JUC并发编程 05——volatile
一.volatile的前世今生
Java语言规范中对 volatile的定义如下:
Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排他锁单独获得这个变量。Java语言提供了volatile,在某些情况下比锁要更加方便。如果一个字段被声明成volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的。
这句话该怎么理解呢?别急,为了更好的理解这个概念,我们需要先来学习下与之相关的 CPU 概念。

volatile是如何来保证可见性的呢?当对volatile变量进行写操作时,jvm在多核处理器下会做两件事:
- 将当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效
为了弥补越来越快的 CPU 与 内存 之间的速度差距,CPU引入了多级缓存(L1,L2,L3或其他)。也就是说处理器是不直接与内存交互的,而是先将系统内存中的数据读到 CPU 缓存后再进行操作,但是操作何时写到内存是不确定的。这个时候就展现出 volatile 的强大了,JVM 实现了当对 volatile 变量进行写操作时,JVM会向处理器发送一条Lock前缀的指令,将这个变量所在的CPU缓存行数据写到内存。
经过上面的步骤,虽然每次对 volatile 的写操作会立即写到内存,但是好像还缺了点什么?
是的,就算上面的步骤已经写回到主存,但是其他处理的缓存行还是旧的呀,依然会出并发的bug。所以在多处理器下,为了保证各个处理器的缓存是一致的,就实现了缓存的一致性性协议。每个处理器通过嗅探在总线上传播的数据来检查自己的缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改时,就会将当前处理器的缓存的缓存行设置为无效。
这样就实现了 volatile 修饰的变量,在写操作时保证多处理器下的数据可见性。
二.volatile的表象是什么
要理解 voaltile 特性,一个非常好的方法就是将对 volatile 变量的 单个 读或者写,看成是使用同一个锁对这些单个的读写操作做了同步。
我们看一组代码

假设有多个线程分别调用上面程序的3个方法,这个程序在语义上和下面程序等价。
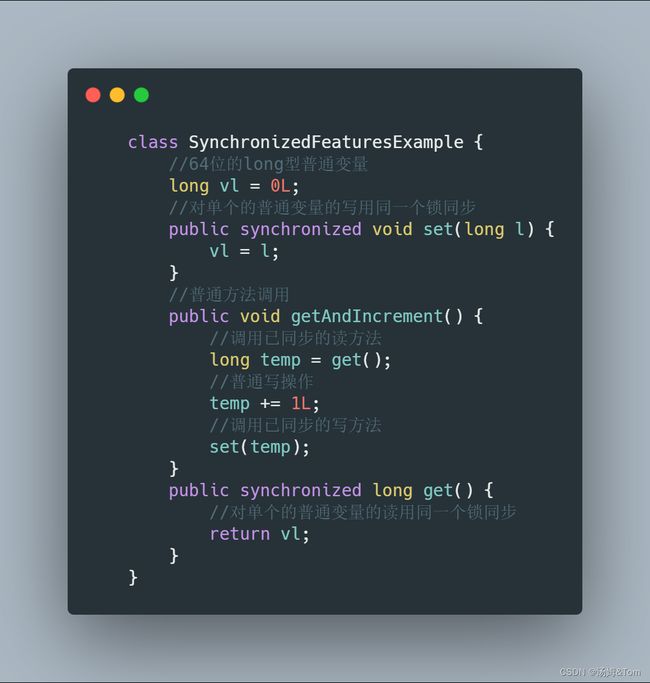
通过上面的代码,我们可以看到对 volatile 修饰的共享变量做单个读写操作时,是和加锁效果一样的,也就意味着对一个volatile变量的读总是能看到对它的最后一次写入。需要注意的是,如果是多个 voaltile 操作或者类似 volatile++ 这种操作是无法保证整体操作的原子性的。
总结下,volatile修饰的变量具有这两个特性:
- 可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写 入。
- 原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不 具有原子性。
看了表象后,你肯定会问,那么具体voaltile到底是如何保证对单个变量的单步操作实现可见性和原子性的呢?我们一起看下JMM是如何保证的。
三.volatile的内存语义及实现
- volatile写的内存语义:当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存。
- volatile读的内存语义:当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
其实就是禁用CPU缓存。例如,我们声明一个 volatile 变量 volatile int x = 0,它表达的是:告诉编译器,对这个变量的读写,不能使用 CPU 缓存,必须从内存中读取或者写入。
为了实现volatile内存语义,JMM会分别限制编译器重排序和处理器重排序。
下面这个表格就是JMM针对编译器制定的volatile重排序规则表:

举例来说,第三行最后一个单元格的意思是:在程序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。

为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。

JSR-133增强了volatile的内存语义
我们先看一段代码:

直觉上看,应该是 42,那实际应该是多少呢?这个要看 Java 的版本,如果在低于 1.5 版本上运行,x 可能是 42,也有可能是 0;如果在 1.5 以上的版本上运行,x 就是等于 42。
分析一下:在JSR-133之前的旧Java内存模型中,虽然不允许volatile变量之间重排序,但允许volatile变量与普通变量重排序。
也就是说在旧的内存模型中,线程A在执行 1. x=42 2. v=true 时,由于1和2之间没有数据依赖关系,所以可能被重排序,所以可能导致在线程B执行到v==true后,x可能并没有执行,就看到x值为0;
因此,在旧的内存模型中,volatile的写-读,没有锁的释放-获取所具有的内存语义。为了提供一种比锁更轻量级的线程之间通信的机制,JSR-133专家组决定增强volatile的内存语义。怎么增强的呢?
从编译器重排序规则和处理器内存屏障插入策略来看,只要volatile变量与普通变量之间的重排序可能会破坏volatile的内存语义,这种重排序就会被编译器重排序规则和处理器内存屏障插入策略禁止。
双重校验锁实现对象单例(线程安全):
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
uniqueInstance 采用 volatile 关键字修饰也是很有必要的
原文链接:并发编程 3:谈谈你对volatile关键字的了解 (qq.com)