OLAP(四):ClickHouse
引言
什么是ClickHouse? | ClickHouse文档
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内各个大厂纷纷跟进大规模使用:
- 今日头条内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
- 阿里内部专门孵化了相应的云数据库ClickHouse,并且在包括手机淘宝流量分析在内的众多业务被广泛使用。
在开源的短短几年时间内,ClickHouse就俘获了诸多大厂的“芳心”,并且在Github上的活跃度超越了众多老牌的经典开源项目,如Presto、Druid、Impala、Geenplum等;其受欢迎程度和社区火热程度可见一斑。
相比HBase和Redis这类NoSQL数据库,ClickHouse使用关系模型描述数据并提供了传统数据库的概念 ( 数据库、表、视图和函数等 )。与此同时,ClickHouse完全使用SQL作为查询语言 ( 支持GROUP BY、ORDER BY、JOIN、IN等大部分标准SQL ),这使得它平易近人,容易理解和学习。
关系模型相比文档和键值对等其他模型,拥有更好的描述能力,也能够更加清晰地表述实体间的关系。更重要的是,在OLAP领域,已有的大量数据建模工作都是基于关系模型展开的 ( 星型模型、雪花模型乃至宽表模型 )。ClickHouse使用了关系模型,所以将构建在传统关系型数据库或数据仓库之上的系统迁移到ClickHouse的成本会变得更低,可以直接沿用之前的经验成果。
--建表语句
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
--total_amount Decimal(16,2) TTL create_time+interval 10 SECOND, --到期后,指定的字段数据归 0
create_time Datetime
) engine =MergeTree
--engine =ReplacingMergeTree(create_time)
--填入的参数为版本字段,重复数据保留版本字段值最大的。如果不填版本字段,默认按照插入顺序保留最后一条。
--继承 MergeTree,只是多了一个去重的功能,数据的去重只会在合并的过程中出现
partition by toYYYYMMDD(create_time) --可选
primary key (id) --可选
order by (id,sku_id); --必选
--表级 TTL
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
--插入数据
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00')
--删除操作
alter table t_order_smt delete where sku_id ='sku_001';
--修改操作
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id =102;
--新增字段
alter table tableName add column newcolname String after col1;
--修改字段类型
alter table tableName modify column newcolname String;
--删除字段
alter table tableName drop column newcolname;
-- 导出数据
clickhouse-client --query "select * from t_order_mt where create_time='2020-06-01
12:00:00'" --format CSVWithNames> /opt/module/data/rs1.csv 可以发现在执行了update,delete操作之后数据目录会生成文件mutation_5.txt,mutation_6.txt。
此外还有在同名的
目录下在末尾增加了_5 ,_6的后缀。
可以看到mutation_5.txt和mutation_6.txt 是日志文件,完整的记录了update和delete操作语句和时间。
mutation_id:生成对应的日志文件用于记录相关的信息。
数据删除的过程是以数据表的每个分区目录为单位,将所有目录重写为新的目录,在目录的命名规则是在原有的名称上加上 block_numbers.number
数据的在重写的过程中会讲所需要删除的数据去掉。旧的数据并不会立即删除,而是被标记为非激活状态(active =0),
等到MergeTree引擎的下一次合并动作触发的时候,
这些非活动目录才会被真正的从物理上删除。
数据 TTL (Time To Live)
TTL 即 Time To Live,MergeTree 提供了可以管理数据或者列的生命周期的功能。
(1) 列级别 TTL
➢ 创建测试表
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);➢ 插入数据(注意:根据实际时间改变)
insert into t_order_mt3 values
(106,'sku_001',1000.00,'2020-06-12 22:52:30'),
(107,'sku_002',2000.00,'2020-06-12 22:52:30'),
(110,'sku_003',600.00,'2020-06-13 12:00:00'); ➢ 手动合并,查看效果 到期后,指定的字段数据归 0

表级 TTL
下面的这条语句是数据会在 create_time 之后 10 秒丢失
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间周期:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
4 MergeTree/ReplacingMergeTree 数据更新
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(*MergeTree)中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。 而且基于MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
5 ReplacingMergeTree
ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是多了一个去重的功能。 尽管 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree。
➢ 去重时机
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预
先作出计划。有一些数据可能仍未被处理。
➢ 去重范围
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。所以 ReplacingMergeTree 能力有限, ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
➢ 案例演示
◼ 创建表
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);向表中插入数据
insert into t_order_rmt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
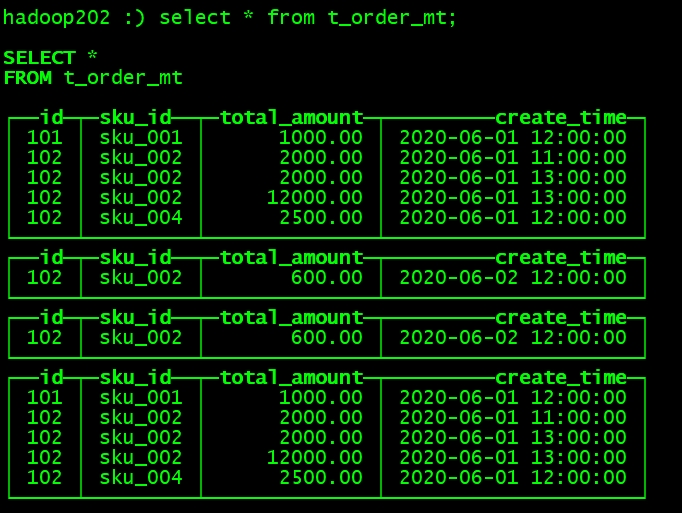
(102,'sku_002',600.00,'2020-06-02 12:00:00');◼ 执行第一次查询
hadoop202 :) select * from t_order_rmt;

