Linux之shell编程
walkingLL 2018-09-22 08:51:26 14717 收藏 129
shell历史
Shell的作用是解释执行用户的命令,用户输入一条命令,Shell就解释执行一条,这种方式称为交互式(Interactive),Shell还有一种执行命令的方式称为批处理(Batch),用户事先写一个Shell脚本(Script),其中有很多条命令,让Shell一次把这些命令执行完,而不必一条一条地敲命令。Shell脚本和编程语言很相似,也有变量和流程控制语句,但Shell脚本是解释执行的,不需要编译,Shell程序从脚本中一行一行读取并执行这些命令,相当于一个用户把脚本中的命令一行一行敲到Shell提示符下执行。
由于历史原因,UNIX系统上有很多种Shell:
(1) sh(Bourne Shell):由Steve Bourne开发,各种UNIX系统都配有sh。
(2) csh(C Shell):由Bill Joy开发,随BSD UNIX发布,它的流程控制语句很像C语言,支持很多Bourne Shell所不支持的功能:作业控制,命令历史,命令行编辑。
(3) ksh(Korn Shell):由David Korn开发,向后兼容sh的功能,并且添加了csh引入的新功能,是目前很多UNIX系统标准配置的Shell,在这些系统上/bin/sh往往是指向/bin/ksh的符号链接。
(4) tcsh(TENEX C Shell):是csh的增强版本,引入了命令补全等功能,在FreeBSD、MacOS X等系统上替代了csh。
(5) bash(Bourne Again Shell):由GNU开发的Shell,主要目标是与POSIX标准保持一致,同时兼顾对sh的兼容,bash从csh和ksh借鉴了很多功能,是各种Linux发行版标准配置的Shell,在Linux系统上/bin/sh往往是指向/bin/bash的符号链接。虽然如此,bash和sh还是有很多不同的,一方面,bash扩展了一些命令和参数,另一方面,bash并不完全和sh兼容,有些行为并不一致,所以bash需要模拟sh的行为:当我们通过sh这个程序名启动bash时,bash可以假装自己是sh,不认扩展的命令,并且行为与sh保持一致。
itcast$ vim /etc/passwd #其中最后一列显示了用户对应的shell类型
root:\x:0:0:root:/root:/bin/bash
nobody:\x:65534:65534:nobody:/nonexistent:/bin/sh
syslog:\x:101:103::/home/syslog:/bin/false
itcast:\x:1000:1000:itcast,:/home/itcast:/bin/bash
ftp:\x:115:125:ftp daemon,:/srv/ftp:/bin/false
用户在命令行输入命令后,一般情况下Shell会fork并exec该命令,但是Shell的内建命令例外,执行内建命令相当于调用Shell进程中的一个函数,并不创建新的进程。以前学过的cd、alias、umask、exit等命令即是内建命令,凡是用which命令查不到程序文件所在位置的命令都是内建命令,内建命令没有单独的man手册,要在man手册中查看内建命令,应该执行
itcast$ man bash-builtins
如export、shift、if、eval、[、for、while等等。内建命令虽然不创建新的进程,但也会有Exit Status,通常也用0表示成功非零表示失败,虽然内建命令不创建新的进程,但执行结束后也会有一个状态码,也可以用特殊变量$?读出。
执行脚本
编写一个简单的脚本test.sh:
#! /bin/sh
cd …
ls
Shell脚本中用#表示注释,相当于C语言的//注释。但如果#位于第一行开头,并且是#!(称为Shebang)则例外,它表示该脚本使用后面指定的解释器/bin/sh解释执行。如果把这个脚本文件加上可执行权限然后执行:
itcast$ chmod a+x test.sh
itcast$ ./test.sh
Shell会fork一个子进程并调用exec执行./test.sh这个程序,exec系统调用应该把子进程的代码段替换成./test.sh程序的代码段,并从它的_start开始执行。然而test.sh是个文本文件,根本没有代码段和_start函数,怎么办呢?其实exec还有另外一种机制,如果要执行的是一个文本文件,并且第一行用Shebang指定了解释器,则用解释器程序的代码段替换当前进程,并且从解释器的_start开始执行,而这个文本文件被当作命令行参数传给解释器。因此,执行上述脚本相当于执行程序
itcast$ /bin/sh ./test.sh
以这种方式执行不需要test.sh文件具有可执行权限。如果将命令行下输入的命令用()括号括起来,那么也会fork出一个子Shell执行小括号中的命令,一行中可以输入由分号;隔开的多个命令,比如:
itcast$ (cd …;ls -l)和上面两种方法执行Shell脚本的效果是相同的,cd …命令改变的是子Shell的PWD,而不会影响到交互式Shell。然而命令
itcast$ cd …;ls -l
则有不同的效果,cd …命令是直接在交互式Shell下执行的,改变交互式Shell的PWD,然而这种方式相当于这样执行Shell脚本:
itcast$ source ./test.sh
或者
itcast$ . ./test.sh
source或者.命令是Shell的内建命令,这种方式也不会创建子Shell,而是直接在交互式Shell下逐行执行脚本中的命令。
基本语法
变量
按照惯例,Shell变量通常由字母加下划线开头,由任意长度的字母、数字、下划线组成。有两种类型的Shell变量:
环境变量
环境变量可以从父进程传给子进程,因此Shell进程的环境变量可以从当前Shell进程传给fork出来的子进程。用printenv命令可以显示当前Shell进程的环境变量。
本地变量
只存在于当前Shell进程,用set命令可以显示当前Shell进程中定义的所有变量(包括本地变量和环境变量)和函数。
环境变量是任何进程都有的概念,而本地变量是Shell特有的概念。在Shell中,环境变量和本地变量的定义和用法相似。在Shell中定义或赋值一个变量:
itcast$ VARNAME=value
注意等号两边都不能有空格,否则会被Shell解释成命令和命令行参数。
一个变量定义后仅存在于当前Shell进程,它是本地变量,用export命令可以把本地变量导出为环境变量,定义和导出环境变量通常可以一步完成:
itcast$ export VARNAME=value
也可以分两步完成:
itcast$ VARNAME=value
itcast$ export VARNAME
用unset命令可以删除已定义的环境变量或本地变量。
itcast$ unset VARNAME
如果一个变量叫做VARNAME,用 ’ VARNAME ’ 可以表示它的值,在不引起歧义的情况下也可以用VARNAME表示它的值。通过以下例子比较这两种表示法的不同:
itcast$ echo $SHELL
注意,在定义变量时不用"’"取变量值时要用。和C语言不同的是,Shell变量不需要明确定义类型,事实上Shell变量的值都是字符串,比如我们定义VAR=45,其实VAR的值是字符串45而非整数。Shell变量不需要先定义后使用,如果对一个没有定义的变量取值,则值为空字符串。
文件名代换(Globbing)
这些用于匹配的字符称为通配符(Wildcard),如:* ? [ ] 具体如下:
* 匹配0个或多个任意字符
? 匹配一个任意字符
[若干字符] 匹配方括号中任意一个字符的一次出现
itcast$ ls /dev/ttyS*
itcast$ ls ch0?.doc
itcast$ ls ch0[0-2].doc
itcast$ ls ch[012] [0-9].doc
注意,Globbing所匹配的文件名是由Shell展开的,也就是说在参数还没传给程序之前已经展开了,比如上述ls ch0[012].doc命令,如果当前目录下有ch00.doc和ch02.doc,则传给ls命令的参数实际上是这两个文件名,而不是一个匹配字符串。
命令代换
由"`"反引号括起来的也是一条命令,Shell先执行该命令,然后将输出结果立刻代换到当前命令行中。例如定义一个变量存放date 命令的输出:
itcast$ DATE=date
itcast$ echo $DATE
命令代换也可以用$()表示:
itcast$ DATE=$(date)
算术代换
使用$(()),用于算术计算,(())中的Shell变量取值将转换成整数,同样含义的$[ ]等价例如:
itcast$ VAR=45
itcast$ echo $(($VAR+3)) 等价于 echo $[VAR+3]或 $[$VAR+3]
$(())中只能用±*/和()运算符,并且只能做整数运算。
$[base#n],其中base表示进制,n按照base进制解释,后面再有运算数,按十进制解释。
echo $[2#10+11]
echo $[8#10+11]
echo $[16#10+11]
反引号
反引号(``) :命令替换,通常用于把命令输出结果传给入变量中。
命令替换是指shell能够将一个命令的标准输出插在一个命令行中任何位置。shell中有两种方法作命令替换:把shell命令用反引号或者$(…)结构括起来,其中,$(…)格式受到POSIX标准支持,也利于嵌套。
# echo The date and time is `date`
The date and time is 三 6月 15 06:10:35 CST 2005
# echo Your current working directory is $(pwd)
Your current working directory is /home/howard/script
转义字符
和C语言类似,\在Shell中被用作转义字符,用于去除紧跟其后的单个字符的特殊意义(回车除外),换句话说,紧跟其后的字符取字面值。例如:
itcast$ echo $SHELL
/bin/bash
itcast$ echo \$SHELL
$SHELL
itcast$ echo \
\
比如创建一个文件名为"$ $"的文件($间含有空格)可以这样:
itcast$ touch \$\ \$
还有一个字符虽然不具有特殊含义,但是要用它做文件名也很麻烦,就是-号。如果要创建一个文件名以-号开头的文件,这样是不正确的:
itcast$ touch -hello
touch: invalid option – h
Try `touch --help’ for more information.
即使加上转义也还是报错:
itcast$ touch \-hello
touch: invalid option – h
Try `touch --help’ for more information.
因为各种UNIX命令都把-号开头的命令行参数当作命令的选项,而不会当作文件名。如果非要处理以-号开头的文件名,可以有两种办法:
itcast$ touch ./-hello
或者
itcast$ touch – -hello
还有一种用法,在后敲回车表示续行,Shell并不会立刻执行命令,而是把光标移到下一行,给出一个续行提示符>,等待用户继续输入,最后把所有的续行接到一起当作一个命令执行。例如:
itcast$ ls \
-l
(ls -l命令的输出)
反斜杠的另一种作用,就是当反斜杠用于一行的最后一个字符时,Shell把行尾的反斜杠作为续行,这种结构在分几行输入长命令时经常使用。
单引号
单引号:所见即所得。
单引号字符串的限制:单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的。单引号字串中不能出现单引号(对单引号使用转义符后也不行)。
和C语言同,Shell脚本中的单引号和双引号一样都是字符串的界定符(双引号下一节介绍),而不是字符的界定符。单引号用于保持引号内所有字符的字面值,即使引号内的和回车也不例外,但是字符串中不能出现单引号。如果引号没有配对就输入回车,Shell会给出续行提示符,要求用户把引号配上对。例如:
itcast$ echo ‘$SHELL’
S H E L L i t c a s t SHELL itcast SHELLitcast echo ‘ABC(回车)
DE’(再按一次回车结束命令)
ABC
DE
双引号
双引号:所见非所得,它会先把变量解析之后,再输出。
双引号的优点:双引号里可以有变量。双引号里可以出现转义字符。
被双引号用括住的内容,将被视为单一字串。它防止通配符扩展,但允许变量扩展。这点与单引号的处理方式不同。
itcast$ DATE=$(date)
itcast$ echo “$DATE”
itcast$ echo ‘$DATE’
再比如:
itcast$ VAR=200
itcast$ echo $VAR
200
itcast$ echo ‘$VAR’
$VAR
itcast$ echo “$VAR”
200
$'String’和$“String”
(1)如果没有特殊定制bash环境或有特殊需求,$“string"和"string"是完全等价的,使用$”"只是为了保证本地化。
以下是man bash关于 " " 的 解 释 : A d o u b l e − q u o t e d s t r i n g p r e c e d e d b y a d o l l a r s i g n ( ""的解释: A double-quoted string preceded by a dollar sign ( ""的解释:Adouble−quotedstringprecededbyadollarsign("string") will cause the string to be translated according to the current locale. If the current locale is C or POSIX, the dollar sign is ignored. If the string is translated and replaced, the replacement is double-quoted.
