【Java】IO流汇总(字节流、字符流、编码方式、序列化)
IO流
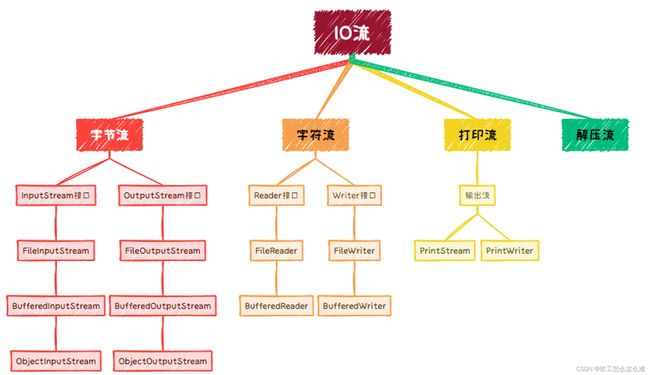
IO流的分类
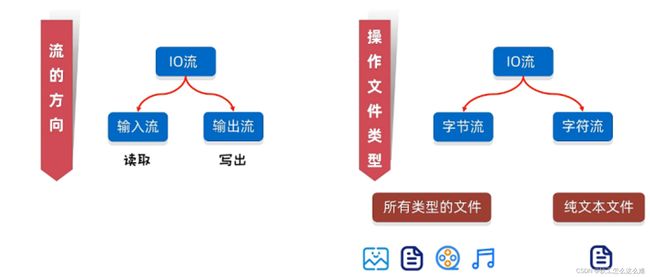
这里的I对应input是输入流,O对应output是输出流,注意不要混淆。可以这么记忆:输入流—>从文件写到流中—>读操作 输出流—>从流写到文件中—>写操作
什么是纯文本文件?
用Windows系统自带的笔记本打开并且能读懂(不乱码)的文件,如:txt文件,md文件,xml文件,lrc文件
FileOutputStream
操作本地文件的字节输出流
步骤及细节
-
创建字节输出流对象
-
参数是字符串表示的路径或者File对象都是可以的
-
如果文件不存在会创建一个新的文件,但是要保证父级路径存在
-
如果文件已经存在,则会清空文件(也就是第一次创建流对象会清空文件)
-
接c. 如果不想要清空文件,想要续写文件,则需要在创建流的时候设定第二个参数的值为true
FileOutputStream fileOutputStream=new FileOutputStream("C:\\Users\\wannner\\IdeaProjects\\demo\\src\\main\\resources\\test.txt",**true**);
-
-
写数据
- int类型的参数就是以ASCII码的形式识别
- byte类型的参数就是直接输入字节
-
释放资源**(注意释放资源遵循先定义后释放的原则)**
常用方法
void write(int b) 一次写一个字节数据
void write(byte[] b) 一次写一个字节数组数据
void write(byte[] b,int off,int len) 一次写一个字节数组的部分数据
代码示例
public static void main(String[] args) throws IOException {
FileOutputStream fileOutputStream = new FileOutputStream("C:\\Users\\wannner\\IdeaProjects\\demo\\src\\main\\resources\\test.txt");
fileOutputStream.write('b');
fileOutputStream.close();
}
FileInputStream
步骤及细节
- 创建字节输入流对象
- 如果文件不存在,就直接报错
- 读取数据
- 一次读一个字节,读出来的数据就是在ASCII上对应的数字
- 读到文件末尾,read方法返回-1
- 释放资源
常见方法
public int read() 一次读一个字节数据
public int read(byte[] buffer) 一次读一个字节数组数据(数组大小选择1024的整数倍)
注意这里的区别
-
无参read
读取一个字节,返回读取字节的十进制的形式
- 如果是单词,就是直接读取出这个字母的字节,返回该字节的十进制(也就是ASCII码)
- 如果是汉字,就是读取出组成这个汉字的字节(GBK中二字节,UTF-8中三字节)
-
有参read
假设我们设定的数组为
byte[] a=new byte[2]- 读取的是单词,那么输出数组的元素,还是输出ASCII码,而不会输出ASCII码所对应的单词
- 读取的是汉字,我假定的byte数组大小为2,在GBK的编码下读取txt文件中的
你好,那么读出来的分别是[-60, -29](你)和[-70, -61](好)而不是直接读出['你','好']
就这么理解:byte类型只有一字节,无法存汉字(二字节或者三字节)注意和⛳做区别 而且建议复习一下byte数组的知识点⛳
字符和ASCII的转换
已知字符怎么得知他的ASCII码或者已知ASCII怎么得出他对应的字符?