◼ 手动合并
OPTIMIZE TABLE t_order_rmt FINAL;
◼ 再执行一次查询
hadoop202 :) select * from t_order_rmt;
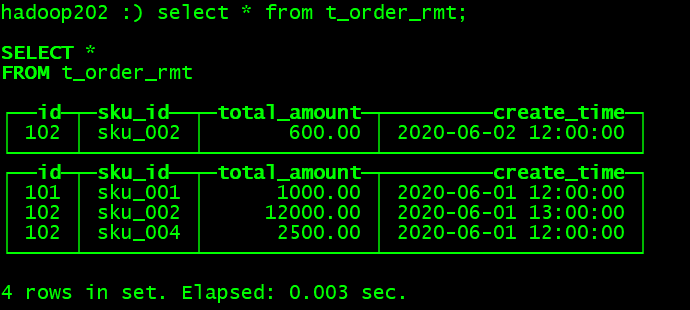
通过测试得到结论
- 实际上是使用 order by 字段作为唯一键
- 去重不能跨分区
- 只有合并分区才会进行去重
- 认定重复的数据保留,版本字段值最大的
- 如果版本字段相同则按插入顺序保留最后一笔
ClickHouse的组件架构
下图是一个典型的ClickHouse集群部署结构图,符合经典的share-nothing架构。

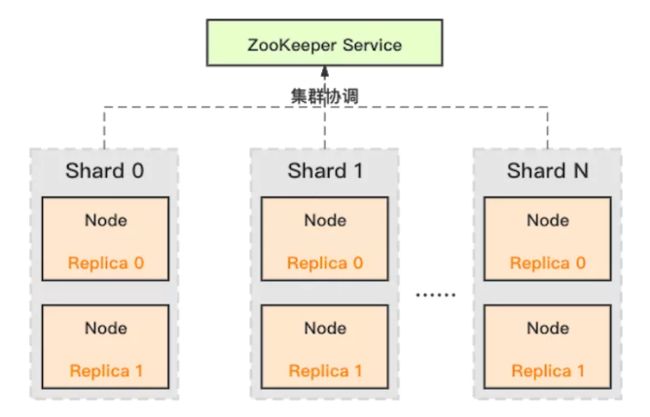
ClickHouse 采用典型的分组式的分布式架构,具体集群架构如上图所示:
- Shard:集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard 的线性扩展能力,支持海量数据的分布式存储计算。
- Node:每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
- ZooKeeper Service:集群所有节点对等,节点间通过 ZooKeeper 服务进行分布式协调。
整个集群分为多个shard(分片),不同shard之间数据彼此隔离;在一个shard内部,可配置一个或多个replica(副本),互为副本的2个replica之间通过专有复制协议保持最终一致性。
ClickHouse根据表引擎将表分为本地表和分布式表,两种表在建表时都需要在所有节点上分别建立。其中本地表只负责当前所在server上的写入、查询请求;而分布式表则会按照特定规则,将写入请求和查询请求进行拆解,分发给所有server,并且最终汇总请求结果。
多主架构(对等架构)
HDFS、Spark、HBase和Elasticsearch这类分布式系统,都采用了Master-Slave主从架构,由一个管控节点作为Leader统筹全局。而ClickHouse则采用Multi-Master多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。这种多主的架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。所以它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
一、ClickHouse存储层
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据列式存储、有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
一、列式存储
Hadoop 生态组件通常依赖 HDFS 作为底层的数据存储,ClickHouse 使用本地盘来自己管理数据,官方推荐使用 SSD 作为存储介质来提升性能。
与行存将每一行的数据连续存储不同,列存将每一列的数据连续存储
列式存储:每个数据分区内部,采用列式存储,每个列涉及两个文件,分别是存储数据的 .bin 文件和存储偏移等索引信息的 .mrk2 文件。
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
- 对于列的聚合,计数,求和等统计操作原因优于行式存储。
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间。
1)分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。

二、数据有序存储 ( sort by )
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
数据排序:每个数据分区内部,所有列的数据是按照 ORDER BY 列进行排序的。可以理解为:对于生成这个分区的原始记录行,先按 ORDER BY 列进行排序,然后再按列拆分存储。
order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理(比如后面会讲的去重和汇总)。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
数据在批量插入时,通常是按原始产生的顺序组织,对于每个列的维度,都无法保证记录确定的存储顺序;而实际的场景中,比如上述的 students 表,数据经常需要按 id 顺序进行组织或分析,ClickHouse 支持数据在存储时,指定按某个/些列排序存储,在数据写入到文件之前,ClickHouse 会对数据先进行排序,然后按列进行存储。 stduents 表 ORDER BY id 之后,实际存储顺序如下。