(2)还有$后接单引号的$‘string’,这在bash中被特殊对待:会将某些反斜线序列(如n,t,",'等)继续转义,而不认为它是字面符号(如果没有$符号,单引号会强制将string翻译为字面符号,包括反斜线)。简单的例子:
[root@xuexi ~]# echo ‘a\nb’
anb
[root@xuexi ~]# echo $‘a\nb’
a
b
$#,$@,$0,$1,$2的含义
变量说明:
$$
Shell本身的PID(ProcessID)
$!
Shell最后运行的后台Process的PID
$?
最后运行的命令的结束代码(返回值)
$-
使用Set命令设定的Flag一览
$*
所有参数列表。如"$*“用「”」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。
$@
所有参数列表。如"$@“用「”」括起来的情况、以"$1" “ 2 " . . . " 2" ... " 2"..."n” 的形式输出所有参数。
$#
添加到Shell的参数个数
$0
Shell本身的文件名
$1~$n
添加到Shell的各参数值。$1是第1参数、$2是第2参数…。
各种括号()、(())、[]、[[]]、{}
更新时间:2017年09月07日 09:10:09 作者:QuintinX 脚本之家
小括号,圆括号()
单小括号 ()
①命令组。括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用。括号中多个命令之间用分号隔开,最后一个命令可以没有分号,各命令和括号之间不必有空格。
②命令替换。等同于`cmd`,shell扫描一遍命令行,发现了$(cmd)结构,便将$(cmd)中的cmd执行一次,得到其标准输出,再将此输出放到原来命令。有些shell不支持,如tcsh。
③用于初始化数组。如:array=(a b c d)
双小括号 (( ))
①整数扩展。这种扩展计算是整数型的计算,不支持浮点型。((exp))结构扩展并计算一个算术表达式的值,如果表达式的结果为0,那么返回的退出状态码为1,或者 是"假",而一个非零值的表达式所返回的退出状态码将为0,或者是"true"。若是逻辑判断,表达式exp为真则为1,假则为0。
②只要括号中的运算符、表达式符合C语言运算规则,都可用在$((exp))中,甚至是三目运算符。作不同进位(如二进制、八进制、十六进制)运算时,输出结果全都自动转化成了十进制。如:echo $((16#5f)) 结果为95 (16进位转十进制)
③单纯用 (( )) 也可重定义变量值,比如 a=5; ((a++)) 可将 $a 重定义为6
④常用于算术运算比较,双括号中的变量可以不使用$符号前缀。括号内支持多个表达式用逗号分开。 只要括号中的表达式符合C语言运算规则,比如可以直接使用for((i=0;i<5;i++)), 如果不使用双括号, 则为for i in seq 0 4或者for i in {0…4}。再如可以直接使用if (($i<5)), 如果不使用双括号, 则为if [ $i -lt 5 ]。
中括号,方括号[]
单中括号 []
①bash 的内部命令,[和test是等同的。如果我们不用绝对路径指明,通常我们用的都是bash自带的命令。if/test结构中的左中括号是调用test的命令标识,右中括号是关闭条件判断的。这个命令把它的参数作为比较表达式或者作为文件测试,并且根据比较的结果来返回一个退出状态码。if/test结构中并不是必须右中括号,但是新版的Bash中要求必须这样。
②Test和[]中可用的比较运算符只有==和!=,两者都是用于字符串比较的,不可用于整数比较,整数比较只能使用-eq,-gt这种形式。无论是字符串比较还是整数比较都不支持大于号小于号。如果实在想用,对于字符串比较可以使用转义形式,如果比较"ab"和"bc":[ ab \< bc ],结果为真,也就是返回状态为0。[ ]中的逻辑与和逻辑或使用-a 和-o 表示。
③字符范围。用作正则表达式的一部分,描述一个匹配的字符范围。作为test用途的中括号内不能使用正则。
④在一个array 结构的上下文中,中括号用来引用数组中每个元素的编号。
双中括号[[ ]]
①[[是 bash 程序语言的关键字。并不是一个命令,[[ ]] 结构比[ ]结构更加通用。在[[和]]之间所有的字符都不会发生文件名扩展或者单词分割,但是会发生参数扩展和命令替换。
②支持字符串的模式匹配,使用=~操作符时甚至支持shell的正则表达式。字符串比较时可以把右边的作为一个模式,而不仅仅是一个字符串,比如[[ hello == hell? ]],结果为真。[[ ]] 中匹配字符串或通配符,不需要引号。
③使用[[ … ]]条件判断结构,而不是[ … ],能够防止脚本中的许多逻辑错误。比如,&&、||、<和> 操作符能够正常存在于[[ ]]条件判断结构中,但是如果出现在[ ]结构中的话,会报错。比如可以直接使用if [[ $a != 1 && $a != 2 ]], 如果不适用双括号, 则为if [ $a -ne 1] && [ $a != 2 ]或者if [ $a -ne 1 -a $a != 2 ]。
④bash把双中括号中的表达式看作一个单独的元素,并返回一个退出状态码。
例子:
if ($i<5)
if [ $i -lt 5 ]
if [ $a -ne 1 -a $a != 2 ]
if [ $a -ne 1] && [ $a != 2 ]
if [[ $a != 1 && $a != 2 ]]
for i in $(seq 0 4);do echo $i;done
for i in `seq 0 4`;do echo $i;done
for ((i=0;i<5;i++));do echo $i;done
for i in {0…4};do echo $i;done
大括号、花括号 {}
常规用法
①大括号拓展。(通配(globbing))将对大括号中的文件名做扩展。在大括号中,不允许有空白,除非这个空白被引用或转义。第一种:对大括号中的以逗号分割的文件列表进行拓展。如 touch {a,b}.txt 结果为a.txt b.txt。第二种:对大括号中以点点(…)分割的顺序文件列表起拓展作用,如:touch {a…d}.txt 结果为a.txt b.txt c.txt d.txt
# ls {ex1,ex2}.sh
ex1.sh ex2.sh
# ls {ex{1…3},ex4}.sh
ex1.sh ex2.sh ex3.sh ex4.sh
# ls {ex[1-3],ex4}.sh
ex1.sh ex2.sh ex3.sh ex4.sh
②代码块,又被称为内部组,这个结构事实上创建了一个匿名函数 。与小括号中的命令不同,大括号内的命令不会新开一个子shell运行,即脚本余下部分仍可使用括号内变量。括号内的命令间用分号隔开,最后一个也必须有分号。{}的第一个命令和左括号之间必须要有一个空格。
几种特殊的替换结构 ${var:-string}
${var:-string},${var:+string},${var:=string},${var:?string}
①${var:-string}和${var:=string}:若变量var为空,则用在命令行中用string来替换${var:-string},否则变量var不为空时,则用变量var的值来替换${var:-string};对于${var:=string}的替换规则和${var:-string}是一样的,所不同之处是${var:=string}若var为空时,用string替换${var:=string}的同时,把string赋给变量var: ${var:=string}很常用的一种用法是,判断某个变量是否赋值,没有的话则给它赋上一个默认值。
② ${var:+string}的替换规则和上面的相反,即只有当var不是空的时候才替换成string,若var为空时则不替换或者说是替换成变量 var的值,即空值。(因为变量var此时为空,所以这两种说法是等价的)
③${var:?string}替换规则为:若变量var不为空,则用变量var的值来替换${var:?string};若变量var为空,则把string输出到标准错误中,并从脚本中退出。我们可利用此特性来检查是否设置了变量的值。
补充扩展:在上面这五种替换结构中string不一定是常值的,可用另外一个变量的值或是一种命令的输出。
四种模式匹配替换结构 ${var%%pattern}
模式匹配记忆方法:
# 是去掉左边(在键盘上#在$之左边)
% 是去掉右边(在键盘上%在$之右边)
#和%中的单一符号是最小匹配,两个相同符号是最大匹配。
${var%pattern},${var%%pattern},${var#pattern},${var##pattern}
第一种模式:${variable%pattern},这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最短的匹配模式
第二种模式: ${variable%%pattern},这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最长的匹配模式
第三种模式:${variable#pattern} 这种模式时,shell在variable中查找,看它是否一给的模式pattern开始,如果是,就从命令行把variable中的内容去掉左边最短的匹配模式
第四种模式: ${variable##pattern} 这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉左边最长的匹配模式
这四种模式中都不会改变variable的值,其中,只有在pattern中使用了*匹配符号时,%和%%,#和##才有区别。结构中的pattern支持通配符,*表示零个或多个任意字符,?表示仅与一个任意字符匹配,[…]表示匹配中括号里面的字符,[!..]表示不匹配中括号里面的字符。
# var=testcase
# echo $var
testcase
# echo ${var%s*e}
testca
# echo $var
testcase
# echo ${var%%s*e}
te
# echo ${var#?e}
stcase
# echo ${var##?e}
stcase
# echo ${var##*e}
# echo ${var##*s}
e
# echo ${var##test}
case
字符串提取和替换,蛮有用 ${var:num1:num2}
${var:num},${var:num1:num2},${var/pattern/pattern},${var//pattern/pattern}
第一种模式:${var:num},这种模式时,shell在var中提取第num个字符到末尾的所有字符。若num为正数,从左边0处开始;若num为负数,从右边开始提取字串,但必须使用在冒号后面加空格或一个数字或整个num加上括号,如${var: -2}、${var:1-3}或${var:(-2)}。
第二种模式:${var:num1:num2},num1是位置,num2是长度。表示从$var字符串的第$num1个位置开始提取长度为$num2的子串。不能为负数。
第三种模式:${var/pattern/pattern}表示将var字符串的第一个匹配的pattern替换为另一个pattern。
第四种模式:${var//pattern/pattern}表示将var字符串中的所有能匹配的pattern替换为另一个pattern。
[root@centos ~]# var=/home/centos
[root@centos ~]# echo $var
/home/centos
[root@centos ~]# echo ${var:5}
/centos
[root@centos ~]# echo ${var: -6}
centos
[root@centos ~]# echo ${var:(-6)}
centos
[root@centos ~]# echo ${var:1:4}
home
[root@centos ~]# echo ${var/o/h}
/hhme/centos
[root@centos ~]# echo ${var//o/h}
/hhme/cenths

符号$后的括号
(1)${a} 变量a的值, 在不引起歧义的情况下可以省略大括号。
(2)$(cmd) 命令替换,和`cmd`效果相同,结果为shell命令cmd的输,过某些Shell版本不支持$()形式的命令替换, 如tcsh。
(3)$((expression)) 和`exprexpression`效果相同, 计算数学表达式exp的数值, 其中exp只要符合C语言的运算规则即可, 甚至三目运算符和逻辑表达式都可以计算。
{}()单独使用
1、多条命令执行
(1)单小括号,(cmd1;cmd2;cmd3) 新开一个子shell顺序执行命令cmd1,cmd2,cmd3, 各命令之间用分号隔开, 最后一个命令后可以没有分号。
(2)单大括号,{ cmd1;cmd2;cmd3;} 在当前shell顺序执行命令cmd1,cmd2,cmd3, 各命令之间用分号隔开, 最后一个命令后必须有分号, 第一条命令和左括号之间必须用空格隔开。
对{}和()而言, 括号中的重定向符只影响该条命令, 而括号外的重定向符影响到括号中的所有命令。
Shell脚本语法
条件测试
命令test或 [ 可以测试一个条件是否成立,如果测试结果为真,则该命令的Exit Status为0,如果测试结果为假,则命令的Exit Status为1(注意与C语言的逻辑表示正好相反)。例如测试两个数的大小关系:
itcast@ubuntu:~$ var=2
itcast@ubuntu:~$ test v a r − g t 1 i t c a s t @ u b u n t u : var -gt 1 itcast@ubuntu:~ var−gt1itcast@ubuntu: echo $?
