机的。它是for 循环的一个版本,可以用在 awk 的 BEGIN、主输入循环、END 模块。
for ( variable in array )
do something with array[lvariable]
重要的是需要记住 awk 中的所有数字下标都是字符串类型。即使使用数字作为下标,awk 将自动将它们转换为字符串。当使用整数作为下标时也不必担心,因为它们也被转换成字符串。但是如果使用实数作为下标,那么向字符串的转换可能会有影响。
[root@ufo666 ~]# gawk 'BEGIN { data[1.23] = "3.21";CONVFMT ="%d"; printf "%s\n",data[1.23] }'
这里,在尖括号中没有打印任何东西,因为在第二个语句中 1.23 被转换为1,而 data [“1”] 的值为空串。
2.7 测试数组中的成员资格
关键词in也是一个操作符,用在条件表达式中米测试一个下标是否是数组的成员。表达式为:
item in array
如果array[item]存在则返回1,否则返回0。例如,如果字符串“1”是数组 data 的下标,以下的条件表达式将为真,但是无法判断这个下标的元素的情况。
[root@ufo666 ~]# awk 'BEGIN{ data[1]="666"; if ("1" in data) print "666是数组中的元素"}'
666是数组中的元素
[root@ufo666 ~]# awk 'BEGIN{ data[1]="666"; if ("666" in data) print "666是数组中的元素"}'
[root@ufo666 ~]#
2.8 用 split() 创建数组
内置函数 split() 能够将任何字符串分解到数组的元素中。这个函数对于从字段中提取“子字段“是很有用的。函数split )的语法为:
n = split(string,array,separator)
string是要被分解到名字为array的元素中的输入字符串。数组的下标从1开始到n,n即为数组中元素的个数,元素根据指定的separator分隔符来分解。如果没有指定分隔符,那么将使用字段分隔符(FS)。separator 可以是一个完整的正则表达式,而不仅仅是单个字符。
z=split ($1,fullname,"")
for (i = 1; i <= z; ++i)
print i,array[i]
2.9 删除数组元素
awk提供了一个语句用于从数组中删除一个元素。语法是:
delete array[subscript]
这里的方括号是必需的。这个语句将删除 array 中下标为 subscript 的元素。特别地,使用 in 测试subscriptc 将返回为假。
[root@ufo666 ~]# awk 'BEGIN {
> myArray[1] = "apple"
> myArray[2] = "banana"
> myArray[3] = "cherry"
>
> # 打印原始数组
> for (i in myArray) {
> print i, myArray[i]
> }
>
> # 删除下标为2的元素
> delete myArray[2]
>
> # 再次打印数组,可以看到下标为2的元素已被删除
> print "\nAfter deletion:"
> for (i in myArray) {
> print i, myArray[i]
> }
> }'
1 apple
2 banana
3 cherry
After deletion:
1 apple
3 cherry
注意,delete 语句不会改变数组中其他元素的下标或值。
2.10 多维数组
awk支持线性数组,在这种数组中的每个元素的下标是单个下标。如果你将线性数组看成是一行数据,那么两位数组将表示数据的行和列。你可以将第三行第二列的数据元素表示为“array[3,2]”。两维和三维数组是多维数组的例子。awk 不支持多维数组,但它为下标提供了一个语法来模拟引用多维数组。例如,你可以如下编写表达式:
file_array[NR,i] = $i
这里的每个输入记录的字段使用记录编号和字段号做下标。因此,可以如下表示:
file_array[2,4]
这将得到第二个记录的第四个字段的值。
