精华推荐 | 【MySQL技术专题】「主从同步架构」全面详细透析MySQL的三种主从复制(Replication)机制的原理和实战开发(原理+实战)
前提概要
随着应用业务数据不断的增大,应用的响应速度不断下降,在检测过程中我们不难发现大多数的请求都是查询操作。此时,我们可以将数据库扩展成主从复制模式,将读操作和写操作分离开来,多台数据库分摊请求,从而减少单库的访问压力,进而应用得到优化。
复制概述
- Replication复制是指将主数据库的DDL和DML操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
- MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL的主从复制
-
一般在大规模的项目上,都是使用MySQL的复制功能来创建MySQL的主从集群的。
-
主要是可以通过为数据库服务器配置一个或多个备库的方式来进行数据同步。
-
复制的功能不仅有利于构建高性能应用,同时也是高可用、可扩展性、灾难恢复、备份以及数据仓库等工作的基础。
-
通过MySQL的主从复制来实现读写分离,相比单点数据库又读又写来说,提升了业务系统性能,优化了用户体验。
-
另外通过主从复制实现了数据库的高可用,当主节点MySQL挂了的时候,可以用从库来顶上。
MySQL支持三种复制方式
- 基于语句(Statement)的复制(也称为逻辑复制)主要是指,在主数据库上执行的SQL语句,在从数据库上会重复执行一遍。
- 优点:MySQL默认采用的就是这种复制,效率比较高。
主从复制原理
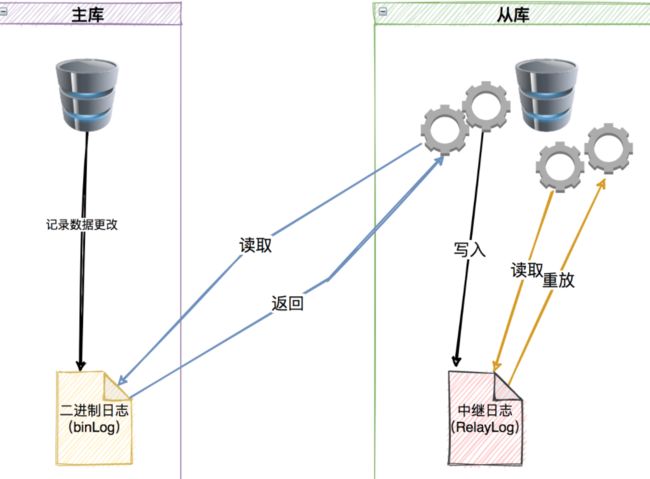
MySQL的复制原理概述上来讲大体可以分为这三步:
- Master主库在事务提交时,会把数据的更新记录作为事件Events记录在二进制日志文件Binlog中。(Dump线程 - 主库线程)
- Master主库推送二进制日志文件Binlog中的日志事件到从库的并且通过写入中继日志Relay Log(I/O线程 - 从库线程)。
- 本质是从库将主库上的日志复制到自己的中继日志(Relay Log)中
- Slave从库 读取且重做(重放)中继日志(Relay Log) 中的事件,将改变反映它自己的数据。(SQL线程 - 从库线程)
下面来详细说一下复制的这三步:
- 第一步:是在主库上记录二进制日志,
- 首先主库要开启binlog日志记录功能,
- 授权Slave从库可以访问的权限。
这里需要注意的一点就是binlog的日志里的顺序是按照事务提交的顺序来记录的而非每条语句的执行顺序。
- 第二步:从库将binLog复制到其本地的RelayLog中。
- 首先从库会启动一个工作线程,称为I/O线程,I/O线程跟主库建立一个普通的客户端连接,
- 然后主库上启动一个特殊的二进制转储(binlog dump)线程,此转储线程会读取binlog中的事件。
- 当追赶上主库后,会进行休眠,直到主库通知有新的更新语句时才继续被唤醒。
这样通过从库上的I/O线程和主库上的binlog dump线程,就将binlog数据传输到从库上的relaylog中了。
-
第三步:从库中启动一个SQL线程,从relaylog中读取事件并在备库中执行,从而实现备库数据的更新。
- 这种复制架构实现了获取事件和重放事件的解耦,运行I/O线程能够独立于SQL线程之外工作。
- 这种架构也限制复制的过程,最重要的一点是在主库上并发运行的操作在备库中只能串行化执行,因为只有一个SQL线程来重放中继日志中的事件。
- 数据或存在延迟和不一致性,所以如果要保证数据的一致性,一定要在主库进行数据操作!