直接强转就可以了
int a;char b;
System.out.println((char)a);
System.out.println((int)b);
代码示例(实现拷贝代码)
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream=new FileInputStream("a.txt");
FileOutputStream fileOutputStream=new FileOutputStream("b.txt");
int b;
while((b=fileInputStream.read())!=-1){
fileOutputStream.write(b);
}
fileOutputStream.close();
fileInputStream.close();
}
这里的(b=fileInputStream.read())!=-1 一定要有,如果没有在下面的fileOutputStream.write(b) 只能写为fileOutputStream.write(fileInput Stream.rean()) 也就是再读一遍,那么一次循环读了两遍(判断一遍,循环体一遍),在循环结束处会出错的
拷贝代码改进
上面的拷贝代码有一个弊端,就是一次只能读写一个字节,耗时太长
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream=new FileInputStream("a.txt");
FileOutputStream fileOutputStream=new FileOutputStream("b.txt");
int len;
byte[] bytes=new byte[10];
while((len=fileInputStream.read(bytes))!=-1){
fileOutputStream.write(bytes,0,len);
}
fileOutputStream.close();
fileInputStream.close();
}
这里的len接收的是read的返回值,代表读取了多少个字符同上面一样,不能删除,要不然会读两次
编码方式
- GBK:国家发布的,包含全部中日韩汉字。Windows系统默认使用的就是GBK,但是系统显示ANSI
- Unicode:国际标准字符集
前面所说的GBK和Unicode都是字符集。我们所常见的这个UTF-8其实是Unicode这个字符集的编码方式,还有UTF-16、UTF-32等等。GBK字符集的编码方式也是GBK
为什么会出现乱码?
-
读取数据时未读完整个汉字
不使用字节流读取文本文件
-
编码和解码的方式不统一
编码解码时使用同一个码表,同一个编码方式
字符流
字符流的底层是字节流
字符流 = 字节流 + 字符集 字符流=字节流+字符集 字符流=字节流+字符集
特点
输入流:一次读一个字节,遇到中文时,一次读多个字节
输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中
FileReader
FileWriter fileWriter=new FileWriter("test.txt", Charset.forName("utf-8"));
字符输入输出流可以设定使用哪种编码格式来读写
-
创建字符输入流对象
-
读取数据
public int read() 读取数据,读到末尾返回-1 public int read(char[] buffer) 读取多个数据,读到末尾返回-1-
无参read
- 读取字母,获取的是他对应的ASCII
- 读取汉字,获取的是这个完整汉字的编码的十进制形式
-
有参read
有参read把读取数据,解码,强转三步合并了
有参 r e a d = 空参 r e a d + 强制类型转换 有参read=空参read+强制类型转换 有参read=空参read+强制类型转换
假设我们设定的数组为
char[] a=new char[2]- 读取字母”abc”,那么获取到的
a[0]='a',这里输出的就直接是a,而不是a所对应的ASCII码 - 同样,读取汉字“你好”,获取到的
a[0]='好',也是直接输出了这个汉字
- 读取字母”abc”,那么获取到的
字符流只有无参read和字节流的一样,其他三种都不一样
可以这样理解:字节流中他是byte类型,可以直接赋值byte a=100所以可以输出ASCII码(int类型)的形式。且大小只有128比特(一个字节),所以不能直接读出一个汉字。
字符流中是char类型,不能使用char a=100的形式赋值,所以输出的值只能是一个一个的字节。而且他的大小是远大于一字节的,可以直接读取一整个汉字 -
-
释放资源
FileWriter
和字节输出流差不多
常用方法
void write(int b) 一次写一个字符
void write(String str) 一次写一个字符串
void write(String str,int off,int len) 一次写一个字符串的部分数据
void write(char[] cbuf) 写出一个字符数组
void write(char[] cbuf,int off,int len) 写出字符数组的一部分
