深度学习python处理数据脚本
概述
总结深度学习项目中使用到的小工具.
图片与标签xml文件相对应
此脚本文件是为了解决图片与标签xml文件不对应的问题,清理数据,主要体现在图片多出几张或者标签多出几张的情况下.
(这里也可以变成“图片与标签txt文件相对应”,只需要把代码中的xml改成txt就可以了)
#encoding:utf-8
# !/usr/bin/python
'''
USE Method:python move.py --xml xmlpath --pic picpath
//由于path = os.path.abspath('.')代码,xmlpath取当前路径下的文件夹路径
'''
import os
import sys
import argparse
import os.path
import shutil
path = os.path.abspath('.')
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='cut pic and xml 1 to 2')
parser.add_argument('--xml', dest='xml', type=str)
parser.add_argument('--pic', dest='pic',type=str)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
xml = args.xml
pic = args.pic
xml_path = path + '/' + xml
pic_path = path + '/' + pic
dst_xml_path = path + '/' + "not_pic"
dst_pic_path = path + '/' + "not_xml"
if not os.path.exists(dst_pic_path):
os.mkdir(dst_pic_path)
else:
print "此目录已存在!"
sys.exit(1)
if not os.path.exists(dst_xml_path):
os.mkdir(dst_xml_path)
else:
print "此目录已存在!"
sys.exit(1)
for file in os.listdir(pic_path):
xml_name = os.path.join(xml_path, os.path.splitext(file)[0] + ".xml")
if os.path.exists(xml_name):
print "This file", file, "has xml !"
elif not os.path.exists(xml_name):
print "This file", file, "has not xml !"
shutil.move(os.path.join(pic_path,file), dst_pic_path)
for file in os.listdir(xml_path):
pic_name = os.path.join(pic_path, os.path.splitext(file)[0] + ".jpg")
if os.path.exists(pic_name):
print "This file", file, "has pic !"
elif not os.path.exists(pic_name):
print "This file", file, "has not pic !"
shutil.move(os.path.join(xml_path, file), dst_xml_path)
print "Done!"
#pic_path = os.path.join(pic_path, pic_name)
#shutil.move(xml_name, dst_path)
#for dirpath, dirnames, filenames in os.walk("f:/"):
# for filename in filenames:
# if os.path.splitext(filename)[1] == ".txt":
# print filepath
# copy(filepath, "F:/test/" + filename)
# Shutil.move(changeFilePath, dst_path)
修改xml中的标签值
修改标签中的值,这里举例只修改标签中的名称.应用场景:当标签类别需要合并,细标签要合并成粗标签时用到.
#!/usr/bin/python
#-*- coding: utf-8 -*-
'''
USE Method : python modify_xml_label.py
'''
# coding=utf-8
import os
import os.path
import xml.dom.minidom
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
path = "/media/t/disk1/jie_shou_ren_ming/matiansu/output/tail_xml"
outpath = "/media/t/disk1/jie_shou_ren_ming/matiansu/output/tail_output_xml"
files = os.listdir(path) # 得到文件夹下所有r文件名称
s = []
for xmlFile in files:
# 遍历文件夹
portion = os.path.splitext(xmlFile)
if not os.path.isdir(xmlFile):
# 判断是否是文件夹,不是文件夹才打开
# print (xmlFile)
# xml文件读取操作
# 将获取的xml文件名送入到dom解析
print(xmlFile)
dom = xml.dom.minidom.parse(os.path.join(path, xmlFile))
###最核心的部分os.path.join(path,xmlFile),路径拼接,输入的是具体路径
root = dom.documentElement
name = root.getElementsByTagName('name')
# pose=root.getElementsByTagName('pose')
# 重命名class name
for i in range(len(name)):
# print (name[i].firstChild.data)
# print(xmlFile)
# if portion[1] == ".xml":
# newname = portion[0] + ".jpg"
# print(newname)
newname ="2"
if name[i].firstChild.data =="1":
name[i].firstChild.data = newname
print(name[i].firstChild.data)
# 保存修改到xml文件中
with open(os.path.join(outpath, xmlFile), 'w') as fh:
dom.writexml(fh)
print('修改filename OK!')
生成xml脚本(caffe)
应用场合:通过小批量标注数据,用caffe训练一个初步模型,在通过下面脚本生成xml标签文件,方便后续标注组人员标注.
#!/usr/bin/env python
# set up Python environment: numpy for numerical routines, and matplotlib for plotting
#-*- coding: utf-8 -*-
import glob
from lxml import etree, objectify
import time
import numpy as np
import sys
import cv2
#from pascal_voc_writer import Writer
#import matplotlib.pyplot as plt
# display plots in this notebook
import argparse
# set display defaults
#plt.rcParams['figure.figsize'] = (10, 10) # large images
#plt.rcParams['image.interpolation'] = 'nearest' # don't interpolate: show square pixels
#plt.rcParams['image.cmap'] = 'gray' # use grayscale output rather than a (potentially misleading) color heatmap
# The caffe module needs to be on the Python path;
# we'll add it here explicitly.
import sys
caffe_root = './' # this file should be run from {caffe_root}/examples (otherwise change this line)
sys.path.insert(0, caffe_root + 'python')