三、主键索引( primary key )
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
主键索引:主键默认与 ORDER BY 列一致,或为 ORDER BY 列的前缀。由于整个分区内部是有序的,且切割为数据块存储,ClickHouse 抽取每个数据块第一行的主键,生成一份稀疏的排序索引,可在查询时结合过滤条件快速裁剪数据块。
对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
但是值得注意的是:ClickHouse的主键索引与MySQL等数据库不同,它并不用于去重,即便primary key相同的行,也可以同时存在于数据库中。要想实现去重效果,需要结合具体的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree实现,我们会在未来的文章系列中再进行详细解读。
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。主键的设定主要依据是查询语句中的 where 条件。
ClickHouse 里的 Primary Key 没有唯一性约束,通常情况下,用户无需显式指定 Primary Key;Sorting Key 即为 Primary Key。两者也可以不同,但 Primary Key 必须为 Sorting Key 的前缀。
ClickHouse 针对 Primary 建立了单独索引,同样是以 index_granularity行为一个索引单元 ,因为数据是按 Primary Key 顺序组织的,这个索引能快速的根据 Primary Key 的值来定位对应的数据。students表中 Primary Key 没有指定,则 id 列即为 Primary Key,其索引如下所示。
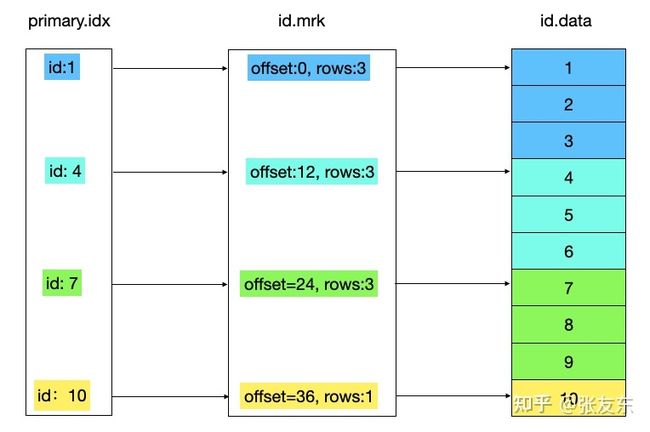
当查询指定 Primary 的范围时,就可以快速根据 primary.idx 索引信息定位到对应的 granule,从而确定 data 文件的扫描范围。
三、稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。目前支持的稀疏索引类型包括:
- minmax: 以index granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
- set(max_rows):以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块,减少IO。
- ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化等值、like、in等查询条件。
- tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割。
- bloom_filter([false_positive]):对指定列构建bloom filter,用于加速等值、like、in等查询条件的执行。
稀疏索引:

对于 Primary Key,ClickHouse 可以通过索引加速查询,如果查询条件是非 Primary Key,则默认需要扫描数据列的所有数据进行条件过滤;为了加速其他列的查询,ClickHouse 支持 Skip Index ,用于快速过滤数据块里是否包含满足条件的数据,Skip Index 主要包括。
minmax,针对列存数据块,记录块内最大,最小值用于过滤。set(max_rows),为该列的数据存储不重复的取值集合,用于过滤,适用于列数据有取值较少,但每个取值数量较多的场景(即 cardinality 比较低的列)bloomfilter,对数据列的取值建立 bloomfilter 索引数据用于快速过滤。ngram、token,为列数据的分词建立 bloomfilter 索引用于快速过滤。
以 minmax 为例,针对 score 列建立 minmax index, GRANULARITY 为2,也就是针对每2个索引单元(index_granularity行)对应一个索引信息。比如要查询分数小于 80 的所有学生的信息,则可以快速过滤掉前面两个索引单元。

五、数据Sharding分片( Distributed ) 分块
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
数据分块:每个列的数据文件中,实际是分块存储的,方便数据压缩及查询裁剪,每个块中的记录数不超过 index_granularity,默认 8192。
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
- 1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
- 2) constant固定分片:写入数据会被分发到固定一个节点上。
- 3)column value分片:按照某一列的值进行hash分片。
- 4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hash sharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local join; 支持自定义sharding,可以为不同业务和SQL Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。
Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
集群写入流程(3 分片 2 副本共 6 个节点):

集群读取流程(3 分片 2 副本共 6 个节点):
在 hadoop202创建 Distribute 分布式表
create table st_order_mt_all on cluster gmall_cluster
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id));
--参数含义
Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()
insert into st_order_mt_all values
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');
--通过查询分布式表和本地表观察输出结果
SELECT * FROM st_order_mt_all;st_order_mt_all
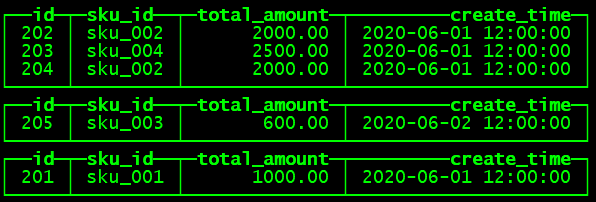
hadoop202: st_order_mt

hadoop203:st_order_mt

hadoop204:st_order_mt

配置分片集群 vim /etc/clickhouse-server/config.d/metrika.xml
六、数据分区 ( partition by )Partition Key
➢ 作用
学过 hive 的应该都不陌生,分区的目的主要是降低扫描的范围,优化查询速度
➢ 如果不填
只会使用一个分区。
➢ 分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这
些文件就会保存到不同的分区目录中。
➢ 并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理。
➢ 数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入
后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可
以手动通过 optimize 执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx final;
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity,然后通过多个 CPU 核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条 Query 就能利用整机所有 CPU。极致的并行处理能力,极大的降低了查询延时。所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务,ClickHouse 并不是强项。
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
- 在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点。
- 对partition进行TTL管理,淘汰过期的分区数据。
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00'); 再次执行上面的插入操作
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');ClickHouse 中的主键primary key,和其他数据库不太一样,它只提供了数据的一级索引,但是却
不是唯一约束

