正则表达式
文章目录
-
- 正则表达式
-
- 1.正则表达式趣味
- 2.正则表达式入门
-
- 部分一
- 部分二
- 部分三(字符转换符号&|)
- 原子表或者原字符
- 边位符
- 数值和空白字符
- \w 与 \W
- 点元字符的使用 .
- 匹配全部字符
- 多行匹配m
- 汉字与字符属性 /u
- lastIndex属性 (不会)
- 有效y使用
- 原子表的基本使用
- 原子表区间的特性
- 原子表排除匹配
- 原子表注意
- 正则操作DOM元素
- mail案例测试
- 原子组引用完成替换
- 嵌套分组和不记录分组
-
- 嵌套分组
- 正则表达式应用
-
- 用户名验证
- 密码验证
- 禁止贪婪
- 禁止贪婪应用
- 打印标签内容
-
- matchAll
- Search
- split
- $在正则表达式中的应用
- 断言匹配
正则表达式
1.正则表达式趣味
var hd = "tiantianxuexi2020qianduan2021"
console.log(hd);
现在需要只取出数字部分
var hd = "tiantianxuexi2020qianduan2021"
console.log(hd);
var hd1=[...hd].filter(a=>!Number.isNaN(parseInt(a)));
console.log(hd1.join(""));
filter 过滤
a=>为方法简写
方法解析
首先parseInt(a) 解析这个a传入的参数是否为数值,是正常返回,不是返回NaN
然后使用Number类下的isNaN进行判断,是返回true,不是返回false;
filter()方法会创建一个新数组,原数组的每个元素传入回调函数中,回调函数中有return返回值,若返回值为true,这个元素保存到新数组中;若返回值为false,则该元素不保存到新数组中;原数组不发生改变。
所以我们需要取出数字部分,数字部分在此为false,因此我们需要取反进行。
然后最后通过join进行连接在一起,如不使用,返回的是一个数组
![]()
正则表达式取值
var hd = "tiantianxuexi2020qianduan2021"
console.log(hd);
console.log(hd.match(/\d/g).join(""));
![]()
结果相同
2.正则表达式入门
正则表达式书写位置
/这里面书写正则表达式/
举一个栗子
/\d/g 其中 \d就是正则表达式 代表着数字数值 g代表全局查找
部分一
test()方法
test方法作用是判断是否字符串里是否包括某些字符串
格式
正则表达式.test(字符串);
举一个栗子
var str ="ourstudyjavascript.com"
console.log(/o/.test(str));
结果返回true;
判断o是否在str这个字符串里面
以上会有一个问题
它不能将变量包括在内进行判断
var str ="ourstudyjavascript.com";
var str2 ="o";
console.log(/str2/.test(str)); //结果返回false
但是这样也可以用另一种方法进行解决
eval()方法
eavl方法它可以将字符串转换为代码运行
var str ="ourstudyjavascript.com"
var str2 ="o";
console.log(eval(`/${str2}/`).test(str)); //结果返回true
部分二
使用对象创建正则表达式
new RegExp();
创建RegExp()对象的语法
new RegExp(pattern,attributes);
| 参数 | 作用 |
|---|---|
| pattern | 书写正则表达式 |
| attributes | 书写参数,g w i 等正则表达式的查找方式 |
var str ="ourstudyjavascript.com"
var str2 =new RegExp("a","g"); //通过全局查找方式,查找a,在此a不必要写成/a/
console.log(str2.test(str)); //结果返回true
同样,这个对象也可以查找变量
var str ="ourstudyjavascript.com"
var st ="u";
var str2 =new RegExp(st,"g");
console.log(str2.test(str)); //结果返回ture
举个小栗子
要求根据用户输入结果来改变字符串的颜色变化
回顾代替replace函数
var hd="abc";
var av=hd.replace(/\w/g,"@"); //当然,第二个参数可以书写方法
console.log(av) //记过返回@@@三个@@@
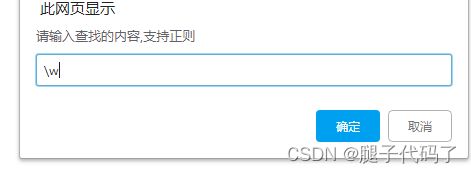
/\w/g代表全局查找字母数字下划线
<div class="abc">
studyjavascript.com
div>
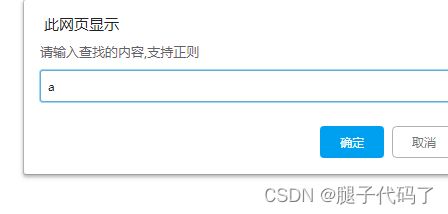
var user=prompt("请输入查找的内容,支持正则");
var con =new RegExp(user,"g");
var div =document.querySelector("div");
div.innerHTML=div.innerHTML.replace(con,search=>{
return `${search}`; //`是Tab上的票
});
查找a