import os
import caffe
import math
from os import walk
from os.path import join
# If you get "No module named _caffe", either you have not built pycaffe or you have the wrong path.
CLASSES = ('__background__',
'SmallVehicle', 'bus', 'BigVehicle')
def gen_txt(image,result,filename, path):
w = image.shape[1]
h = image.shape[0]
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder('JPEGImages'),
E.filename(filename),
E.size(
E.width(w),
E.height(h),
E.depth(3)
),
E.segmented(0),
)
#etree.ElementTree(anno_tree).write(path[:-4]+".xml", pretty_print=True)
for i in range(result.shape[1]):
for j in range(3,7,1):
if result[0][i][j]<0:
result[0][i][j] = 0
if result[0][i][j]>1:
result[0][i][j] = 1
left = result[0][i][3] * w
top = result[0][i][4] * h
right = result[0][i][5] * w
bot = result[0][i][6] * h
label = result[0][i][1]
score = result[0][i][2]
if(score<0.5) :
continue;
E2 = objectify.ElementMaker(annotate=False)
anno_tree2 = E2.object(
E.name(CLASSES[int(label)]),
E.pose('Unspecified'),
E.truncated('0'),
E.difficult('0'),
E.bndbox(
E.xmin(int(left)),
E.ymin(int(top)),
E.xmax(int(right)),
E.ymax(int(bot))
)
)
print "i = %d " % i
anno_tree.append(anno_tree2)
etree.ElementTree(anno_tree).write(path[:-4]+".xml", pretty_print=True)
def vis_detections(image,result) :
w = image.shape[1]
h = image.shape[0]
for i in range(result.shape[1]):
left = result[0][i][3] * w
top = result[0][i][4] * h
right = result[0][i][5] * w
bot = result[0][i][6] * h
score = result[0][i][2]
label = result[0][i][1]
box = [left,top,right,bot];
if(score>0.4) :
print(left,right,top,bot,score,label)
cv2.rectangle(image,(int(left), int(top)),(int(right),int(bot)),(0,255,0), 2)
label = '{:s} {:.3f}'.format(CLASSES[int(label)], score)
font = cv2.FONT_HERSHEY_SIMPLEX
size = cv2.getTextSize(label, font, 0.5, 0)[0]
cv2.rectangle(image,(int(left), int(top)),
(int(left+size[0]),int(top+ size[1])),(0,255,0), -1)
cv2.putText(image, label,(int(left+0.5), int(top+ size[1]+0.5)),font,0.5,(0,0,0),0)
def write_detections(image,result,writer) :
w = image.shape[1]
h = image.shape[0]
for i in range(result.shape[1]):
left = result[0][i][3] * w
top = result[0][i][4] * h
right = result[0][i][5] * w
bot = result[0][i][6] * h
score = result[0][i][2]
label = result[0][i][1]
if(score>0.1) :
print(left,right,top,bot,score,label)
cv2.rectangle(image,(int(left), int(top)),(int(right),int(bot)),(0,255,0), 2)
label = '{:s}'.format(CLASSES[int(label)])
font = cv2.FONT_HERSHEY_SIMPLEX
size = cv2.getTextSize(label, font, 0.5, 0)[0]
cv2.rectangle(image,(int(left), int(top)),
(int(left+size[0]),int(top+ size[1])),(0,255,0), -1)
cv2.putText(image, label,(int(left), int(top+ size[1])),font,0.5,(0,0,0),0)
#writer.addObject(label, int(left+0.5), int(top+0.5), int(right+0.5), int(bot+0.5))
def det(image,transformer,net):
transformed_image = transformer.preprocess('data', image)
#plt.imshow(image)
net.blobs['data'].data[...] = transformed_image
### perform classification
output = net.forward()
res = output['detection_out'][0] # the output probability vector for the first image in the batch
#print(res.shape)
return res
def is_imag(filename):
return filename[-4:] in ['.png', '.jpg']
def main(args):
caffe.set_mode_gpu()
model_def = args.model_def
model_weights = args.model_weights
net = caffe.Net(model_def, # defines the structure of the model
model_weights, # contains the trained weights
caffe.TEST) # use test mode (e.g., don't perform dropout)
mu = np.array([0.5, 0.5, 0.5])
# create transformer for the input called 'data'
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1)) # move image channels to outermost dimension
transformer.set_mean('data', mu) # subtract the dataset-mean value in each channel
transformer.set_raw_scale('data', 1.0) # rescale from [0, 1] to [0, 255]
transformer.set_channel_swap('data', (2,1,0)) # swap channels from RGB to BGR
net.blobs['data'].reshape(1, # batch size
3, # 3-channel (BGR) images
args.image_resize, args.image_resize) # image size is 227x227
filenames = os.listdir(args.image_dir)
images = filter(is_imag, filenames)
for image in images :
pic = args.image_dir + image
input = caffe.io.load_image(pic)
image_show =cv2.imread(pic)
start_time=time.time()
result = det(input,transformer,net)
end_time=time.time()
print("time:%lf" % (end_time-start_time))
#vis_detections(image_show,result)
gen_txt(image_show,result,image, pic)
if args.write_voc:
writer = Writer(pic, input.shape[1], input.shape[0])
write_detections(image_show,result,writer)
base = os.path.splitext(pic)[0]
writer.save(base+".xml")
else :
cv2.imshow("Image", image_show)
#cv2.waitKey (1000)
def parse_args():
parser = argparse.ArgumentParser()
'''parse args'''
parser.add_argument('--image_dir', default='/media/t/disk1/DukTo0929/14/')
parser.add_argument('--model_def', default='/media/t/disk1/jie_shou_ren_ming/guopei/MobileNetSSD_deploy.prototxt')
parser.add_argument('--model_weights', default='/media/t/disk1/jie_shou_ren_ming/guopei/mobilenet_v2_300x300_iter_10000.caffemodel')
parser.add_argument('--image_resize', default=608, type=int)
parser.add_argument('--write_voc', default=False)
return parser.parse_args()
if __name__ == '__main__':
main(parse_args())
删除满足一定条件的标注框
应用场景:例如删除标注数据中标注框的面积小于10000的框.
