一、什么是Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为分布式SQL查询引擎。从下图可以查看RDD、DataFrames与DataSet的关系。
二、为什么要学习Spark SQL?
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!所以我们类比的理解:Hive---SQL-->MapReduce,Spark SQL---SQL-->RDD。都是一种解析传统SQL到大数据运算模型的引擎,属于数据分析的范围。
三、什么是DataFrame和DataSet?
首先,最简单的理解我们可以认为DataFrame就是Spark中的数据表(类比传统数据库),DataFrame的结构如下:
DataFrame(表)= Schema(表结构) + Data(表数据)
总结:DataFrame(表)是Spark SQL对结构化数据的抽象。可以将DataFrame看做RDD。
DataFrame
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优化。DataFrames可以从各种来源构建,
例如:
- 结构化数据文件(JSON)
- 外部数据库或现有RDDs
DataFrame API支持的语言有Scala,Java,Python和R。
从上图可以看出,DataFrame相比RDD多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
DataSet
Dataset是数据的分布式集合。Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象。它提供了RDD的优点(强类型化)以及Spark SQL优化后的执行引擎的优点。一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作。 Dataset API 支持Scala和Java。 Python不支持Dataset API。
四、测试数据
我们使用2个csv文件作为部分测试数据:
dept.csv信息:
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON
emp.csv信息:
7369,SMITH,CLERK,7902,1980/12/17,800,,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,,20
7839,KING,PRESIDENT,,1981/11/17,5000,,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,,20
7900,JAMES,CLERK,7698,1981/12/3,950,,30
7902,FORD,ANALYST,7566,1981/12/3,3000,,20
7934,MILLER,CLERK,7782,1982/1/23,1300,,10
将这2个csv文件put到HDFS的hdfs://bigdata111:9000/input/csvFiles/目录以便后面使用
[root@bigdata111 ~]# hdfs dfs -ls /input/csvFiles
Found 2 items
-rw-r--r-- 1 root supergroup 84 2018-06-15 13:40 /input/csvFiles/dept.csv
-rw-r--r-- 1 root supergroup 617 2018-06-15 13:40 /input/csvFiles/emp.csv
五、创建DataFrame
前提:在集群模式下启动spark-shell:bin/spark-shell --master spark://bigdata111:7077
方式1:使用case class定义表
(1) 定义case class代表表的结构schema
scala>case class Emp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
(2) 导入emp.csv文件(导入数据)
scala>val lines = sc.textFile("/root/temp/csv/emp.csv").map(_.split(","))//读取Linux本地数据
或者
scala>val lines = sc.textFile("hdfs://10.30.30.146:9000/input/csvFiles/emp.csv").map(_.split(","))//读取HDFS数据
(3) 生成表: DataFrame
scala>val allEmp = lines.map(x=>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
(4)由allEmp直接生成表
scala>val empDF = allEmp.toDF
(4) 操作: DSL语句
scala>empDF.show ----> select * from emp
scala>empDF.printSchema ----> desc emp
操作结果:
方式2:使用SparkSession对象创建DataFrame
什么是SparkSession?
Apache Spark 2.0引入了SparkSession,其为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与Spark交互。
在2.0版本之前,与Spark交互之前必须先创建SparkConf和SparkContext。然而在Spark 2.0中,我们可以通过SparkSession来实现同样的功能,而不需要显式地创建SparkConf, SparkContext 以及 SQLContext,因为这些对象已经封装在SparkSession中。
通过SparkSession可以访问Spark所有的模块!
使用Sparksession创建DataFrame过程:
(2)加载结构化数据
scala>val lines = sc.textFile("/root/temp/csv/emp.csv").map(_.split(","))//读取Linux数据
或者
scala>val lines = sc.textFile("hdfs://10.30.30.146:9000/input/emp.csv").map(_.split(","))//读取HDFS数据
(3) 定义schema:StructType
scala>import org.apache.spark.sql._
scala>import org.apache.spark.sql.types._
scala>val myschema = StructType(List(StructField("empno", DataTypes.IntegerType)
, StructField("ename", DataTypes.StringType)
,StructField("job", DataTypes.StringType)
,StructField("mgr", DataTypes.StringType)
,StructField("hiredate", DataTypes.StringType)
,StructField("sal", DataTypes.IntegerType)
,StructField("comm", DataTypes.StringType)
,StructField("deptno", DataTypes.IntegerType)))
(4)把读入的每一行数据映射成一个个Row
scala>val rowRDD = lines.map(x=>Row(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
(5) 使用SparkSession.createDataFrame创建表
scala>val df = spark.createDataFrame(rowRDD,myschema)
可以看到df支持的函数很多,其实就是RDD的算子。这里也可以看出DF很像一个RDD。
方式3:直接读取格式化的文件(json,csv)等-最简单
前提:数据文件本身一定具有格式,这里我们选取json格式的数据,json文件可以使用spark例子中提供的people.json。你也可以使用任意json文件进行操作。
测试数据如下:
[root@bigdata111 resources]# pwd
/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources
[root@bigdata111 resources]# ls
full_user.avsc kv1.txt people.json people.txt user.avsc users.avro users.parquet
[root@bigdata111 resources]# more people.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
使用SparkSession对象直接读取Json文件
spark>val peopleDF = spark.read.json("hdfs://bigdata111:9000/input/people.json")
创建完毕DF之后就可以直接查看表的信息,十分的简单:
六、操作DataFrame(DSL+SQL)
DataFrame操作也称为无类型的Dataset操作.操作的DataFrame是方法1创建的empDF.
>1.DSL(domain-specific language)操作DataFrame
1.查看所有的员工信息===selec * from empDF;
scala>empDF.show
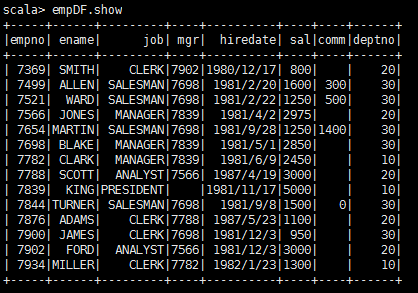
2.查询所有的员工姓名 ($符号添加不加功能一样)===select ename,deptno from empDF;
scala>empDF.select("ename","deptno").show
scala>empDF.select("deptno").show