这个语法不能创建多维数组。它将转换为一个字符串来唯一识别线性数组中的元素。多维数组下标的分量解释为单独的字符串(例如“2”和“4”) ,并使用系统变量SUBSEP的值来连接。下表分量的分隔符默认地被定义为“\034”,这是一个不可打印的下标实际为“2\0344”(使用SUBSEP将“2”和“4”连接起来)。模拟多维数组的主要后果是数组越大,访问个别的元素就越慢。
多维数组的语法也支持测试数组的成员资格。下标必需放置在圆括号中
if ((i,j) in array)
这可以测试下标i,j(实际上是SUBSEP j)是否在指定的数组中存在,对多维数组的循环操作和一位数组相同。
for (item in array)
你必须用split ()函数来访问单独的下标分量。即:
split(item,subscr,SUBSEP)
以上split ()函数使用下标item创建数组subscr。
注意:我们在前面的例子用嵌套循环来输出两维位图数组,因为需要维护行和列。
2.11 作为系统变量的数组
Awk中提供的两个系统变量,它们是数组。
- ARGV:这是一个命令行参数的数组,不包括脚本本身和任何调用awk 指定的选项,这个数组中的元素的个数可以从ARGC中获得。数组中第一个元素的下标是0(和awk 中的其他数组不同,而和C一致),最后一个下标是ARGC-1。
- ENVIRON:一个环境变量数组,数组中每个元素是当前环境变量的值,而其下表是环境变量的名字。
2.12 命令行参数数组
你可以编写一个循环来访问ARGV数组中的所有元素。
# argv.awk - print command-line parameters
BEGIN { for (x = 0; x < ARGC;++x)
print ARGV[x]
print ARGC
}
这个例子也打印了ARGC的值,即命令行参数的个数。
在通常情况下,ARGC 的值不小于 2 。如果你不希望引用程序名或文件名,你可以将计数器初始化为 1 并测试 ARGC-1 以避免访问最后一个参数(假设这里只有一个文件名)。
注意,如果你在Shell脚本中调用了awk,命令行的参数将传递给Shell而不是传递给awk。你必须将Shell脚本的命令行参数,传递给在Shell脚本中的awk程序。例如你可以用“$*(星号)”将Shell脚本中的所有命令行传递给awk。参见下面的Shell脚本:
awk '
# argv.sh - print command-line parameters
BEGIN {
for (x = 0; x $*
这个Shell脚本和第一个调用awk 的例子所做的工作一样。
# number. awk - test command-line parameters
BEGIN {
for (x = 1; x < ARGC;++x)
if ( ARGV[x] !~/^[O-9]+$/ ) {
print ARGV[x],"is not an integer"
exit 1
}
}
因为可以再ARGV数组中添加和删除,因此有许多潜在的有趣时处理。例如,你可以把文件名放置在数组的末尾,这样就可以像在命令行中指定的一样被打开。同样地,你也可以从数组中删除文件名,那么它将永远无法打开。注意,如果向ARGV中添加元素,也必须递增ARGC;awk 使用 ARGC 的值得到到ARGV中的有多少元素可以处理。因此,简单地递增ARGC将使awk 不能检测到ARGV中的最后一个元素。
在特殊的情况下,如果ARGV的元素的值是一个空串(“”) , awk将跳过它并继续处理下一个元素。
2.13 环境变量数组
数组ENVIRON被分别添加到gawk 和MKS awk 中。然后被添加到System V Rlease 4 nawk 中,现在被包含在POSIX标准的awk 中。它允许你访问环境变量。下面的程序循环访问了数组 ENVIRON 的所有元素并进行打印。
# environ. awk - print environment variable
BEGIN {
for (env in ENVIRON)
print env "=" ENVIRON[env]
}
[root@ufo666 ~]# awk 'BEGIN {for (env in ENVIRON) print env "=" ENVIRON[env]}'
AWKPATH=.:/usr/share/awk
LANG=en_US.UTF-8
HISTSIZE=1000
XDG_RUNTIME_DIR=/run/user/0
USER=root
TERM=xterm
SHELL=/bin/bash
...