手动 optimize 之后
hadoop202 :) optimize table t_order_mt final;
再次查询 ,数据按照create_time进行分区了

ClickHouse 支持对数据分 Partition 存储,不同 Partition 之间的数据物理隔离,用户可以根据 Partition Key 快速过滤 Parition 是否有满足条件的数据,比如将数据按时间进行分区,不同月份的数据存储到不同的 Partition,与传统关系型数据库的分区类似。
例如 PARTIION BY score/10 相当于按 score 进行分区,每10分一档为一个 Partion,当查询一档内的分数区间时,就可以快速过滤掉不相关的 Partition。
七、主备同步,副本 写入流程
ClickHouse通过主备复制提供了高可用能力,主备架构下支持无缝升级等运维操作。而且相比于其他系统它的实现有着自己的特色:
- 1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
- 2)可以任意配置副本个数,副本数量可以从0个到任意多个;
- 3)不同shard可以配置不提供副本个数,用于解决单个shard的查询热点问题;
副本 写入流程

副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表
配置副本 vim /etc/clickhouse-server/config.d/metrika.xml
hadoop202
2181
hadoop203
2181
hadoop204
2181
➢ 在 hadoop202 的/etc/clickhouse-server/config.xml 中增加

➢ 同步到 hadoop203 和 hadoop204 上
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.d/metrika.xml
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.xml
分别在 hadoop202 和 hadoop203 上启动 ClickHouse 服务
hadoop202
create table t_order_rep (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/t_order_rep','rep_202')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);hadoop203
create table t_order_rep (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/t_order_rep','rep_203')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id); 在 hadoop202 上执行 insert 语句
insert into t_order_rep values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00'); 在 hadoop203 上执行 select,可以查询出结果,说明副本配置正确

八、高吞吐写入能力LSM Tree
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
ClickHouse采用列式作为单机存储,并且采用了类LSM tree的结构来进行组织与合并。一张MergeTree本地表,从磁盘文件构成如下图所示。

本地表的数据被划分为多个Data PART,每个Data PART对应一个磁盘目录。Data PART在落盘后,就是immutable的,不再变化。ClickHouse后台会调度MergerThread将多个小的Data PART不断合并起来,形成更大的Data PART,从而获得更高的压缩率、更快的查询速度。当每次向本地表中进行一次insert请求时,就会产生一个新的Data PART,也即新增一个目录。如果insert的batch size太小,且insert频率很高,可能会导致目录数过多进而耗尽inode,也会降低后台数据合并的性能,这也是为什么ClickHouse推荐使用大batch进行写入且每秒不超过1次的原因。
在Data PART内部存储着各个列的数据,由于采用了列存格式,所以不同列使用完全独立的物理文件。每个列至少有2个文件构成,分别是.bin 和 .mrk文件。其中.bin是数据文件,保存着实际的data;而.mrk是元数据文件,保存着数据的metadata。此外,ClickHouse还支持primary index、skip index等索引机制,所以也可能存在着对应的pk.idx,skip_idx.idx文件。
数据写入
在数据写入过程中,数据被按照index_granularity切分为多个颗粒(granularity),默认值为8192行对应一个颗粒。多个颗粒在内存buffer中积攒到了一定大小(由参数min_compress_block_size控制,默认64KB),会触发数据的压缩、落盘等操作,形成一个block。每个颗粒会对应一个mark,该mark主要存储着2项信息:
- 1)当前block在压缩后的物理文件中的offset,
- 2)当前granularity在解压后block中的offset。
所以Block是ClickHouse与磁盘进行IO交互、压缩/解压缩的最小单位,而granularity是ClickHouse在内存中进行数据扫描的最小单位。
如果有ORDER BY key或Primary key,则ClickHouse在Block数据落盘前,会将数据按照ORDER BY key进行排序。主键索引pk.idx中存储着每个mark对应的第一行数据,也即在每个颗粒中各个列的最小值。
当存在其他类型的稀疏索引时,会额外增加一个
- minmax会记录各个颗粒的最小、最大值;
- set会记录各个颗粒中的distinct值;
- bloomfilter会使用近似算法记录对应颗粒中,某个值是否存在;

ClickHouse写入链路
ClickHouse提供2种写入方法,1)写本地表;2)写分布式表。
写本地表方式,需要业务层感知底层所有server的IP,并且自行处理数据的分片操作。由于每个节点都可以分别直接写入,这种方式使得集群的整体写入能力与节点数完全成正比,提供了非常高的吞吐能力和定制灵活性。但是相对而言,也增加了业务层的依赖,引入了更多复杂性,尤其是节点failover容错处理、扩缩容数据re-balance、写入和查询需要分别使用不同表引擎等都要在业务上自行处理。
而写分布式表则相对简单,业务层只需要将数据写入单一endpoint及单一一张分布式表即可,不需要感知底层server拓扑结构等实现细节。写分布式表也有很好的性能表现,在不需要极高写入吞吐能力的业务场景中,建议直接写入分布式表降低业务复杂度。
以下阐述分布式表的写入实现原理。
ClickHouse使用Block作为数据处理的核心抽象,表示在内存中的多个列的数据,其中列的数据在内存中也采用列存格式进行存储。示意图如下:其中header部分包含block相关元信息,而id UInt8、name String、_date Date则是三个不同类型列的数据表示。

