Python修改Excel中某一列的值
修改Excel中某一列的值
一、背景
在日常处理数据时,常常会遇到excel中数据进行批量修改,而这些数据往往是没规律的,但是站在python的角度,他们又是有规律的。我在尝试开发抽奖系统的时候,想要展示给读者们更为详细的资料,但是又想保护名单中的人物,于是我想要批量更改excel中姓名中的其中一个字来实现。通过excel自身的功能,我并没有找到可以简便修改的方式,一想到本身就在学习,不如拿起python这个工具来解决。于是有了下面的方式:
二、代码实现(以切片方式为例,文章结尾附上另一种方式实现)
1、代码展示
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx'
data = pd.read_excel(file_path, header=0) #读取文件内容
for i in range(0, len(data.to_dict()['姓名'])):
temp = data.to_dict()['姓名'][i][0] + '小' + data.to_dict()['姓名'][i][2:]
data.loc[i, '姓名'] = temp
data.to_excel(file_path, index=False)
运行结果:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\CSDN_Demo\pyqt5\0626.py
孙小雪
张小超
........
王小鹏
兰小
佟小阁
Process finished with exit code 0
2、代码解析
1)panda函数
panda是核心数据分析支持库,提供快速、灵活、明确的数据结构。具体详细可查看panda的中文说明进行详细了解:https://www.pypandas.cn/docs/getting_starte。
import pandas as pd
2)read_excel方法
read_excel是将excel文件读取到pandas DataFrame中,dataframe 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
①文件路径

②文件内容
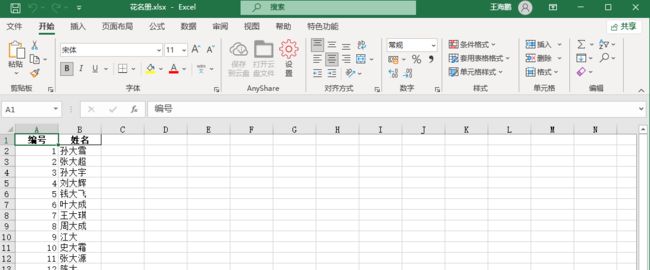
③通过read_excel获取文件内容
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx' #文件路径
data = pd.read_excel(file_path, header=0) #header=0 指从第一行开始读取数据(id=0)
print(data)
运行结果:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\CSDN_Demo\pyqt5\0626.py
编号 姓名
0 1 孙大雪
1 2 张大超
2 3 孙大宇
3 4 刘大辉
4 5 钱大飞
.. .. ...
59 60 何大彤
60 61 刘大鸿
61 62 王大鹏
62 63 兰大
63 64 佟大阁
[64 rows x 2 columns]
Process finished with exit code 0
这样得到的data数据格式为
3)data.to_dict()方法
上面我们通过read_excel将数据取出来,但是我想对数据处理,上面的数据格式我并不了解,于是将数据格式转化为我们熟悉的格式:字典,来帮助我们进行下一步操作:
①代码实现
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx'
data = pd.read_excel(file_path, header=0)
print(data.to_dict())
print(type(data.to_dict()))
运行结果:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\CSDN_Demo\pyqt5\0626.py
{'编号': {0: 1, 1: 2, 2: 3, 3: 4, 4: 5, 5: 6, 6: 7, 7: 8, 8: 9, 9: 10, 10: 11, 11: 12, 12: 13, 13: 14, 14: 15, 15: 16, 16: 17, 17: 18, 18: 19, 19: 20, 20: 21, 21: 22, 22: 23, 23: 24, 24: 25, 25: 26, 26: 27, 27: 28, 28: 29, 29: 30, 30: 31, 31: 32, 32: 33, 33: 34, 34: 35, 35: 36, 36: 37, 37: 38, 38: 39, 39: 40, 40: 41, 41: 42, 42: 43, 43: 44, 44: 45, 45: 46, 46: 47, 47: 48, 48: 49, 49: 50, 50: 51, 51: 52, 52: 53, 53: 54, 54: 55, 55: 56, 56: 57, 57: 58, 58: 59, 59: 60, 60: 61, 61: 62, 62: 63, 63: 64}, '姓名': {0: '孙大雪', 1: '张大超', 2: '孙大宇', 3: '刘大辉', 4: '钱大飞', 5: '叶大成', 6: '王大琪', 7: '周大成', 8: '江大', 9: '史大霜', 10: '张大源', 11: '陈大', 12: '范大俊', 13: '邹大文', 14: '郭大阳', 15: '李大齐', 16: '高大阳', 17: '贾大烨', 18: '贺大玉', 19: '杨大如', 20: '刘大春', 21: '姜大兆', 22: '鄂大东', 23: '刘大', 24: '李大宇', 25: '荣大惠', 26: '杜大萌', 27: '李大', 28: '郑大阡', 29: '谭大', 30: '贾大丽', 31: '荀大', 32: '郑大希', 33: '黄大然', 34: '岳大明', 35: '陶大岩', 36: '王大', 37: '王大旭', 38: '李大儒', 39: '汤大芸', 40: '文大', 41: '李大鹏', 42: '葛大杰', 43: '胡大鉴', 44: '蒋大帆', 45: '曾大杰', 46: '陈大文', 47: '陈大宇', 48: '张大铭', 49: '上大裕博', 50: '何大豪', 51: '张大洳', 52: '杨大淇', 53: '黄大', 54: '张大杰', 55: '李大洋', 56: '何大璐', 57: '谭大大', 58: '张大初', 59: '何大彤', 60: '刘大鸿', 61: '王大鹏', 62: '兰大', 63: '佟大阁'}}
<class 'dict'>
Process finished with exit code 0
②数据应用
既然我们把数据转换为了字典类型,那我们尝试通过字典的方式将数据提取出来:
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx'
data = pd.read_excel(file_path, header=0)
print(data.to_dict()['姓名'][1]) #在这里加上了两个索引['姓名'][1],前面是将姓名这列提取出来,后面的索引是具体到第几个名字。
print(type(data.to_dict()))
运行结果:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\CSDN_Demo\pyqt5\0626.py
张大超
<class 'dict'>
Process finished with exit code 0
4)字符串替换
在这里我采用的是切片的方式,进行指定位置的字符更换,当然还有其他方法进行处理,具体可参考此文章:解决:TypeError: ‘str’ object does not support item assignment 的问题。
5)data.loc[rows,columns]
data.loc[i, '姓名']代表索引行与列,获取到具体的值后就可以进行处理。
当然不采用data.loc[i, '姓名']也可以,直接利用上面的一样可以实现:data.to_dict()['姓名'][i],秉持着学习过程中掌握越多知识越好的原则,在这里我就采用data.loc[i, '姓名']的方式了。
①代码示例
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx'
data = pd.read_excel(file_path, header=0)
print(data.to_dict()['姓名'][1])
data.loc[1, '姓名']='张小超'
print(data.to_dict()['姓名'][1])
运行结果:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\CSDN_Demo\pyqt5\0626.py
张大超
张小超
Process finished with exit code 0
6)to_excel()方法
上面讲了读入文件内容,那么当我们修改完数据后,也是需要将修改后的数据写入文件中,这样才能实现我们的目的。
to_excel():将数据从dataframe导出到excel中
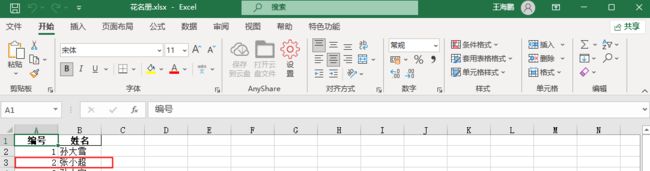
①原文件内容