MySQL主从复制模式
MySQL的主从复制其实是支持,异步复制、半同步复制、GTID复制等多种复制模式的。
异步模式
MySQL的默认复制模式就是异步模式,主要是指MySQL的主服务器上的I/O线程,将数据写到binlong中就直接返回给客户端数据更新成功,不考虑数据是否传输到从服务器,以及是否写入到relaylog中。在这种模式下,复制数据其实是有风险的,一旦数据只写到了主库的binlog中还没来得急同步到从库时,就会造成数据的丢失。
- 这种模式确也是效率最高的,因为变更数据的功能都只是在主库中完成就可以了,从库复制数据不会影响到主库的写数据操作。

这种异步复制模式虽然效率高,但是数据丢失的风险很大,所以就有介绍的半同步复制模式。
半同步模式
MySQL从5.5版本开始通过以插件的形式开始支持半同步的主从复制模式,什么是半同步主从复制模式呢?
-
异步复制模式:主库在执行完客户端提交的事务后,只要将执行逻辑写入到binlog后,就立即返回给客户端,并不关心从库是否执行成功,这样就会有一个隐患,就是在主库执行的binlog还没同步到从库时,主库挂了,这个时候从库就就会被强行提升为主库,这个时候就有可能造成数据丢失。
-
同步复制模式:当主库执行完客户端提交的事务后,需要等到所有从库也都执行完这一事务后,才返回给客户端执行成功。因为要等到所有从库都执行完,执行过程中会被阻塞,等待返回结果,所以性能上会有很严重的影响。
-
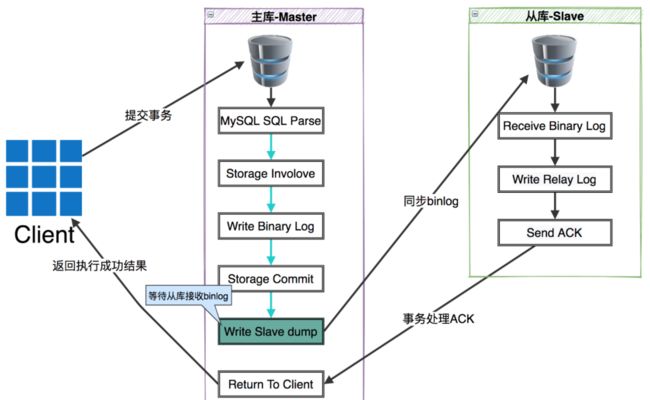
半同步复制模式:半同步复制模式,可以说是介于异步和同步之间的一种复制模式,主库在执行完客户端提交的事务后,要等待至少一个从库接收到binlog并将数据写入到relay log中才返回给客户端成功结果。半同步复制模式,比异步模式提高了数据的可用性,但是也产生了一定的性能延迟,最少要一个TCP/IP连接的往返时间。
- 半同步复制模式,可以很明确的知道,在一个事务提交成功之后,此事务至少会存在于两个地方一个是主库一个是从库中的某一个。
- 在master的dump线程去通知从库时,增加了一个ACK机制,也就是会确认从库是否收到事务的标志码,master的dump线程不但要发送binlog到从库,还有负责接收slave的ACK。当出现异常时,Slave没有ACK事务相应,为了保证性能会那么将自动降级为异步复制,直到异常修复后再自动变为半同步复制。
MySQL半同步复制的流程如下
半同步复制的隐患
半同步复制模式也存在一定的数据风险,当事务在主库提交完后等待从库ACK的过程中,如果Master宕机了,这个时候就会有两种情况的问题。
-
事务还没发送到Slave上:若事务还没发送Slave上,客户端在收到失败结果后,会重新提交事务,因为重新提交的事务是在新的Master上执行的,所以会执行成功,后面若是之前的Master恢复后,会以Slave的身份加入到集群中,这个时候,之前的事务就会被执行两次,
- 第一次是之前此台机器作为Master的时候执行的,
- 第二次是做为Slave后从主库中同步过来的。
-
事务已经同步到Slave上:因为事务已经同步到Slave了,所以当客户端收到失败结果后,再次提交事务,你那么此事务就会再当前Slave机器上执行两次。
-
为了解决上面的隐患,MySQL从5.7版本开始,增加了一种新的半同步方式,新的半同步方式的执行过程是将“Storage Commit”这一步移动到了“Write Slave dump”后面。
-
这样保证了只有Slave的事务ACK后,才提交主库事务。MySQL 5.7.2版本新增了一个参数来进行配置:rpl_semi_sync_master_wait_point,此参数有两个值可配置:
-
AFTER_SYNC:参数值为AFTER_SYNC时,代表采用的是新的半同步复制方式。
-
AFTER_COMMIT:代表采用的是之前的旧方式的半同步复制模式。
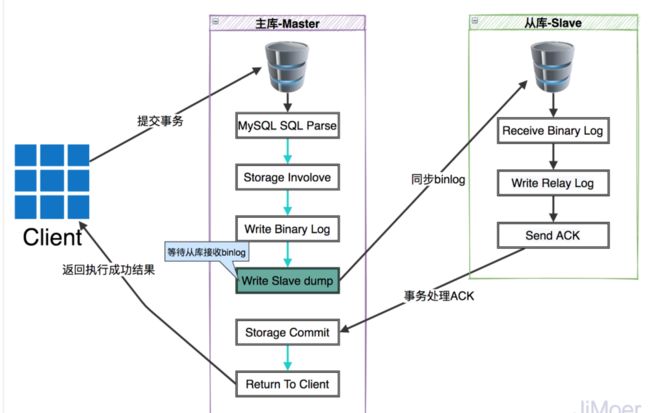
