12-高并发-多级缓存
缓存技术是一个老生常谈的话题,但是,它也是解决性能问题的利器,一把瑞士军刀。
如缓存算法、热点数据与更新缓存、更新缓存与原子性、缓存崩溃与快速恢复等各种问题。
而这些问题中,有些问题又是与场景相关,因此,如何合理应用缓存来解决问题也是一个选择题。
本文所有内容都跟读服务缓存相关,不会涉及写服务数据的缓存。
本文不考虑内容型应用前置的CDN架构,也不会涉及缓存数据结构优化、缓存空间利用率跟业务数据相关的细节问题,主要从架构和提升命中率等层面来探讨缓存方案。
多级缓存介绍
所谓多级缓存,是指在整个系统架构的不同系统层级进行数据缓存,以提升访问效率,这也是应用最广的方案之一。我们应用的整体架构和流程如下图所示。
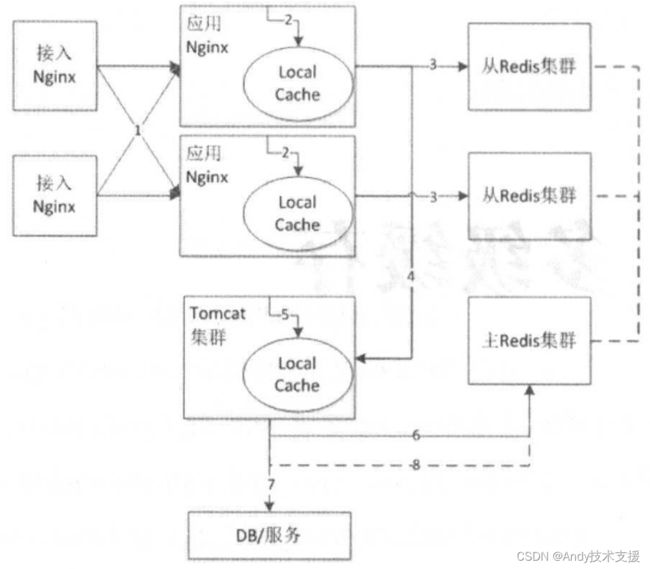
- 接入Nginx将请求负载均衡到应用Nginx,此处常用的负载均衡算法是轮询或者一致性哈希。轮询可以使服务器的请求更加均衡,而一致性哈希可以提升应用Nginx的缓存命中率,后续在负载均衡和缓存算法部分我们再详细介绍。
- 应用Nginx读取本地缓存(本地缓存可以使用Lua Shared Dict、Nginx Proxy Cache(磁盘/内存)、Local Redis实现)。如果本地缓存命中,则直接返回,使用应用Nginx本地缓存可以提升整体的吞吐量,降低后端压力,尤其应对热点问题非常有效。为什么要使用Nginx本地缓存我们将在热点数据与缓存失效部分详细介绍。
- 如果Nginx本地缓存没命中,则会读取相应的分布式缓存(如Redis缓存,还可以考虑使用主从架构来提升性能和吞吐量),如果分布式缓存命中,则直接返回相应数据(并回写到Nginx本地缓存)。
- 如果分布式缓存也没有命中,则会回源到Tomcat集群,在回源到Tomcat集群时,也可以使用轮询和一致性哈希作为负载均衡算法。
- 在Tomcat应用中,首先读取本地堆缓存。如果有,则直接返回(并会写到主Redis集群),为什么要加一层本地堆缓存将在缓存崩溃与快速修复部分详细介绍。
- 作为可选部分,如果步骤4没有命中,则可以再尝试一次读主Redis集群操作,目的是防止当从集群有问题时的流量冲击。
- 如果所有缓存都没有命中,则只能查询DB或相关服务获取相关数据并返回。
- 步骤7返回的数据异步写到主Redis集群,此处可能有多个Tomcat实例同时写主Redis集群,会造成数据错乱,如何解决该问题将在更新缓存与原子性部分详细介绍。
整体分了三部分缓存:应用Nginx本地缓存、分布式缓存、Tomcat堆缓存。每一层缓存都用来解决相关问题,如应用Nginx本地缓存用来解决热点缓存问题,分布式缓存用来减少访问回源率,Tomcat堆缓存用于防止相关缓存失效/崩溃之后的冲击。
如何缓存数据
过期与不过期
对于缓存的数据我们可以考虑不过期缓存和带过期时间缓存,什么场景应该选择哪种模式需要根据业务和数据量等因素来决定。