0
itcast@ubuntu:~$ test v a r − g t 3 i t c a s t @ u b u n t u : var -gt 3 itcast@ubuntu:~ var−gt3itcast@ubuntu: echo $?
1
itcast@ubuntu:~$ [ v a r − g t 3 ] i t c a s t @ u b u n t u : var -gt 3 ] itcast@ubuntu:~ var−gt3]itcast@ubuntu: echo $?
1
虽然看起来很奇怪,但左方括号 [ 确实是一个命令的名字,传给命令的各参数之间应该用空格隔开,比如:$VAR、-gt、3、] 是 [ 命令的四个参数,它们之间必须用空格隔开。命令test或 [ 的参数形式是相同的,只不过test命令不需要 ] 参数。以 [ 命令为例,常见的测试命令如下表所示:
[ -d DIR ] 如果DIR存在并且是一个目录则为真
[ -f FILE ] 如果FILE存在且是一个普通文件则为真
[ -z STRING ] 如果STRING的长度为零则为真
[ -n STRING ] 如果STRING的长度非零则为真
[ STRING1 = STRING2 ] 如果两个字符串相同则为真
[ STRING1 != STRING2 ] 如果字符串不相同则为真
[ ARG1 OP ARG2 ] ARG1和ARG2应该是整数或者取值为整数的变量,OP是-eq(等于)-ne(不等于)-lt(小于)-le(小于等于)-gt(大于)-ge(大于等于)之中的一个。
和C语言类似,测试条件之间还可以做与、或、非逻辑运算:
[ ! EXPR ] EXPR可以是上表中的任意一种测试条件,!表示"逻辑反(非)"
[ EXPR1 -a EXPR2 ] EXPR1和EXPR2可以是上表中的任意一种测试条件,-a表示"逻辑与"
[ EXPR1 -o EXPR2 ] EXPR1和EXPR2可以是上表中的任意一种测试条件,-o表示"逻辑或"
例如:
$ VAR=abc
$ [ -d Desktop -a $VAR = ‘abc’ ]
$ echo $?
0
注意,如果上例中的$VAR变量事先没有定义,则被Shell展开为空字符串,会造成测试条件的语法错误(展开为[ -d Desktop -a = ‘abc’ ]),作为一种好的Shell编程习惯,应该总是把变量取值放在双引号之中(展开为[ -d Desktop -a “” = ‘abc’ ]):
$ unset VAR
$ [ -d Desktop -a $VAR = ‘abc’ ]
bash: [: too many arguments
$ [ -d Desktop -a “$VAR” = ‘abc’ ]
$ echo $?
1
分支if/then/elif/else/fi
if的基本语法
if [ command ];then
符合该条件执行的语句
elif [ command ];then
符合该条件执行的语句
else
符合该条件执行的语句
fi
文件/文件夹(目录)判断
[ -b FILE ] 如果 FILE 存在且是一个块特殊文件则为真。
[ -c FILE ] 如果 FILE 存在且是一个字特殊文件则为真。
[ -d DIR ] 如果 FILE 存在且是一个目录则为真。
[ -e FILE ] 如果 FILE 存在则为真。
[ -f FILE ] 如果 FILE 存在且是一个普通文件则为真。
[ -g FILE ] 如果 FILE 存在且已经设置了SGID则为真。
[ -k FILE ] 如果 FILE 存在且已经设置了粘制位则为真。
[ -p FILE ] 如果 FILE 存在且是一个名字管道(F如果O)则为真。
[ -r FILE ] 如果 FILE 存在且是可读的则为真。
[ -s FILE ] 如果 FILE 存在且大小不为0则为真。
[ -t FD ] 如果文件描述符 FD 打开且指向一个终端则为真。
[ -u FILE ] 如果 FILE 存在且设置了SUID (set user ID)则为真。
[ -w FILE ] 如果 FILE存在且是可写的则为真。
[ -x FILE ] 如果 FILE 存在且是可执行的则为真。
[ -O FILE ] 如果 FILE 存在且属有效用户ID则为真。
[ -G FILE ] 如果 FILE 存在且属有效用户组则为真。
[ -L FILE ] 如果 FILE 存在且是一个符号连接则为真。
[ -N FILE ] 如果 FILE 存在 and has been mod如果ied since it was last read则为真。
[ -S FILE ] 如果 FILE 存在且是一个套接字则为真。
[ FILE1 -nt FILE2 ] 如果 FILE1 has been changed more recently than FILE2, or 如果 FILE1 exists and FILE2 does not则为真。
[ FILE1 -ot FILE2 ] 如果 FILE1 比 FILE2 要老, 或者 FILE2 存在且 FILE1 不存在则为真。
[ FILE1 -ef FILE2 ] 如果 FILE1 和 FILE2 指向相同的设备和节点号则为真。
字符串判断
[ -z STRING ] 如果STRING的长度为零则为真 ,即判断是否为空,空即是真;
[ -n STRING ] 如果STRING的长度非零则为真 ,即判断是否为非空,非空即是真;
[ STRING1 = STRING2 ] 如果两个字符串相同则为真 ;
[ STRING1 != STRING2 ] 如果字符串不相同则为真 ;
[ STRING1 ] 如果字符串不为空则为真,与-n类似
数值判断
[ INT1 -eq INT2 ] INT1和INT2两数相等为真 ,=
[ INT1 -ne INT2 ] INT1和INT2两数不等为真 ,<>
[ INT1 -gt INT2 ] INT1大于INT1为真 ,>
[ INT1 -ge INT2 ] INT1大于等于INT2为真,>=
[ INT1 -lt INT2 ] INT1小于INT2为真 ,<
[ INT1 -le INT2 ] INT1小于等于INT2为真,<=
复杂逻辑判断
-a 与
-o 或
! 非
举例
和C语言类似,在Shell中用if、then、elif、else、fi这几条命令实现分支控制。这种流程控制语句本质上也是由若干条Shell命令组成的,例如先前讲过的
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
其实是三条命令,if [ -f ∼/.bashrc ]是第一条,then . ∼/.bashrc是第二条,fi是第三条。如果两条命令写在同一行则需要用;号隔开,一行只写一条命令就不需要写;号了,另外,then后面有换行,但这条命令没写完,Shell会自动续行,把下一行接在then后面当作一条命令处理。和[命令一样,要注意命令和各参数之间必须用空格隔开。if命令的参数组成一条子命令,如果该子命令的Exit Status为0(表示真),则执行then后面的子命令,如果Exit Status非0(表示假),则执行elif、else或者fi后面的子命令。if后面的子命令通常是测试命令,但也可以是其它命令。Shell脚本没有{}括号,所以用fi表示if语句块的结束。见下例:
#! /bin/sh
if [ -f /bin/bash ]
then
echo "/bin/bash is a file"
else
echo "/bin/bash is NOT a file"
fi
if :; then echo "always true"; fi
":"是一个特殊的命令,称为空命令,该命令不做任何事,但Exit Status总是真。此外,也可以执行/bin/true或/bin/false得到真或假的Exit Status。再看一个例子:
#! /bin/sh
echo "Is it morning? Please answer yes or no."
read YES_OR_NO
if [ "$YES_OR_NO" = "yes" ]; then
echo "Good morning!"
elif [ "$YES_OR_NO" = "no" ]; then
echo "Good afternoon!"
else
echo "Sorry, $YES_OR_NO not recognized. Enter yes or no."
exit 1
fi
exit 0
上例中的read命令的作用是等待用户输入一行字符串,将该字符串存到一个Shell变量中。
此外,Shell还提供了&&和||语法,和C语言类似,具有Short-circuit特性,很多Shell脚本喜欢写成这样:
test “$(whoami)” != ‘root’ && (echo you are using a non-privileged account; exit 1)
&&相当于"if…then…",而||相当于"if not…then…"。&&和||用于连接两个命令,而上面讲的-a和-o仅用于在测试表达式中连接两个测试条件,要注意它们的区别,例如:
test “$VAR” -gt 1 -a “$VAR” -lt 3
和以下写法是等价的
test “$VAR” -gt 1 && test “$VAR” -lt 3
case/esac
case命令可类比C语言的switch/case语句,esac表示case语句块的结束。C语言的case只能匹配整型或字符型常量表达式,而Shell脚本的case可以匹配字符串和Wildcard,每个匹配分支可以有若干条命令,末尾必须以;;结束,执行时找到第一个匹配的分支并执行相应的命令,然后直接跳到esac之后,不需要像C语言一样用break跳出。
除了以;;结束之外,还可以用**;&连接执行多个条件**。
(1) 实例1:
#! /bin/sh
echo "Is it morning? Please answer yes or no."
read YES_OR_NO
case "$YES_OR_NO" in
yes|y|Yes|YES)
echo "Good Morning!";;
[nN]*)
echo "Good Afternoon!";;
*)
echo "Sorry, $YES_OR_NO not recognized. Enter yes or no."
exit 1;;
esac
exit 0
(2) 实例2:
for option in ${OPTIONS}; do
echo "processing option: $option"
case $option in
BoardConfig*.mk)
option=device/rockchip/$RK_TARGET_PRODUCT/$option
;& #继续执行后面的条件
*.mk)
CONF=$(realpath $option)
echo "switching to board: $CONF"
if [ ! -f $CONF ]; then
echo "not exist!"
exit 1
fi
ln -rsf $CONF $BOARD_CONFIG
;;
lunch) build_select_board ;;
all) build_all ;;
info) build_info ;;
app/*|external/*) build_pkg $option ;;
*) usage ;;
esac
done
(3) 实例3:
使用case语句的例子可以在系统服务的脚本目录/etc/init.d中找到。这个目录下的脚本大多具有这种形式(以/etc/init.d/nfs-kernel-server为例):
case "$1" in
start)
...
;;
stop)
...
;;
reload | force-reload)
...
;;
restart)
...