查找字母下划线

部分三(字符转换符号&|)
var str ="studyjavascript.com"
console.log(/a|@/.test(str));
判断是否包含a或者@
电话号检测
var tel ="010-9999999";
console.log(/(010|020)\-\d{7,8}/.test(tel));
其中(010|020)是为了保证两侧都有检测
\d{7,8} 表示随机数字7-8位
\-转义为普通的字符。
原子表或者原字符
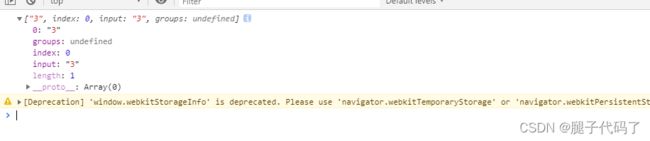
[] 原子表 相当于或 [123456] 相当于1或2或3或4…
var tel =/[123456]/;
var t="3";
console.log(t.match(tel)); //这个时候就是匹配全部的123456了 结果返回索引
() 原子符 相当于与
var tel =/(123|456)/;
var t="3211214";
console.log(t.match(tel)); //返回null
表示匹配123 或者456 这两个整体。
![]()
边位符
| ^ | $ |
|---|---|
| 表示必须以此为开头的匹配 | 表示必须以此为结尾的匹配 |
var hd ="woaixuejavascript 2020";
var hs ="2020 woaixuejavascript";
console.log(hd.match(/\d+/)); //正常匹配数字
console.log(hs.match(/^\d+/)); //匹配开头为数字的字符
console.log(hd.match(/\d+$/)); //匹配结尾为数字的字符
其中+代表匹配多个 和/g全局查找一个效果

数值和空白字符
数字既是/\d/用来匹配字符
var hd ="张三:010-33333333,李四:020-55555555";
//获取电话号码
console.log(hd.match(/\d+-\d{7,8}/g));
//获取特定字符,使用原子表----匹配原子表内的元素
console.log(hd.match(/[:\d-,]/g));
//获取特定字符,除原子表内的元素
console.log(hd.match(/[^:\d,]/g));
![]()
![]()
var hd =`
张三:010-33333333,李四:020-55555555
`;
//判断是否有空 \s
console.log(/\s/.test(hd));
// 判断是否有空
var hs ="\nwoaixuejava";
console.log(/\s/.test(hs));
var hh ="";
//判断除了空还有其他元素么
console.log(/\S/.test(hh));

\w 与 \W
\w字符指的是匹配字母数字下划线
var hd ="abc@123_";
console.log(hd.match(/\w/g));
![]()
/W是匹配除了字母数字下划线
var hd ="abc@123_";
console.log(hd.match(/\W/g));
![]()
匹配email小栗子
var email ="[email protected]";
console.log(email.match(/\w+@\w+\.\w+/));
![]()
匹配用户名 (以字母开头,右数字字母下划线组成)
var input = prompt("请输入用户名");
console.log(input);
var hs=/^[a~z]\w{5,9}$/i;
console.log(hs.test(input));
![]()
点元字符的使用 .
/./ 元字符匹配表示除了换行符以外全部匹配
var hd ="woaixuejavascript_1da@#954&*)";
console.log(hd.match(/.+/));
![]()
现在使用模板匹配
var hd =`
woaixuejava.com
`;
console.log(hd.match(/./g));
![]()
注意 + 和全局变量g有区别
例如上面的例子使用+和g的区别
+:![]()
g:![]()
/s单行模式,使之为一行
var hd =`
woaixuejava.com
javascript
`;
console.log(hd.match(/.+/)[0]);
![]()
var hd =`
woaixuejava.com
javascript
`;
console.log(hd.match(/.+/s)[0]);

