漫话Kubernetes的网络架构,该用NodePort还是Ingress还是load balancer?
目录
一、基本概念
1. Kubernetes pod
2. Kubernetes service
3. Kubernetes NodePort
4. Kubernets Ingress
5. Kubernetes loadbalancer
二、从实际需求谈Kubernetes引入的各种网络概念
问题No 1:NodePort和Ingress好像实现原理差不多,有了NodePort为啥还整出个Ingress,既生瑜何生亮么?
问题No 2: 通过NodePort和Ingress已经可以实现从k8s集群外部访问k8s集群内部pod提供的服务,为啥还要在k8s集群前边放置一个传统的LB?
问题No 3: 再看一眼操蛋的service, 他真的有必要存在么?没有他不可以么?
要说清楚Kubernetes的网络架构,需要对计算机网络有比较深入的理解,至少是实战的CCNA or CCNP level的网络工程师,并且要对现代Linux所具备的各种网络功能非常理解才能彻底搞清楚底层实现细节,比如Linux的birdge, firewall (iptable), router/NAT等等功能。
现代Linux操作系统已经远远不是一个传统的单一操作系统,他集成了操作系统,交换机,路由器,防火墙等等很多功能。由于虚拟机、容器技术的发展,很多在传统网络设备中才有的功能,比如switch/route/firwall等等,都被移植到了单个Linux server中,做为Linux的一个一个模块单元。这样一个运行Linux操作系统的物理主机,如果开启虚拟化或容器功能,那就相当于传统的由多个物理主机 + 多个网络设备(交换机 + 路由器 + 防火墙)共同组成的环境。这种转变是由vmware, redhat, openstack, docker, kubernetes等等厂家和开源社区根据虚拟化/容器化技术逐渐演进,秉持节省成本,由软件代替专有网络设备、减少网络硬件设备支出的理念而产生的,这也是随着各种虚拟化,容器化和云技术逐步发展自然而然产生的结果。
本文不打算从底层的网络实现细节介绍Linux的交换、路由、防火墙功能,也不打算介绍Kubernetes实现的各种网络功能是如何由Linux的各种网络模块来支撑的,而是从最上层、最基本的、现实的业务组网需求来逐一介绍Kubernetes的基本网络相关的概念。
如果想了解kubernetes底层网络实现,大家可以参考以下这篇文章,写的非常好:
https://blog.csdn.net/gui951753/article/details/87387197
Kubernetes底层网络实现有多种方式可选,上面这篇文章介绍了其中比较流行的一种方式 -- flannel插件。什么?Kubernetes的底层网络要以插件的方式来实现?没错,这就是k8s设计牛B的的地方之一。底层网络可以采用任何我们见过的已有的、成熟的SDN(Software Defined Network)网络技术来稍加改造,以插件方式部署到k8s集群中。当然这些网络插件也还是建立在Linux操作系统的交换、路由、防火墙功能模块之上。具体有那些网络插件,大家可以参考如下官方文档:
https://kubernetes.io/zh/docs/concepts/cluster-administration/networking/
另外,想补充的是云原生计算基金会 (CNCF -- Cloud Native Computing Foundation) 最近宣布由灵雀云公司开源的容器网络项目Kube-OVN 正式进入 CNCF 沙箱(Sandbox)托管。这是全球范围内首个被CNCF纳入托管的开源CNI网络项目,也是国内容器公司首次将独立设计研发的项目成功贡献进入CNCF基金会。
Kube-OVN是灵雀云公司开源的基于OVN的Kubernetes网络组件Kube-OVN,提供了大量目前Kubernetes不具备的网络功能,并在原有基础上进行增强。通过将OpenStack领域成熟的网络功能平移到Kubernetes,来应对更加复杂的基础环境和应用合规性要求。
Kube-OVN主要具备五大主要功能:Namespace 和子网的绑定,以及子网间访问控制,静态IP分配,动态QoS,分布式和集中式网关,内嵌 LoadBalancer。将OpenStack社区的网络功能向Kubernetes平移,从而弥补Kubernetes网络的不足,打造更加完整的网络体系。
说了这么多,其实想说的是,k8s尽管已经出现有些时间了,但是网络这一块儿还是处于百家争鸣、不断变更,急速发展之中。
本文演示环境的k8s集群, 网络插件就是使用的flannel,是相对来说最简单、最易用的一个插件。
我们先来介绍k8s的一些基本概念(这些基本概念不做详细介绍,具体可以参考相关文档),然后从具体业务组网需求来介绍Kubernetes为什么会出现这些网络概念,或者为什么要支持这些网络功能。
一、基本概念
在介绍基本概念之前,为了后边行文简化,介绍几个约定的术语:
k8s: 指kubernetes, k根s之间正好是8个字母。
node: 一个node这里转指一个k8s集群中的主机。在k8s集群中,有master node(上边只部署k8s管理组件)和work node(上边可以运行用户自己创建的pod)
k8s集群:一个k8s集群由多个node组成。
k8s集群外部主机: 没有加入k8s集群的主机,不管是不是根k8s集群主机在同一个网段内,都叫k8s集群外部主机。
LB:Load Balancer - 复杂均衡器的简写。
1. Kubernetes pod
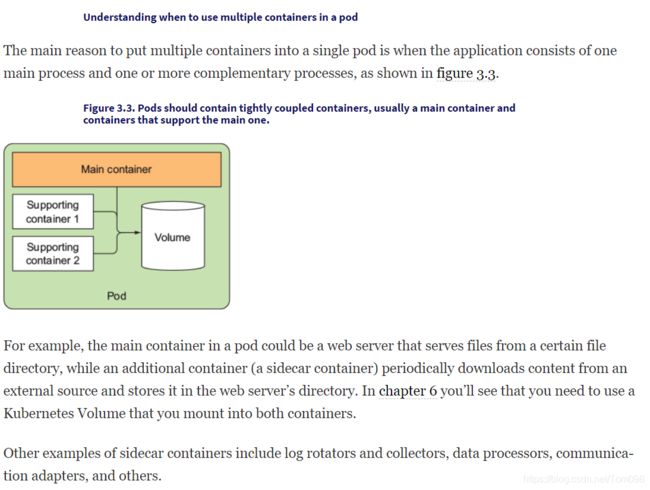