*)
log_success_msg"Usage: nfs-kernel-server {start|stop|status|reload|force-reload|restart}"
exit 1
;;
esac
启动nfs-kernel-server服务的命令是
$ sudo /etc/init.d/nfs-kernel-server start
$1是一个特殊变量,在执行脚本时自动取值为第一个命令行参数,也就是start,所以进入start)分支执行相关的命令。同理,命令行参数指定为stop、reload或restart可以进入其它分支执行停止服务、重新加载配置文件或重新启动服务的相关命令。
循环for/do/done
Shell脚本的for循环结构和C语言很不一样,它类似于某些编程语言的foreach循环。例如:
#! /bin/sh
for FRUIT in apple banana pear; do
echo “I like $FRUIT”
done
FRUIT是一个循环变量,第一次循环$FRUIT的取值是apple,第二次取值是banana,第三次取值是pear。再比如,要将当前目录下的chap0、chap1、chap2等文件名改为chap0、chap1、chap2等(按惯例,末尾有字符的文件名表示临时文件),这个命令可以这样写:
$ for FILENAME in chap?; do mv $FILENAME $FILENAME~; done
也可以这样写:
$ for FILENAME in `ls chap?`; do mv $FILENAME $FILENAME~; done
while/do/done
while的用法和C语言类似。比如一个验证密码的脚本:
#! /bin/sh
echo “Enter password:”
read TRY
while [ “$TRY” != “secret” ]; do
echo “Sorry, try again”
read TRY
done
下面的例子通过算术运算控制循环的次数:
#! /bin/sh
COUNTER=1
while [ “$COUNTER” -lt 10 ]; do
echo “Here we go again”
COUNTER=$(($COUNTER+1))
done
另,Shell还有until循环,类似C语言的do…while。如有兴趣可在课后自行扩展学习。
break和continue
break[n]可以指定跳出几层循环;continue跳过本次循环,但不会跳出循环。
即break跳出,continue跳过。
练习:将上面验证密码的程序修改一下,如果用户输错五次密码就报错退出。
位置参数和特殊变量 $X
有很多特殊变量是被Shell自动赋值的,我们已经遇到了$?和$1。其他常用的位置参数和特殊变量在这里总结一下:
$0 相当于C语言main函数的argv[0]
$1、$2… 这些称为位置参数(Positional Parameter),相当于C语言main函数的argv[1]、argv[2]…
$# 相当于C语言main函数的argc - 1,注意这里的#后面不表示注释
$@ 表示参数列表"$1" “$2” …,例如可以用在for循环中的in后面。
$* 表示参数列表"$1" “$2” …,同上
$? 上一条命令的Exit Status
$$ 当前进程号
位置参数可以用shift命令左移。比如shift 3表示原来的$4现在变成$1,原来的$5现在变成$2等等,原来的$1、$2、$3丢弃,$0不移动。不带参数的shift命令相当于shift 1。例如:
#! /bin/sh
echo “The program $0 is now running”
echo “The first parameter is $1”
echo “The second parameter is $2”
echo “The parameter list is $@”
shift
echo “The first parameter is $1”
echo “The second parameter is $2”
echo “The parameter list is $@”
read
要与Linux交互,脚本获取键盘输入的结果是必不可少的,read可以读取键盘输入的字符。shell的read就是按行从文件(或标准输入或给定文件描述符)中读取数据的最佳选择。当使用管道、重定向方式组合命令时感觉达不到自己的需求时,不妨考虑下while read line。
read [-rs] [-a ARRAY] [-d delim] [-n nchars] [-N nchars] [-p prompt] [-t timeout] [-u fd] [var_name1 var_name2 …]
read命令用于从标准输入中读取输入单行,并将读取的单行根据IFS变量分裂成多个字段,并将分割后的字段分别赋值给指定的变量列表var_name。第一个字段分配给第一个变量var_name1,第二个字段分配给第二个变量var_name2,依次到结束。如果指定的变量名少于字段数量,则多出的字段数量也同样分配给最后一个var_name,如果指定的变量命令多于字段数量,则多出的变量赋值为空。
如果没有指定任何var_name,则分割后的所有字段都存储在特定变量REPLY中。
选项说明
-a:将分裂后的字段依次存储到指定的数组中,存储的起始位置从数组的index=0开始。
-d:指定读取行的结束符号。默认结束符号为换行符。
-n:限制读取N个字符就自动结束读取,如果没有读满N个字符就按下回车或遇到换行符,也会结束读取。
-N:严格要求读满N个字符才自动结束读取,即使中途按下了回车或遇到了换行符也不结束。其中换行符或回车算一个字符。
-p:给出提示符。默认不支持"n"换行,要换行需要特殊处理,见下文示例。例如,"-p 请输入密码:"
-r:禁止反斜线的转义功能。这意味着""会变成文本的一部分。
-s:静默模式。输入的内容不会回显在屏幕上。
-t:超时时间,在达到超时时间时,read退出并返回错误。不会读取任何内容,即使已经输入了一部分。
-u:从给定文件描述符(fd=N)中读取数据。
基本用法示例
(1)将读取的内容分配给数组变量,从索引号0开始分配。
[root@xuexi ~]# read -a array_test
what is you name?
[root@xuexi ~]# echo ${array_test[@]}
what is you name?
[root@xuexi ~]# echo ${array_test[0]}
what
(2)指定读取行的结束符号,而不再使用换行符。
[root@xuexi ~]# read -d ‘/’
what is you name // # 输入完尾部的"/",自动结束read
由于没有指定var_name,所以通过$REPLY变量查看read读取的行。
[root@xuexi ~]# echo $REPLY
what is you name /
(3)限制输入字符。
例如,输入了5个字符后就结束。
[root@xuexi tmp]# read -n 5
12345
[root@xuexi tmp]# echo $REPLY # 输入12345共5个字符
12345
如果输入的字符数小于5,按下回车会立即结束读取。
[root@xuexi ~]# read -n 5
123
[root@xuexi ~]# echo $REPLY
123
但如果使用的是"-N 5"而不是"-n 5",则严格限制读满5个字符才结束读取。
[root@xuexi ~]# read -N 5
123n4
[root@xuexi ~]# read -N 5
123 # 3后的回车(换行)算是一个字符
4
(4)使用-p选项给出输入提示。
[root@xuexi ~]# read -p "pls enter you name: "
pls enter you name: Junmajinlong
[root@xuexi ~]# echo $REPLY
Junmajinlong
"-p"选项默认不带换行功能,且也不支持"n"换行。但通过$'string’的方式特殊处理,就可以实现换行的功能。例如:
[root@node2 ~]# read -p $‘Enter your name: \n’
Enter your name:
JunMaJinLong
关于$'String’和$"String"的作用,见http://www.cnblogs.com/f-ck-need-u/p/8454364.html
(5)禁止反斜线转义功能。
[root@xuexi ~]# read -r
what is you name ?
[root@xuexi ~]# echo $REPLY
what is you name ?
(6)不回显输入的字符。比如输入密码的时候,不回显输入密码。
[root@xuexi ~]# read -s -p "please enter your password: "
please enter your password:
[root@xuexi ~]# echo $REPLY
123456
(7)将读取的行分割后赋值给变量。
[root@xuexi ~]# read var1 var2 var3
abc def galsl djks
[root@xuexi ~]# echo $var1:::$var2:::$var3
abc:::def:::galsl djks
(8)给出输入时间限制。没完成的输入将被丢弃,所以变量将赋值为空(如果在执行read前,变量已被赋值,则此变量在read超时后将被覆盖为空)。
[root@xuexi ~]# var=5
[root@xuexi ~]# read -t 3 var
1
[root@xuexi ~]# echo $var
while read line
如果read不明确指定按字符数读取文件(或标准输入),那么默认是按行读取的,而且每读一行都会在那一行处打上标记(即文件指针。当然,按字符数读取也一样会打上标记),表示这一次已经读取到了这个地方,使得下次仍然能够从这里开始继续向下读取。这使得read结合while使用的时候,是按行读数据非常好的方式。
例如:
[root@xuexi ~]# cat test1
a
b
c
d
# 用法示例1
[root@xuexi ~]# cat test1 | while read line;do echo $line;done
a
b
c
d
# 用法示例2
[root@xuexi ~]# while read line;do echo $line;done
b
c
d
# 用法示例3:请对比下面这条命令和上面的 关于while read line,需要注意几个事项: 所以,在使用while read line的时候,能用示例2的方式就用示例2,如果你还不理解或者找不到其它方式,那么直接记住这个结论。 显示文本行或变量,或者把字符串输入到文件。 echo [option] string echo “hellonn” 可以通过 | 把一个命令的输出传递给另一个命令做输入。 tee命令把结果输出到标准输出,另一个副本输出到相应文件。 df -k | awk ‘{print $1}’ | grep -v “文件系统” | tee a.txt tee -a a.txt表示追加操作。 cmd > file 把标准输出重定向到新文件中 和C语言类似,Shell中也有函数的概念,但是函数定义中没有返回值也没有参数列表。例如: 注意函数体的左花括号 { 和后面的命令之间必须有空格或换行,如果将最后一条命令和右花括号 } 写在同一行,命令末尾必须有分号;。但,不建议将函数定义写至一行上,不利于脚本阅读。 在定义foo()函数时并不执行函数体中的命令,就像定义变量一样,只是给foo这个名一个定义,到后面调用foo函数的时候(注意Shell中的函数调用不写括号)才执行函数体中的命令。Shell脚本中的函数必须先定义后调用,一般把函数定义语句写在脚本的前面,把函数调用和其它命令写在脚本的最后(类似C语言中的main函数,这才是整个脚本实际开始执行命令的地方)。 Shell函数没有参数列表并不表示不能传参数,事实上,函数就像是迷你脚本,调用函数时可以传任意个参数,在函数内同样是用$0、$1、$2等变量来提取参数,函数中的位置参数相当于函数的局部变量,改变这些变量并不会影响函数外面的$0、$1、$2等变量。函数中可以用return命令返回,如果return后面跟一个数字则表示函数的Exit Status。 下面这个脚本可以一次创建多个目录,各目录名通过命令行参数传入,脚本逐个测试各目录是否存在,如果目录不存在,首先打印信息然后试着创建该目录。 注意:is_directory()返回0表示真返回1表示假。 当需要忽略全空格的时候,用[ $NAME ]。 (1) 变量通过" "引号引起来 #!/bin/sh (2) 直接通过变量判断 #!/bin/sh (3) 使用test判断 (4) 使用""判断 &&:用来执行条件成立后执行的命令 例如: 获取执行结果代码。使用"$?"获取。 (1) shell返回码,标识整个脚本的执行结果状态,用"exit 返回码"表示。 使用declare -a 命令定义数组(数组的索引是从0开始计数的),接下来就可以通过[]操作符为不同索引位置的元素赋值。 注意:shell变量是弱类型的,数组中元素类型可以不相同 #增加元素 创建数组最简单的方法是使用()直接定义数组,括号中元素用空格隔开;在括号中也可以声明下标。实例: #或者在()中声明下标,默认从0开始 #下标可以不连续 使用[]操作符,为每一个指定下标赋值,下标也可以不连续 days=(`cat days.txt`) 指定下标,使用[]操作符为元素赋值,当下标不存在时,相当于为数组增加元素 指定下标,使用[]操作符从数组中对应元素,然后使用$取值,格式:${数组名[索引]} #取出第1个元素 #取出第3个元素 获得数组中所有值:${数组名[@]}、${数组名[]} 注意:${数组名}并不会获得所有值,它只会获得到第一个元素的值。