3.查询所有的员工姓名和薪水,并给薪水加100块钱===select ename,sal,sal+100 from empDF;
scala>empDF.select("sal",$"sal"+100).show

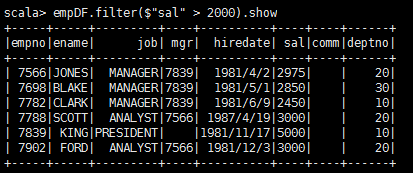
4.查询工资大于2000的员工===select * from empDF where sal>2000;
scala>empDF.filter($"sal" > 2000).show
5.分组===select deptno,count(*) from empDF group by deptno;
scala>empDF.groupBy("deptno").avg().show
scala>empDF.groupBy($"deptno").max().show

2.SQL操作DataFrame
(1)前提条件:需要把DataFrame注册成是一个Table或者View
scala>empDF.createOrReplaceTempView("emp")
(2)使用SparkSession执行从查询
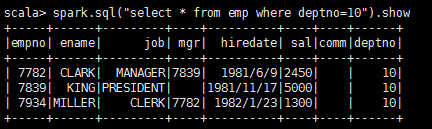
scala>spark.sql("select * from emp").show
scala>spark.sql("select * from emp where deptno=10").show
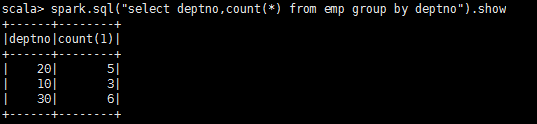
(3)求每个部门的工资总额
scala>spark.sql("select deptno,sum(sal) from emp group by deptno").show
七、视图(临时和全局视图)
在使用SQL操作DataFrame的时候,有一个前提就是必须通过DF创建一个表或者视图:empDF.createOrReplaceTempView("emp")
在SparkSQL中,如果你想拥有一个临时的view,并想在不同的Session中共享,而且在application的运行周期内可用,那么就需要创建一个全局的临时view。并记得使用的时候加上global_temp作为前缀来引用它,因为全局的临时view是绑定到系统保留的数据库global_temp上。
① 创建一个普通的view和一个全局的view
scala>empDF.createOrReplaceTempView("emp1")
scala>empDF.createGlobalTempView("emp2")

② 在当前会话中执行查询,均可查询出结果。
scala>spark.sql("select * from emp1").show
scala>spark.sql("select * from global_temp.emp2").show
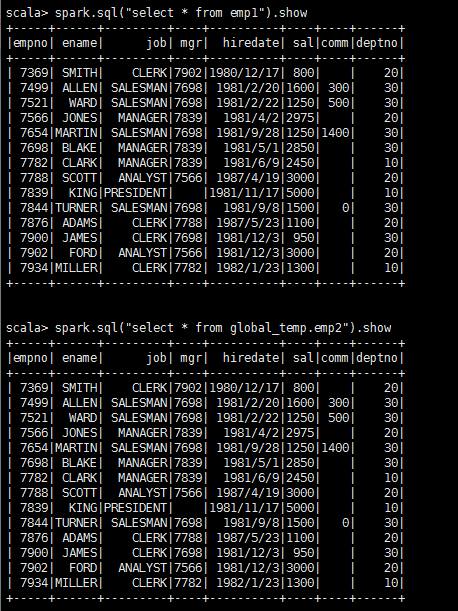
③ 开启一个新的会话,执行同样的查询
scala>spark.newSession.sql("select * from emp1").show (运行出错)
scala>spark.newSession.sql("select * from global_temp.emp2").show