在Block之上,封装了能够进行流式IO的stream接口,分别是IBlockInputStream、IBlockOutputStream,接口的不同对应实现不同功能。
当收到INSERT INTO请求时,ClickHouse会构造一个完整的stream pipeline,每一个stream实现相应的逻辑:
InputStreamFromASTInsertQuery #将insert into请求封装为InputStream作为数据源
-> CountingBlockOutputStream #统计写入block count
-> SquashingBlockOutputStream #积攒写入block,直到达到特定内存阈值,提升写入吞吐
-> AddingDefaultBlockOutputStream #用default值补全缺失列
-> CheckConstraintsBlockOutputStream #检查各种限制约束是否满足
-> PushingToViewsBlockOutputStream #如有物化视图,则将数据写入到物化视图中
-> DistributedBlockOutputStream #将block写入到分布式表中在以上过程中,ClickHouse非常注重细节优化,处处为性能考虑。在SQL解析时,ClickHouse并不会一次性将完整的INSERT INTO table(cols) values(rows)解析完毕,而是先读取insert into table(cols)这些短小的头部信息来构建block结构,values部分的大量数据则采用流式解析,降低内存开销。在多个stream之间传递block时,实现了copy-on-write机制,尽最大可能减少内存拷贝。在内存中采用列存存储结构,为后续在磁盘上直接落盘为列存格式做好准备。
SquashingBlockOutputStream将客户端的若干小写,转化为大batch,提升写盘吞吐、降低写入放大、加速数据Compaction。
默认情况下,分布式表写入是异步转发的。
DistributedBlockOutputStream将Block按照建表DDL中指定的规则(如hash或random)切分为多个分片,每个分片对应本地的一个子目录,将对应数据落盘为子目录下的.bin文件,写入完成后就返回client成功。随后分布式表的后台线程,扫描这些文件夹并将.bin文件推送给相应的分片server。.bin文件的存储格式示意如下:

数据查询
在查找时,如果query包含主键索引条件,则首先在pk.idx中进行二分查找,找到符合条件的颗粒mark,并从mark文件中获取block offset、granularity offset等元数据信息,进而将数据从磁盘读入内存进行查找操作。类似的,如果条件命中skip index,则借助于index中的minmax、set等信息,定位出符合条件的颗粒mark,进而执行IO操作。借助于mark文件,ClickHouse在定位出符合条件的颗粒之后,可以将颗粒平均分派给多个线程进行并行处理,最大化利用磁盘的IO吞吐和CPU的多核处理能力。
二、ClickHouse计算层
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
1、多核并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
2、分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略:
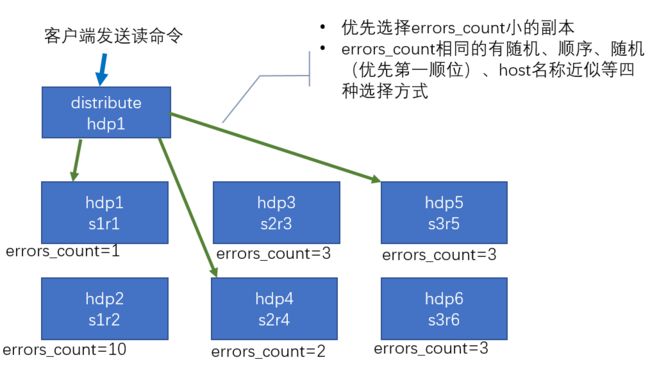
- 随机下发:在多个replica中随机选择一个;
- 最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
- in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
- first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
3、向量化执行与SIMD
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
- 1)对每一行数据都要调用相应的函数,函数调用开销占比高;
- 2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
- 3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
4、动态代码生成Runtime Codegen
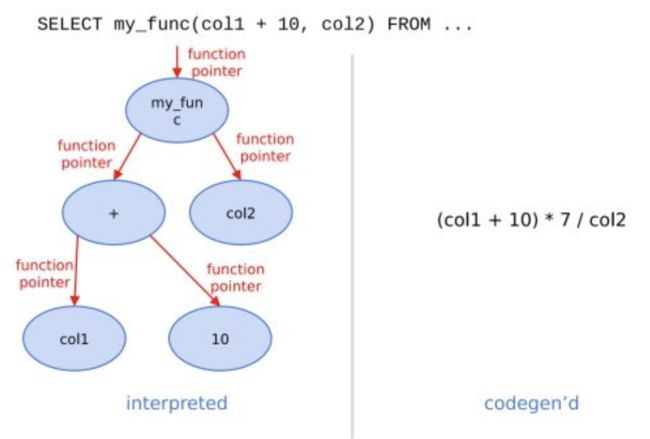
在经典的数据库实现中,通常对表达式计算采用火山模型,也即将查询转换成一个个operator,比如HashJoin、Scan、IndexScan、Aggregation等。为了连接不同算子,operator之间采用统一的接口,比如open/next/close。在每个算子内部都实现了父类的这些虚函数,在分析场景中单条SQL要处理数据通常高达数亿行,虚函数的调用开销不再可以忽略不计。另外,在每个算子内部都要考虑多种变量,比如列类型、列的size、列的个数等,存在着大量的if-else分支判断导致CPU分支预测失效。
ClickHouse实现了Expression级别的runtime codegen,动态地根据当前SQL直接生成代码,然后编译执行。如下图例子所示,对于Expression直接生成代码,不仅消除了大量的虚函数调用(即图中多个function pointer的调用),而且由于在运行时表达式的参数类型、个数等都是已知的,也消除了不必要的if-else分支判断。
5、近似计算
近似计算以损失一定结果精度为代价,极大地提升查询性能。在海量数据处理中,近似计算价值更加明显。
ClickHouse实现了多种近似计算功能:
- 近似估算distinct values、中位数,分位数等多种聚合函数;
- 建表DDL支持SAMPLE BY子句,支持对于数据进行抽样处理;
6、复杂数据类型支持
ClickHouse还提供了array、json、tuple、set等复合数据类型,支持业务schema的灵活变更。
查询加速
- 如果表指定了 Partition Key,并且查询条件包含 Partition Key,则根据查询条件快速过滤满足条件的 Partition。
- 在 Partition 内部,如果查询条件指定了 Primary Key 或 Sort Key,则根据 Primary Index 来过滤满足条件的索引单元。
- 如果查询条件的列有 Skip Index,则根据对应 Index 过滤满足条件的索引单元。
三、Clickhouse为什么这么快?减少数据扫描范围
相信看过ClickHouse性能测试报告的同学都很震惊于他超高的OLAP查询性能。于是下一步开始搜索“ClickHouse性能为什么高”看到了例如:
1 计算
- 多核并行
- 分布式计算
- 向量化执行
- 基于内存
2 存储
- 列式存储
- 数据压缩
- 有序
- 稀疏索引
- 数据分片
- 分区
- 主备
针对OLAP类的查询最简单的优化方式就是减少数据扫描范围,故而我们以此作为开篇。
问题:
有一个表(tab01)有10个int类型的字段(col1,col2,col3…col10),这个表中有十亿条数据。
{176, 35, 27, 82, 65, 75, 20, 25, 92, 35},
{322, 42, 33, 12, 82, 77, 65, 22, 98, 12},
…
为了简单假定该表没有主键和索引,在本篇中也不考虑任何的数据压缩。
需要完成如下查询:
SELECT avg(col1),avg(col2) FROM tab01 WHERE col3 > 500;方案一:行存储
传统的 MySQL 数据库的每一行数据都是物理的存储在一起的。如果我要去 id 等于 10000 这一条数据的 name 列,那我就必须要把这一行数据读取出来,然后取 name 列。由于 name 列的数据都存储在一起,因此效率大大地超过了传统的数据库。
如果该表以行存储的方式存储为一个文件:tab01.dat , 每条数据40字节,那么整个文件大小为40GB,在这个方案中,我们需要从头到尾读取文件所有数据,也就是需要从磁盘读取40GB的内容。显然行存储方案对于处理这类问题来说并不高效。