即${数组名}等价于${数组名[0]} 结果: 利用"@“或”*“字符,将数组扩展成列表,然后使用”#"来获取数组元素的个数。 示例: days=(one two three four) 结果: 存在以下三种方式: 示例: days=(one two three four) #fou循环带下标遍历 #while循环 结果: 删除一个数组或数组中元素用unset命令。 unset 数组名[索引] #删除索引下的元素 用()将多个数组连接在一起,()中各个数组用空格隔开。 Shell提供了一些用于调试脚本的选项,如: 这些选项有三种常见的使用方法。 如: 如: set -x和set +x分别表示启用和禁用-x参数,这样可以只对脚本中的某一段进行跟踪调试。 如: shell中set指令的用法详解 更新时间:2020年10月16日 11:46:49 作者:曹灰灰 脚本之家 set [-可选参数] [-o 选项] set 指令可根据不同的需求来设置当前所使用 shell 的执行方式,同时也可以用来设置或显示 shell 变量的值。当指定某个单一的选项时将设置 shell 的常用特性,如果在选项后使用 -o 参数将打开特殊特性,若是 +o 将关闭相应的特殊特性。而不带任何参数的 set 指令将显示当前 shell 中的全部变量,且总是返回 true,除非遇到非法的选项。 可选参数及其说明如下: 最常用的两个参数就是 -e 与 -x ,一般写在 shell 代码逻辑之前,这两个组合在一起用,可以在 debug 的时候替你节省许多时间 。 注:set -e结束程序的条件比较复杂,在man bash里面,足足用了一段话描述各种情景。大多数执行都会在出错时退出,除非 shell 命令位于以下情况: set:初始化位置参数。调用 set 是接一个或多个参数时,set 会把参数的值赋予位置参数,从 $1 开始赋值。如下例子: $ ./set-it.sh 如上,在执行 set-it.sh 脚本时并没有输入参数,但是使用 set 指令后会对位置参数进行赋值。 set:显示 shell 变量。如果不带任何参数的使用 set 命令,set 指令就会显示一列已设置的 shell 变量,包括用户定义的变量和关键字变量。 以前我们用grep在一个文件中找出包含某些字符串的行,比如在头文件中找出一个宏定义。其实grep还可以找出符合某个模式(Pattern)的一类字符串。例如找出所有符合[email protected]模式的字符串(也就是email地址),要求x字符可以是字母、数字、下划线、小数点或减号,email地址的每一部分可以有一个或多个x字符,例如[email protected]、[email protected],当然符合这个模式的不全是合法的email地址,但至少可以做一次初步筛选,筛掉a.b、c@d等肯定不是email地址的字符串。再比如,找出所有符合yyy.yyy.yyy.yyy模式的字符串(也就是IP地址),要求y是0-9的数字,IP地址的每一部分可以有1-3个y字符。 如果要用grep查找一个模式,如何表示这个模式,这一类字符串,而不是一个特定的字符串呢?从这两个简单的例子可以看出,要表示一个模式至少应该包含以下信息: 规定一些特殊语法表示字符类、数量限定符和位置关系,然后用这些特殊语法和普通字符一起表示一个模式,这就是正则表达式(Regular Expression)。例如email地址的正则表达式可以写成[a-zA-Z0-9.-]+@[a-zA-Z0-9.-]+.[a-zA-Z0-9_.-]+,IP地址的正则表达式可以写成[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}。下一节介绍正则表达式的语法,我们先看看正则表达式在grep中怎么用。例如有这样一个文本文件testfile: $ egrep ‘[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}’ testfile egrep相当于grep -E,表示采用Extended正则表达式语法。grep的正则表达式有Basic和Extended两种规范,它们之间的区别下一节再解释。另外还有fgrep命令,相当于grep -F,表示只搜索固定字符串而不搜索正则表达式模式,不会按正则表达式的语法解释后面的参数。 注意正则表达式参数用单引号括起来了,因为正则表达式中用到的很多特殊字符在Shell中也有特殊含义(例如),只有用单引号括起来才能保证这些字符原封不动地传给grep命令,而不会被Shell解释掉。 192.168.1.1符合上述模式,由三个.隔开的四段组成,每段都是1到3个数字,所以这一行被找出来了,可为什么1234.234.04.5678也被找出来了呢?因为grep找的是包含某一模式的行,这一行包含一个符合模式的字符串234.234.04.567。相反,123.4234.045.678这一行不包含符合模式的字符串,所以不会被找出来。 grep是一种查找过滤工具,正则表达式在grep中用来查找符合模式的字符串。其实正则表达式还有一个重要的应用是验证用户输入是否合法,例如用户通过网页表单提交自己的email地址,就需要用程序验证一下是不是合法的email地址,这个工作可以在网页的Javascript中做,也可以在网站后台的程序中做,例如PHP、Perl、Python、Ruby、Java或C,所有这些语言都支持正则表达式,可以说,目前不支持正则表达式的编程语言实在很少见。除了编程语言之外,很多UNIX命令和工具也都支持正则表达式,例如grep、vi、sed、awk、emacs等等。"正则表达式"就像"变量"一样,它是一个广泛的概念,而不是某一种工具或编程语言的特性。 我们知道C的变量和Shell脚本变量的定义和使用方法很不相同,表达能力也不相同,C的变量有各种类型,而Shell脚本变量都是字符串。同样道理,各种工具和编程语言所使用的正则表达式规范的语法并不相同,表达能力也各不相同,有的正则表达式规范引入很多扩展,能表达更复杂的模式,但各种正则表达式规范的基本概念都是相通的。本节介绍egrep(1)所使用的正则表达式,它大致上符合POSIX正则表达式规范,详见regex(7)(看这个man page对你的英文绝对是很好的锻炼)。希望读者仿照上一节的例子,一边学习语法,一边用egrep命令做实验。 (1) 数量限定符 例如有如下文本: a匹配0个或多个a,而第三行包含0个a,所以也包含了这一模式。单独用a这样的正则表达式做查找没什么意义,一般是把a作为正则表达式的一部分来用。 (2) 位置限定符 例如上一节我们用[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}查找IP地址,找到这两行 如果用^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}$查找,就可以把1234.234.04.5678这一行过滤掉了。 (3) 其它特殊字符 以上介绍的是grep正则表达式的Extended规范,Basic规范也有这些语法,只是字符?+{}|()应解释为普通字符,要表示上述特殊含义则需要加转义。如果用grep而不是egrep,并且不加-E参数,则应该遵照Basic规范来写正则表达式。 Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。 grep [options] pattern 主要参数:grep --help可查看 pattern正则表达式主要参数: itcast$ grep ‘test’ d* itcast $ grep ‘test’ aa bb cc itcast $ grep ‘[a-z]{5}’ aa itcast $ grep 'wesest.1′ aa 明确要求搜索子目录: 或忽略子目录 如果有很多输出时,您可以通过管道将其转到’less’上阅读: 下面还有一些有意思的命令行参数: 例如:grep “abc|xyz” testfile 表示过滤包含abc或xyz的行 还有些用于搜索的特殊符号:< 和 > 分别标注单词的开始与结尾。 由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只要你具有相应的权限。 1、find命令的一般形式为 2、find命令的参数; 3、find命令选项 -type 查找某一类型的文件,诸如: -xtype<文件类型> 文件类型和-type一样,区别在于查找有问题的相关文件。 另外,下面三个的区别: 4、使用exec或ok来执行shell命令 在有些操作系统中只允许-exec选项执行诸如ls或ls -l这样的命令。大多数用户使用这一选项是为了查找旧文件并删除它们。建议在真正执行rm命令删除文件之前,最好先用ls命令看一下,确认它们是所要删除的文件。 exec选项后面跟随着所要执行的命令或脚本,然后是一对儿{},一个空格和一个,最后是一个分号。为了使用exec选项,必须要同时使用print选项。如果验证一下find命令,会发现该命令只输出从当前路径起的相对路径及文件名。 例如:为了用ls -l命令列出所匹配到的文件,可以把ls -l命令放在find命令的-exec选项中 上面的例子中,find命令匹配到了当前目录下的所有普通文件,并在-exec选项中使用ls -l命令将它们列出。 在/logs目录中查找更改时间在5日以前的文件并删除它们: 记住:在shell中用任何方式删除文件之前,应当先查看相应的文件,一定要小心!当使用诸如mv或rm命令时,可以使用-exec选项的安全模式。它将在对每个匹配到的文件进行操作之前提示你。 在下面的例子中, find命令在当前目录中查找所有文件名以.conf结尾、更改时间在5日以上的文件,并删除它们,只不过在删除之前先给出提示。 任何形式的命令都可以在-exec选项中使用。 在下面的例子中我们使用grep命令。find命令首先匹配所有文件名为" passwd*"的文件,例如passwd、passwd.old、passwd.bak,然后执行grep命令看看在这些文件中是否存在一个itcast用户。 1、查找当前用户主目录下的所有文件: 2、让当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件; 3、为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径; 4、查找/var/logs目录中更改时间在7日以前的普通文件,并在删除之前询问它们; 5、为了查找系统中所有属于root组的文件; 6、find命令将删除当目录中访问时间在7日以来、含有数字后缀的admin.log文件。 7、为了查找当前文件系统中的所有目录并排序; (1) 使用name选项 想要在当前目录及子目录中查找所有的’ .txt’文件,可以用: 想要的当前目录及子目录中查找文件名以一个大写字母开头的文件,可以用: 想要在/etc目录中查找文件名以host开头的文件,可以用: 想要查找$HOME目录中的文件,可以用: 要想让系统高负荷运行,就从根目录开始查找所有的文件: 如果想在当前目录查找文件名以两个小写字母开头,跟着是两个数字,最后是.txt的文件,下面的命令就能够返回例如名为ax37.txt的文件: (2) 用perm选项 还有一种表达方法:在八进制数字前面要加一个横杠-,表示都匹配,如-007就相当于777,-006相当于666 -perm mode:文件许可正好符合mode (3) prune忽略某个目录 如果希望在/apps目录下查找文件,但不希望在/apps/bin目录下查找,可以用: 比如要在/home/itcast目录下查找不在dir1子目录之内的所有文件 避开多个文件夹 (5) 使用user和nouser选项 在/etc目录下查找文件属主为uucp的文件: 为了查找属主帐户已经被删除的文件,可以使用-nouser选项。这样就能够找到那些属主在/etc/passwd文件中没有有效帐户的文件。在使用-nouser选项时,不必给出用户名;find命令能够为你完成相应的工作。 (6) 使用group和nogroup选项 要查找没有有效所属用户组的所有文件,可以使用nogroup选项。下面的find命令从文件系统的根目录处查找这样的文件 (7) 按照更改时间或访问时间等查找文件 希望在系统根目录下查找更改时间在5日以内的文件,可以用: 为了在/var/adm目录下查找更改时间在3日以前的文件,可以用: (8) 查找比某个文件新或旧的文件 (9) 使用type选项 在当前目录下查找除目录以外的所有类型的文件,可以用: 在/etc目录下查找所有的符号链接文件,可以用 (10) 使用size选项 在/home/apache目录下查找文件长度恰好为100字节的文件: 在当前目录下查找长度超过10块的文件(一块等于512字节): (11) 使用depth选项 它将首先匹配所有的文件然后再进入子目录中查找。 (12) 使用mount选项 从当前目录开始查找位于本文件系统中文件名以XC结尾的文件: 练习:请找出你10天内所访问或修改过的.c和.cpp文件。 xargs是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。它把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理。通常情况下,xargs从管道或者stdin中读取数据,但是它也能够从文件的输出中读取数据。xargs的默认命令是echo,这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。 xargs是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令,下面是一些如何有效使用xargs 的实用例子。 $ xargs [-options] [command] xargs命令的作用,是将标准输入转为命令行参数。 $ echo “hello world” | xargs echo xargs的作用在于,大多数命令(比如rm、mkdir、ls)与管道一起使用时,都需要xargs将标准输入转为命令行参数。 xargs后面的命令默认是echo。 $ xargs # 等同于 大多数时候,xargs命令都是跟管道一起使用的。但是,它也可以单独使用。 $ xargs 再看一个例子。 上面的例子输入xargs find -name以后,命令行会等待用户输入所要搜索的文件。用户输入"*.txt",表示搜索当前目录下的所有 TXT 文件,然后按下Ctrl d,表示输入结束。这时就相当执行find -name *.txt。 默认情况下,xargs将换行符和空格作为分隔符,把标准输入分解成一个个命令行参数。 $ echo “one two three” | xargs mkdir -d参数可以更改分隔符。 上面的命令指定制表符t作为分隔符,所以atbtc就转换成了三个命令行参数。echo命令的-e参数表示解释转义字符。 使用xargs命令以后,由于存在转换参数过程,有时需要确认一下到底执行的是什么命令。 -p参数打印出要执行的命令,询问用户是否要执行。 上面的命令执行以后,会打印出最终要执行的命令,让用户确认。用户输入y以后(大小写皆可),才会真正执行。 -t参数则是打印出最终要执行的命令,然后直接执行,不需要用户确认。 由于xargs默认将空格作为分隔符,所以不太适合处理文件名,因为文件名可能包含空格。 find命令有一个特别的参数-print0,指定输出的文件列表以null分隔。然后,xargs命令的-0参数表示用null当作分隔符。 上面命令删除/path路径下的所有文件。由于分隔符是null,所以处理包含空格的文件名,也不会报错。 还有一个原因,使得xargs特别适合find命令。有些命令(比如rm)一旦参数过多会报错"参数列表过长",而无法执行,改用xargs就没有这个问题,因为它对每个参数执行一次命令。 上面命令找出所有 TXT 文件以后,对每个文件搜索一次是否包含字符串abc。 如果标准输入包含多行,-L参数指定多少行作为一个命令行参数。 上面命令同时将".txt"和.md两行作为命令行参数,传给find命令导致报错。 $ xargs -L 1 find -name 下面是另一个例子。 上面代码指定每行运行一次echo命令,所以echo命令执行了三次,输出了三行。 -L参数虽然解决了多行的问题,但是有时用户会在同一行输入多项。 $ xargs find -name -n参数指定每次将多少项,作为命令行参数。 下面是另一个例子。 如果xargs要将命令行参数传给多个命令,可以使用-I参数。 -I指定每一项命令行参数的替代字符串。 $ cat foo.txt | xargs -I file sh -c ‘echo file; mkdir file’ $ ls 上面代码中,foo.txt是一个三行的文本文件。我们希望对每一项命令行参数,执行两个命令(echo和mkdir),使用-I file表示file是命令行参数的替代字符串。执行命令时,具体的参数会替代掉echo file; mkdir file里面的两个file。 xargs默认只用一个进程执行命令。如果命令要执行多次,必须等上一次执行完,才能执行下一次。 –max-procs参数指定同时用多少个进程并行执行命令。–max-procs 2表示同时最多使用两个进程,–max-procs 0表示不限制进程数。 $ docker ps -q | xargs -n 1 --max-procs 0 docker kill 小小工匠 2016-09-17 15:17:01 58409 收藏 59 cut是一个选取命令,一般来说,选取信息通常是针对"行"来进行分析的,并不是整篇信息分析的。 cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。 如果不指定 File 参数,cut 命令将读取标准输入。 必须指定 -b、-c 或 -f 标志之一。 cut 默认以制表符为分隔符。 -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。 cut命令主要是接受三个定位方法: 提取第3,4,5,9的字节: cut -b 3-5,9 注意:cut命令如果使用-b选项,执行时会先把-b后面所有的定位进行从小到大排序,然后再提取,不能颠倒顺序。 对于中文提取,-c 会以字符为单位,输出正常;-b以字节(8位二进制)计算。 对于非固定格式信息,需要域。之前需要先设置间隔符,再提取第几个域。 注意:如果遇到空格和制表符时,怎么辨认? cut -d 用什么符号表示制表符或空格? 处理多空格… sed意为流编辑器(Stream Editor),在Shell脚本和Makefile中作为过滤器使用非常普遍,也就是把前一个程序的输出引入sed的输入,经过一系列编辑命令转换为另一种格式输出。sed和vi都源于早期UNIX的ed工具,所以很多sed命令和vi的末行命令是相同的。 sed [options] ‘command’ file(s) -e
[root@xuexi ~]# while read line
1.强烈建议,不要在管道后面使用while read line。正如上面第1个示例中 cat test1|while read line。因为管道会开启子shell,使得while中的命令都在子shell中执行,而且,cat test1会一次性将test1文件所有数据装入内存,如果test1文件足够大,会直接占用巨量内存。而第二个示例使用输入重定向的方式则每次只占用一行数据的内存,而且是在当前shell环境下执行的,while内的变量赋值、数组赋值在退出while后仍然有效。
2.不要使用示例3,因为测试了就知道为什么不用,它会在每次循环的时候都重新打开test1文件,使得每次都从头开始读数据,而不是每次从上一次标记的地方继续读数据。输入输出echo
-e 解析转义字符
-n 不回车换行。默认情况echo回显的内容后面跟一个回车换行。
echo -e “hellonn”
echo “hello”
echo -n “hello”管道 |
cat myfile | more
ls -l | grep “myfile”
df -k | awk ‘{print $1}’ | grep -v “文件系统”
df -k 查看磁盘空间,找到第一列,去除"文件系统",并输出Tee 输出内容到文件
df -k | awk ‘{print $1}’ | grep -v “文件系统” | tee -a a.txt文件重定向
cmd >> file 追加
cmd > file 2>&1 标准出错也重定向到1所指向的file里
cmd >> file 2>&1
cmd < file1 > file2 输入输出都定向到文件里
cmd < &fd 把文件描述符fd作为标准输入
cmd > &fd 把文件描述符fd作为标准输出
cmd < &- 关闭标准输入函数
#! /bin/sh
foo(){ echo “Function foo is called”;}
echo “-=start=-”
foo
echo “-=end=-”
#! /bin/sh
is_directory()
{
DIR_NAME=$1
if [ ! -d $DIR_NAME ]; then
return 1
else
return 0
fi
}
for DIR in "$@"; do
if is_directory "$DIR"
then :
else
echo "$DIR doesn't exist. Creating it now..."
mkdir $DIR > /dev/null 2>&1
if [ $? -ne 0 ]; then
echo "Cannot create directory $DIR"
exit 1
fi
fi
done
判断变量是否为空
不能忽略全空格的时候,用[ “$NAME” != “” ]。
para1=
if [ ! -n “$para1” ]; then
echo “IS NULL”
else
echo “NOT NULL”
fi
【输出结果】“IS NULL”
para1=
if [ ! $para1 ]; then
echo “IS NULL”
else
echo “NOT NULL”
fi
【输出结果】“IS NULL”
#!/bin/sh
dmin=
if test -z “$dmin”
then
echo “dmin is not set!”
else
echo “dmin is set !”
fi
【输出结果】“dmin is not set!”
#!/bin/sh
dmin=
if [ “$dmin” = “” ]
then
echo “dmin is not set!”
else
echo “dmin is set !”
fi&& 和 || 的单独实用
||:用来执行条件不成立后的执行命令
(cd ${LICHEE_BR_DIR} && [ -x ${build_script} ] && ./${build_script})
[ $? -ne 0 ] && mk_error “build buildroot Failed” && return 1shell脚本返回值
shell 返回码 "保留的"退出码
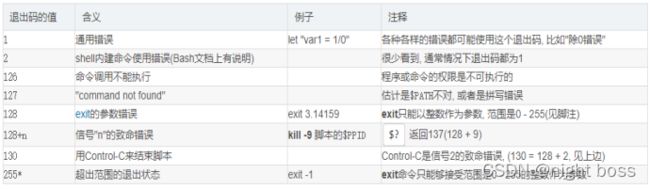
shell返回码与函数返回码、命令返回码的区别
(2) 函数返回码,标识一个函数的执行结果状态,用"return 返回码"表示。
(3) 命令返回码,标识一个命令的执行结果状态,在命令执行后,紧跟着获取返回码,用"$?"获取。数组
数组定义
declare定义
declare -a names
names[0]=tom
names[1]=jack
在定义数组的同时,可以同时赋值,用()表示,各元素之间用空格隔开
#定义的同时直接赋值
declare -a names=(tom jack)
names[2]=sue直接定义
#使用()直接数组
Days=()#声明一个空数组
days1=(one two three four five)#字符串不加引号也可以
days2=([0]=‘one’ [1]=‘two’ [2]=‘three’ [3]=‘four’)
days3=([0]=‘one’ [2]=‘three’)带下标定义
header[0]=‘user’
header[1]=‘pid’
header[2]=’%CPU’
header[3]=’%MEM’从文件读取数组
数组操作
赋值
declare -a names
names[0]=tom取值
days=(one two three four five)
echo ${days[0]}
echo ${days[2]}
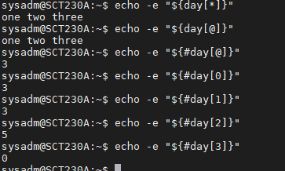
${数组名[@]}得到是以空格隔开的元素,${数组名[]}得到的是一整个字符串。用在数组遍历中时,如果不加"",他们的效果是一样的,如果加了"",${数组名[*]}会是一个元素的字符串。

示例:
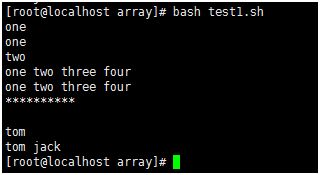
#!/bin/bash
#数组取值
days=(one two three four)
echo ${days}
echo ${days[0]}
echo ${days[1]}
echo ${days[@]}
echo ${days[*]}
echo “**********”
names=()
names[1]=tom
names[2]=jack
echo ${names}
echo ${names[1]}
echo ${names[@]}
长度
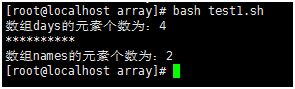
#!/bin/bash
#数组个数
echo “数组days的元素个数为:${#days[@]}”
echo “*********"
names=()
names[1]=tom
names[2]=jack
echo "数组names的元素个数为:${#names[]}”
注意:如果某个元素是字符串,可以通过制定索引的方式获得该元素的长度。
遍历
(1)${数组名[@]}、${数组名[*]}均可以获得所有元素(不管是元素列表,还是一整个字符串),使用for循环遍历即可
(2)带数组下标的遍历,当需要使用到数组的下标时,可以使用${!数组名[@]}
(3)while循环:根据元素的个数遍历,但对于稀疏数组,可能会丢失数据
#!/bin/bash
#数组遍历
#for循环遍历
for day in ${days[]} #或${days[@]},但是如果加了"",就只能用"${days[@]}"
do
echo $day
done
echo "**************"
for i in ${!days[@]}
do
echo ${days[$i]}
done
echo “***************”
names=() #数组names是一个稀疏数组
names[1]=tom
names[2]=jack
i=0
while [ $i -lt ${#names[*]} ]
do
echo ${names[$i]}
let i++
done

删除
unset 数组名 #删除整个数组连接
days=(one two three four)
names=(tom jack)
days=(${days[@]} ${names[@]})Shell脚本调试方法
-n 读一遍脚本中的命令但不执行,用于检查脚本中的语法错误。
-v 一边执行脚本,一边将执行过的脚本命令打印到标准错误输出。
-x 提供跟踪执行信息,将执行的每一条命令和结果依次打印出来。在命令行提供参数
$ sh -x ./script.sh在脚本开头提供参数
#! /bin/sh -x在脚本中用set命令启用或禁用参数
#! /bin/sh
if [ -z “$1” ]; then
set -x
echo “ERROR: Insufficient Args.”
