图像融合论文阅读:DDcGAN: 一种用于多分辨率图像融合的双鉴别器条件生成对抗网络
@article{ma2020ddcgan,
title={DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion},
author={Ma, Jiayi and Xu, Han and Jiang, Junjun and Mei, Xiaoguang and Zhang, Xiao-Ping},
journal={IEEE Transactions on Image Processing},
volume={29},
pages={4980–4995},
year={2020},
publisher={IEEE}
}
SCI A1; IF 10.6
[论文下载地址]
[代码下载地址]
文章目录
- 论文解读
-
- 关键词
- 核心思想
-
- 思想核心
- 思想扩展
- 网络结构
-
- 红外与可见光
-
- 生成器
- 判别器
- PET和MRI
- 损失函数
-
- 红外与可见光
-
- 生成器损失
- 判别器损失
- 医学图像
- 数据集
- 训练设置
- 实验
-
- 评价指标
- Baseline
- 实验结果
- 传送门
-
- 图像融合相关论文阅读笔记
- 图像融合论文baseline总结
- 其他论文
- 其他总结
- ✨精品文章总结
论文解读
关键词
Image fusion, generative adversarial network, infrared image, medical image, different resolutions.
图像融合,生成对抗网络,红外图像,医学图像,不同分辨率
核心思想
思想核心
作者提出了双判别器条件生成对抗网络(dual-discriminator conditional generative adversarial network (DDcGAN))。该网络是一个端到端的模型,也可以融合不同分辨率的源图像。
该模型使用了【一个生成器和两个判别器】
- 生成器用于生成融合图像
- 两个判别器分别用于区分融合图像和两个源图像的结构差异和内容损失
在融合不同分辨率图像的方面,作者并没有对低分辨率图像上采样,而是使用【反卷积层】学习低分辨率到高分辨率的映射关系。
思想扩展
DDcGAN和FusionGAN出自同一个人,FusionGAN比这篇论文早一年,两篇核心思想很相似,有兴趣的同学可以移步至:
[FusionGAN: A generative adversarial network for infrared and visible image fusion]
此外,这篇论文的初稿也在上一年(2019年)发布过:
@inproceedings{xu2019learning,
title={Learning a Generative Model for Fusing Infrared and Visible Images via Conditional Generative Adversarial Network with Dual Discriminators.},
author={Xu, Han and Liang, Pengwei and Yu, Wei and Jiang, Junjun and Ma, Jiayi},
booktitle={IJCAI},
pages={3954–3960},
year={2019}
}
[初稿论文地址]
相关知识
[一文看懂「生成对抗网络 - GAN」基本原理+10种典型算法+13种应用]
[什么是图像融合?(一看就通,通俗易懂)]
网络结构
红外与可见光

作者首先假设可见光图像v的分辨率是红外图像i的4×4倍,如上图所示。
【生成器G的目的】是使用可见光图像v和红外图像i来生成具有足够真实感和信息量的融合图像G(v,i)来欺骗判别器。
判别器 D v D_v Dv用于将鉴别可见光图像和生成图像。
判别器 D i D_i Di用于将鉴别原始低分辨率红外图像和下采样的生成(融合)图像。
下采样的方式采用平均池化,为什么不用最大池化呢?因为平均池化相比于最大池化,可以更好的保留低频信息,而热辐射信息正是低频信息。
为了平衡生成器和判别器之间的关系,除了判别器的输入外,作者没有将源图像v或者i作为 D v D_v Dv或 D i D_i Di的额外添加信息。即每个判别器的输入是单通道的采样图像或源图像而不是包含了采样图片和对应源图像的双通道。因为一旦同时输入采样图像和源图像,判别器会偷懒,认为自己的任务是判断两个图像是否相同,这是一个很简单的任务。如果这件事发生了,对抗关系无法成立,生成器G生成的图像根本不能欺骗判别器D,生成器也就开始摆烂了,更倾向于随机生成图像而不是想办法好好融合图像。
因此,【生成器G的目标】【最小化下式】:

ψ是下采样算子,由两个平均池化层组成,3×3的卷积核,步长为2。
相反的,【判别器D的目标】是【最大化上式】。
生成器
生成器由两个反卷积层,一个编码器和一个解码器组成,如下图所示。
因为红外图像分辨率较低,因此在编码之前引入了【反卷积层】用来【学习】从【低分辨率到高分辨率】的【映射关系】。反卷积层的输出是一个高分辨率的特征图,而不是简单插值上采样的图像。
可见光图像也输入反卷积层,同上。
将两个高分辨率特征图concat到一起,作为编码器的输入。特征提取和融合均在编码器内完成,因此编码器的输出为融合的特征图。将融合特征图作为解码器的输入用于重建,输出结果为与可见光图像相同的融合图像。

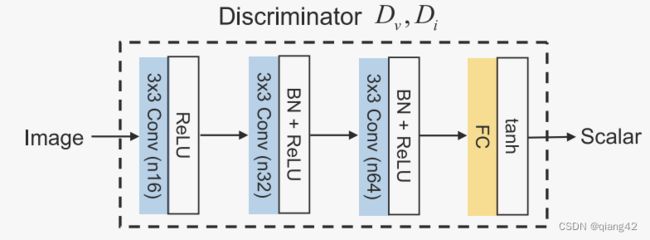
判别器
PET和MRI
下图的上采样使用的是双三次插值(bicubic interpolation)
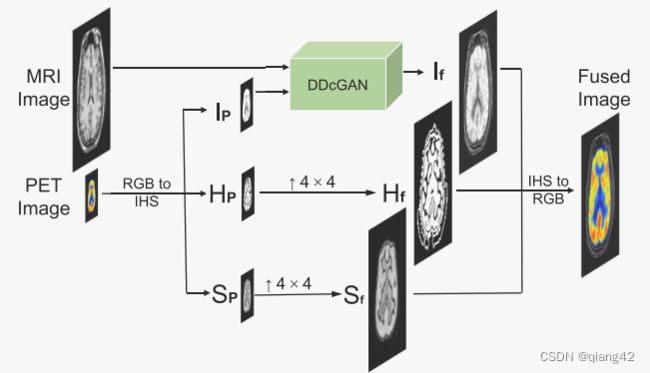
PET和MRI的相关知识大家可以自行搜索,在这里只需要记住:
- PET是低分辨率的伪彩色图像
- MRI是高分辨率的多通道图像
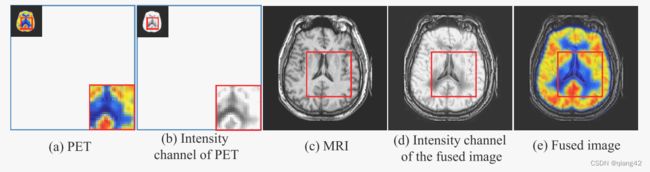
作者提出的方法是将RGB的PET图像变成【强度、色调和饱和度】图像(intensity, hue and saturation,【IHS】)
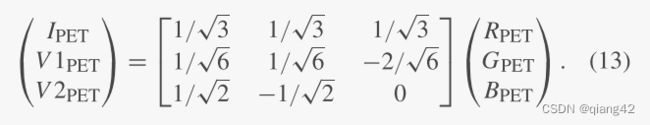

结果可以使用下面的式子转换回去,即IHV到RGB:


PET和MRI的关系可以参考下图,图片来源
损失函数
红外与可见光
生成器损失
生成器损失由【对抗性损失 L G a d c \mathcal L_G^adc LGadc】和【内容损失 L c o n \mathcal L_{con} Lcon】组成。如下式所示:
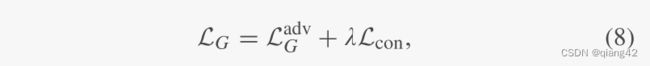
λ \lambda λ是控制平衡的参数,作者在本文设置为0.5。
对抗性损失 L G a d c \mathcal L_G^adc LGadc来自于判别器D,公式如下:
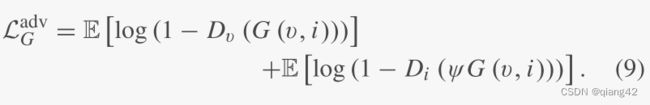
内容损失 L c o n \mathcal L_{con} Lcon如下所示:

- 第一项为下采样的生成图像和红外图像的像素强度约束, ∣ ∣ ⋅ ∣ ∣ F ||·||_F ∣∣⋅∣∣F是Frobenius范数,即矩阵所有对应元素的平方和再开方。
- 第二项中, η \eta η为平衡关系的参数,本文为1.2。
∣ ∣ ⋅ ∣ ∣ T V ||·||_{TV} ∣∣⋅∣∣TV是TV范式,所谓TV不是电视,而是Total Variation,全变分。
作者认为TV范式相比于0范式,可以有效解决[不确定性多项式时间问题(non-deterministic polynomial-time)]
(TV项用在图像复原和去噪中的作用就是保持图像的光滑性,消除图像复原可能带来的伪影。缺陷在于会使得复原的图像过于光滑,在一些细节比较多的图像中会使得复原后的图像丢失细节。)
参考资料
[弗罗贝尼乌斯范数(Frobenius norm)]
[Frobenius norm(Frobenius 范数)]
[如何理解全变分(Total Variation,TV)模型?]
[非确定性多项式时间-百度百科]
判别器损失
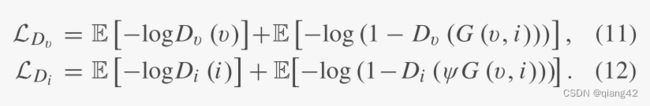
判别器的对抗损失可以计算分布之间的JS发散度,从而识别强度或者纹理信息是否真实,鼓励生成与真实分布相似的分布。
(JS 散度度量了两个概率分布的相似度)
参考链接
[KL散度、JS散度、Wasserstein距离]
[GAN:两者分布不重合JS散度为log2的数学证明]
医学图像
可以看到,和之前介绍的基本一样
![]()



数据集
- VIF:从TNO中选36对图像,裁剪成27264对84×84的图像,将红外图像下采样至21×21。
- MED:从Harvard中选256×256的PET和MRI图像,PET图像每个通道均下采样至64×64。83对PET和MRI下采样并i裁剪成为9984对84×84的MRI以及PET强度大小为21×21的图像对。
图像融合数据集参考链接
[图像融合常用数据集整理]
训练设置

实验
评价指标
- entropy (EN)熵
- mean gradient (MG)平均梯度
- spatial frequency(SF)空间频率
- standard deviation (SD)标准差
- peak signal-to-noise ratio (PSNR)峰值信噪比
- correlation coefficient (CC)相关系数
- structural similarity index measure (SSIM)结构相似性指数
- visual information fidelity(VIF)视觉保真度
参考资料
[图像融合定量指标分析]
Baseline
- directional discrete cosine transform and principal component analysis (DDCTPCA)
- hybrid multi-scale decomposition (HMSD)
- fourth-order partial differential equations (FPDE)
- gradient transfer fusion(GTF)
- different resolution total variation (DRTV)
- DenseFuse
- FusionGAN
参考资料
[图像融合论文baseline及其网络模型]
实验结果


更多实验结果及分析可以查看原文:
[论文下载地址]
[代码下载地址]
传送门
图像融合相关论文阅读笔记
[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
[FusionGAN: A generative adversarial network for infrared and visible image fusion]
[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
[Visible and Infrared Image Fusion Using Deep Learning]
[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
[U2Fusion: A Unified Unsupervised Image Fusion Network]
图像融合论文baseline总结
[图像融合论文baseline及其网络模型]
其他论文
[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
其他总结
[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
如有疑问可联系:[email protected];
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~