效果就是将多行的元素放在一行 然后打印后还原
因为.元字符不能匹配换行符,当匹配后遇到换行符时,将会结束,所以需要将其换成一行,这样就可以取得第一个元素了
匹配网址
//匹配网址
var url ="http://www.15821838384qq.com";
console.log(url.match(/^https?:\/\/www\.\w+\.\w+/));

匹配全部字符
原子表匹配字符
[\d\D] \d 表示匹配所有数字,\D表示匹配除数字以外的数字
另外还有\s\S 空格
[\w\W]等等
var hd =`
javascript
web
`;
console.log(hd.match(/[\d\D]+<\/span>/))

多行匹配m
//多行匹配
var hd=`
#1 javas,6000元 #
#42 web,6000元 #
#444 js,8000元 # 正则表示
#432 node,7000元 #
`;
console.log(hd.match(/\s+#\d+\s+.+\s+#\s/g));

第三行不符合规则,所以我们不需要他,因此我们进一步去除
hd.match(/^\s+#\d+\s+.+\s+#$/gm)
多行匹配一行一行进行测试
var less=hd.match(/^\s+#\d+\s+.+\s+#$/gm).map(v=>{
var v=v.replace(/\s+#\d+\s+/,"").replace(/\s+#/,"");
[name,price]=v.split(",");
return [name,price];
})
console.log(less);
汉字与字符属性 /u
//汉字与字符属性
//
var hd ="woaixuejs,2020.!";
//获取字符
console.log(hd.match(/\p{L}/ug));
//获取标点符号
console.log(hd.match(/\p{P}/ug));
![]()
lastIndex属性 (不会)
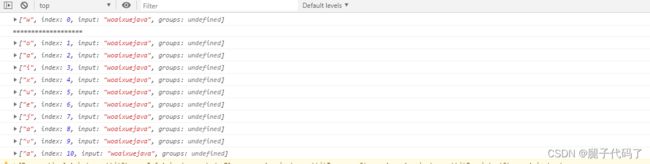
var hd = "woaixuejava";
var reg =/\w/g;
// console.log(hd.match(/\w/));
// console.log(/\w/g.lastIndex);
console.log(reg.exec(hd));
console.log("===================");
while((res=reg.exec(hd))){
console.log(res);
}
有效y使用
y使用方法是联合lastIndex配合使用。
var hd="欢迎拨打以下电话: 111111,222222,333333,拨打电话可获得vip课程会员";
//根据lastindex获取电话号码 ,不需要使用g全局查找,使用y有效连续查询即可
// var reg =/\d{6}/g;
// console.log(hd.match(reg));
var regg=/\d+,?/y;
var sa=[];
regg.lastIndex=10;
// console.log(hd.match(regg));
while((reg=regg.exec(hd))){
console.log(reg);
sa.push(reg[0]);
}
console.log(sa);

原子表的基本使用
var hd ="2021-02-03";
//匹配查出日期
console.log(hd.match(/\d+-\d+-\d+/));
有时候日期格式也为
2021/02/03 这样格式也是正确的,为此
var hd ="2021-02-03";
//匹配查出日期
console.log(hd.match(/\d+-\d+-\d+/));
var hd1="2021/02/03";
console.log(hd1.match(/\d+[-\/]\d+[-\/]\d+/));
console.log(hd.match(/\d+[-\/]\d+[-\/]\d+/));
[a,b]原子表的意思是为当匹配a或者b都为ture;
当然也可能会出现2021-02/03这种情况,这显然是不符合标准的,为此
console.log(hd.match(/\d+([-\/])\d+\1\d+/));
可以使间隔符号与前面保持一致;格式([a,b]) \1 与前面括号内保持一致;
原子表区间的特性
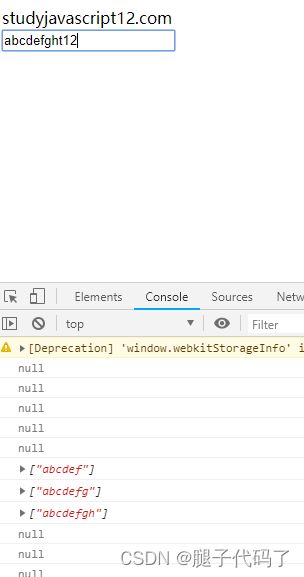
<input type="text" name="usename">
var usename=document.querySelector(`[name="usename"]`); //获取名字为usename的标签
usename.addEventListener("keyup",function(){ //添加键盘抬起事件
console.log(this.value.match(/^[a-z]\w{5,7}$/g)); //用户名6~8位
});
原子表排除匹配
//排除匹配
var hd ="woaixuejavascript";
console.log(hd.match(/[iu]/g)); //全局查找iu这两个字符
//排除^ ,除了iu
console.log(hd.match(/[^iu]/g)); //全局查找除了iu的其他字符