八、使用数据源
在介绍parquet文件的时候我们使用的是Spark例子文件夹中提供的users.parquet文件:
[root@bigdata111 resources]# pwd
/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources
[root@bigdata111 resources]# ls
full_user.avsc kv1.txt people.json people.txt temp user.avsc users.avro users.parquet
1、通用的Load/Save函数
(*)什么是parquet文件?
Parquet是列式存储格式的一种文件类型,列式存储有以下的核心:
- 可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
- 压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
- 只读取需要的列,支持向量运算,能够获取更好的扫描性能。
Parquet格式是Spark SQL的默认数据源,可通过spark.sql.sources.default配置
(*)通用的Load/Save函数
- load函数读取Parquet文件:scala>val userDF = spark.read.load("hdfs://bigdata111:9000/input/users.parquet")
对比如下语句:
scala>val peopleDF = spark.read.json("hdfs://bigdata111:9000/input/people.json")
scala>val peopleDF = spark.read.format("json").load("hdfs://bigdata111:9000/input/people.json")
查询Schema和数据:scala>userDF.show

- save函数保存数据,默认的文件格式:Parquet文件(列式存储文件)
scala>userDF.select("favorite_color").write.save("/root/temp/result1")
scala>userDF.select("favorite_color").write.format("csv").save("/root/temp/result2")
scala>userDF.select("favorite_color").write.csv("/root/temp/result3")
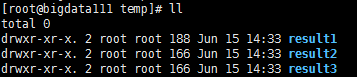
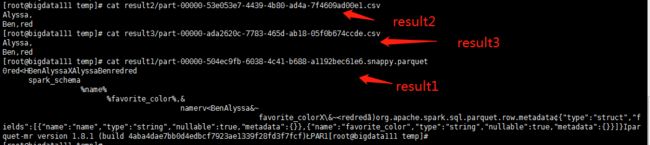
(*)显式指定文件格式:加载json格式
直接加载:val usersDF = spark.read.load("/root/resources/people.json")
会出错
val usersDF = spark.read.format("json").load("/root/resources/people.json")
(*)存储模式(Save Modes)
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。需要注意的是,这些保存模式不使用任何锁定,不是原子操作。此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。SaveMode详细介绍如下:
默认为SaveMode.ErrorIfExists模式,该模式下,如果数据库中已经存在该表,则会直接报异常,导致数据不能存入数据库.另外三种模式如下:
SaveMode.Append 如果表已经存在,则追加在该表中;若该表不存在,则会先创建表,再插入数据;
SaveMode.Overwrite 重写模式,其实质是先将已有的表及其数据全都删除,再重新创建该表,最后插入新的数据;
SaveMode.Ignore 若表不存在,则创建表,并存入数据;在表存在的情况下,直接跳过数据的存储,不会报错。
Demo:
usersDF.select($"name").write.save("/root/result/parquet1")
--> 出错:因为/root/result/parquet1已经存在
usersDF.select($"name").write.mode("overwrite").save("/root/result/parquet1")
5 读写mysql
5.1 JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
5.1.1 从Mysql中加载数据库(Spark Shell 方式)
- 启动Spark Shell,必须指定mysql连接驱动jar包
spark-shell --master spark://hadoop1:7077 --jars mysql-connector-java-5.1.35-bin.jar --driver-class-path mysql-connector-java-5.1.35-bin.jar
- 从mysql中加载数据
val jdbcDF = sqlContext.read.format("jdbc").options(
Map("url"->"jdbc:mysql://hadoop1:3306/bigdata",
"driver"->"com.mysql.jdbc.Driver",
"dbtable"->"person", // "dbtable"->"(select * from person where id = 12) as person",
"user"->"root",
"password"->"123456")
).load()
- 执行查询
jdbcDF.show()
5.1.2 将数据写入到MySQL中(打jar包方式)
- 编写Spark SQL程序
import java.util.Properties
import org.apache.spark.sql.{Row, SQLContext, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author y15079
* @create 2018-05-12 2:50
* @desc
**/
object JdbcDFDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MysqlDemo").setMaster("local[2]")
val sc = new SparkContext(conf)
//创建SQLContext spark1.6.1以下的写法
//val sqlContext = new SQLContext(sc)
//spark2.0 以上的写法
val sqlContext = SparkSession.builder().config(conf).getOrCreate()
//通过并行化创建RDD
val personRDD = sc.parallelize(Array("1 tom 5", "2 jerry 3", "3 kitty 6")).map(_.split(" "))
//通过StructType直接指定每个字段的schema
val schema = StructType(
List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
)
)
//将RDD映射到rowRDD
val rowRDD = personRDD.map(p=>Row(p(0).toInt, p(1).trim, p(2).toInt))
//将schema信息应用到rowRDD上
val personDataFrame = sqlContext.createDataFrame(rowRDD, schema)
//创建Properties存储数据库相关属性
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "123456")
//将数据追加到数据库
personDataFrame.write.mode("append").jdbc("jdbc:mysql://localhost:3306/bigdata","bigdata.person", prop)
sc.stop()
}
}
用maven-shade-plugin插件将程序打包
将jar包提交到spark集群
spark-submit
--class cn.itcast.spark.sql.jdbcDF
--master spark://hadoop1:7077
--jars mysql-connector-java-5.1.35-bin.jar
--driver-class-path mysql-connector-java-5.1.35-bin.jar
/root/demo.jar