数组的下标是变量的名字。该脚本产生与env命令相同的输出(在一些系统中是printenv)。
可以使用变量名作为数组的下标访问任意元素:
ENVIRON["LOGNAME"]
也可以修改数组ENVIRON中的任意元素:
ENVIRON["LOGNAME"] = "Tom"
但是这个修改并不改变用户的真实环境(例如,当执行完awk时,LOGNAME的值没有变化),同样也没有改变程序的环境,这些程序是awk 使用 getline() 或 system() 调用的。
3. 函数
函数是一个独立的计算过程,它接受一些参数作为输入并返回一些值,awk 有许多内置函数,可分为两组:算术函数和字符串函数。Awk也支持用户自定义函数,允许你编写自己的函数来扩展内置函数。
3.1 算术函数:

注意:int ()函数是简单的舍位,没有使用四舍五入法则(使用printf格式“%.0f”实现舍入)。
函数rand ()生成一个在0和1之间的浮点型的伪随机数。函数srand ()为随机数发生器设置一个种子数或起点数。如果调用srand ()时没有参数,它将用当时的时间来生成一个种子数。若有参数x, srand ()使用x作为种子数。
如果没有调用srand () 、 awk在开始执行程序之前默认为以某个常量为参数调用srand ()、使得你的程序在每次运行时都从同一个种子数开始。这可以用于重复测试相同的操作,但是如果希望程序在不同的时间运行具有不同的操作则不合适。
[root@ufo666 ~]# awk 'BEGIN{print rand();print rand();srand();print rand();print rand()}'
0.237788
0.291066
0.948047
0.876318
[root@ufo666 ~]# awk 'BEGIN{print rand();print rand();srand();print rand();print rand()}'
0.237788
0.291066
0.354718
0.294386
[root@ufo666 ~]# awk 'BEGIN{print rand();print rand();srand();print rand();print rand()}'
0.237788
0.291066
0.280761
0.470268
返回 1~TOPNUM 之间的一个数。
awk -v TOPNUM=$1 '
BEGIN {
# 用当前的时间作种子数生成随机数
srand( )
# 取得一个随机数
select = 1 + int(rand()*TOPNUM) # 打印挑选的结果
print select
}'
awk 'BEGIN{srand(); print 1+int(rand()*10)}'
[root@ufo666 ~]# awk 'BEGIN{
> # 初始化一些变量
> x = 3.14159
> y = 2
>
> # sin(): 计算正弦值
> sin_result = sin(x)
> print "sin() result:", sin_result
>
> # cos(): 计算余弦值
> cos_result = cos(x)
> print "cos() result:", cos_result
>
> # atan2(): 计算反正切值
> atan2_result = atan2(y, x)
> print "atan2() result (in radians):", atan2_result
> print "atan2() result (in degrees):", atan2_result * 180 / 3.14159
>
> # sqrt(): 计算平方根
> sqrt_result = sqrt(y)
> print "sqrt() result:", sqrt_result
>
> # int(): 取整数部分
> int_result = int(3.14)
> print "int() result:", int_result
>
> # rand(): 生成一个随机数(0 到 1 之间)
> srand()
> random_number = rand()
> print "rand() result:", random_number
>
> # exp(): 求 e 的指数
> exp_result = exp(1)
> print "exp() result:", exp_result
>
> # log(): 自然对数
> log_result = log(x)
> print "log() result:", log_result
>
> # log10(): 基于10的对数
> log10_result = log10(x)
> print "log10() result:", log10_result
> }'
sin() result: 2.65359e-06
cos() result: -1
atan2() result (in radians): 0.566912
atan2() result (in degrees): 32.4817
sqrt() result: 1.41421
int() result: 3
rand() result: 0.0466595
exp() result: 2.71828
log() result: 1.14473
awk: cmd. line:41: fatal: function `log10' not defined
注意,某些版本的 awk 可能不支持所有这些函数。
3.2 字符串函数
内置字符串函数比算术函数更重要且更有趣。因为awk实质上是被设计成字符串处理语言,它的很多功能都起源于这些函数。


sprint() 函数使用和 printf() 相同的格式说明,sprintf ()不是将结果打印出来,而是返回一个字符串并可以赋给一个变量。
[root@ufo666 ~]# awk 'BEGIN{
> # 初始化一些变量和数组
> str = "Hello, World! This is a test string."
> regex = "is"
>
> # 使用 gsub() 函数全局替换 "is" 为 "was"。
> # gsub(): 全局替换
> gsub(regex, "was", str)
> print "gsub() result:", str
>
>
> # 使用 sub() 函数替换第一个出现的 "is" 为 "was"。
> # sub(): 替换第一个匹配项
> str = "Hello, World! This is a test string."