②代码示例
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx'
data = pd.read_excel(file_path, header=0)
print(data.to_dict()['姓名'][1])
data.loc[1, '姓名']='张小超'
data.to_excel(file_path, index=False) #index代表不需要写入索引
print(data.to_dict()['姓名'][1])
运行结果:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\CSDN_Demo\pyqt5\0626.py
张大超
张小超
Process finished with exit code 0
index=True时结果如下:

③更改后的文件内容
3、总结
通过上面的分步解析,想必大家对上面的代码有了更清晰的了解,接下来我们实际运行一下。
1)代码附上
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx'
data = pd.read_excel(file_path, header=0)
for i in range(0, len(data.to_dict()['姓名'])): #len(data.to_dict()['姓名'] 获取行数,遍历每一个姓名
temp = data.to_dict()['姓名'][i][0] + '小' + data.to_dict()['姓名'][i][2:] #data.to_dict()['姓名'][i][0]:['姓名']代表获取姓名这列,[i]代表获取的具体单一姓名,[0]代表姓名的第一个字,[2:]代表从第二个字开始到最后
data.loc[i, '姓名'] = temp
data.to_dict()['姓名'][i]= temp
data.to_excel(file_path, index=False)
2)运行结果展示
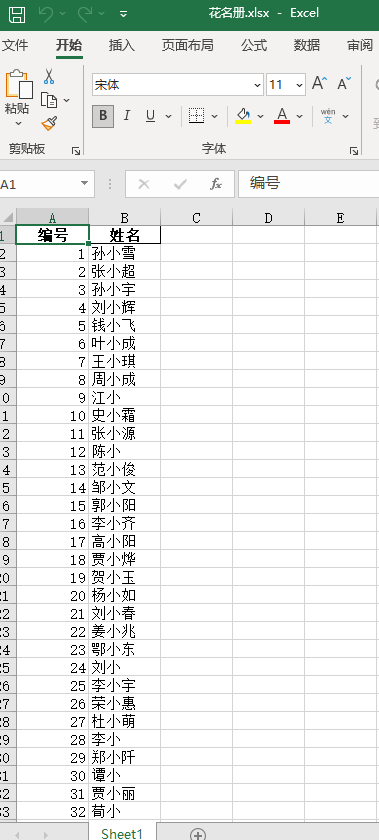
三、附录
在这里给大家贴上另一种方式,仅供大家参考:
import pandas as pd
file_path = 'D:\CSDN\花名册.xlsx'
data = pd.read_excel(file_path, header=0)
for i in range(0, len(data.to_dict()['姓名'])):
middle = data.to_dict()['姓名'][i][1]
temp = data.to_dict()['姓名'][i]
temp = temp.replace(middle, '大')
data.loc[i, '姓名'] = temp
print(temp)
data.to_excel(file_path, index=False)
四、结论
举一反三往往会让我们收获更多的知识,在学习的路上不要嫌弃麻烦,知识的汲取需要点滴实现。加油!