列存储
如果我们将该表的数据以列存储,即:将所有数据存储为10个文件,col1.dat 存储col1列所有的10亿条数据,依此类推,我们得到了10个数据文件,每个数据文件存储十亿个数据,大小为4GB。
那么完成上面的查询,只需要读取col1.dat 、 col2.dat 、 col3.dat 三个文件,总共12GB。 读磁盘的大小仅为方案一的30%。 现在我们就通过减少数据扫描范围达到了提升性能的目的。这也是列存储广泛应用在OLAP场景中的原因。
方案二:高效的数据压缩,默认使用LZ4算法,总体压缩比可达 8:1。
默认使用LZ4算法压缩,在Yandex.Metrica的生产环境中,数据总体的压缩比可以达到8:1 ( 未压缩前17PB,压缩后2PB )。列式存储除了降低IO和存储的压力之外,还为向量化执行做好了铺垫。
按列存储相比按行存储的另一个优势是对数据压缩的友好性。同样可以用一个示例简单说明压缩的本质是什么。假设有两个字符串abcdefghi和bcdefghi,现在对它们进行压缩,如下所示:
压缩前:abcdefghi_bcdefghi压缩后:abcdefghi_(9,8)
可以看到,压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换。例如上述示例中的 (9,8),表示如果从下划线开始向前移动9个字节,会匹配到8个字节长度的重复项,即这里的bcdefghi。
方案三: 将数据分块
借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
在列存储的基础上,如果按照8192条数据进行分块,比如:col1.dat 的前 8192条数据是数据块1,接下来8192条数据是数据块2。所有数据文件都是如此,数据的逻辑组织如下所示:

数据列分块示意图
执行过程:以数据块为单位依次读取col3列的所有数据块,取得数据块中所有符合条件(col3 > 500)的数据下标。
如果在该数据块中有符合条件的数据,则从col1.dat和col2.dat中读取对应位置的数据块,并取出对应位置的数据。
如果在该数据块中没有符合条件的数据,则不需要读取col1.dat和col2.dat中对应位置的数据块。
在这个优化中,我们只需要读取col3.dat全部数据和部分或全部col1.dat和col2.dat的数据,数据扫描范围相比于上一个方案进一步缩小。 这也就是ClickHouse中PreWhere所作的优化。
方案四: 数据块索引
一般的OLAP可能需要存储千亿甚至万亿级的数据,普通一条数据一个索引的方式已经不适应于这么大的数据量。此时,对数据列上以数据块为单位建立索引是比较适合的方案。例如:对上例中列col3以数据块建立索引每条索引存储指定数据块中的最大值、最小值,十亿条数据的列仅需要不到13万条索引。