> sub(regex, "was", str)
> print "sub() result:", str
>
> # 使用 index() 函数查找 "test" 在 str 中的位置。
> # index(): 查找子串位置
> pos = index(str, "test")
> print "index() result:", pos
>
> # 使用 length() 函数计算 str 的长度。
> # length(): 计算字符串长度
> len = length(str)
> print "length() result:", len
>
> # 使用 match() 函数匹配正则表达式 /World/ 并获取匹配信息(RSTART 和 RLENGTH)。
> # match ()函数也设置了两个系统变量:RSTART和RLENGTH。
> # RSTART中包含这个函数的返回值,即匹配子串的开始位置。
> # RLENGTH中包含匹配的字符串的字符数(而不是子串的结束位置)。
> # 当模式不匹配时,RSTART设置为0,而RLENGTH设置为-1。
> # match(): 匹配正则表达式并获取匹配信息
> if (match(str, /World/)) {
> print "match() result:"
> print " RSTART:", RSTART
> print " RLENGTH:", RLENGTH
> print " substr(RSTART, RLENGTH):", substr(str, RSTART, RLENGTH)
> }
>
> # match($0,pattern){
> # 提取匹配中的模式的字符串
> # 用字符串在$0中的开始位置和长度#打印字符串
> # print substr($0,RSTART,RLENGTH)
> # } 'pattern="$1" $2
> # 使用 split() 函数将 str 按空格分割成数组 fields。
> # split(): 分割字符串为数组
> split(str, fields, " ")
> print "split() result:"
> for (i in fields) {
> print " Field", i, ": ", fields[i]
> }
>
> # 使用 substr() 函数提取 str 中的子串。
> # substr(): 提取子串
> substr_result = substr(str, 10, 7)
> print "substr() result:", substr_result
> }'
-------------------------------------------------------
sub() result: Hello, World! Thwas is a test string.
index() result: 26
length() result: 37
match() result:
RSTART: 8
RLENGTH: 5
substr(RSTART, RLENGTH): World
split() result:
Field 4 : is
Field 5 : a
Field 6 : test
Field 7 : string.
Field 1 : Hello,
Field 2 : World!
Field 3 : Thwas
substr() result: rld! Th
3.3 自定义函数
通常情况下,我们将函数定义放在脚本顶部的模式操作规则之前。函数用下面的语法定义:
function name (parameter-list){
statements
}
左大括号后面的换行和右大括号前面的换行都是可选的。你也可以在包含参数列表的右圆括号后和左大括号前进行换行。
parameter-list是用逗号分隔的变量列表,当函数被调用时,它被作为参数传递到函数中。函数体由一个或多个语句组成。函数中通常包含一个return 语句,用于将控制返回到脚本中调用该函数的位置;它通常带有一个表达式来返回一个值,如下所示:
return expression
注意,当调用用户自定义函数时,在函数名和左圆括号之间可以没有空格。但这对内置函数是不适合的。
理解局部变量和全局变量的概念是很重要的。在函数之外定义的变量是全局变量,在函数参数列表中或函数体中定义的变量是局部变量。在awk中,所有变量默认都被初始化为空串,包括全局变量和局部变量。这意味着,如果你在awk脚本中使用一个没有赋初值的变量,它将被当作空串来对待。在函数内部,我们可以正常访问和使用局部变量和全局变量。在函数外部,我们可以访问全局变量,但无法访问局部变量。
# 全局变量
global_var = 10
function my_function() {
# 局部变量
local_var = 20
print "局部变量 local_var:", local_var
print "全局变量 global_var:", global_var
}
my_function()
print "局部变量 local_var:", local_var