不过期缓存场景一般思路如下图所示。
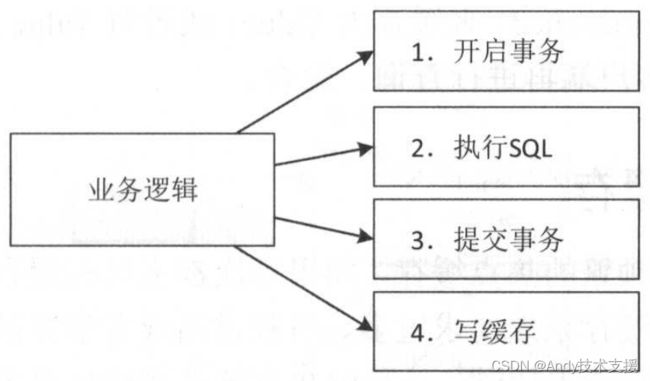
使用Cache-Aside模式,首先写数据库,如果成功,则写缓存。
这种场景下存在事务成功、缓存写失败但无法回滚事务的情况。另外,不要把写缓存放在事务中,尤其写分布式缓存,因为网络抖动可能导致写缓存响应时间很慢,引起数据库事务阻塞。
如果对缓存数据一致性要求不是那么高,数据量也不是很大,则可以考虑定期全量同步缓存。
为更好解决以上多个事务的问题,可以考虑使用“队列术”中所使用的基于Canal实现缓存同步。
对于长尾访问的数据、大多数数据访问频率都很高的场景,或者是缓存空间足够,都可以考虑不过期缓存,比如用户、分类、商品、价格、订单等。当缓存满了,可以考虑用LRU机制驱逐老的缓存数据。
过期缓存机制,如采用懒加载,一般用于缓存其他系统的数据(无法订阅变更消息,或者成本很高)、缓存空间有限、低频热点缓存等场景。
常见步骤是首先读取缓存,如果不命中,则查询数据,然后异步写入缓存并设置过期时间,下次读取将命中缓存。
热点数据经常使用过期缓存,即在应用系统上缓存比较短的时间。这种缓存可能存在一段时间的数据不一致情况,需要根据场景来决定如何设置过期时间。如库存数据可以在前端应用上缓存几秒钟,短时间的不一致是可以忍受的。
维度化缓存与增量缓存
对于电商系统,一个商品可能拆成如基础属性、图片列表、上下架、规格参数、商品介绍等。
如果商品变更了,要把这些数据都更新一遍,更新成本很高,包括接口调用量和带宽。
因此,最好将数据进行维度化并增量更新(只更新变的部分)。
尤其如上下架这种只是一个状态变更但每天频繁调用的数据,维度化后能减少服务很大压力。
大Value缓存
要警惕缓存中的大Value,尤其是使用Redis时。
遇到这种情况时可以考虑使用多线程实现的缓存,如Memcached,来缓存大Value;或者对Value进行压缩;或者将Value拆分为多个小Value,客户端再进行查询、聚合。
热点缓存
对于那些访问非常频繁的热点缓存,如果每次都去远程缓存系统中获取,可能会因为访问量太大导致远程缓存系统请求过多、负载过高或者带宽过高等问题,最终可能导致缓存响应慢,使客户端请求超时。
一种解决方案是通过挂更多的从缓存,客户端通过负载均衡机制读取从缓存系统数据。
不过也可以在客户端所在的应用/代理层本地存储一份,从而避免访问远程缓存,即使像库存这种数据,在有些应用系统中也可以进行几秒钟的本地缓存,从而降低远程系统的压力。
分布式缓存与应用负载均衡
缓存分布式
此处说的分布式缓存一般采用分片实现,即将数据分散到多个实例或多台服务器。算法一般采用取模和一致性哈希。要采用如之前所说的不过期缓存机制,可以考虑取模机制,扩容时一般是新建一个集群。