小栗子
var hd="张三:010-123456,李四:020-123456";
console.log(hd.match(/[^:,\d-]+/g));
![]()
原子表注意
[() .+] 在原子表内的()表示普通的括号,.和+也是普通的标点字符,
()在原子表外表示原子组。在原子表外需要转义
正则操作DOM元素
删除body中的h标签
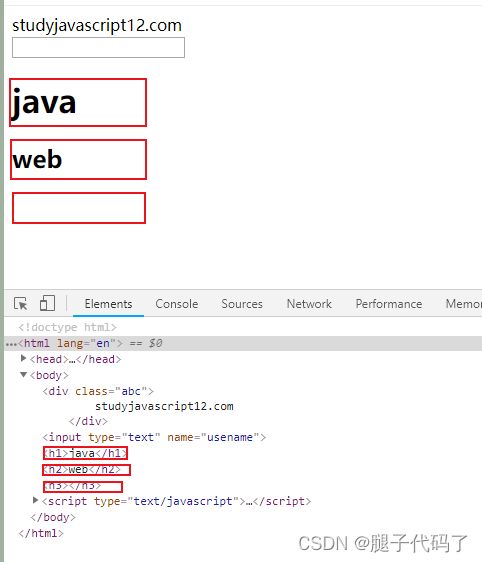
var body = document.body;
var reg =/<(h[1-6])>.+<\/\1>/gi;
body.innerHTML=body.innerHTML.replace(reg,"");