print "全局变量 global_var:", global_var
按值传递时,传递给函数的参数会被复制一份,函数内部对参数的修改不会影响原始变量。按引用传递时,数组副本仍然保持对原始数组的引用。这意味着,通过在函数内部修改数组副本,可以影响原始数组的内容。
# 定义一个数组
BEGIN {
my_array[1] = 10
my_array[2] = 20
my_array[3] = 30
}
function modify_array(arr) {
arr[2] = 100
print "修改后函数中的数组:"
for (i in arr) {
print "arr[" i "] =", arr[i]
}
}
# 调用函数,按引用传递
BEGIN {
print "修改前的数组:"
for (i in my_array) {
print "my_array[" i "] =", my_array[i]
}
modify_array(my_array)
print "修改后的原始数组:"
for (i in my_array) {
print "my_array[" i "] =", my_array[i]
}
}
[root@ufo666 ~]# awk -f test
修改前的数组:
my_array[1] = 10
my_array[2] = 20
my_array[3] = 30
修改后函数中的数组:
arr[1] = 10
arr[2] = 100
arr[3] = 30
修改后的原始数组:
my_array[1] = 10
my_array[2] = 100
my_array[3] = 30
例子,对字符串数组进行排序,return 不能直接返回数组。
#!/usr/bin/awk -f
function sort_string_array(arr) {
asort(arr, sorted_arr)
}
BEGIN {
# 测试数据
my_array[1] = "apple"
my_array[2] = "cat"
my_array[3] = "banana"
my_array[4] = "dog"
# 调用排序函数进行排序
sort_string_array(my_array)
# 打印排序结果
print "排序结果:"
for (i in sorted_arr) {
print "sorted_arr[" i "] =", sorted_arr[i]
}
}
[root@ufo666 ~]# awk -f test
排序结果:
sorted_arr[4] = dog
sorted_arr[1] = apple
sorted_arr[2] = banana
sorted_arr[3] = cat
3.4 维护函数库
你或许希望把一个有用的函数保存在一个文件中,并保存在一个重要的目录 下。awk 允许使用多个 -f 选项来指定多个程序文件。
awk -f sort.awk -f sorter.awk test
注意,保存函数文档的有关信息有助于在重用它们时理解他们如何工作。
4. “底部抽屉”,已有的框架
4.1 getline 函数
getline 函数用于从输入中读取另一行。getline 函数不仅能读取正常的输入数据流,而且也能处理来自文件和管道的输入。
getline 函数类似于 awk 中的 next 语句。两者都是导致下一个输入行被读取, next 语句将控制传递回脚本的顶部。getline 函数得到下一行但没有改变脚本的控制。可能的返回值为:
- 1 如果能够读取一行。
- 0 如果到了文件末尾。
- -1 如果遇到错误。
注意:不能写成 getline(),它的语法不允许有圆括号。
我们可以用 while 循环从文件中读取所有的行,测试到文件结束时循环退出。
{
print "使用next语句跳过部分行:"
print "--------------------------"
file = "data.txt"
while ((getline line < file) > 0) {
if (line == "skip") {
next
}
print line
}
close(file)
}
{
print "\n使用getline函数获取下一行但不跳过行:"
print "--------------------------"
file = "data.txt"
while ((getline line < file) > 0) {
if (line == "skip") {
print "跳过行:", line
}
print "下一行:", line
}
从标准输入读取数据,存储在 $0 变量中。
[root@ufo666 ~]# awk 'BEGIN{printf "请输入姓名:"; getline < "-"; print $0}'
请输入姓名:zhao
zhao
4.2 将输入赋给一个变量
getline 函数允许你将输入记录赋给一个变量,变量的名字为一个参数来提供。将输入赋给一个变量不会影响当前的输入行,也就是说,对 $0 没有影响。新的输入行没有被分解成字段,因些对变量 NF 也无影响。但它递增了记录计数器 NF 和FNR。