exit 1
set +x
fi语法
功能说明
参数说明
-a 标示已修改的变量,以供输出至环境变量
-b 使被中止的后台程序立刻回报执行状态
-d Shell预设会用杂凑表记忆使用过的指令,以加速指令的执行。使用-d参数可取消
-e 若指令传回值不等于0,则立即退出shell
-f 取消使用通配符
-h 自动记录函数的所在位置
-k 指令所给的参数都会被视为此指令的环境变量
-l 记录for循环的变量名称
-m 使用监视模式
-n 测试模式,只读取指令,而不实际执行
-p 启动优先顺序模式
-P 启动-P参数后,执行指令时,会以实际的文件或目录来取代符号连接
-t 执行完随后的指令,即退出shell
-u 当执行时使用到未定义过的变量,则显示错误信息
-v 显示shell所读取的输入值
-H shell 可利用"!"加<指令编号>的方式来执行 history 中记录的指令
-x 执行指令后,会先显示该指令及所下的参数
+<参数> 取消某个set曾启动的参数。与-<参数>相反
-o option 特殊属性有很多,大部分与上面的可选参数功能相同,这里就不列了重点参数
set -x 会在执行每一行 shell 脚本时,把执行的内容输出来。它可以让你看到当前执行的情况,里面涉及的变量也会被替换成实际的值。
set -e 会在执行出错时结束程序,就像其他语言中的"抛出异常"一样。(准确说,不是所有出错的时候都会结束程序,见下面的注)
1.一个 pipeline 的非结尾部分,比如error | ok
2.一个组合语句的非结尾部分,比如ok && error || other
3.一连串语句的非结尾部分,比如error; ok
4.位于判断语句内,包括test、if、while等等。其他用法
$ cat set-it.sh
#!/bin/bash
set first second third
echo $3 $2 $1
third second first
$ set
BASH_VERSION=‘4.2.24(1)-release’
COLORS=/etc/DIR_COLORS
MAIL=/var/spool/mail/username
…正则表达式及常用命令
字符类(Character Class):如上例的x和y,它们在模式中表示一个字符,但是取值范围是一类字符中的任意一个。
数量限定符(Quantifier): 邮件地址的每一部分可以有一个或多个x字符,IP地址的每一部分可以有1-3个y字符。
各种字符类以及普通字符之间的位置关系:例如邮件地址分三部分,用普通字符@和.隔开,IP地址分四部分,用.隔开,每一部分都可以用字符类和数量限定符描述。为了表示位置关系,还有位置限定符(Anchor)的概念,将在下面介绍。
192.168.1.1
1234.234.04.5678
123.4234.045.678
abcde
192.168.1.1
1234.234.04.5678
基本语法
字符类
再次注意grep找的是包含某一模式的行,而不是完全匹配某一模式的行。
aaabc
aad
efg
查找a这个模式的结果。会发现,三行都被找了出来。
$ egrep 'a’ testfile
aaabc
aad
efg
位置限定符可以帮助grep更准确地查找。
192.168.1.1
1234.234.04.5678Basic正则和Extended正则区别
grep
作用
grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。格式及主要参数
-a --text # 不要忽略二进制数据。
-A <显示行数> --after-context=<显示行数> # 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b --byte-offset # 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-B<显示行数> --before-context=<显示行数> # 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count # 计算符合范本样式的行数。
-C<显示行数> --context=<显示行数>或-<显示行数> # 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> --directories=<动作> # 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> # 指定字符串作为查找文件内容的范本样式。
-E --extended-regexp # 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> --file=<规则文件> # 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F --fixed-regexp # 将范本样式视为固定字符串的列表。
-G --basic-regexp # 将范本样式视为普通的表示法来使用。
-h --no-filename # 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H --with-filename # 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i --ignore-case # 忽略字符大小写的差别。
-l --file-with-matches # 列出文件内容符合指定的范本样式的文件名称。
-L --files-without-match # 列出文件内容不符合指定的范本样式的文件名称。
-n --line-number # 在显示符合范本样式的那一列之前,标示出该列的编号。
-q --quiet或–silent # 不显示任何信息。
-R/-r --recursive # 此参数的效果和指定"-d recurse"参数相同。
-s --no-messages # 不显示错误信息。
-v --revert-match # 反转查找。
-V --version # 显示版本信息。
-w --word-regexp # 只显示全字符合的列。
-x --line-regexp # 只显示全列符合的列。
-y # 此参数效果跟"-i"相同。
-o # 只输出文件中匹配到的部分。
–color=auto :可以将找到的关键词部分加上颜色的显示。
^ # 锚定行的开始 如:’^grep’匹配所有以grep开头的行。
$ # 锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. # 匹配一个非换行符的字符 如:'gr.p’匹配gr后接一个任意字符,然后是p。
* # 匹配零个或多个先前字符 如:'grep’匹配所有一个或多个空格后紧跟grep的行。
.* # 一起用代表任意字符。 [] # 匹配一个指定范围内的字符,如’[Gg]rep’匹配Grep和grep。
[^] # 匹配一个不在指定范围内的字符,如:’[^A-FH-Z]rep’匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
(…) # 标记匹配字符,如’(love)’,love被标记为1。
< # 锚定单词的开始,如:’
x{m} # 重复字符x,m次,如:'0{5}'匹配包含5个o的行。
x{m,} # 重复字符x,至少m次,如:'o{5,}'匹配至少有5个o的行。x{m,n} # 重复字符x,至少m次,不多于n次,如:'o{5,10}'匹配5–10个o的行。
w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:'Gw
W # w的反置形式,匹配一个或多个非单词字符,如点号句号等。
b # 单词锁定符,如: 'bgrepb’只匹配grep。grep命令使用简单实例
显示所有以d开头的文件中包含 test的行
显示在aa,bb,cc文件中匹配test的行。
显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.),这些字符后面紧跟着 另外一个es(1),找到就显示该行。如果用egrep或grep -E,就不用""号进行转义,直接写成’w(es)t.*1′就可以了。grep命令使用复杂实例
grep -r
grep -d skip
itcast$ grep magic /usr/src/Linux/Documentation/* | less
这样,您就可以更方便地阅读。
有一点要注意,您必需提供一个文件过滤方式(搜索全部文件的话用 *)。如果您忘了,'grep’会一直等着,直到该程序被中断。如果您遇到了这样的情况,按 ,然后再试。
grep -i pattern files :不区分大小写地搜索。默认情况区分大小写,
grep -l pattern files :只列出匹配的文件名,
grep -L pattern files :列出不匹配的文件名,
grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),
grep -C number pattern files :匹配的上下文分别显示[number]行,
grep pattern1 | pattern2 files :显示匹配 pattern1 或 pattern2 的行,
grep pattern1 files | grep pattern2 :显示既匹配 pattern1 又匹配 pattern2 的行。
grep -n pattern files 即可显示行号信息
grep -c pattern files 即可查找总行数
例如:
grep man * 会匹配 ‘Batman’、‘manic’、‘man’等,
grep ‘
‘^’: 指匹配的字符串在行首,
‘$’: 指匹配的字符串在行 尾,find
在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间(这里是指30G字节以上的文件系统)。find 命令格式
find pathname -options [-print -exec -ok …]
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录,递归查找。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为’command’ {} \;,注意{}内部无空格,和\;之间含有一个空格分隔符。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
-name 按照文件名查找文件。
-perm 按照文件权限来查找文件。
-prune 使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用-depth选项,那么-prune将被find命令忽略。
-user 按照文件属主来查找文件。
-group 按照文件所属的组来查找文件。
-mtime -n +n 按照文件的更改时间来查找文件,-n表示文件更改时间距现在n天以内,+n表示文件更改时间距现在n天以前。find命令还有-atime和-ctime 选项,但它们都和-m time选项。
-nogroup 查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser 查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2 查找更改时间比文件file1新但比文件file2旧的文件。
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
-size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计。
-depth 在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
-maxdepth 查找目录深度,-maxdepth 1 只查找当前目录
-fstype 查找位于某一类型文件系统中的文件,这些文件系统类型通常可以在配置文件/etc/fstab中找到,该配置文件中包含了本系统中有关文件系统的信息。
-mount 在查找文件时不跨越文件系统mount点。
-follow 如果find命令遇到符号链接文件,就跟踪至链接所指向的文件。
-amin n 查找系统中最后N分钟访问的文件
-atime n 查找系统中最后n24小时访问的文件
-cmin n 查找系统中最后N分钟被改变文件状态的文件
-ctime n 查找系统中最后n24小时被改变文件状态的文件
-mmin n 查找系统中最后N分钟被改变文件数据的文件
-mtime n 查找系统中最后n*24小时被改变文件数据的文件
-amin<分钟> 查找在指定时间曾被存取过的文件或目录,单位以分钟计算。
-anewer<参考文件或目录> 查找其存取时间较指定文件或目录的存取时间更接近现在的文件或目录。
-atime<24小时数> 查找在指定时间曾被存取过的文件或目录,单位以24小时计算。
-cmin<分钟> 查找在指定时间之时被更改的文件或目录。
-cnewer<参考文件或目录> 查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录。
-ctime<24小时数> 查找在指定时间之时被更改的文件或目录,单位以24小时计算。
-daystart 从本日开始计算时间。
-depth 从指定目录下最深层的子目录开始查找。
-expty 寻找文件大小为0 Byte的文件,或目录下没有任何子目录或文件的空目录。
-exec<执行指令> 假设find指令的回传值为True,就执行该指令。
-false 将find指令的回传值皆设为False。
-fls<列表文件> 此参数的效果和指定"-ls"参数类似,但会把结果保存为指定的列表文件。
-follow 排除符号连接。
-fprint<列表文件> 此参数的效果和指定"-print"参数类似,但会把结果保存成指定的列表文件。
-fprint0<列表文件> 此参数的效果和指定"-print0"参数类似,但会把结果保存成指定的列表文件。