#!/usr/bin/python
#-*- coding: utf-8 -*-
'''
USE Method : python modify_xml_label.py
'''
# coding=utf-8
import os
import os.path
from lxml import etree, objectify
import xml.dom.minidom
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
path = "/home/t/data/VOCdevkit/MyDataSet/Annotations"
outpath = "/home/t/data/VOCdevkit/MyDataSet/Annotations_output"
def gen_txt(w,h,result,filename,path):
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder('JPEGImages'),
E.filename(filename),
#E.path(path),
E.size(
E.width(w),
E.height(h),
E.depth(3)
),
E.segmented(0),
)
for i in range(len(result)):
E2 = objectify.ElementMaker(annotate=False)
anno_tree2 = E2.object(
E.name(result[i][0]),
E.pose('Unspecified'),
E.truncated('0'),
E.difficult('0'),
E.bndbox(
E.xmin(result[i][1]),
E.xmax(result[i][2]),
E.ymin(result[i][3]),
E.ymax(result[i][4])
)
)
print "i = %d " % i
anno_tree.append(anno_tree2)
etree.ElementTree(anno_tree).write(path, pretty_print=True)
files = os.listdir(path) # 得到文件夹下所有r文件名称
for xmlFile in files:
# 遍历文件夹
portion = os.path.splitext(xmlFile)
rect_coordinates = []
if not os.path.isdir(xmlFile):
# 判断是否是文件夹,不是文件夹才打开
# print (xmlFile)
# xml文件读取操作
# 将获取的xml文件名送入到dom解析
print(xmlFile)
dom = xml.dom.minidom.parse(os.path.join(path, xmlFile))
###最核心的部分os.path.join(path,xmlFile),路径拼接,输入的是具体路径
root = dom.documentElement
xmin = root.getElementsByTagName('xmin')
ymin = root.getElementsByTagName('ymin')
xmax = root.getElementsByTagName('xmax')
ymax = root.getElementsByTagName('ymax')
width = root.getElementsByTagName('width')
height = root.getElementsByTagName('height')
name = root.getElementsByTagName('name')
# pose=root.getElementsByTagName('pose')
# 重命名class name
if(0 == len(xmin)):
continue
for i in range(len(xmin)):
# print (name[i].firstChild.data)
# print(xmlFile)
# if portion[1] == ".xml":
# newname = portion[0] + ".jpg"
# print(newname)
rect_coordinate = []
area = ((int)(xmax[i].firstChild.data)-(int)(xmin[i].firstChild.data))*((int)(ymax[i].firstChild.data)-(int)(ymin[i].firstChild.data))
if area < 10000:
print area
continue
else:
rect_coordinate.append(name[i].firstChild.data)
rect_coordinate.append(xmin[i].firstChild.data)
rect_coordinate.append(xmax[i].firstChild.data)
rect_coordinate.append(ymin[i].firstChild.data)
rect_coordinate.append(ymax[i].firstChild.data)
rect_coordinates.append(rect_coordinate)
gen_txt(width[0].firstChild.data,height[0].firstChild.data,rect_coordinates,xmlFile,os.path.join(outpath, xmlFile))
# 保存修改到xml文件中
#with open(os.path.join(outpath, xmlFile), 'w') as fh:
#dom.writexml(fh)
#print('修改filename OK!')
caffe测试python脚本
caffe前向推理脚本:
import numpy as np
import sys,os
import cv2
caffe_root = './caffe_ssd/' # this file should be run from {caffe_root}/examples (otherwise change this line)
sys.path.insert(0, caffe_root + 'python')
import caffe
net_file= './MobileNetSSD_deploy.prototxt'
caffe_model='./mobilenet_v2_300x300_iter_2000.caffemodel'
test_dir = "/media/t/disk1/chengyun/vehicle_data_v2/kakou/JPEGImages"
if not os.path.exists(caffe_model):
print(caffe_model + " does not exist")
exit()
if not os.path.exists(net_file):
print(net_file + " does not exist")
exit()
net = caffe.Net(net_file, caffe_model, caffe.TEST)
CLASSES = ('background',
'car')
def preprocess(src):
img = cv2.resize(src, (300,300))
#img = img - np.array([104.0, 117.0, 123.0])
img = img - 127.5
img = img * 0.007843
return img
def postprocess(img, out):
h = img.shape[0]
w = img.shape[1]
box = out['detection_out'][0,0,:,3:7] * np.array([w, h, w, h])
cls = out['detection_out'][0,0,:,1]
conf = out['detection_out'][0,0,:,2]
return (box.astype(np.int32), conf, cls)
def detect(imgfile):
origimg = cv2.imread(imgfile)
img = preprocess(origimg)
img = img.astype(np.float32)
img = img.transpose((2, 0, 1))
net.blobs['data'].data[...] = img
out = net.forward()
box, conf, cls = postprocess(origimg, out)
for i in range(len(box)):
p1 = (box[i][0], box[i][1])
p2 = (box[i][2], box[i][3])
width = box[i][2] - box[i][0]
height = box[i][3] - box[i][1]
#cv2.rectangle(origimg, p1, p2, (255,0,0), 2)
p3 = (max(p1[0], 15), max(p1[1], 15))
cv2.rectangle(origimg, p1, p2, (255,0,0), 2)
title = "%s:%.2f" % (CLASSES[int(cls[i])], conf[i])
cv2.putText(origimg, title, p3, cv2.FONT_ITALIC, 1, (0, 255, 0), 2)
#cv2.imshow("SSD", origimg)
cv2.imwrite(os.path.join("imgs_res", os.path.basename(imgfile)), origimg)
#k = cv2.waitKey(0) & 0xff
#Exit if ESC pressed
#if k == 27 : return False
return True
for f in os.listdir(test_dir):
if detect(test_dir + "/" + f) == False:
break
将图片分成白天和晚上
#!/usr/bin/env python
# set up Python environment: numpy for numerical routines, and matplotlib for plotting
#-*- coding: utf-8 -*-
import glob
import time
import numpy as np
import sys
import cv2
#from pascal_voc_writer import Writer
#import matplotlib.pyplot as plt
# display plots in this notebook
import argparse
# set display defaults
#plt.rcParams['figure.figsize'] = (10, 10) # large images
#plt.rcParams['image.interpolation'] = 'nearest' # don't interpolate: show square pixels
#plt.rcParams['image.cmap'] = 'gray' # use grayscale output rather than a (potentially misleading) color heatmap