BEGIN{ printf "Enter your name:"
getline name < "-"
print name
}
注意,将输入数据赋给变量的语法,通常错误地写成:
name=getline # 错误写法
4.3 从管道读取输入
可以执行一个命令并将输出结果用管道输送到 getline。这个行被分解为字段并设置了系统变量NF。同样地,你也可以将结果赋给一个变量:
"who am i" | getline
"who am i" | getline me
通过将输出结果赋给一个变量可以避免设置$0和NF,但输入行没有被分解为字段。
当一个命令的输出结果被用管道输送给 getline 且包含多个行时, getline 一 次读取一行。第一次调用getline,它将读取输出的第一行。如果再次调用 getline, 它将读取第二行。要读取输出的所有行,就必须创建一个循环来执行 getline, 直到不再有输出为止。例如,下面的例子使用 while 循环来读取输出的每一行并将它赋给数组 who_out 的下一个元素:
while ("who" | getline)
who_out[++i]=$0
每次调用 getline 函数时,读取输出的下一行。然而,其中的 who 命令只执行 一次。
4.4 close()函数
close()函数用于关闭打开的文件和管道。使用它有以下几个原因:
- 每次你只能打开一定数量的管道。为了在一个程序中能够打开你所希望的数量的管道,你必须用 close() 函数来关闭一个你用过的管道(通常是,当 getline 返回0或-1时)。下面是一个例子:
close("who")
- 关闭一个管道使得你可以运行同一个命令两次。
- 为了使用一个输出管道来完成它的工作,使用 close()可能是必要的。例 如:

- 为了保证同时打开的文件数不超过系统的限制,关闭打开的文件是必要的。
4.5 System()函数
System()函数执行一个以表达式给出的命令。然而,它的命令没有产生可供程序处理的输出。它返回被执行的命令的退出状态。脚本等待这个命令完成任务后才继续执行。

第一次运行产生新的目录,并且 system()返回退出状态0(成功)。第二次执行这命令,目录已经存在,因此 mkdir 失败并产生一个出错信息。“Command Failed”信息是 awk 产生的。
编写一个菜单选项:(如果 BEGIN 模块中不允许定义的变量,可以用 awk 的 -v 选项传递变量,同时 -v 选项也可以使用shell变量传递)
#!/usr/bin/awk -f
function print_menu() {
print "菜单选项:"
print "1. 显示当前目录"
print "2. 显示系统时间"
print "3. 退出"
}
function execute_option(option) {
if (option == 1) {
print "当前目录:"
system("pwd")
} else if (option == 2) {
print "系统时间:"
system("date")
} else if (option == 3) {
print "退出菜单"
close("menu")
exit
} else {
print "无效的选项,请重新输入"
}
}
BEGIN {
while (1) {
print_menu()
printf "请输入选项: "
getline option < "/dev/tty"
execute_option(option)
print ""
}
}
[root@ufo666 ~]# awk -f test
菜单选项:
1. 显示当前目录
2. 显示系统时间
3. 退出
请输入选项: 1
当前目录:
/root
菜单选项:
1. 显示当前目录
2. 显示系统时间
3. 退出
请输入选项: 2
系统时间:
Mon Dec 18 16:57:15 CST 2023
菜单选项:
1. 显示当前目录
2. 显示系统时间
3. 退出
请输入选项: 3
退出菜单
4.6 直接向文件和管道输出
任何 print 和printf 语句可以用输出重定向操作符“>”或“>>”直接将输出 结果写入一个文件中。例如,下面的语句将当前记录写到文件 data. out 中:
print > data.out
因为重定向操作符“>”和关系操作符是一样的,所以当你用表达式作为 print 命令的参数时可能会产生混淆。规定当“>”出现在任何打印语句的参数列表中时被看做是重定向操作符。要想使“>”出现在表达式的参数列表中时被看做是关系操作符,可以用圆括号将表达式或参数列表括起来。
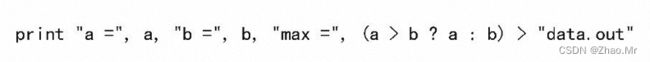
4.7 直接输出到一个管道
你也可以将输出直接写入一个管道,命令为:
print | command
该命令在第一次执行时打开一个管道,并将当前记录作为输入输送给命令 command。换名话说,这里的命令只执行了一次,但每执行一次 print 命令将提供另一个输入行。
# 统计单词数量
{ sub(/^\.../,"")
print | "wc -w"