-fprintf<列表文件><输出格式> 此参数的效果和指定"-printf"参数类似,但会把结果保存成指定的列表文件。
-fstype<文件系统类型> 只寻找该文件系统类型下的文件或目录。
-gid<群组识别码> 查找符合指定之群组识别码的文件或目录。
-group<群组名称> 查找符合指定之群组名称的文件或目录。
-help或–help 在线帮助。
-ilname<范本样式> 此参数的效果和指定"-lname"参数类似,但忽略字符大小写的差别。
-iname<范本样式> 此参数的效果和指定"-name"参数类似,但忽略字符大小写的差别。
-inum
-ipath<范本样式> 此参数的效果和指定"-ipath"参数类似,但忽略字符大小写的差别。
-iregex<范本样式> 此参数的效果和指定"-regexe"参数类似,但忽略字符大小写的差别。
-links<连接数目> 查找符合指定的硬连接数目的文件或目录。
-iname<范本样式> 指定字符串作为寻找符号连接的范本样式。
-ls 假设find指令的回传值为True,就将文件或目录名称列出到标准输出。
-maxdepth<目录层级> 设置最大目录层级。
-mindepth<目录层级> 设置最小目录层级。
-mmin<分钟> 查找在指定时间曾被更改过的文件或目录,单位以分钟计算。
-mount 此参数的效果和指定"-xdev"相同。
-mtime<24小时数> 查找在指定时间曾被更改过的文件或目录,单位以24小时计算。
-name<范本样式> 指定字符串作为寻找文件或目录的范本样式。
-newer<参考文件或目录> 查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录。
-nogroup 找出不属于本地主机群组识别码的文件或目录。
-noleaf 不去考虑目录至少需拥有两个硬连接存在。
-nouser 找出不属于本地主机用户识别码的文件或目录。
-ok<执行指令> 此参数的效果和指定"-exec"参数类似,但在执行指令之前会先询问用户,若回答"y"或"Y",则放弃执行指令。
-path<范本样式> 指定字符串作为寻找目录的范本样式。
-perm<权限数值> 查找符合指定的权限数值的文件或目录。
-print 假设find指令的回传值为True,就将文件或目录名称列出到标准输出。格式为每列一个名称,每个名称之前皆有"./"字符串。
-print0 假设find指令的回传值为True,就将文件或目录名称列出到标准输出。格式为全部的名称皆在同一行。
-printf<输出格式> 假设find指令的回传值为True,就将文件或目录名称列出到标准输出。格式可以自行指定。
-prune 不寻找字符串作为寻找文件或目录的范本样式。
-regex<范本样式> 指定字符串作为寻找文件或目录的范本样式。
-size<文件大小> 查找符合指定的文件大小的文件。
-true 将find指令的回传值皆设为True。
-uid<用户识别码> 查找符合指定的用户识别码的文件或目录。
-used<日数> 查找文件或目录被更改之后在指定时间曾被存取过的文件或目录,单位以日计算。
-user<拥有者名称> 查找符合指定的拥有者名称的文件或目录。
-version或–version 显示版本信息。
-xdev 将范围局限在先行的文件系统中。
使用find时,只要把想要的操作写在一个文件里,就可以用exec来配合find查找,很方便的。
# find . -type f -exec ls -l {} \;
$ find logs -type f -mtime +5 -exec rm {} \;
$ find . -name “*.conf” -mtime +5 -ok rm {} \;
< rm … ./conf/httpd.conf > ? n
按y键删除文件,按n键不删除。
# find /etc -name “passwd*” -exec grep “itcast” {} \;
itcast:\x:1000:1000::/home/itcast:/bin/bashfind命令的例子
下面两种方法都可以使用
$ find $HOME -print
$ find ~ -print
$ find . -type f -perm 644 -exec ls -l {} \;
$ find / -type f -size 0 -exec ls -l {} \;
$ find /var/logs -type f -mtime +7 -ok rm {} \;
$find . -group root -exec ls -l {} \;
该命令只检查三位数字,所以相应文件的后缀不要超过999。先建几个admin.log*的文件 ,才能使用下面这个命令
$ find . -name “admin.log[0-9][0-9][0-9]” -atime -7 -ok rm {} \;
$ find . -type d | sortfind 命令的参数
文件名选项是find命令最常用的选项,要么单独使用该选项,要么和其他选项一起使用。可以使用某种文件名模式来匹配文件,记住要用引号将文件名模式引起来。不管当前路径是什么,如果想要在自己的根目录HOME中查找文件名符合∗.txt的文件,使用’~'作为 ‘pathname’ 的参数,波浪号代表了你的HOME目录。
$ find ~ -name “*.txt” -print
$ find . -name ".txt" -print
$ find . -name “[A-Z]*” -print
$ find /etc -name “host*” -print
$ find ~ -name “*” -print 或find . --print
$ find / -name “*” -print
$find . -name “[a-z][a-z][0-9][0-9].txt” -print
按照文件权限模式用-perm选项,按文件权限模式来查找文件的话。最好使用八进制的权限表示法。如在当前目录下查找文件权限位为755的文件,即文件属主可以读、写、执行,其他用户可以读、执行的文件,可以用:
$ find . -perm 755 -print
# ls -l
# find . -perm 006
# find . -perm -006
-perm +mode:文件许可部分符合mode
-perm -mode: 文件许可完全符合mode
如果在查找文件时希望忽略某个目录,因为你知道那个目录中没有你所要查找的文件,那么可以使用-prune选项来指出需要忽略的目录。在使用-prune选项时要当心,因为如果你同时使用了-depth选项,那么-prune选项就会被find命令忽略。
$ find /apps -path “/apps/bin” -prune -o -print
find /home/itcast -path “/home/itcast/dir1” -prune -o -print
find /usr/sam ( -path /usr/sam/dir1 -o -path /usr/sam/file1 ) -prune -o -print
注意()前后的空格。
按文件属主查找文件,如在$HOME目录中查找文件属主为itcast的文件,可以用:
$ find ~ -user itcast -print
$ find /etc -user uucp -print
例如,希望在/home目录下查找所有的这类文件,可以用:
$ find /home -nouser -print
就像user和nouser选项一样,针对文件所属于的用户组, find命令也具有同样的选项,为了在/apps目录下查找属于itcast用户组的文件,可以用:
$ find /apps -group itcast -print
$ find / -nogroup -print
如果希望按照更改时间来查找文件,可以使用mtime,atime或ctime选项。如果系统突然没有可用空间了,很有可能某一个文件的长度在此期间增长迅速,这时就可以用mtime选项来查找这样的文件。用减号-来限定更改时间在距今n日以内的文件,而用加号+来限定更改时间在距今n日以前的文件。
$ find / -mtime -5 -print
$ find /var/adm -mtime +3 -print
如果希望查找更改时间比某个文件新但比另一个文件旧的所有文件,可以使用-newer选项。它的一般形式为:
newest_file_name ! oldest_file_name
其中,!是逻辑非符号。
在/etc目录下查找所有的目录,可以用:
$ find /etc -type d -print
$ find . ! -type d -print
$ find /etc -type l -print
可以按照文件长度来查找文件,这里所指的文件长度既可以用块(block)来计量,也可以用字节来计量。以字节计量文件长度的表达形式为N c;以块计量文件长度只用数字表示即可。在按照文件长度查找文件时,一般使用这种以字节表示的文件长度,在查看文件系统的大小,因为这时使用块来计量更容易转换。 在当前目录下查找文件长度大于1 M字节的文件:
$ find . -size +1000000c -print
$ find /home/apache -size 100c -print
$ find . -size +10 -print
在使用find命令时,可能希望先匹配所有的文件,再在子目录中查找。使用depth选项就可以使find命令这样做。这样做的一个原因就是,当在使用find命令向磁带上备份文件系统时,希望首先备份所有的文件,其次再备份子目录中的文件。在下面的例子中, find命令从文件系统的根目录开始,查找一个名为CON.FILE的文件。
$ find / -name “CON.FILE” -depth -print
在当前的文件系统中查找文件(不进入其他文件系统),可以使用find命令的mount选项。
$ find . -name “*.XC” -mount -printxargs
xargs命令的格式
真正执行的命令,紧跟在xargs后面,接受xargs传来的参数。xargs 命令的作用
hello world
上面的代码将管道左侧的标准输入,转为命令行参数hello world,传给第二个echo命令。
$ echo “one two three” | xargs mkdir
上面的代码等同于mkdir one two three。如果不加xargs就会报错,提示mkdir缺少操作参数。xargs 的单独使用
$ xargs echo
输入xargs按下回车以后,命令行就会等待用户输入,作为标准输入。你可以输入任意内容,然后按下Ctrl d,表示输入结束,这时echo命令就会把前面的输入打印出来。
hello (Ctrl + d)
hello
$ xargs find -name
“*.txt”
./foo.txt
./hello.txt-d 参数与分隔符
上面代码中,mkdir会新建三个子目录,因为xargs将one two three分解成三个命令行参数,执行mkdir one two three。
$ echo -e “atbtc” | xargs -d “t” echo
a b c-p 参数,-t 参数
$ echo ‘one two three’ | xargs -p touch
touch one two three ?..
$ echo ‘one two three’ | xargs -t rm
rm one two three-0 参数与 find 命令
$ find /path -type f -print0 | xargs -0 rm
$ find . -name “*.txt” | xargs grep “abc”-L 参数
$ xargs find -name
“.txt"
".md”
find: paths must precede expression: `*.md’
使用-L参数,指定每行作为一个命令行参数,就不会报错。
“.txt"
./foo.txt
./hello.txt
".md”
./README.md
上面命令指定了每一行(-L 1)作为命令行参数,分别运行一次命令(find -name)。
$ echo -e “a\nb\nc” | xargs -L 1 echo
a
b
c-n 参数
“.txt" ".md”
find: paths must precede expression: `*.md’
上面的命令将同一行的两项作为命令行参数,导致报错。
$ xargs -n 1 find -name
上面命令指定将每一项(-n 1)标准输入作为命令行参数,分别执行一次命令(find -name)。
$ echo {0…9} | xargs -n 2 echo
0 1
2 3
4 5
6 7
8 9
上面命令指定,每两个参数运行一次echo命令。所以,10个阿拉伯数字运行了五次echo命令,输出了五行。-I 参数
$ cat foo.txt
one
two
three
one
two
three
one two three–max-procs 参数
上面命令表示,同时关闭尽可能多的 Docker 容器,这样运行速度会快很多。cut
语法
参数说明
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除。
第一,字节(bytes),用选项-b
第二,字符(characters),用选项-c
第三,域(fields),用选项-f举例
-3 表示从第一字节到第三字节;
3.表示从第三字节到结尾。
当遇到多字节字符时,使用-n选项,不会将多字节字符拆开。cut -nb 1,2,3
cut -d : -f 1
-d设置间隔符为:,-f 1 为提取第一个域。
先检查这段空格是由空格组成还是制表符组成:
cat tab_space.txt
sed -n l tab_space.txt
如果是制表位(TAB),就会显示t, 如果是空格,就会原样显示。(sed中n后面的l是小写的L)
cut -d 默认间隔为制表符,可以省略。若设置空格为间隔符,则 cut -d ’ ’ -f 4
(两个单引号中要有一个空格)
而且只能在-d 后面设置一个空格,不允许有多个空格。cut允许的间隔符是一个字符。cut的缺陷和不足
如果文件里面的某些域是由若干个空格来间隔的,那么用cut就有点麻烦了,因为cut只擅长处理"以一个字符间隔"的文本内容。sed
命令格式
sed [options] -f scriptfile file(s)选项