# The caffe module needs to be on the Python path;
# we'll add it here explicitly.
import sys
import os
#import python
import math
from os import walk
from os.path import join
# If you get "No module named _caffe", either you have not built pycaffe or you have the wrong path.
def get_image_list(image_dir, suffix=['jpg','JPG','png']):
'''get all image path ends with suffix'''
if not os.path.exists(image_dir):
print("PATH:%s not exists" % image_dir)
return []
imglist = []
filenames = []
for root, sdirs, files in os.walk(image_dir):
if not files:
continue
for filename in files:
filepath = os.path.join(root, filename)
if filename.split('.')[-1] in suffix:
imglist.append(filepath)
filenames.append(filename)
return imglist,filenames
def is_night_or_day(img,thres0=40,thres1=100):
img_BGR = img.copy()
img_HSV = cv2.cvtColor(img_BGR,cv2.COLOR_BGR2HSV)
img_H,img_S,img_V = cv2.split(img_HSV)
average_V = np.sum(np.reshape(img_V,(img_V.size,))) / img_V.size
if (average_V < thres0):
return 0
elif (average_V > thres1):
return 1
else:
return 2
if __name__ == '__main__':
image_src = '/media/t/disk1/jie_shou_ren_ming/chengyun/vehicle_data_v2/kakou/JPEGImages'
image_src_path , filenames = get_image_list(image_src, suffix=['jpg','JPG','png'])
for i in range(len(image_src_path)):
image_show =cv2.imread(image_src_path[i])
dst_img_name = filenames[i]
if (is_night_or_day(image_show) == 0):
cv2.imwrite('/media/t/disk1/jie_shou_ren_ming/chengyun/vehicle_data_v2/kakou/output'+'/night/'+dst_img_name,image_show)
elif (is_night_or_day(image_show) == 1):
cv2.imwrite('/media/t/disk1/jie_shou_ren_ming/chengyun/vehicle_data_v2/kakou/output'+'/day/'+dst_img_name,image_show)
else:
cv2.imwrite('/media/t/disk1/jie_shou_ren_ming/chengyun/vehicle_data_v2/kakou/output'+'/others/'+dst_img_name,image_show)
截取ROI区域的图片
#encoding:utf-8
import cv2
import argparse
import sys
import os
import xml.dom.minidom
path = os.path.abspath('.')
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='save classes to folder')
parser.add_argument('--xml', dest='xml', type=str)
parser.add_argument('--pic', dest='pic', type=str)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
def ReadXml(xmlfile):
dom = xml.dom.minidom.parse(xmlfile) #打开xml文档
root = dom.documentElement #得到xml文档对象
name = root.getElementsByTagName('name')
xmin = root.getElementsByTagName('xmin')
ymin = root.getElementsByTagName('ymin')
xmax = root.getElementsByTagName('xmax')
ymax = root.getElementsByTagName('ymax')
results = []
for i in range(len(name)):
imgbox = [int(xmin[i].firstChild.data),int(ymin[i].firstChild.data),int(xmax[i].firstChild.data),int(ymax[i].firstChild.data)]
results.append({'name':name[i].firstChild.data.encode("utf-8"), 'imgbox':imgbox})
return results
def saveimg(dir,picfile):
img = cv2.imread(picfile)
# if img == None :
# print None
# return "0"
xml_class = dir['name']
xml_class_path = os.path.join(path , 'classes1',xml_class)
pic_class = os.path.join(xml_class_path,os.path.splitext(x)[0] + ".jpg")
if not os.path.exists(xml_class_path):
os.mkdir(xml_class_path)
class_img = img[dir['imgbox'][1]:dir['imgbox'][3], dir['imgbox'][0]:dir['imgbox'][2]]
cv2.imwrite(pic_class,class_img)
else:
class_img = img[dir['imgbox'][1]:dir['imgbox'][3], dir['imgbox'][0]:dir['imgbox'][2]]
cv2.imwrite(pic_class, class_img)
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
pic_folder = args.pic
xml_folder = args.xml
pic_folder_path = os.path.join(path,pic_folder)
xml_folder_path = os.path.join(path,xml_folder)
if not os.path.exists(os.path.join(path, 'classes1')):
os.mkdir(os.path.join(path, 'classes1'))
else:
print "此目录已存在!"
sys.exit(1)
for x in os.listdir(xml_folder_path) :
xml_file_path = os.path.join(xml_folder_path,x)
pic_file_path = os.path.join(pic_folder_path,os.path.splitext(x)[0] + ".jpg")
results = ReadXml(xml_file_path)
print xml_file_path
print pic_file_path
for num in xrange(len(results)) :
saveimg(results[num],pic_file_path)
print "This file has done! "
print "_______________________________________"
print 'Done'
xml转txt文件的脚本
我们知道使用labelimg标注好的文件格式是.xml文件 如果我们要使用yolov5就需要把它转换成yolov5需要的文件格式 .txt (这是重点) 代码附下:
# -*- coding: utf-8 -*-
import os
import xml.etree.ElementTree as ET
dirpath = r'D:\pythonProject1\yolov5-6.0\bottle_dataset\stronger\xml' # 原来存放xml文件的目录
newdir = r'D:\pythonProject1\yolov5-6.0\bottle_dataset\stronger\labels' # 修改label后形成的txt目录
if not os.path.exists(newdir):
os.makedirs(newdir)
dict_info = {'green': 0, 'transparent': 1, 'white': 2, 'blue': 3, 'unknown': 4, 'orange': 5} # 有几个 类别 填写几个label names
for fp in os.listdir(dirpath):
if fp.endswith('.xml'):
root = ET.parse(os.path.join(dirpath, fp)).getroot()
xmin, ymin, xmax, ymax = 0, 0, 0, 0
sz = root.find('size')
width = float(sz[0].text)
height = float(sz[1].text)
filename = root.find('filename').text
for child in root.findall('object'): # 找到图片中的所有框
sub = child.find('bndbox') # 找到框的标注值并进行读取
label = child.find('name').text
label_ = dict_info.get(label)
if label_:
label_ = label_
else:
label_ = 0
xmin = float(sub[0].text)
ymin = float(sub[1].text)
xmax = float(sub[2].text)
ymax = float(sub[3].text)
try: # 转换成yolov3的标签格式,需要归一化到(0-1)的范围内
x_center = (xmin + xmax) / (2 * width)
x_center = '%.6f' % x_center
y_center = (ymin + ymax) / (2 * height)