}
在大多数情况下,我们宁愿用 shell 脚本将 awk 命令的输出结果,用管道输送给另一个命令,而不是在 awk 脚本中来处理,例如,我们将前面的例子改写成 shell脚本,调用 awk 并用管道输送它的结果给 wc:
# 统计单词数量
{ sub(/^\.../,"")
print
} $* | wc -w
注意,每次只能打开一定数量的管道。使用 close() 函数关闭用过的管道。
4.8 处理多个文件
当读文件或写文件时文件被打开。每个操作系统对一个正在运行程序能够同时打开的文件的数量都有一定的限制,而且,每个 awk 实现对打开文件的数量都有内部限制,这个数字可能比系统限制要小。为了避免打开过多的文件, awk 提供了 close() 函数用于关闭打开的文件。关闭已经处理完的文件可使程序打开更多的文件。
直接向文件写入输出的一个常见的方法,是将一个大的文件分割成几个小的文件。尽管 UNIX 提供了有用的 split 和 csplit 命令,它们可以完成相同的工作,但它们不能为一个新文件指定一个有用的文件名。你可以用变量来指定文件名并从文件的模式中挑选一个值。例如,如果 $1 提供一个可以作为文件名的字符串,你可以编写一个脚本将每个记录输出到它对应的文件中:
print $0 > $1
如果一个 awk 程序是几个程序的一个管道的一部分,甚至是其他的 awk 程序的一部分,你可以用 tee 命令将输出重定向到一个文件,同时也将输出用管道传递给下一个命令。
4.9 调试
- print 语句在程序中不同地方打印变量的值。例如,使用一个变量作为标志来确定是否执行了某个过程。
- 注释掉一系列可能引起问题的行,看它们是否真的有问 题。
- 当所有的方法都失败时,可以使用编辑器来删除命令或删除部分程序直到错误消失。当然,要对程序做一个备份并在临时备份上删除行。这是一个非常笨拙的技术,却是在全部放弃或重新从头开始之前一个有效的办法。
- 要认识到 awk 脚本通常只限定在固定领域,程序主要是要解决某个特定的问题。而不是解决许多不同用户遇到的一系列问题。因为这些程序的这种特点,要求 它们具有专业的质量是没有必要的。因此,编写100%的用户层程序是没有必要 的。
4.10 约束
在任何 awk 实现中都有固定的约束。这些特定实现工具的约束,但对大多数系统都是一个好的参考值。超过这些约束将使脚本产生无法预测的问题。
注意:经验表明大多数 awk 允许打开的管道数大于1。对于数值型数据项, awk 使用双精度型,浮点型数据的长度限制由机器的结构决定。

4.11 使用 #! 语法调用 awk
“#!” 语法是从 shell 脚本中调用 awk 的可选的语法。它的优点是你可以在 shell脚本的命令行中指定 awk 的参数和文件名。运用这个语法的最好方法 是将下面一行作为 shell 脚本的第一行:
#! /bin/awk -f
“#!”后面跟的是所用的 awk 所在的路径名,然后是-f选项。在这一行之后,你可以写 awk 脚本:
#!/bin/awk -f
{ print $1 }
注意,脚本周围不必使用引号。在第一行后面的所有行都能够像在单独的脚本文件中一样被执行。
awk_script='
# 此处编写awk脚本的内容
BEGIN {
print "Hello, World!"
print "输入的参数个数:", ARGC-1
print "参数列表:"
for (i=1; i<=ARGC-1; i++) {
print ARGV[i]
}
}'
awk -f <(echo "$awk_script") "$@"
使用单引号将awk脚本包裹起来,以确保脚本的内容不被shell解析。最后,使用"$@"将shell命令行的所有参数传递给awk命令,以便在awk脚本中获取这些参数。
在shell中,$@和$*都是用来获取命令行参数的特殊变量。它们的主要区别在于如何对待参数中的空白字符和引号。
#!/bin/bash
echo "使用\$@获取命令行参数:"
for arg in "$@"; do
echo "$arg"
done
echo
echo "使用\$*获取命令行参数:"
for arg in "$*"; do
echo "$arg"
done
[root@ufo666 ~]# sh test AAA BB,B "CC C"
使用$@获取命令行参数:
AAA
BB,B
CC C
使用$*获取命令行参数:
AAA BB,B CC C
-
$@将命令行参数作为一个个独立的字符串进行处理。每个参数都可以保留其原始的空白字符和引号。在使用时,通常将$@放在双引号中以保留每个参数的完整性。
-
$*将命令行参数作为一个字符串进行处理。所有参数被合并为一个字符串,参数之间以空格分隔。在使用时,通常将$*放在双引号中,以确保参数正确分隔。
至此,所有的 awk 命令已经介绍完。
附录一【sed命令快速参考】
https://blog.csdn.net/qq_42226855/article/details/135087772
附录二【awk命令快速参考】
https://blog.csdn.net/qq_42226855/article/details/135088023