数据块索引
执行过程:首先读取col3数据块索引,判断该列存储的数据是否满足条件[27,87] 与 (500,) 是否有交集。
如果有交集则继续上一个方案的步骤。
如果没有交集则不需要读取任何数据块。
在这个优化中,需要读取col3.idx所有的数据,以及col1, col2, col3 的部分数据块。与上一个方案相比,扫描到的数据量进一步缩小。
一说到Clickhouse,大家都知道它非常快,那么CH为什么这么快,是因为使用了向量化、列式数据库还是其它。下面我们一起来探索它的奥秘。(《ClickHouse原理解析与应用实践》总结)
1、硬件方面
ClickHouse会在内存中进行GROUP BY,并且使用HashTable装载数据。与此同时,他们非常在意CPU L3级别的缓存,因为一次L3的缓存失效会带来70~100ns的延迟。这意味着在单核CPU上,它会浪费4000万次/秒的运算;而在一个32线程的CPU上,则可能会浪费5亿次/秒的运算。所以别小看这些细节,一点一滴地将它们累加起来,数据是非常可观的。正因为注意了这些细节,所以ClickHouse在基准查询中能做到1.75亿次/秒的数据扫描性能。
2、算法方面
在ClickHouse的底层实现中,经常会面对一些重复的场景,例如字符串子串查询、数组排序、使用HashTable等。如何才能实现性能的最大化呢?算法的选择是重中之重。以字符串为例,有一本专门讲解字符串搜索的书,名为'Handbook of Exact String Matching Algorithms',列举了35种常见的字符串搜索算法。各位猜一猜ClickHouse使用了其中的哪一种?答案是一种都没有。这是为什么呢?因为性能不够快。在字符串搜索方面,针对不同的场景,ClickHouse最终选择了这些算法:
- 对于常量,使用Volnitsky算法;
- 对于非常量,使用CPU的向量化执行SIMD,暴力优化;
- 正则匹配使用re2和hyperscan算法。
性能是算法选择的首要考量指标。
3、应景优化,特定场景,特殊优化
CH会在不同的场景使用不同的算法。例如,在去重函数uniqCombined中,会根据数据量选择不同的算法:数据量比较少的时候,会选择使用Array来保存;数据量中等的时候,使用HashSet;数据量很大的时候,会使用HyperLogLog算法。
针对同一个场景的不同状况,选择使用不同的实现方式,尽可能将性能最大化。关于这一点,其实在前面介绍字符串查询时,针对不同场景选择不同算法的思路就有体现了。类似的例子还有很多,例如去重计数uniqCombined函数,会根据数据量的不同选择不同的算法:
- 当数据量较小的时候,会选择Array保存;
- 当数据量中等的时候,会选择HashSet;
- 而当数据量很大的时候,则使用HyperLogLog算法。
对于数据结构比较清晰的场景,会通过代码生成技术实现循环展开,以减少循环次数。接着就是大家熟知的大杀器—向量化执行了。SIMD被广泛地应用于文本转换、数据过滤、数据解压和JSON转换等场景。相较于单纯地使用CPU,利用寄存器暴力优化也算是一种降维打击了。
5. 多样化的表引擎
也许因为Yandex.Metrica的最初架构是基于MySQL实现的,所以在ClickHouse的设计中,能够察觉到一些MySQL的影子,表引擎的设计就是其中之一。与MySQL类似,ClickHouse也将存储部分进行了抽象,把存储引擎作为一层独立的接口。截至本书完稿时,ClickHouse共拥有合并树、内存、文件、接口和其他6大类20多种表引擎。其中每一种表引擎都有着各自的特点,用户可以根据实际业务场景的要求,选择合适的表引擎使用。
将表引擎独立设计的好处是显而易见的,通过特定的表引擎支撑特定的场景,十分灵活。对于简单的场景,可直接使用简单的引擎降低成本,而复杂的场景也有合适的选择。
4、向量化、多线程与分布式
坊间有句玩笑,即'能用钱解决的问题,千万别花时间'。而业界也有种调侃如出一辙,即'能升级硬件解决的问题,千万别优化程序'。有时候,你千辛万苦优化程序逻辑带来的性能提升,还不如直接升级硬件来得简单直接。