而对于可以丢失的缓存数据,可以考虑一致性哈希,即使其中一个实例出问题只是丢一小部分,对于分片实现可以考虑客户端实现,或者使用如Twemproxy中间件进行代理(分片对客户端是透明的)。如果使用Redis,则可以考虑使用redis-cluster分布式集群方案。
应用负载均衡
应用负载均衡一般采用轮询和一致性哈希,一致性哈希可以根据应用请求的URL或者URL参数将相同的请求转发到同一个节点。而轮询是将请求均匀地转发到每个服务器,如下图所示。
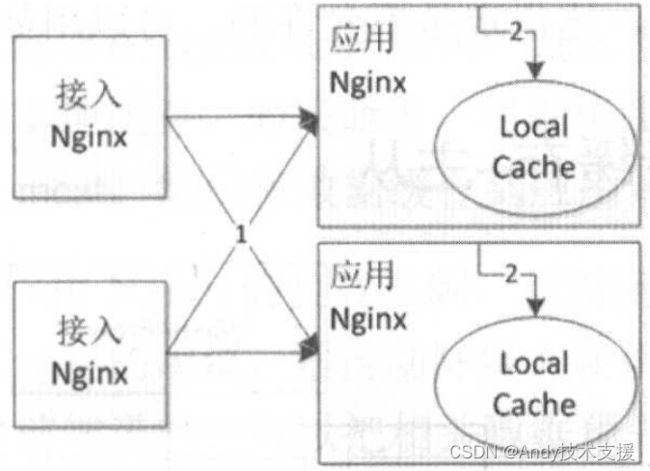
轮询的优点是,到应用Nginx的请求更加均匀,使得每个服务器的负载基本均衡。轮询的缺点是,随着应用Nginx服务器的增加,缓存的命中率会下降,比如,原来10台服务器命中率为90%,再加10台服务器将可能降低到45%。而这种方式不会因为热点问题导致其中某一台服务器负载过重。
一致性哈希的优点是,相同请求都会转发到同一台服务器,命中率不会因为增加服务器而降低。一致性哈希的缺点是,因为相同的请求会转发到同一台服务器,因此,可能造成某台服务器负载过重,甚至因为请求太多导致服务出现问题。
解决办法是根据实际情况动态选择使用哪种算法。
- 负载较低时,使用一致性哈希。
- 热点请求降级一致性哈希为轮询,或者如果请求数据有规律,则可考虑带权重的一致性哈希,
- 将热点数据推送到接入层Nginx,直接响应给用户。
热点数据与更新缓存
热点数据会造成服务器压力过大,导致服务器性能、吞吐量、带宽达到极限,出现响应慢或者拒绝服务的情况,这肯定是不允许的。可以用如下几个方案去解决。
单机全量缓存+主从
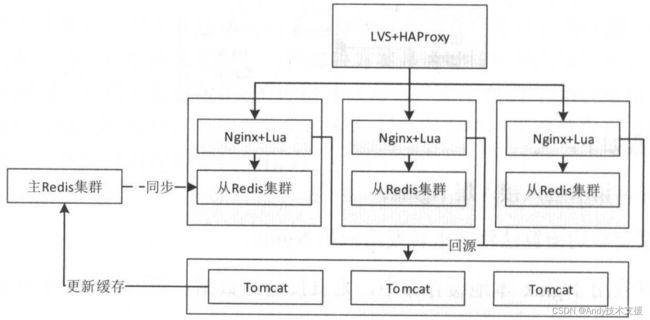
如上图所示,所有缓存都存储在应用本机,回源之后会把数据更新到主Redis集群,然后通过主从模式复制到其他从Redis集群。缓存的更新可以采用懒加载或者订阅消息进行同步。
分布式缓存+应用本地热点
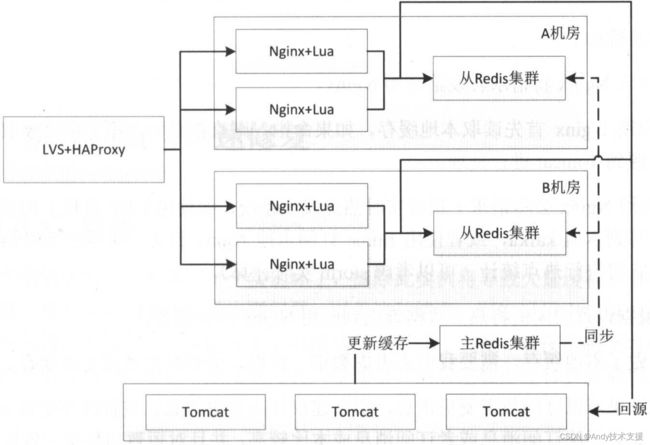 对于分布式缓存,我们需要在Nginx+Lua应用中进行应用缓存来减少Redis集群的访问冲击,即首先查询应用本地缓存,如果命中,则直接缓存,如果没有命中,则接着查询Redis集群、回源到Tomcat,然后将数据缓存到应用本地。
对于分布式缓存,我们需要在Nginx+Lua应用中进行应用缓存来减少Redis集群的访问冲击,即首先查询应用本地缓存,如果命中,则直接缓存,如果没有命中,则接着查询Redis集群、回源到Tomcat,然后将数据缓存到应用本地。
对于LVS+HAProxy到应用Nginx的负载机制,正常情况采用一致性哈希,如果某个请求类型的访问量突破了一定的阈值,则自动降级为轮询机制。
而对于一些秒杀活动之类的热点,我们是可以提前知道的,可以把相关数据预先推送到应用Nginx,并将负载均衡机制降级为轮询。
实际场景中我们是通过两级Nginx(接入Nginx→应用Nginx)实现该特性的,没有在LVS+HAProxy层实现。
另外,可以考虑建立实时热点发现系统来发现热点。

具体步骤如下。
- 接入Nginx将请求转发给应用Nginx。
- 应用Nginx首先读取本地缓存。如果命中,则直接返回,不命中会读取分布式缓存、回源到Tomcat进行处理。
- 应用Nginx会将请求上报给实时热点发现系统,如使用UDP直接上报请求,或者将请求写到本地kafka,或者使用flume订阅本地Nginx日志。上报给实时热点发现系统后,它将进行热点统计(可以考虑storm实时计算)。
- 根据设置的阈值将热点数据推送到应用Nginx本地缓存。
因为做了本地缓存,需要我们去考虑数据一致性,即何时失效或更新缓存。
- 如果可以订阅数据变更消息,那么建议订阅变更消息以进行缓存更新。
- 如果无法订阅消息或者订阅消息成本比较高,并且对短暂的数据一致性要求不严格(比如,在商品详情页看到的库存,可以短暂的不一致,只要保证下单时一致即可),那么可以设置合理的过期时间,过期后再查询新的数据。
- 如果是秒杀之类的,可以订阅活动开启消息,将相关数据提前推送到前端应用,并将负载均衡机制降级为轮询。
- 建立实时热点发现系统来对热点进行统一推送和更新。
更新缓存与原子性
正如之前说的,如果多个应用同时操作一份数据,很可能导致缓存数据变成脏数据,解决办法如下。
- 更新数据时使用更新时间戳或者版本对比,如果使用Redis,则可以利用其单线程机制进行原子化更新。使用如canal订阅数据库binlog。
- 将更新请求按照相应的规则分散到多个队列,然后每个队列进行单线程更新,更新时拉取最新的数据保存。
- 用分布式锁,在更新之前获取相关的锁。
缓存崩溃与快速修复
取模
对于取模机制,如果其中一个实例坏了,摘除此实例将导致大量缓存不命中,则瞬间大流量可能导致后端DB/服务出现问题。
对于这种情况,可以采用主从机制来避免实例坏了的问题,即其中一个实例坏了可以用从/主顶上来。但是,取模机制下增加一个节点将导致大量缓存不命中,一般是建立另一个集群,然后把数据迁移到新集群,把流量迁移过去。
一致性哈希
对于一致性哈希机制,如果其中一个实例坏了,摘除此实例只影响一致性哈希环上的部分缓存不命中,不会导致大量缓存瞬间回源到后端DB/服务,但是也会产生一些影响。
另外,也可能因为一些误操作导致整个缓存集群出现问题,如何快速恢复呢?
快速恢复
如果出现之前说到的一些问题,可以考虑如下方案。
- 主从机制,做好冗余,即其中一部分不可用,将对等的部分补上去。
- 如果因为缓存导致应用可用性已经下降,可以考虑部分用户降级,然后慢慢减少降级量,后台通过Worker预热缓存数据。
也就是说,如果整个缓存集群坏了,而且没有备份,那么只能慢慢将缓存重建。为了让部分用户还是可用的,可以根据系统承受能力,通过降级方案让一部分用户先用起来,将这些用户相关的缓存重建。另外,通过后台Worker进行缓存数据的预热。