y_center = '%.6f' % y_center
w = (xmax - xmin) / width
w = '%.6f' % w
h = (ymax - ymin) / height
h = '%.6f' % h
except ZeroDivisionError:
print(filename, '的 width有问题')
with open(os.path.join(newdir, fp.split('.xml')[0] + '.txt'), 'a+') as f:
f.write(' '.join([str(label_), str(x_center), str(y_center), str(w), str(h) + '\n']))
print('ok')
代码只需要更改5,6行的文件路径和第11行你所标注的类别即可。
注:.xml转化成.txt文件放入labels内。
注:我们用到的所有照片放入JPEGImage内。
生成的.txt内容如下(以我的数据为例)第一列是设定的标签,后面是坐标位置
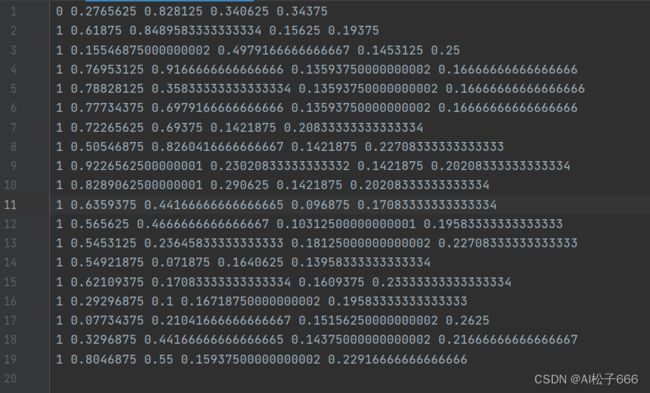
yolo的txt标签文件转换成voc的xml文件脚本
网上很多xml转txt格式的,却没有txt转xml格式的,自己写了脚本如下:
txt标签文件格式

xml文件格式

转换代码如下:
#coding=utf-8
#makexml("txt所在文件夹","xml保存地址","图片所在地址")
from xml.dom.minidom import Document
import os
import cv2
def makexml(txtPath,xmlPath,picPath): #读取txt路径,xml保存路径,数据集图片所在路径
dict = {'0': "person",#字典对类型进行转换
'1': "car",
'2': "bus",
'3': "truck"}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile=open(txtPath+name,'r',encoding='iso8859-1')
txtList = txtFile.readlines()
img = cv2.imread(picPath+name[0:-4]+".jpg")
print(picPath+name[0:-4]+".jpg")
Pheight,Pwidth,Pdepth=img.shape
#for i in txtList:
#oneline = i.strip().split(" ")
folder = xmlBuilder.createElement("folder")#folder标签
folderContent = xmlBuilder.createTextNode("VOC2007")
folder.appendChild(folderContent)
annotation.appendChild(folder)
filename = xmlBuilder.createElement("filename")#filename标签
filenameContent = xmlBuilder.createTextNode(name[0:-4]+".jpg")
filename.appendChild(filenameContent)
annotation.appendChild(filename)
size = xmlBuilder.createElement("size")# size标签
width = xmlBuilder.createElement("width") # size子标签width
widthContent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthContent)
size.appendChild(width)
height = xmlBuilder.createElement("height") # size子标签height
heightContent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightContent)
size.appendChild(height)
depth = xmlBuilder.createElement("depth") # size子标签depth
depthContent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthContent)
size.appendChild(depth)
annotation.appendChild(size)
for i in txtList:
oneline = i.strip().split(" ")
object = xmlBuilder.createElement("object")
picname = xmlBuilder.createElement("name")
if oneline[0]>='4':
continue
nameContent = xmlBuilder.createTextNode(dict[oneline[0]])
picname.appendChild(nameContent)
object.appendChild(picname)
pose = xmlBuilder.createElement("pose")
poseContent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(poseContent)
object.appendChild(pose)
truncated = xmlBuilder.createElement("truncated")
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
difficult = xmlBuilder.createElement("difficult")
difficultContent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultContent)
object.appendChild(difficult)
bndbox = xmlBuilder.createElement("bndbox")
xmin = xmlBuilder.createElement("xmin")
mathData=int(((float(oneline[1]))*Pwidth+1)-(float(oneline[3]))*0.5*Pwidth)
if mathData<0:
mathData= 0
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
ymin = xmlBuilder.createElement("ymin")
mathData = int(((float(oneline[2]))*Pheight+1)-(float(oneline[4]))*0.5*Pheight)
if mathData<0:
mathData= 0
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
xmax = xmlBuilder.createElement("xmax")
mathData = int(((float(oneline[1]))*Pwidth+1)+(float(oneline[3]))*0.5*Pwidth)
if mathData > Pwidth:
mathData= Pwidth
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
ymax = xmlBuilder.createElement("ymax")
mathData = int(((float(oneline[2]))*Pheight+1)+(float(oneline[4]))*0.5*Pheight)
if mathData > Pheight:
mathData= Pheight
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
f = open(xmlPath+name[0:-4]+".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
txt_path = '/root/zhangsong/huawei/data/zsmodify_data/txt/'
xml_path = '/root/zhangsong/huawei/data/zsmodify_data/Annotations/'
image_path = '/root/zhangsong/huawei/data/zsmodify_data/JPEGImages/'
makexml(txt_path,xml_path,image_path)
python遍历获取文件:for (root, dirs, files) in walk(roots):
注意事项:这是个遍历类似于生成器的感觉,一层一层遍历直接上代码,帮助大家清晰理解:
测试代码如下
path = 'F:/KuGou'
def file_name(file_dir):
a = 1
for root, dirs, files in os.walk(file_dir):#遍历文件夹、根目录、目录文件夹、目录里的文件
print(root)
print("*****************")
print(dirs)
print("************")
print(files)
print(a)
a +=1
file_name(path)
结果如下
F:/KuGou
*****************
['01', '02']
************
[]
1
F:/KuGou\01
*****************
[]
************
['1.png', '2.png']
2
F:/KuGou\02
*****************
[]
************
['2018120618453717793.pdf']
3
删除爬虫出来的小图片
爬虫爬了大量的图片,但的图片大小残次不齐,下面的代码目的是删除小于20K的图片
这里图片size小于250*250的就会删除,最后计算一个小于20K文件的百分比。但第一次运行的时候先不要运行remove语句,毕竟20K的闸值需要你自己设定的
import os
'''
DirList = [
'/home/king/PycharmProjects/nsfw_data_scrapper/raw_data/drawings',
'/home/king/PycharmProjects/nsfw_data_scrapper/raw_data/hentai',
'/home/king/PycharmProjects/nsfw_data_scrapper/raw_data/neutral',
'/home/king/PycharmProjects/nsfw_data_scrapper/raw_data/porn',
'/home/king/PycharmProjects/nsfw_data_scrapper/raw_data/sexy']
'''
DirList = [
'E:\\projection\\fair\\data\\dataset\\open_fire']
for path in DirList:
print(path)
tall = 0
small = 0
for filename in os.listdir(path):
fullName = os.path.join(path, filename)
size = os.path.getsize(fullName)
if size < 250 * 250:
small = small + 1
os.remove(fullName)