字节缓冲流
-
BufferedInputStream
-
BufferedOnputStream
-
缓冲区是位于内存中的
-
读:先把数据读到缓冲区,当要读取某些数据的时候就直接读取缓存区的数据,那么就是读取内存,速度快。原本的是去读取磁盘,太慢
-
写:先把数据写到缓存取,再一次性写到磁盘,减少了直接写入磁盘的次数,书写的速度变快
方法
public BufferedInputStream(InputStream is) 把基本流包装成高级流,提高读取数据的性能
public BuferedOutputStream(OutputStream os) 把基本流流包装成高级流,提高写出数据的性能
- 不用特地去关基本流,关闭高级流就可以
- 如果要续写文件,则是在基本流中写上对应代码
字符缓冲流
- BufferedReader
- BufferedWriter
大体上和字节缓冲流差不多,多了几个特有方法
public String readLine() 读取一行数据,如果没有数据可读了,会返回null
public void newLine() 跨平台的换行
- 使用
readLine()不会读出换行符 - 不同的操作系统的换行符不一样,所以要使用跨平台换行
转换流
是字符流和字节流之间的桥梁
作用:
- 指定字符集读写(jdk11后淘汰了)
- 字节流想要使用字符流中的方法
为什么要使用字节流+转换流的方法呢?不能直接使用字符流吗?
字符流只用作用于文本文件中,其他文件是无法用字符流的
构造方法
BufferedInputStream bff=new BufferedInputStream(new BufferedInputStream(new FileInputStream("test.txt")));
这里和前面的缓冲流类似 new 想要转换的流(new 转换流(new 基本流()))
序列化流/对象操作输出流
什么是序列化/反序列化
- 序列化:把对象转化为一种特殊的字符串(可以理解为编码),方便于存储
- 反序列化:序列化的逆过程,反序列为对象
除了基本数据类型(整数、浮点数、布尔、字符)和字符串类型,其他的数据类型都需要通过序列化来存储
序列化实现方法
- Serializable接口
对象类要实现Serializable接口,他是一个标记型接口,一旦实现了这个接口,那么就表示当前的对象类可以被序列化
自己写的JavaBean类需要实现该接口,其他的类(List、Map等)Java底层已经事先实现好了
版本号
在我们每次修改JavaBean的时候版本号都会修改
假如:我们使用序列化存入student对象(此时的版本号为1),我们修改了student对象的参数(版本号转变为2),再使用反序列化流来读取就无法识别为student类了
解决方法:在JavaBean类中自己写一个固定的版本号,不让他改变就行了
private static final long serialVersionUID = 1L;
也可以修改idea的设置,让idea为我们写
-
在设置中搜索
Serializable,勾选“不带serializableUID的可序列化” -
此时的类名会出现荧光标记,直接Alt+回车就可以自动生成
如果一个对象中的某个成员变量不想被序列化,怎么办?
给成员变量加上transient关键字修饰
- 第三方库
常用方法
public ObjectOutputStream(OutputStream out) 把基本流包装成高级流
public final void writeObject(Object obj) 把对象数列话(写出)到文件中去
前提:对象类要实现Serializable接口,他是一个标记型接口,一旦实现了这个接口,那么就表示当前的对象类可以被序列化
反序列化流/对象操作输入流
public ObjectInputStream(InputStream out) 把基本流变为高级流
public Object readObject() 把序列化到本地文件中的对象读取到程序中来
打印流
一般指的是PrintStream,PrintWriter两个类
字节打印流没有缓冲流。字节/字符打印流的方法一模一样,不书写两遍
构造方法
public PrintStream(OutputStream/File/String) 关联字节输出流/文件/文件路径
public PrintStream(String fileName,Charset charset) 指定字符编码
public PrintStream(OutputStream out,boolean autoFlush) 自动刷新
public PrintStream(OutputStream out,boolean autoFlush,String encoding) 指定字符编码且自动刷新
成员方法
public void write(int b) 常规方法:规则跟之前一样,将指定的字节写出
public void printLn() 特有方法:打印任意数据,自动刷新,自动换行
public void print() 特有方法:打印任意数据,不换行
public void printf(String format,Object... args) 特有方法:带有占位符的打印语句,不换行