在kubernetes中, pod是最小的管理单元,在采用docker容器化技术的kubernetes环境中,一个pod可以包含一个和多个docker容器。但是一个pod只有一个network namespace,当一个pod有多个docker container(容器)时,这些docker container共享一个network namespace。简单说,就是这些同属一个pod的docker container共享相同的网络环境- 共同的网卡、IP、hostname、路由、网络协议栈等等。如果感觉理解困难,不知道什么时network namespace,可以暂时不考虑那么多,就认为这些同属于一个pod的docker container,就相当于功能属于一个主机,有共同主机名和IP等,但是他们除了网络,对内存、cpu的访问又是隔离的,不会因为一个container里的应用内存泄漏(OOM - Out Of Memory),或者High CPU,而导致其他container的应用受影响。同时各个container还会拥有自己的文件系统 - 对, 文件系统也是隔离的。轻易不要把多个container放到一个pod中,只有极个别情况才需要这样做。这一点<
2. Kubernetes service机制
简单说,一个k8s service就是由一组后端的、运行同样应用的pod共同提供的服务。为什么是一组,当然是为了提高高可用性和吞吐量。然而客户端访问不是直接访问这一组pod的每一个IP,这样一个一个指定太麻烦了,而且一旦某个pod发生故障在其他node重启,IP地址变更,客户端也需要随着更改。所以就需要为这一组pod提供的服务指定一个共同的位于前端IP。这个IP叫Cluster IP,或者Service IP。客户端(Client)将请求直接发给Service的ClusterIP,然后由这个ClusterIP所代表的service 对象再转发给后端的分布在不同的pod上,比如下图的pod1, pod2, pod3。为了简化,下图中没有标出pod1, pod2, pod3分别所处的node。
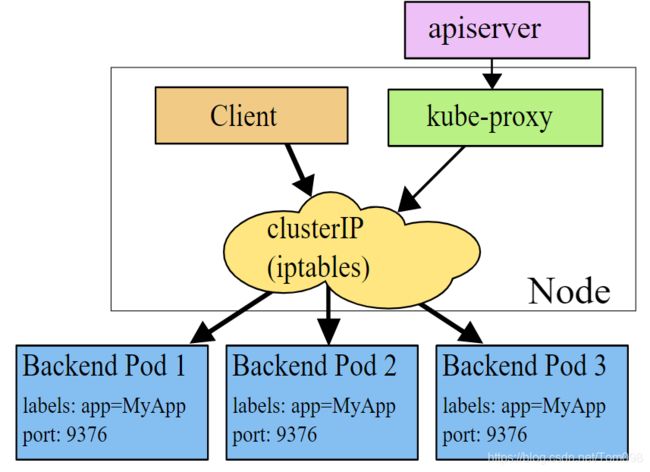
在client将请求发给clusterIP之后,service有多种代理模式将请求转发给后端pod,具体请参考如下官方文档:
https://kubernetes.io/zh/docs/concepts/services-networking/service/
从k8s集群外部如何访问k8s集群内部的service角度,又可以将service分为ClusterIP, NodePort, LoadBalancer等等。具体同样可以参考上边的官方文档连接。
下边我们以实验室环境进一步介绍k8s ClusterIP 类型的service。 比如下边代表了一个由三个物理主机组成的k8s集群,其中k8s-node1专门用于管理,k8s-node2根k8s-node3上面可以运行用户创建的pod:
[root@k8s-node1 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-node1 Ready master 27h v1.17.3 10.0.2.4 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.2
k8s-node2 Ready 26h v1.17.3 10.0.2.5 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.2
k8s-node3 Ready 26h v1.17.3 10.0.2.15 CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.2
在这个环境中,我们先创建一个yaml文件定义一个deployment,这个depoyment使用docker iamge tomcat:6.0.53-jre8来创建pod,并且是创建了三个pod副本。
[root@k8s-node1 k8s]# cat tomcat6-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat6
name: tomcat6
spec:
replicas: 3
selector:
matchLabels:
app: tomcat6
template:
metadata:
labels:
app: tomcat6
spec:
containers:
- image: tomcat:6.0.53-jre8
name: tomcat
然后我们再创建一个yaml文件来为这个deployment(也即与这个deployment关联的这三个运行tomcat的pod)创建一个service,注意我们这里是要创建一个最基本的ClusterIP类型的service (默认就是这种类型),所以我们将NodePort相关的内容都注释掉,在下边一节我们再介绍NodePort类型的service。
[root@k8s-node1 k8s]# cat tomcat6-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: tomcat6
name: tomcat6
namespace: default
spec:
# externalTrafficPolicy: Cluster
ports:
# - nodePort: 31160
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: tomcat6
# sessionAffinity: None
# type: NodePort
最后我们再定义一个yaml文件来创建一个独立的pod(不与任何deployment/service关联)