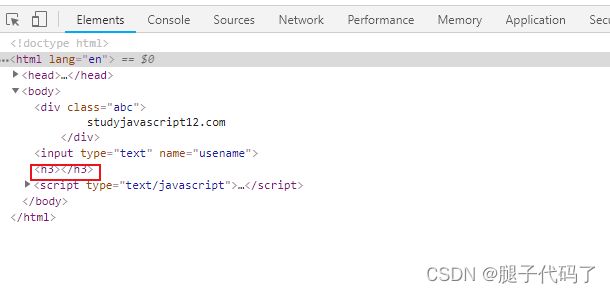
但是h3并没有删除
var body = document.body;
var reg =/<(h[1-6])>.*<\/\1>/gi;
body.innerHTML=body.innerHTML.replace(reg,"");
将+换成*就可以将
删除
这是因为*代表0个或者多个
值得注意的是,当
<h1>
java
h1>
这样时, 正则中的.就失去了作用,因此可以用
var body = document.body;
var reg =/<(h[1-6])>[\s\S]*<\/\1>/gi;
body.innerHTML=body.innerHTML.replace(reg,"");
或者\D\d都可以
mail案例测试
<input type="text" name="mail">
//mail
var mail =document.querySelector("[name='mail']");
mail.addEventListener("keyup",function(){
var hd =mail.value;
//[email protected]
//[email protected]
// var reg = /^\w+@\w+\.\w+$/i; // 满足一
var reg =/^\w+@(\w+\.)+\w+$/; //满足条件二
console.log(hd.match(reg));
});
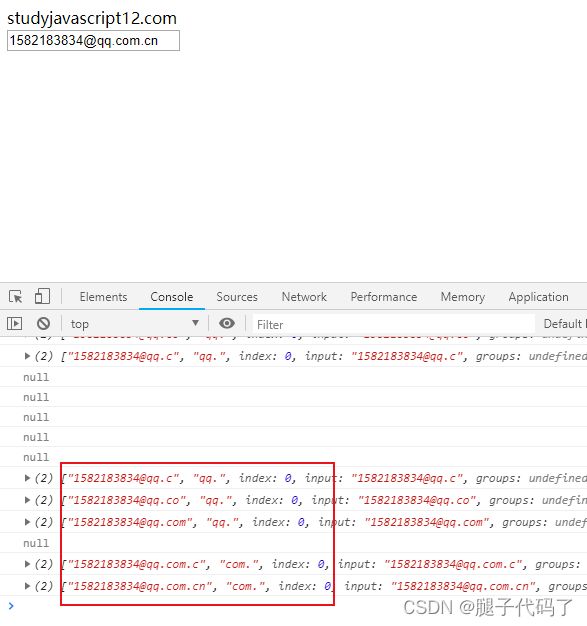
原子组在mail中的使用
原子组引用完成替换
操作要求,将标签替换成
标签
//原子组的替换使用
var hd=`
javas
web
webspring
`;
var reg =/<(h[1-6])>([\s\S]+)<\/\1>/ig;
console.log(hd.match(reg));
// hd.replace(reg,"$2
");
console.log(hd.replace(reg,"$2
"));
替换参数
hd.replace(reg,(p0,p1,p2,p3)=>{})
| 参数 | 实质 |
|---|---|
| p0 | javas |
| p1 | h1 |
| p2 | javas |
var reg =/<(h[1-6])>([\s\S]+)<\/\1>/gi;
var hs =hd.replace(reg,(p0,p1,p2)=>{
return `${p2}`;
});
console.log(hs);
嵌套分组和不记录分组
嵌套分组
var hd="https://www.xianzhe.com";
var reg=/https?:\/\/\w+\.\w+\.(com|org|cn)/;
console.log(hd.match(reg));
将www.xianzhe.com网址部分取出
var hd="https://www.xianzhe.com";
var reg=/https?:\/\/(\w+\.\w+\.(com|org|cn))/;
console.log(hd.match(reg));

