Java的Set集合相关介绍
当我们需要对元素去重的时候,会使用Set集合,可选的Set集合有三个,分别是HashSet、LinkedHashSet、TreeSet,这三个常用的Set集合有什么区别呢?底层实现原理是什么样?这篇文章一起来深度剖析。
共同点
这三个类都实现了Set接口,所以使用方式都是一样的,使用add()方法添加元素,使用remove()删除元素,使用contains()方法判断元素是否存在,使用iterator()方法迭代遍历元素,这三个类都可以去除重复元素。
特性
- HashSet是最基础的Set集合,可以去除重复元素,元素存储是无序的。
- LinkedHashSet在HashSet功能基础上,增加了按照元素插入顺序或者访问顺序的迭代方式。
- TreeSet在HashSet功能基础上,可以保证按照元素大小顺序排列。
底层实现
- HashSet是基于HashMap实现的,使用组合的方式,并非继承。
- LinkedHashSet继承自HashSet,而内部则是采用组合LinkedHashMap的方式实现的。 就是这么乱,一会儿看一下源码就明白了。
- TreeSet是基于TreeMap实现的,采用组合的方式,跟上面两个Set集合没关系。
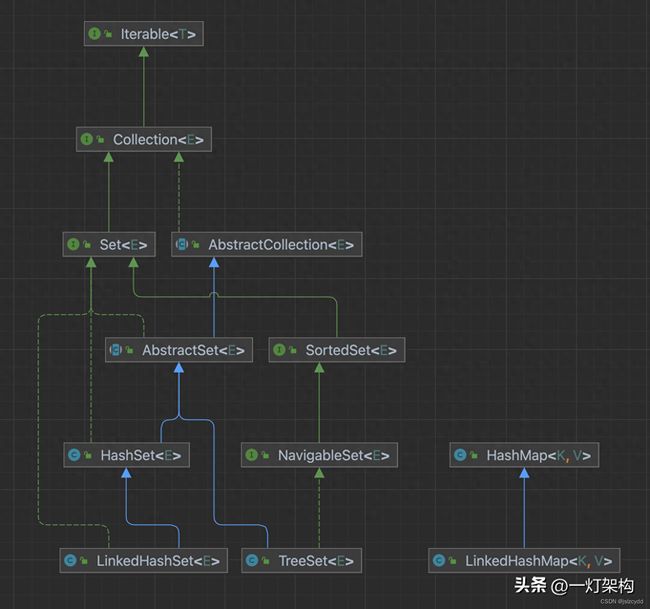
下面详细看一下这三个Set集合源码的底层实现:
HashSet源码实现
类属性
public class HashSet
extends AbstractSet
implements Set, Cloneable, java.io.Serializable {
/**
* 使用HashMap存储数据
*/
private transient HashMap map;
/**
* value的默认值
*/
private static final Object PRESENT = new Object();
} 可以看出HashSet实现了Set接口,内部采用HashMap存储元素,利用了HashMap的key不能重复的特性,实现元素去重。而value使用默认值,是一个空对象,没有任何作用,纯粹占坑。
初始化
HashSet常用的构造方法有两个,有参构造方法,可以指定初始容量和负载系数。
/**
* 无参构造方法
*/
HashSet hashSet1 = new HashSet<>();
/**
* 有参构造方法,指定初始容量和负载系数
*/
HashSet hashSet = new HashSet<>(16, 0.75f);
再看一下构造方式对应的源码实现:
/**
* 无参构造方法
*/
public HashSet() {
map = new HashMap<>();
}
/**
* 有参构造方法,指定初始容量和负载系数
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}HashSet的构造方式源码也很简单,都是利用的HashMap的构造方法实现。
常用方法源码
/**
* 添加元素
*/
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
/**
* 删除元素
*/
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
/**
* 判断是否包含元素
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
* 迭代器
*/
public Iterator iterator() {
return map.keySet().iterator();
} HashSet方法源码也很简单,都是利用HashMap的方法实现逻辑。利用HashMap的key不能重复的特性,value使用默认值(一个其实没有实际意义的值),contains()方法和iterator()方法也都是针对key进行操作。
LinkedHashSet源码实现
LinkedHashSet继承自HashSet,没有任何私有的属性。
public class LinkedHashSet
extends HashSet
implements Set, Cloneable, java.io.Serializable {
} 初始化
LinkedHashSet常用的构造方法有三个,有参构造方法,可以指定初始容量和负载系数。
/**
* 无参构造方法
*/
Set linkedHashSet1 = new LinkedHashSet<>();
/**
* 有参构造方法,指定初始容量
*/
Set linkedHashSet2 = new LinkedHashSet<>(16);
/**
* 有参构造方法,指定初始容量和负载系数
*/
Set linkedHashSet3 = new LinkedHashSet<>(16, 0.75f); LinkedHashSet的构造方法使用的是父类HashSet的构造方法,而HashSet的构造方法使用的是LinkedHashMap的构造方法,设计的就是这么乱!