tall = tall + 1
print(tall, small, small/tall * 100)
python脚本文件操作删除满足一定条件的文件内容(darknet标签文件修改)
#删除类型为0(火)的标签
with open(label_file,"r",encoding="utf-8") as f:
read_lines = f.readlines()
#print(lines)
with open(label_file,"w",encoding="utf-8") as f_w:
for read_line in read_lines:
if int(read_line.split()[0]) == 0:
continue
else:
#类型为0的标签之外,所有标签类别减1
modefy_read_line_list = list(read_line)
if int(modefy_read_line_list[0]) > 0 :
modefy_read_line_list[0] = str(int(modefy_read_line_list[0]) -1)
read_line = ''.join(modefy_read_line_list)
f_w.write(read_line)
opencv-python图片基本操作
scr_img = cv2.imread(image_path)
#scr_img.shape[0] #图像的高度
#scr_img.shape[1] #图像的宽度
xmins = xmins * scr_img.shape[1]
ymins = ymins * scr_img.shape[0]
xmaxs = xmaxs * scr_img.shape[1]
ymaxs = ymaxs * scr_img.shape[0]
out_iou_img = scr_img[(int)(ymins):(int)(ymaxs),(int)(xmins):(int)(xmaxs)] #截取ROI区域的图片
cv2.imwrite(output_file + 'cat_{}_{}.jpg'.format(i,objects_num),out_iou_img) #保存图片
图片的复制粘贴(用于数据增强)
如果想将两张图像进行融合,只需再读取一张图像即可,方法原理类似。 实现代码如下:
# -*- coding:utf-8 -*-
import cv2
import numpy as np
#读取图片
img = cv2.imread("test.jpg", cv2.IMREAD_UNCHANGED)
test = cv2.imread("test3.jpg", cv2.IMREAD_UNCHANGED)
#定义300*100矩阵 3对应BGR
face = np.ones((200, 200, 3))
#显示原始图像
cv2.imshow("Demo", img)
#显示ROI区域
face = img[100:300, 150:350]
test[400:600,400:600] = face
cv2.imshow("Pic", test)
#等待显示
cv2.waitKey(0)
cv2.destroyAllWindows()
修改文件名
#-*- coding: utf-8 -*-
#!/usr/bin/env python
'''
USE Method:python ./modify_file_name.py
'''
#-*- coding: utf-8 -*-
#!/usr/bin/env python
'''
USE Method:python ./modify_file_name.py
'''
import os
import glob
import cv2
global count
def get_image_list(image_dir, suffix=['jpg','JPG','png']):
'''get all image path ends with suffix'''
if not os.path.exists(image_dir):
print("PATH:%s not exists" % image_dir)
return []
imglist = []
count = 0
for root, sdirs, files in os.walk(image_dir):
if not files:
continue
for filename in files:
filepath = os.path.join(root, filename)
print('*************')
#filename = filename + '.jpg'
if filename.split('.')[-1] in suffix:
newpath = os.path.join(root, 'crawler0_20210106_') + str(count) + '.jpg'
os.rename(filepath,newpath)
count += 1
return imglist
if __name__ == '__main__':
image_src = r'C:\Users\Administrator\Desktop\crawler0'
image_src_path = get_image_list(image_src, suffix=['jpg','JPG','png'])
随机删除图片
如果图片有点多余,可以随机删除一定比例的图片,也可以删除对应的标签文件。
import os
import io
import math
import sys
import cv2
import shutil
import random
import numpy as np
from collections import namedtuple, OrderedDict
label_names = ['person','car','bus','truck','motorcycle','chemical']
def get_files(dir, suffix):
res = []
for root, directory, files in os.walk(dir):
for filename in files:
name, suf = os.path.splitext(filename)
if suf in suffix:
#res.append(filename)
res.append(os.path.join(root, filename))
return res
def random_filter_image(list_path,random_rate):
image_list = get_files(list_path, ['.jpg'])
total_len = len(image_list)
print('total_label_len', total_len)
for i in range(0, total_len):
gen_rate = random.random()
#'''
if (gen_rate < random_rate):
pass
else:
os.remove(image_list[i])
continue
#'''
image_file = image_list[i]
file_name, type_name = os.path.splitext(image_file)
file_txt_name = file_name + '.txt'
with open(file_txt_name,"w",encoding="utf-8") as f_w:
pass
random.shuffle(image_list)
def main():
global random_rate
#list_path = r'C:\Users\Administrator\Desktop\negative_image\101\outsourcing_data\201210'
list_path = r'E:\projection\fair\data\genarate_4to1\negative_image\101\data\20729'
save_base_dir= r'E:\projection\cat'
random_rate = 0.25
random_filter_image(list_path,random_rate)
if __name__ == '__main__':
main()
文件重命名
#-*- coding: utf-8 -*-
#!/usr/bin/env python
'''
USE Method:python ./modify_file_name.py
'''
import os
import glob
import cv2
global count
def get_image_list(image_dir, suffix=['jpg','JPG','png']):
'''get all image path ends with suffix'''
if not os.path.exists(image_dir):
print("PATH:%s not exists" % image_dir)
return []
imglist = []
count = 0
for root, sdirs, files in os.walk(image_dir):
if not files:
continue
for filename in files:
filepath = os.path.join(root, filename)
print('filename*************',filename)
#print('root*************',root)
#filename = filename + '.jpg'
if filename.split('.')[-1] in suffix:
newpath = os.path.join(root, 'output') + str(count) + '.mp4'
print('newpath*************',newpath)
os.rename(filepath,newpath)
count += 1
return imglist
if __name__ == '__main__':
image_src = r'E:\projection\fair\data\磁盘\output1'
image_src_path = get_image_list(image_src, suffix=['mp4'])
标签过滤
darknet删除一些不满足要求的标签框,如标签坐标为负值。
import os
import io
import math
import sys
import random
import argparse
from collections import namedtuple, OrderedDict
label_names = ['person','car','bus','truck']
def get_files(dir, suffix):
res = []
for root, directory, files in os.walk(dir):
for filename in files:
name, suf = os.path.splitext(filename)
if suf == suffix:
#res.append(filename)
res.append(os.path.join(root, filename))
return res
def gbbox_iou(box1, box2):
b1_x1, b1_y1, b1_x2, b1_y2 = box1
b2_x1, b2_y1, b2_x2, b2_y2 = box2
inter_rect_x1 = max(b1_x1, b2_x1)
inter_rect_y1 = max(b1_y1, b2_y1)
inter_rect_x2 = min(b1_x2, b2_x2)