距离CPU越远,则数据的访问速度越慢。从寄存器中访问数据的速度,是从内存访问数据速度的300倍,是从磁盘中访问数据速度的3000万倍。所以利用CPU向量化执行的特性,对于程序的性能提升意义非凡。
SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式 ( 其他的还有指令级并行和线程级并行 ),它的原理是在CPU寄存器层面实现数据的并行操作。,CH使用向量化执行。SIMD被广泛地应用于文本转换、数据过滤、数据解压和JSON转换等场景。相对于单纯使用CPU,利用寄存器暴力优化也算是一种降维打击
5、持续测试和持续改进
如果只是单纯地在上述细节上下功夫,还不足以构建出如此强大的ClickHouse,还需要拥有一个能够持续验证、持续改进的机制。由于Yandex的天然优势,ClickHouse经常会使用真实的数据进行测试,这一点很好地保证了测试场景的真实性。与此同时,ClickHouse也是我见过的发版速度最快的开源软件了,差不多每个月都能发布一个版本。没有一个可靠的持续集成环境,这一点是做不到的。正因为拥有这样的发版频率,ClickHouse才能够快速迭代、快速改进。
四、哪些场景比较适合使用ClickHouse呢?
ClickHouse比较适合分析结构化的、干净的、不可变的流式数据,比如打点日志分析啦,行为分析啦。强烈建议将源源不断的流式数据和提前已经定义好的维度表组合起来,并塞到一个基于事实的大宽表中去( a single wide fact table,一张宽大的事实表,是不是很有亲切感?)。
ClickHouse比较适用于以下行业/场景:
- 网页端和客户端产品的数据分析
- 广告系统和实时竞价广告
- 电信行业
- 电商和金融行业
- 信息安全
- 实时监控和遥感测量
- 时间序列
- 商业智能
- 在线游戏
- 所有的互联网场景
ClickHouse不适合的场景:
- OLAP联机事物处理(上面提到过的,小黑板敲起来,mysql这种比较适合)
- 键值对数据高效率访问请求(想到redis了嘛?)
- 二进制数据或文件存储(想到mongDB了嘛?)
- 过度标准化的数据(有很多人好奇了,开什么玩笑,数据按说应该是越标准化越好啊?这个问题应该这样理解,那些过于简单直接、没啥维度和灵活度需求的数据,咋能体现ClickHouse的优势呢,你用啥数据库都能做得很6啊)
五、 clickhouse与mysql查询速度对比
数据量为308万行,每行14个列的测试
select * from bigtableclickhouse:67.62s ; mysql:0.002s
clickhouse感觉是瞬间查出来,但是加载10000行数据刷屏用了很久很久,clickhouse里查询的列数一多,加载的时间就变长
- TOPN
clickhouse:0.13s ; mysql:0.020sselect* from bigtable order by dish_Name limit 1
- 统计数据有多少行:
select count(1) from bigtableclickhouse:0.015s ; mysql:1.33s
- 统计一共有多少个订单:
select count(1) from (select consumption_id,created_org from bigtable group by consumption_id,created_org)a;clickhouse:0.121s ; mysql:5.15s
- 来吃过的次数里各有多少人:82行
select sum_all,count(1) as countall from (select member_id,count(1) as sum_all from
(select member_id,consumption_id,created_org from bigtable group by consumption_id,created_org) a group by member_id) a
group by sum_all;clickhouse:0.166s ; mysql:5.50s
- 添加条件的查询:
SELECT COUNT(1) FROM bigtable
WHERE member_id IN (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,
20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,
40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,
60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,
76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,
95,96,97,98,99,100)
AND bill_date BETWEEN '2017-01-01' AND '2017-12-31'
AND fans_id >10
clickhouse:0.027s ; mysql:2.05s
- 每个用户最常吃的菜品:8万行
SELECT member_id,dish_name,sum_all FROM (
SELECT member_id,dish_name,COUNT(1) AS sum_all FROM bigtable WHERE dish_name NOT IN('米饭','打包盒','茶位费')
GROUP BY member_id,dish_name ORDER BY member_id,sum_all DESC) a GROUP BY member_idclickhouse:11.90s ; mysql:9.88s
- 来个猛的,四重子查询:171万行
SELECT * FROM bigtable
WHERE member_id IN(SELECT member_id FROM bigtable WHERE member_id IN(SELECT member_id FROM bigtable WHERE source_type=1 AND member_id IN (SELECT member_id FROM bigtable WHERE source_type=1
AND member_id IN (SELECT member_id FROM bigtable WHERE fans_id !=0))
) AND is_subscribed=1 )clickhouse:65.284s ; mysql:Mysql不行了,查了30分钟还没结果;clickhouse同样是加载行数用了很久
关联表查询,三个表分别为近100万,13万,13万: 三个表相互关联拼接的查询: 8万行
clickhouse:3.65s ; mysql:4min46s
在几万十几万行的数据里,clickhouse的速度也是要显著快于mysql
结论:
那么这部分对比查询时间的结果显而易见了:
- 对于简单查询来说,查询列数多的话mysql有优势,查询列数少的话clickhouse领先。
- 对于复杂查询来说,clickhouse占有显著优势
另外,展示行数的多少会影响clickhouse的查询时间,不知道是不是因为使用linux的原因
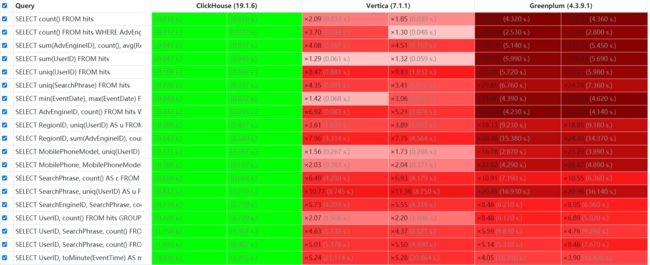
ClickHouse 对比 Greenplum
从测试结果看,ClickHouse 几乎在所有场景下性能都最佳,并且从所有查询整体看,ClickHouse 领先图灵奖得主 Michael Stonebraker 所创建的 Vertica 达 6 倍,领先 Greenplum 达到 18 倍。