[root@k8s-node1 k8s]# cat nginx-standalone.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
有了上边的三个yaml文件,我们就可以执行'kubectl apply -f‘ 跟上上边的三个文件来创建相应的资源了:
[root@k8s-node1 k8s]# kubectl apply -f tomcat6-deployment.yaml
deployment.apps/tomcat6 created
[root@k8s-node1 k8s]# kubectl apply -f tomcat6-service.yaml
service/tomcat6 created
[root@k8s-node1 k8s]# kubectl apply -f nginx-standalone.yaml
pod/nginx created
创建完之后,我们会看到如下资源:有三个运行tomcat 的pod,和一个独立的nginx pod。有一个名字是tomcat6的service, Service IP (CLUSTER-IP)是10.96.130.163, Service port是80。那这个service如何直到对应后端哪些个pod呢?它是通过最后一列SELECTOR,lable是app=tomcat6来获取哪些pod属于这个service的。因为通过deployment 创建的三个运行tomcat的pod,他们的label都是app:tomcat6, 而单独创建的nginx pod的label是app: nginx,所以这样就能区分。
k8s集群内部其他的pod就可以service ip+port的方式或者直接通过service name的方式,将请求发给这个前端的service IP, 然后由service 对象转发给后端这个service对应的某一个运行tomcat的后端pod(嗯,你们看错,我把k8s的service 的前端部分叫做service对象,纯粹为了说明简单,理解更容易,避免进入底层的实现细节,我们可以把一个service理解成一个真实存在的对象或者软件模块,他有域名或者name, IP,PORT)。
[root@k8s-node1 k8s]# kubectl get all -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/nginx 1/1 Running 0 13h 10.244.1.15 k8s-node2
pod/tomcat6-5f7ccf4cb9-8jxz7 1/1 Running 2 2d11h 10.244.1.11 k8s-node2
pod/tomcat6-5f7ccf4cb9-gbtt5 1/1 Running 0 13h 10.244.2.10 k8s-node3
pod/tomcat6-5f7ccf4cb9-hvxs5 1/1 Running 0 13h 10.244.2.11 k8s-node3
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.96.0.1 443/TCP 3d6h
service/tomcat6 ClusterIP 10.96.73.198 80/TCP 13s app=tomcat6
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/tomcat6 3/3 3 3 2d11h tomcat tomcat:6.0.53-jre8 app=tomcat6
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset.apps/tomcat6-5f7ccf4cb9 3 3 3 2d11h tomcat tomcat:6.0.53-jre8 app=tomcat6,pod-template-hash=5f7ccf4cb9
这个例子中,pod里边每个tomcat监听在8080端口:
[root@k8s-node1 ~]# kubectl get service/tomcat6 -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2021-01-30T17:26:23Z"
labels:
app: tomcat6
name: tomcat6
namespace: default
resourceVersion: "160877"
selfLink: /api/v1/namespaces/default/services/tomcat6
uid: d3c2ee07-bd28-4d9b-941e-2b4dacc40faf
spec:
clusterIP: 10.96.246.235
externalTrafficPolicy: Cluster
ports:
port: 80
protocol: TCP
targetPort: 8080 <<<< 这个targetPort就是pod里,tomcat的监听端口。简单起见,可以
将一个pod理解成一个主机或虚拟机哦
selector:
app: tomcat6 <<<< 通过app=tomcat6这个选择器,将我的k8s集群环境中所有打有
app=tomcat6 label的pod做为后端server。而我这个实验环境中正好运行tomcat的三个pod都打有app=tomcat6 标识。
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
这是不是很熟悉的节奏?对,这就是传统的负载均衡机制。在LB后端可以有多个服务器,上边跑的同样的应用。LB上可以配置一个对外IP。所有客户端的访问,都是将请求发给LB上配置的对外的这个service IP,然后LB收到请求后,将请求再转发给后端的server。这样就实现了系统高可用性(High Availability)或者说冗余性(redundancy),避免单点故障(single point failure)。比如下图:
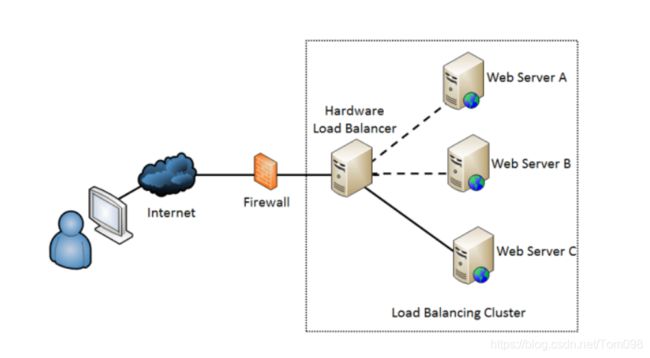
k8s的service我们也可以把他看成一个LB, 只不过这个LB不是硬件实现的,而是由软件实现的,而且他就存在与我们运行Linux的node内部。
另外,k8s service对象与传统的硬件或者软件LB还有一点不一样。在我们的例子中,如果在三个node上(k8s-node1, k8s-node2, k8s-node3) 分别执行ifconfig 或者ip address命令,你会发现没有哪一个node的网卡配置了service ip - 10.96.9.14。
[root@k8s-node1 ~]# ip a |grep inet
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
inet 10.0.2.4/24 brd 10.0.2.255 scope global noprefixroute dynamic eth0
inet6 fe80::a00:27ff:fe3c:4edf/64 scope link
inet 192.168.56.100/24 brd 192.168.56.255 scope global noprefixroute eth1
inet6 fe80::a00:27ff:fe9a:2380/64 scope link
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
inet 10.244.0.0/32 scope global flannel.1
inet6 fe80::c8a6:99ff:fe19:fb79/64 scope link
inet 10.244.0.1/24 brd 10.244.0.255 scope global cni0
inet6 fe80::2839:46ff:fefa:3234/64 scope link
inet6 fe80::f433:2eff:fe7b:d9cf/64 scope link
inet6 fe80::689a:d3ff:fe54:a446/64 scope link
[root@k8s-node2 ~]# ip a |grep inet
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
inet 10.0.2.5/24 brd 10.0.2.255 scope global noprefixroute dynamic eth0
inet6 fe80::a00:27ff:febc:459d/64 scope link
inet 192.168.56.101/24 brd 192.168.56.255 scope global noprefixroute eth1
inet6 fe80::a00:27ff:fea8:cf80/64 scope link
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
inet 10.244.1.0/32 scope global flannel.1
inet6 fe80::ac94:26ff:fe72:2907/64 scope link
inet 10.244.1.1/24 brd 10.244.1.255 scope global cni0
inet6 fe80::c74:acff:fe48:aa3d/64 scope link
inet6 fe80::60ca:61ff:fed6:b4c2/64 scope link
inet6 fe80::c07c:63ff:feb2:71d4/64 scope link
inet6 fe80::5c34:2dff:fe5d:b8e2/64 scope link
[root@k8s-node3 ~]# ip a |grep inet
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
inet 10.0.2.15/24 brd 10.0.2.255 scope global noprefixroute dynamic eth0
inet6 fe80::a00:27ff:fe18:f310/64 scope link
inet 192.168.56.102/24 brd 192.168.56.255 scope global noprefixroute eth1
inet6 fe80::a00:27ff:fe51:5aa2/64 scope link
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
inet 10.244.2.0/32 scope global flannel.1
inet6 fe80::48b3:98ff:fe6b:681b/64 scope link
然而我们在 三个node节点上执行命令"curl http://10.96.9.14/index.html"时,发现都能正常返回结果(目前所有运行tomcat的三个pod都跑在2好节点上),哪怕是不运行用户创建的pod,只运行管理服务的1号节点也能返回结果:
[root@k8s-node3 ~]# curl http://10.96.9.14/index.html
...
Apache Tomcat