MySQL从5.7.2版本开始,默认的半同步复制方式就是AFTER_SYNC方式了,但是方案不是万能的,因为AFTER_SYNC方式是在事务同步到Slave后才提交主库的事务的,若是当主库等待Slave同步成功的过程中Master挂了,这个Master事务提交就失败了,客户端也收到了事务执行失败的结果了,但是Slave上已经将binLog的内容写到Relay Log里了,这个时候,Slave数据就会多了,但是多了数据一般问题不算严重,多了总比少了好。
半同步复制模式的参数:
mysql> show variables like '%Rpl%';
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
| rpl_stop_slave_timeout | 31536000 |
+-------------------------------------------+------------+
- 半同步复制模式开关: rpl_semi_sync_master_enabled
- rpl_semi_sync_master_timeout:半同步复制,超时时间,单位毫秒,当超过此时间后,自动切换为异步复制模式
MySQL 5.7.3引入的,该变量设置主需要等待多少个slave应答,才能返回给客户端,默认为1。
- rpl_semi_sync_master_wait_for_slave_count:此值代表当前集群中的slave数量是否还能够满足当前配置的半同步复制模式,默认为ON,当不满足半同步复制模式后,全部Slave切换到异步复制,此值也会变为OFF
- rpl_semi_sync_master_wait_no_slave: 代表半同步复制提交事务的方式,5.7.2之后,默认为AFTER_SYNC
- rpl_semi_sync_master_wait_point
GTID模式
MySQL从5.6版本开始推出了GTID复制模式,GTID即全局事务ID (global transaction identifier)的简称,GTID是由UUID+TransactionId组成的,UUID是单个MySQL实例的唯一标识,在第一次启动MySQL实例时会自动生成一个server_uuid, 并且默认写入到数据目录下的auto.cnf(mysql/data/auto.cnf)文件里。TransactionId是该MySQL上执行事务的数量,随着事务数量增加而递增。这样保证了GTID在一组复制中,全局唯一。
这样通过GTID可以清晰的看到,当前事务是从哪个实例上提交的,提交的第多少个事务。
来看一个GTID的具体形式:
mysql> show master status;
+-----------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------+----------+--------------+------------------+-------------------------------------------+
| on.000003 | 187 | | | 76147e28-8086-4f8c-9f98-1cf33d92978d:1-322|
+-----------+----------+--------------+------------------+-------------------------------------------+
1 row in set (0.00 sec)
GTID:76147e28-8086-4f8c-9f98-1cf33d92978d:1-322
UUID:76147e28-8086-4f8c-9f98-1cf33d92978d
TransactionId:1-322
GTID的工作原理
由于GTID在一组主从复制集群中的唯一性,从而保证了每个GTID的事务只在一个MySQL上执行一次。那么是怎么实现这种机制的呢?GTID的原理又是什么样的呢?