public class HashSet
extends AbstractSet
implements Set, Cloneable, java.io.Serializable {
/**
* HashSet的构造方法,底层使用的是LinkedHashMap,专门给LinkedHashSet使用
*
* @param initialCapacity 初始容量
* @param loadFactor 负载系数
* @param dummy 这个字段没啥用
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
} LinkedHashSet的其他方法也是使直接用的父类HashSet的方法,就不用看了。
LinkedHashSet额外实现了按照元素的插入顺序或者访问顺序进行迭代的功能,是使用LinkedHashMap的实现,也是多用了一个链表的方式来维护元素的插入顺序
TreeSet源码实现
类属性
public class TreeSet extends AbstractSet
implements NavigableSet, Cloneable, java.io.Serializable {
/**
* 用来存储数据
*/
private transient NavigableMap m;
/**
* value的默认值
*/
private static final Object PRESENT = new Object();
} TreeSet内部使用NavigableMap存储数据,而NavigableMap是TreeMap的父类,后面在初始化NavigableMap的时候,会用TreeMap进行替换。而value使用默认空对象,与HashSet类似。
初始化
TreeSet有两个构造方法,有参构造方法,可以指定排序方式,默认是升序
/**
* 无参构造方法
*/
TreeSet treeSet1 = new TreeSet<>();
/**
* 有参构造方法,传入排序方式,默认升序,这里传入倒序
*/
TreeSet treeSet2 = new TreeSet<>(Collections.reverseOrder()); 再看一下构造方法的源码实现:
TreeSet(NavigableMap m) {
this.m = m;
}
/**
* 无参构造方法
*/
public TreeSet() {
this(new TreeMap());
}
/**
* 有参构造方法,传入排序方式,默认升序,这里传入倒序
*/
public TreeSet(Comparator comparator) {
this(new TreeMap<>(comparator));
} TreeSet的构造方法内部是直接使用的TreeMap的构造方法,是基于TreeMap实现的。
常用方法源码
/**
* 添加元素
*/
public boolean add(E e) {
return m.put(e, PRESENT) == null;
}
/**
* 删除元素
*/
public boolean remove(Object o) {
return m.remove(o) == PRESENT;
}
/**
* 判断是否包含元素
*/
public boolean contains(Object o) {
return m.containsKey(o);
}
/**
* 迭代器
*/
public Iterator iterator() {
return m.navigableKeySet().iterator();
}
TreeSet常用方法的底层实现都是使用的TreeMap的方法逻辑,就是这么偷懒。
TreeSet可以按元素大小顺序排列的功能,也是使用TreeMap实现的,由于TreeSet可以元素大小排列,所以跟其他Set集合相比,增加了一些按照元素大小范围查询的方法。
| 作用 |
方法签名 |
| 获取第一个元素 |
E first() |
| 获取最后一个元素 |
E last() |
| 获取大于指定键的最小键 |
E higher(E e) |
| 获取小于指定键的最大元素 |
E lower(E e) |
| 获取大于等于指定键的最小键 |
E ceiling(E e) |
| 获取小于等于指定键的最大键 |
E floor(E e) |
| 获取并删除第一个元素 |
E pollFirst() |
| 获取并删除最后一个元素 |
E pollLast() |
| 获取前几个元素(inclusive表示是否包含当前元素) |
NavigableSet headSet(E toElement, boolean inclusive) |
| 获取后几个元素(inclusive表示是否包含当前元素) |
NavigableSet tailSet(E fromElement, boolean inclusive) |
| 获取其中一段元素集合(inclusive表示是否包含当前元素) |
NavigableSet subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) |
| 获取其中一段元素集合(左开右开) |
SortedSet subSet(E fromElement, E toElement) |
| 获取前几个元素(不包含当前元素) |
SortedSet headSet(E toElement) |
| 获取后几个元素(不包含当前元素) |
SortedSet tailSet(E fromElement) |
但是其实这些方法感觉平时都用的很少,仅仅作为参考一下就是
HashSet、LinkedHashSet、TreeSet,这三个常用的Set集合的共同点是都实现了Set接口,所以使用方式都是一样的,使用add()方法添加元素,使用remove()删除元素,使用contains()方法判断元素是否存在,使用iterator()方法迭代遍历元素,这三个类都可以去除重复元素。
总结
不同点是: HashSet的关键特性:
- 是最基础的Set集合,可以去除重复元素。
- HashSet是基于HashMap实现的,使用组合的方式,并非继承。
- 利用了HashMap的key不重复的特性,而value是一个默认空对象,其他方法也都是使用HashMap实现。
LinkedHashSet的关键特性:
- LinkedHashSet继承自HashSet,而内部则是采用组合LinkedHashMap的方式实现的。
- LinkedHashSet在HashSet功能基础上,增加了按照元素插入顺序或者访问顺序的迭代方式,代价是额外增加一倍的存储空间。
- 方法内部都是使用LinkedHashMap实现的。
TreeSet的关键特性:
- TreeSet是基于TreeMap实现的,也是采用组合的方式。
- TreeSet在HashSet功能基础上,可以保证按照元素大小顺序排列,代价是查询、插入、删除接口的时间复杂度从O(1)退化到O(log n)。
- 方法内部都是使用TreeMap实现的。