inter_rect_y2 = min(b1_y2, b2_y2)
inter_width = inter_rect_x2 - inter_rect_x1 + 1
inter_height = inter_rect_y2 - inter_rect_y1 + 1
if inter_width > 0 and inter_height > 0:
inter_area = inter_width * inter_height
#iou
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
#iou = inter_area / (b1_area + b2_area - inter_area)
iou = inter_area / b1_area
else:
iou = 0
return iou
def convert_dataset(list_path, output_file):
# 读取目录里面所有的 txt标记文件 列表
label_list = get_files(list_path, '.txt')
total_label_len = len(label_list)
random.shuffle(label_list)
print('total_label_len', total_label_len)
error_count = 0
fp=open(output_file,'w')
for i in range(0, total_label_len):
sys.stdout.write('\r>> Calculating {}/{} error{}'.format(
i + 1, total_label_len, error_count))
sys.stdout.flush()
# 单个Label txt文件读取
label_file = label_list[i]
file_name, type_name = os.path.splitext(label_file)
image_path = file_name + '.jpg'
if type_name != '.txt' or not os.path.exists(image_path):
error_count += 1
print("error_file: ",label_file.encode('UTF-8', 'ignore').decode('UTF-8'))
continue
fd = open(label_file, 'r')
lines = [line.split() for line in fd]
fd.close()
error_id = 0
for line in lines:
class_index = int(line[0])
xmins = float(line[1]) - float(line[3]) / 2
ymins = float(line[2]) - float(line[4]) / 2
xmaxs = float(line[1]) + float(line[3]) / 2
ymaxs = float(line[2]) + float(line[4]) / 2
if float(line[3])<=0 or float(line[4]) <= 0 :
error_id = 1
print('\n error index: ', class_index, 'label_file', label_file)
continue
if class_index >= 3:
error_id = 1
print('\n error index: ', class_index, 'label_file', label_file)
continue
# if xmins < 0 or ymins < 0 :
# error_id = 1
# print('\n error index: ', class_index, 'label_file', label_file)
# if ymaxs > 1 or xmaxs > 1 :
# print('\n error index: ', class_index, 'label_file', label_file)
# error_id = 1
if error_id:
continue
# is_person_car = False
# bbox_num = len(lines)
# for i in range(0, bbox_num):
# if int(lines[i][0]) != 0:
# continue
# for j in range(0, bbox_num):
# if i==j or int(lines[j][0])==0:
# continue
# xmins = float(lines[i][1]) - float(lines[i][3]) / 2
# ymins = float(lines[i][2]) - float(lines[i][4]) / 2
# xmaxs = float(lines[i][1]) + float(lines[i][3]) / 2
# ymaxs = float(lines[i][2]) + float(lines[i][4]) / 2
# xmins1 = float(lines[j][1]) - float(lines[j][3]) / 2
# ymins1 = float(lines[j][2]) - float(lines[j][4]) / 2
# xmaxs1 = float(lines[j][1]) + float(lines[j][3]) / 2
# ymaxs1 = float(lines[j][2]) + float(lines[j][4]) / 2
# box1 = (xmins, ymins, xmaxs, ymaxs)
# box2 = (xmins1, ymins1, xmaxs1, ymaxs1)
# #过滤行人在车中
# iou = gbbox_iou(box1, box2)
# if iou > 0.99:
# is_person_car = True
# if is_person_car:
# continue
print("image_path: ", image_path)
fp.write(image_path)
fp.write('\n')
print('total_label_len', total_label_len)
fp.close()
def main():
parser = argparse.ArgumentParser(prog='gen_label_list.py')
parser.add_argument('--img-path', type=str, default='/root/zhangsong/fairworks/github/darknet-master/fireworks/data/smoke', help='test path')
parser.add_argument('--valid', type=str, default='fireworks/data/test_train.txt', help='*.txt path')
opt = parser.parse_args()
print(opt.img_path, opt.valid)
convert_dataset(opt.img_path, opt.valid)
if __name__ == '__main__':
main()
darknet感兴趣区域截取
import os
import io
import math
import sys
import random
import argparse
import cv2
from collections import namedtuple, OrderedDict
label_names = ['person','car','bus','truck']
def get_files(dir, suffix):
res = []
for root, directory, files in os.walk(dir):
for filename in files:
name, suf = os.path.splitext(filename)
if suf == suffix:
#res.append(filename)
res.append(os.path.join(root, filename))
return res
def gbbox_iou(box1, box2):
b1_x1, b1_y1, b1_x2, b1_y2 = box1
b2_x1, b2_y1, b2_x2, b2_y2 = box2
inter_rect_x1 = max(b1_x1, b2_x1)
inter_rect_y1 = max(b1_y1, b2_y1)
inter_rect_x2 = min(b1_x2, b2_x2)
inter_rect_y2 = min(b1_y2, b2_y2)
inter_width = inter_rect_x2 - inter_rect_x1 + 1
inter_height = inter_rect_y2 - inter_rect_y1 + 1
if inter_width > 0 and inter_height > 0:
inter_area = inter_width * inter_height
#iou
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
#iou = inter_area / (b1_area + b2_area - inter_area)
iou = inter_area / b1_area
else:
iou = 0
return iou
def convert_dataset(list_path, output_file):
# 读取目录里面所有的 txt标记文件 列表
label_list = get_files(list_path, '.txt')
total_label_len = len(label_list)
random.shuffle(label_list)
print('total_label_len', total_label_len)
error_count = 0
for i in range(0, total_label_len):
sys.stdout.write('\r>> Calculating {}/{} error{}\n'.format(
i + 1, total_label_len, error_count))
sys.stdout.flush()
# 单个Label txt文件读取
label_file = label_list[i]
file_name, type_name = os.path.splitext(label_file)
#print(file_name)
#print(file_name.split('\\')[-1] + 'aaaaaa')
cut_image_name_list = file_name.split('\\')[-2:] #cut_image_name_list is list
cut_image_name = ''.join(cut_image_name_list) #list to str
image_path = file_name + '.jpg'
if type_name != '.txt' or not os.path.exists(image_path):
error_count += 1
print("error_file: ",label_file.encode('UTF-8', 'ignore').decode('UTF-8'))
continue
scr_img = cv2.imread(image_path)
#'''
#删除类型为0(火)的标签
with open(label_file,"r",encoding="utf-8") as f:
read_lines = f.readlines()
#print(lines)
with open(label_file,"w",encoding="utf-8") as f_w:
for read_line in read_lines:
if int(read_line.split()[0]) == 0:
continue
else:
#所有标签类别减1
modefy_read_line_list = list(read_line)
if int(modefy_read_line_list[0]) > 0 :
modefy_read_line_list[0] = str(int(modefy_read_line_list[0]) -1)
read_line = ''.join(modefy_read_line_list)
#删除标签矩形长宽及面积比较小的图片
labels_coordi = read_line.split()
if float(labels_coordi[3]) * scr_img.shape[1] < 30.0 :
continue
if float(labels_coordi[4]) * scr_img.shape[0] < 30.0 :
continue
f_w.write(read_line)
#'''
#截取图片
fd = open(label_file, 'r')
lines = [line.split() for line in fd]
fd.close()
error_id = 0
objects_num = 0
#newlabels = []
for line in lines:
'''
if int(line[0]) == 0:
continue
else:
newlabels
'''
class_index = int(line[0])
xmins = float(line[1]) - float(line[3]) / 2
ymins = float(line[2]) - float(line[4]) / 2
xmaxs = float(line[1]) + float(line[3]) / 2
ymaxs = float(line[2]) + float(line[4]) / 2
if float(line[3])<=0 or float(line[4]) <= 0 :
error_id = 1
print('\n error index: ', class_index, 'label_file', label_file)
continue
if class_index >= 3:
error_id = 1
print('\n error index: ', class_index, 'label_file', label_file)
continue
if xmins < 0 :
xmins = 0
if ymins < 0 :
ymins = 0
if ymaxs > 1 :
ymaxs = 1
if xmaxs > 1 :
xmaxs = 1
xmins = xmins * scr_img.shape[1]
ymins = ymins * scr_img.shape[0]
xmaxs = xmaxs * scr_img.shape[1]
ymaxs = ymaxs * scr_img.shape[0]
out_iou_img = scr_img[(int)(ymins):(int)(ymaxs),(int)(xmins):(int)(xmaxs)]
'''
#实现感兴趣区域ROI的复制粘贴
temp_iou_img = scr_img[0:80,0:200]
scr_img[100:180,100:300] = temp_iou_img
cv2.imwrite(output_file + 'zhantie_{}_{}.jpg'.format(i,objects_num),scr_img)
'''
cv2.imwrite(output_file + '{}_{}.jpg'.format(cut_image_name,objects_num),out_iou_img)
objects_num += 1
if error_id:
continue
print('total_label_len', total_label_len)
def main():
parser = argparse.ArgumentParser(prog='gen_label_list.py')
parser.add_argument('--img-path', type=str, default='E:\\projection\\fair\\data\\smoke', help='test path')
parser.add_argument('--out-path', type=str, default='E:\\projection\\forestout\\', help='*.txt path')
opt = parser.parse_args()
print(opt.img_path, opt.out_path)
convert_dataset(opt.img_path, opt.out_path)
if __name__ == '__main__':
main()
统一图片大小
import os
import io
import math
import sys
import cv2
import shutil
import random
import numpy as np
from collections import namedtuple, OrderedDict
label_names = ['person','car','bus','truck','motorcycle','chemical']
def get_files(dir, suffix):
res = []
for root, directory, files in os.walk(dir):
for filename in files:
name, suf = os.path.splitext(filename)
if suf in suffix:
#res.append(filename)
res.append(os.path.join(root, filename))
return res
def uniform_image_size(list_path,width_size,height_size):
image_list = get_files(list_path, ['.jpg'])
total_len = len(image_list)
print('total_label_len', total_len)
for i in range(0, total_len):
image_file = image_list[i]
img = cv2.imread(image_file)
if img.shape[0] != height_size or img.shape[1] != width_size:
img = cv2.resize(img, (width_size,height_size), interpolation=cv2.INTER_LINEAR)
os.remove(image_file)
cv2.imwrite(image_file, img)
print('img.shape[0]',img.shape[0],'--------',image_file)
random.shuffle(image_list)
def main():
list_path = r'E:\projection\fair\data\genarate_4to1\negative_image\101'
width_size = 1280
height_size = 720
uniform_image_size(list_path,width_size,height_size)
if __name__ == '__main__':
main()
图片打mask
import os
import io
import math
import sys
import cv2
import shutil
import random
import numpy as np
from collections import namedtuple, OrderedDict
label_names = ['person', 'car', 'bus', 'truck', 'motorcycle', 'chemical']
def get_files(dir, suffix):
res = []
for root, directory, files in os.walk(dir):
for filename in files:
name, suf = os.path.splitext(filename)
if suf == suffix:
# res.append(filename)
res.append(os.path.join(root, filename))
return res
def convert_dataset(list_path, save_base_dir):
while True:
width_rate = random.random()
if (width_rate > 0.3 and width_rate < 0.7):
break
else:
continue
while True:
height_rate = random.random()
if (height_rate > 0.3 and height_rate < 0.7):
break
else:
continue
image_list = get_files(list_path, '.jpg')
total_len = len(image_list)
print('total_label_len', total_len)
if not os.path.exists(save_base_dir):
os.makedirs(save_base_dir)
random.shuffle(image_list)
error_count = 0
image_count = 0
for i in range(0, total_len):
image_file = image_list[i]
img = cv2.imread(image_file)
img_h, img_w, img_c = img.shape
print("img: ", img_w, img_h)
img_name, img_type = os.path.splitext(image_file)
_, image_name = os.path.split(img_name)
image_count += 1
img4 = np.full((img_h, img_w, img.shape[2]), 0, dtype=np.uint8)
img4[700:1200, :] = img[700:1200, :]
save_img = save_base_dir + '/' + image_name + str(image_count) + 'preprocess.jpg'
cv2.imwrite(save_img, img4)
def main():
list_path = r'F:\gongye\data\biaozhu\JPEGImages\IMG_3462'
# base_dir = os.getcwd()
save_base_dir = r'F:\gongye\data\biaozhu\JPEGImages\IMG_3462cutmask'
# save_base_dir = os.path.join(save_base_dir, 'r554DergCvk4h00')
convert_dataset(list_path, save_base_dir)
if __name__ == '__main__':
main()
结果如下:

只列举了一些基本的python脚本,拿去用吧.