- 当从服务器连接主服务器时,把自己执行过的GTID(Executed_Gtid_Set: 即已经执行的事务编码)以及获取到GTID(Retrieved_Gtid_Set: 即从库已经接收到主库的事务编号)都传给主服务器。
- 主服务器会从服务器缺少的GTID以及对应的transactionID都发送给从服务器,让从服务器补全数据。当主服务器宕机时,会找出同步数据最成功的那台conf服务器,直接将它提升为主服务器。
- 若是强制要求某一台不是同步最成功的一台从服务器为主,会先通过change命令到最成功的那台服务器,将GTID进行补全,然后再把强制要求的那台机器提升为主。
主要数据同步机制可以分为这几步:
- master更新数据时,在事务前生产GTID,一同记录到binlog中。
- slave端的i/o线程,将变更的binlog写入到relay log中。
- sql线程从relay log中获取GTID,然后对比Slave端的binlog是否有记录。
- 如果有记录,说明该GTID的事务已经执行,slave会忽略该GTID。
- 如果没有记录,Slave会从relay log中执行该GTID事务,并记录到binlog。
- 在解析过程中,判断是否有主键,如果没有主键就使用二级索引,再没有二级索引就扫描全表。
GTID的优劣势
通过上面的分析我们可以得出GTID的优势是:
- 每一个事务对应一个执行ID,一个GTID在一个服务器上只会执行一次;
- GTID是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置;
- 减少手工干预和降低服务故障时间,当主机挂了之后通过软件从众多的备机中提升一台备机为主机;
GTID的缺点:
- 首先不支持非事务的存储引擎;
- 不支持create table … select 语句复制(主库直接报错);(原理: 会生成两个sql, 一个是DDL创建表SQL, 一个是insert into 插入数据的sql; 由于DDL会导致自动提交, 所以这个sql至少需要两个GTID, 但是GTID模式下, 只能给这个sql生成一个GTID)
- 不允许一个SQL同时更新一个事务引擎表和非事务引擎表;
- 在一个MySQL复制群组中,要求全部开启GTID或关闭GTID。
- 开启GTID需要重启 (mysql5.7除外);
- 开启GTID后,就不再使用原来的传统复制方式(不像半同步复制,半同步复制失败后,可以降级到异步复制);
- 对于create temporary table 和 drop temporary table语句不支持;
- 不支持sql_slave_skip_counter;
开启GTID的必备条件:
MySQL 5.6 版本,在my.cnf文件中添加:
gtid_mode=on (必选) #开启gtid功能
log_bin=log-bin=mysql-bin (必选) #开启binlog二进制日志功能
log-slave-updates=1 (必选) #也可以将1写为on
enforce-gtid-consistency=1 (必选) #也可以将1写为on
MySQL 5.7或更高版本,在my.cnf文件中添加:
gtid_mode=on (必选)
enforce-gtid-consistency=1 (必选)
log_bin=mysql-bin (可选) #高可用切换,最好开启该功能
log-slave-updates=1 (可选) #高可用切换,最好打开该功能
实战搭建步骤(同步模式,其他模式类似知识参数略微不同)
主库操作
- 在master 的配置文件(/usr/my.cnf)中,配置如下内容:
- server-id=1:mysql 服务ID,保证整个集群环境中唯一
- log-bin=/var/lib/mysql/mysqlbin:mysql binlog 日志的存储路径和文件名
- log-bin-index = mysql-bin.index(设置二进制日志索引文件名)
- binlog_format = mixed (binlog的模式)
- STATEMENT:语句复制
- ROW:行复制
- MIXED:混和复制,默认选项
- sync-binlog = 1(是否开启同步方式): 默认为0,为保证不会丢失数据,需设置为1,用于强制每次提交事务时,同步二进制日志到磁盘上。
- character-set-server = utf8(字符串编码)
- log-err:(错误日志,默认已经开启)
- basedir:(mysql的安装目录)
- tmpdir:(mysql的临时目录)
- datadir:mysql的数据存放目录
- read-only=0 是否只读,1 代表只读, 0 代表读写
- binlog-ignore-db=mysql:忽略的数据库, 指不需要同步的数据库(逗号分割)
- binlog-do-db=db01 (指定同步的数据库)
- 执行完毕之后,需要重启Mysql:
service mysql restart;
- 创建同步数据的账户,并且进行授权操作:
grant replication slave on . to ‘itcast’@‘192.168.192.131’ identified by ‘itcast’;
flush privileges;
- 为了获取一个一致性的快照,需对所有表设置读锁:
flush tables with read lock;
