ES排错命令
GET _cat/indices?v&health=red
GET _cat/indices?v&health=yellow
GET _cat/indices?v&health=green
确定哪些索引有问题,多少索引有问题。_cat API 可以通过返回结果告诉我们这一点

查看有问题的分片以及原因。
这与索引列表有关,但是索引列表只会告诉你哪些索引存在问题,现在还需要我们根据索引列表形成问题列表。
为此我们应该使用如下_cat API:
GET /_cat/shards?v&h=n,index,shard,prirep,state,sto,sc,unassigned.reason,unassigned.details&s=sto,index

只提示一个字段的含义:unassigned.reason 未分配分片的原因,返回值包括:
ALLOCATION_FAILED:由于分片分配失败而未分配。
CLUSTER_RECOVERED:由于集群恢复而未分配。
DANGLING_INDEX_IMPORTED:由于导入了悬空索引导致未分配。
EXISTING_INDEX_RESTORED:由于恢复为已关闭的索引导致未分配。
INDEX_CREATED:由于API创建索引而未分配。
INDEX_REOPENED:由于打开已关闭索引而未分配。
NEW_INDEX_RESTORED:由于恢复到新索引而未分配。
NODE_LEFT:由于托管的节点离开集群而未分配。
REALLOCATED_REPLICA:确定了更好的副本位置,并导致现有副本分配被取消。
REINITIALIZED:当分片从开始移动回初始化,导致未分配。
REPLICA_ADDED:由于显式添加副本而未分配。
REROUTE_CANCELLED:由于显式取消重新路由命令而未分配。
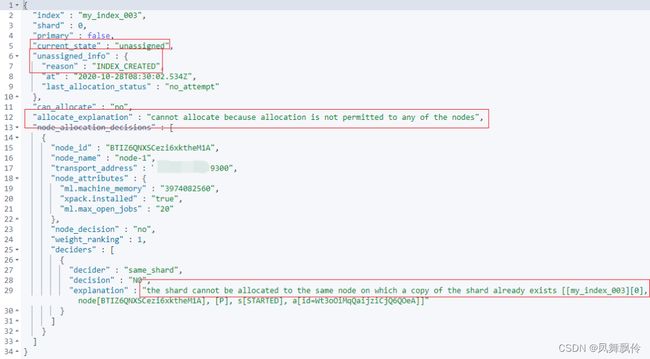
GET /_cluster/allocation/explain
{
"index": "my_index_003",
"shard": 0,
"primary": false
}
以上几个参数都是可选参数。
指定了三个参数:
-
index:索引名称。
-
shard: 分片数。
-
primary: 是否是主分片。
-
POST /_cluster/reroute
{
"commands": [
{
"move": {
"index": "test", "shard": 0,
"from_node": "node1", "to_node": "node2"
}
},
{
"allocate_replica": {
"index": "test", "shard": 1,
"node": "node3"
}
}
]
}手动分配分片,借助 reroute API。
查看文件描述符
GET _nodes/stats/process?filter_path=**.max_file_descriptors 锁定地址空间
为了提高数据访问和操作效率,将进程使用的地址空间锁定在物理内存中,防止交换到swap空间。
1.开启内存锁
修改config/elasticsearch.yml中的bootstrap.memory_lock参数
bootstrap.memory_lock: true
2.检查锁是否开启
输入:
GET _nodes?filter_path=**.mlockall