如果不想让com加入,那么这就要使它进行不记录分组
?:
var reg=/https?:\/\/(\w+\.\w+\.(?:com|org|cn))/;
console.log(hd.match(reg));
举一个小栗子
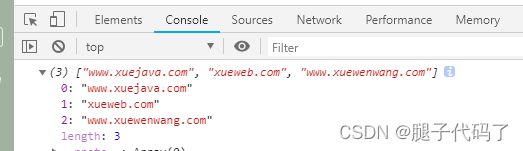
var hd="http://www.xuejava.com https://xueweb.com www.xuewenwang.com";
var reg=/((?:\w+\.)?\w+\.(?:com|cn|org))/gi;
console.log(hd.match(reg));
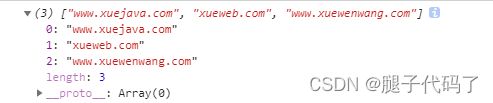
var hd="http://www.xuejava.com https://xueweb.com https://www.xuewenwang.com";
var reg=/https?:\/\/((?:\w+\.)?\w+\.(?:com|cn|org))/gi;
var h=[];
while((res=reg.exec(hd))){
h.push(res[1]);
}
console.log(h);
正则表达式应用
用户名验证
<input type="text" name="usename">
document.querySelector("[name='usename']").addEventListener("keyup",function(){
var value =this.value;
var reg =/^[a-z]\w{5,8}$/ig;
console.log(reg.test(value));
})
密码验证
document.querySelector("[name='password']").addEventListener("keyup",(e)=>{
var regs=[/^[a-z]\w{4,7}$/i,/[A-Z]/,/[0-9]/];
var pss=e.target.value;
var s=regs.every(e=>e.test(pss));
console.log(s);
})
多密码验证,必须是字母开头,必须有大写字母,必须有数字组成
获取value新方法 e.target.value;
every(function());
every方法必须满足数组内的所有条件才为true;否者全为false;
every更多介绍→https://www.runoob.com/jsref/jsref-every.html
禁止贪婪
var hd ="hdddd";
var reg =/hd+/;
console.log(hd.match(reg));
![]()
当开始匹配时,+会趋向于最大化,例如在上述+的例子,+表示一个或者多个,它默认贪婪,所以会匹配出后面所有的d
为此我们可以使它禁止贪婪
var hd ="hdddd";
var reg =/hd+?/;
console.log(hd.match(reg));
![]()
除此之外还有+*?等多种可以使用
| 符号 | 作用 |
|---|---|
| + | 表示多个 |
| * | 表示1个或多个 |
| ? | 表示0个或一个 |
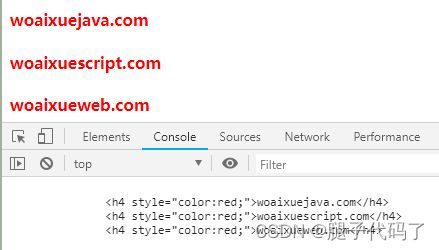
禁止贪婪应用
将 main.innerHTML=main.innerHTML.replace(…) 中中的main.innerHTML=main…很重要 打印出woaixuejava.com 和 woaixuescript.com 和woaixueweb.com 高版本浏览器使用,低版本使用不了 在matchAll属于迭代器,需要进行遍历输出才能获取内容 搜索方法 字符串的方法在,支持正则表达式 拆分方法 字符串的方法,支持正则 将一下电话号码格式替换为010-00000000格式 $1代表第一个原子组,$2代表弟二个原子组 $& 代表内容本身 $` 内容前一个 ! $’ 内容后一个 将目标成%%%java=== 为百度加上超链接 为超链接加上http中的s,并且没有www加上www,并且第三超链接不变 ?= 相当于条件语句,以为后面为。。。的 在下面我们只想找啊前面的这个你好。所以我们的目的就是要找到后面为啊的这个你好 举一个例子 百度是一个非常有用的网址,百度旗下有很多有用的内容。 我们需要为后面为旗下的百度加上百度的超链接。 ?<= 意味前面为某某的什么 百度是一个非常有用的网址,12345百度旗下有很多有用的内容。 查询 ?!后面不为。。的某元素 百度后面不是旗下的将会被选中。 ?
百度前面不是数字的百度将会被选中。 模糊电话号码查询 后四位数用*号代替 限制用户名关键词,不能包含“外挂”这两个字 使用断言排除选择 其他替换就可以 =/(?<=\d)百度/g; 百度后面不是旗下的将会被选中。 ?
百度前面不是数字的百度将会被选中。 模糊电话号码查询 后四位数用*号代替 限制用户名关键词,不能包含“外挂”这两个字 使用断言排除选择 其他替换就可以 <main>
<span>woaixuejava.comspan>
<span>woaixuescript.comspan>
<span>woaixueweb.comspan>
main>
var main =document.querySelector("main");
var reg = /([\S\s]+?)<\/span>/gi;
main.innerHTML=main.innerHTML.replace(reg,(v,p1)=>{
return `${p1}`;
});
console.log(main.innerHTML);
打印标签内容
<main>
<h1>woaixuejava.comh1>
<h2>woaixuescript.comh2>
<h1>woaixueweb.comh1>
main>
var main =document.querySelector("main");
var reg =/<(h[1-6])>([\s\S]+?)<\/\1>/gi;
var s=main.innerHTML.match(reg);
var shu=[];
for(var i=0;i<=s.length-1;i++){
var target=s[i].replace(/<(h[1-6])>/,"").replace(/<\/(h[1-6])>/,"");
shu.push(target);
}
console.log(shu);

matchAll
for(var iterator of hd){
console.log(iterator)
}
Search
var hd ="woaixuejavas";
hd.search("o");
//hd.search(/o/gi);
split
var hd ="2021-02-06";
hd.split("-");
//hd.split(/[\/-]/); 无论分隔符是-还是/都是可以拆分的
$在正则表达式中的应用
var hd ="(010)99999999 (020)88888888";
var reg=/\((\d{3,4})\)(\d{7,8})/g;
console.log(hd.replace(reg,"$1-$2"));
var hd="%java=";
reg=/java/g;
console.log(hd.replace(reg,"$&"));
![]()
var hd="%java=";
reg=/java/g;
console.log(hd.replace(reg,"$`"));
![]()
var hd="%java=";
reg=/java/g;
console.log(hd.replace(reg,"$'"));
![]()
var hd="%java=";
reg=/java/g;
console.log(hd.replace(reg,"$`$`$&$'$'"));
![]()
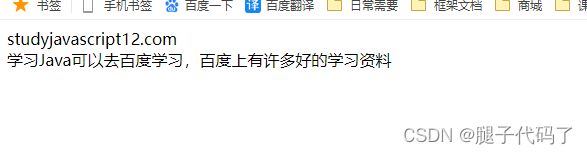
var main =document.querySelector("main");
main.innerHTML=main.innerHTML.replace(/百度/,"$&");

<main>
<a style="color:red;" href="http://www.baidu.com">百度a>
<a href="http://hello.com">你好a>
<a href="http://www.puter.com">皮套a>
<h5>wwww...h5>
main>

var main=document.querySelector("main");
var reg =/(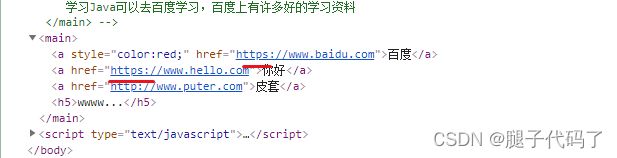
断言匹配
var hd ="你好呀还是你好啊更有礼貌!"
var reg=/你好(?=啊)/g
var main =document.querySelector("main");
var reg=/百度(?=旗下)/g;
main.innerHTML=main.innerHTML.replace(reg,"$&");

var main =document.querySelector("main");
var reg=/(?<=\d)百度/g;
main.innerHTML=main.innerHTML.replace(reg,"$&");
var reg =/百度(?!旗下)/g;
var reg =/(?/g;
var hd=`
张三: 12345678910,
里斯: 15566677780
`;
var reg =/(?<=\d{7})\d+/g;
var h=hd.replace(reg,()=>{
return "*".repeat(4);
});
console.log(h);
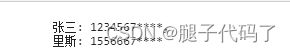
<main>
<input type="text" name="username">
main>
var username =document.querySelector("[name='username']");
username.addEventListener("keyup",(e)=>{
var value=e.target.value;
var reg=/^(?!.*外挂.*).*?\d{2,4}$/g;
var hd=value.match(reg);
console.log(hd);
});
<main>
<a href="https://orc.woaixuejava.com">1a>
<a href="https://oss.woaixueweb.com">2a>
<a href="https://sins.woaixuejava.com">3a>
<a href="https://woaixuejava.com">4a>
main>
var data=document.querySelector("main");
var reg =/https:\/\/(\w+)?(?/gi;
data.innerHTML.replace(reg,(v)=>{
console.log(v);
});
main.innerHTML=main.innerHTML.replace(reg,“$&”);
查询
?!后面不为。。的某元素
~~~javascript
var reg =/百度(?!旗下)/g;
var reg =/(?/g;
var hd=`
张三: 12345678910,
里斯: 15566677780
`;
var reg =/(?<=\d{7})\d+/g;
var h=hd.replace(reg,()=>{
return "*".repeat(4);
});
console.log(h);
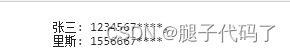
<main>
<input type="text" name="username">
main>
var username =document.querySelector("[name='username']");
username.addEventListener("keyup",(e)=>{
var value=e.target.value;
var reg=/^(?!.*外挂.*).*?\d{2,4}$/g;
var hd=value.match(reg);
console.log(hd);
});
<main>
<a href="https://orc.woaixuejava.com">1a>
<a href="https://oss.woaixueweb.com">2a>
<a href="https://sins.woaixuejava.com">3a>
<a href="https://woaixuejava.com">4a>
main>
var data=document.querySelector("main");
var reg =/https:\/\/(\w+)?(?/gi;
data.innerHTML.replace(reg,(v)=>{
console.log(v);
});