- 备份主数据库数据
- 主库可以停机,则直接拷贝所有数据库文件。
- 主库是在线生产库,可采用mysqldump备份数据,它对所有存储引擎均可使用。
针对事务性引擎-mysqldump
mysqldump -uroot -ptiger --all-database -e --single-transaction --flush-logs --max_allowed_packet=1048576 --net_buffer_length=16384 > /data/all_db.sql
针对 MyISAM 引擎,或多引擎混合的数据库-mysqldump
mysqldump -uroot --all-database -e -l --flush-logs --max_allowed_packet=1048576 --net_buffer_length=16384 > /data/all_db.sql
主从数据库都是数据都是一致的,直接执行 show master status 查看日志坐标。
show master status;

字段含义:
- File : 从哪个日志文件开始推送日志文件
- Position : 从哪个位置开始推送日志
- Binlog_Ignore_DB : 指定不需要同步的数据库
- 恢复主库的写操作:
unlock tables;
从库操作
- 导入备份数据
mysql -uroot -p < /data/all_db.sql
在从库端配置文件中,配置如下内容:
- mysql服务端ID,唯一
- server-id=2
- 指定binlog日志
- log-bin=/var/lib/mysql/mysqlbin
其他配置
- binlog_format = mixed
- log-slave-updates = 0(控制 slave 上的更新是否写入二进制日志,默认为0;若 slave 只作为从服务器,则不必启用;若 slave 作为其他服务器的 master,则需启用,启用时需和 log-bin、binlog-format 一起使用,这样 slave 从主库读取日志并重做,然后记录到自己的二进制日志中;)
- relay-log = mysql-relay-bin(设置中继日志文件基本名)
- relay-log-index = mysql-relay-bin.index(设置中继日志索引文件名)
- read-only = 1(设置 slave 为只读,但具有super权限的用户仍然可写)
- slave_net_timeout = 10(设置网络超时时间,即多长时间测试一下主从是否连接,默认为3600秒,即1小时,这个值在生产环境过大,我们将其修改为10秒,即若主从中断10秒,则触发重新连接动作。)
- 执行完毕之后,需要重启Mysql:
service mysql restart;
- 执行如下指令 :
change master to master_host='192.168.2.21', master_user='repl', master_password='repl',master_port=3306,
master_log_file='mysql-bin.000001',master_log_pos=120;
指定当前从库对应的主库的IP地址,用户名,密码,从哪个日志文件开始的那个位置开始同步推送日志。
- 开启同步操作
start slave;
show slave status;
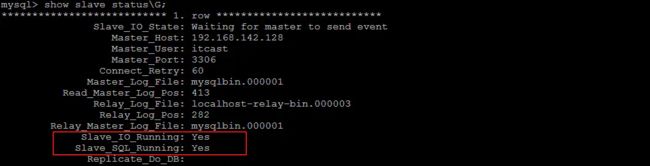
可以看到图中显示出来的:IO线程和SQL线程都处于运行状态:
- Slave_IO_Running:此进程负责 slave 从 master 上读取 binlog 日志,并写入 slave 上的中继日志。
- Slave_SQL_Running:此进程负责读取并执行中继日志中的 binlog 日志。
这两个进程的状态需全部为 YES,只要有一个为 NO,则复制就会停止。当 Relay_Master_Log_File = Master_Log_File 且 Read_Master_Log_Pos = Exec_Master_Log_Pos 时,则表明 slave 和 master 处于完全同步的状态。
- 停止同步操作
stop slave;
验证同步操作
- 在主库中创建数据库,创建表,并插入数据 :
create database db01;
user db01;
create table user
(
id int(11) not null auto_increment,
name varchar(50) not null,
sex varchar(1),
primary key (id)
) engine = innodb
default charset = utf8;
insert into user(id, name, sex)
values (null, 'Tom', '1');
insert into user(id, name, sex)
values (null, 'Trigger', '0');
insert into user(id, name, sex)
values (null, 'Dawn', '1');
- 在从库中查询数据,进行验证 :
-
在从库中,可以查看到刚才创建的数据库:

-
在该数据库中,查询user表中的数据:
