ModelScope-Agent初体验
简读Paper
ModelScope-Agent: Building Your Customizable Agent System with Open-source Large Language Models:https://arxiv.org/abs/2309.00986
1.Introduction
To enable the open-source LLMs to better control the whole agent system, we further propose a comprehensive framework of tool-use data collection, customized model training, evaluation and deployment. Notably, we release a comprehensive tool-enhanced dataset MSAgent-Bench, which consists of 598k dialogues with various API categories, multi-turn API calls, API-Oriented QA, and API-Agnostic instructions in both English and Chinese. A simple training strategy of WeightedLM, that enhances the training of generation of API name and parameters, is used to better ensure the correctness of API calls. Besides, an evaluation framework is also supported in our library to examine the tool-use abilities of the trained models in different aspects. Furthermore, we applied ModelScope-Agent in a real-world application of ModelScope Community namely ModelScopeGPT, which is able to connect open-source LLMs with more than 1000 public AI models and access localized community knowledge in ModelScope for community QA.
为了使开源llm能够更好地控制整个agent系统,我们进一步提出了一个工具使用数据收集、定制模型训练、评估和部署的综合框架。值得注意的是,我们发布了一个全面的工具增强数据集MSAgent-Bench,其中包括598k个带有各种API类别的对话,多轮API调用,面向API的QA和API不可知性的中英文指令。采用加权LM的简单训练策略,增强了API名称和参数生成的训练,更好地保证了API调用的正确性。此外,我们的库中还支持一个评估框架,以检查训练模型在不同方面的工具使用能力。此外,我们将ModelScope- agent应用于ModelScope Community的实际应用ModelScopeGPT,它能够将开源llm与1000多个公共AI模型连接起来,并在ModelScope中访问本地化的社区知识,用于社区QA。
To summarize, ModelScope-Agent is a general and customizable agent system designed for developers to harness the power of open-source LLMs.The library targets the following goals:
• Agent based on Open-Source LLMs: the controller of ModelScope-Agent can be flexibly
selected from open-source LLMs that are optimized through our agent training framework.
• Support and Customization of Diverse Tools:Dozens of diverse model APIs and common
APIs are given by default. The library supports registering new self-defined APIs and automatic API retrieval from the toolset.
• Customizable of Applications: ModelScopeAgent can be flexibly applied in various industry applications. The agent and training framework are documented describing its usage, construction and optimization.
ModelScope-Agent is in continual development by the engineers at ModelScope and is released under an Apache 2.0 license. Full documentation is available through the project website.
总而言之,ModelScope-Agent是一个通用的、可定制的Agent系统,专为开发人员设计,以利用开源llm的强大功能。
•基于开源llm的Agent: ModelScope-Agent的控制器可以灵活地从开源llm中选择,这些llm通过我们的Agent训练框架进行优化。
•支持和定制多种工具:默认提供数十种不同的模型api和通用api。该库支持注册新的自定义API和从工具集自动检索API。
•可定制的应用:ModelScopeAgent可以灵活地应用于各种行业应用。文档描述了Agent和训练框架的使用、构造和优化。
ModelScope- agent由ModelScope的工程师持续开发,并在Apache 2.0许可下发布。完整的文档可通过项目网站获得。
2.The ModelScope Agent
ModelScope-Agent is designed to facilitate developers in building customizable agent systems based on open-source LLMs. The overall system architecture is shown in Figure 1. It includes open-source LLMs as controller, a tool-use module and a memory module to interact with. Given human instruction, the Agent, which adopts the selected LLM as the controller, will automatically plan tasks, selectively uses tools, leverage knowledge in memory, and finally provides helpful responses to users.
ModelScope-Agent旨在帮助开发人员基于开源llm构建可定制的Agent系统。整个系统架构如图1所示。它包括开源llm作为控制器,一个工具使用模块和一个内存模块进行交互。在人类的指令下,Agent将选择的LLM作为控制器,自动规划任务,有选择地使用工具,利用内存中的知识,最终为用户提供有用的响应。
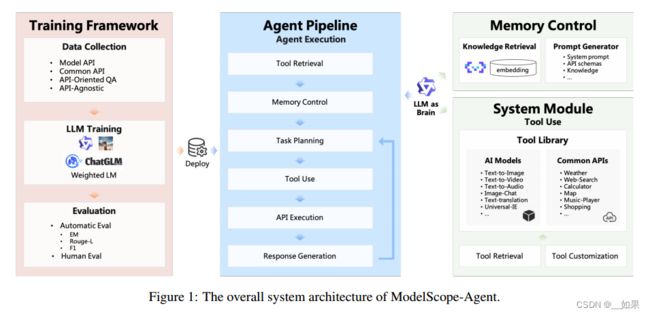
2.1.LLMs as Brain
LLMs serve as the brain of the agent, responsible for planning and decomposing user requests, selectively calling tools, performing retrieval, and integrating all the information from previous steps to generate the final response. In order to make it easier for users to customize the agent with their own LLMs, we have added support for various open-source LLMs by default, such as LLaMA, ChatGLM and ChatPLUG, which have been optimized through our tool learning pipeline. The details of training strategy and tool-use datasets can be referred to Section 3. ModelScope-Agent has integrated the LLM inference pipeline of the ModelScope community, and replacing LLMs can be done by simply setting the model_name and model_config. In model_config, the model_id, model_revision, and model parameter settings such as max sequence length, should be configured.
llm充当Agent的大脑,负责规划和分解用户请求,有选择地调用工具,执行检索,并集成来自前面步骤的所有信息以生成最终响应。为了方便用户使用自己的llm定制Agent,我们默认增加了对各种开源llm的支持,例如LLaMA, ChatGLM和ChatPLUG,这些都是通过我们的工具学习pipline进行优化的。训练策略和工具使用数据集的细节可参考第3节。ModelScope- agent集成了ModelScope社区的LLM推理pipline,只需设置model_name和model_config即可替换LLM。在model_config中,应该配置model_id、model_revision和模型参数设置,例如最大序列长度。
# LLM config " cfg_file "
from modelscope . utils . config import Config
model_cfg = Config . from_file ( cfg_file )
llm = LocalLLM ( model_name , model_cfg )Furthermore, the ModelScope-Agent also provides a standard way to integrate new LLM. Users can add their own LLMs, by integrating the LLM pipeline into ModelScope. After that, the agent can select the new LLMs for training and inference.
此外,ModelScope-Agent还提供了一种集成新LLM的标准方法。用户可以通过将LLMpipline集成到ModelScope中来添加他们自己的LLM。之后,智能体可以选择新的llm进行训练和推理。
2.2.Tool Use
Tool Library
The tool library is used to configure and manage various collections of APIs used in the agent. ModelScope-Agent can support a wide range of both common APIs such as search APIs, and AI model APIs across NLP, CV, Audio and Multi-modal models in ModelScope and HuggingFace. Each tool API consists of the API name, description, parameters and request functions. Users can easily choose and configure proper APIs in the library to build their own agent. The default APIs supported in the library can be referred to Appendix A.1.
工具库用于配置和管理Agent中使用的各种api集合。ModelScope- agent可以支持广泛的常见api,如搜索api,以及ModelScope和HuggingFace中的NLP, CV, Audio和多模态模型中的AI模型api。每个工具API由API名称、描述、参数和请求函数组成。用户可以很容易地在库中选择和配置适当的api来构建自己的Agent。库中支持的默认api可参考附录A.1。
# tool default config file " default_file "
tool_cfg = Config.from_file(default_file)Register and Customize New Tool
The agent allows users to register and customize new tools, while also supporting quick integration of newly registered tools into the agent, enabling LLMs to selectively use the additional self-defined tools for specific applications. This can be simply done by inheriting from a base class, namely Tool, and defining a new CustomTool with the API-related schema of API name, description, parameters, and request functions. More details about CustomTool can be referred in Appendix A.2.
Agent允许用户注册和定制新工具,同时还支持将新注册的工具快速集成到Agent中,使llm能够有选择地为特定应用程序使用额外的自定义工具。这可以简单地通过继承基类(即Tool),并使用API名称、描述、参数和请求函数的API相关模式定义新的CustomTool来完成。有关CustomTool的更多详细信息请参见附录A.2。
from modelscope_agent . tools import Tool
class CustomTool(Tool):
# logic added here
# refer example in Appendix A.2
tool_list = {'customo-tool': CustomTool()}Tool Retrieval and Execution
Due to the large amount of tool APIs in the tool library, a tool retrieval module is further introduced to recommend appropriate APIs for each instruction prompt. Specifically, we use the dense vector retrieval method based on the unified multilingual textembedding API. We vectorize both the text descriptions of the APIs and the instruction prompt using the text-embedding API. The top-3 most relevant APIs with the highest vector product scores are selected for tool use. As a result, the schema information of the retrieved APIs will be concatenated with other system prompts in the subsequent memory module and sent to LLMs as input. With the concatenated instruction prompt, the LLMs will plan and generate the API request, which will be executed by the agent. The agent will then return the results to the LLMs for continuous generation.
由于工具库中有大量的工具api,因此进一步引入了工具检索模块,为每个指令提示推荐合适的api。
具体来说,我们使用了基于统一多语言文本模板API 6的密集向量检索方法。我们对API的文本描述和使用文本嵌入API的指令提示进行了矢量化。具有最高矢量产品分数的前3个最相关的api被选择用于工具使用。因此,检索到的api的模式信息将与后续内存模块中的其他系统提示连接起来,并作为输入发送给llm。使用连接的指令提示符,llm将计划并生成API请求,该请求将由Agent执行。然后,Agent将结果返回给llm进行连续生成。
2.3.Memory Control
The memory module is used to retrieve, and assemble a series of contextual information as input to the LLMs. It consists of a knowledge retrieval submodule and a prompt generator submodule, which are responsible for external knowledge retrieval and instruction prompt generation, respectively.
内存模块用于检索和组合一系列上下文信息,作为llm的输入。它由知识检索子模块和提示生成器子模块组成,分别负责外部知识检索和指令提示生成。
Knowledge Retrieval
It enables the agent to get access to up-to-date and localized information related with query prompt, thereby augmenting LLMs with dynamic and domain-specific knowledge. We follow the same dense vector retrieval method as the previous tool retrieval module, and support large-scale knowledge retrieval from localized document corpus. Similarly, it allows users to customize by changing to other open-source retrieval frameworks.
它使Agent能够访问与查询提示相关的最新和本地化的信息,从而用动态和特定于领域的知识增强llm。我们采用与之前的工具检索模块相同的密集向量检索方法,支持从本地化文档语料库中大规模检索知识。类似地,它允许用户通过更改为其他开源检索框架来进行定制。
Prompt Generator
The prompt generator is used to assemble all available contextual information
such as system prompt, API schema, retrieved knowledge, conversation history, and few-shot examples. According to the type of user query and the maximum length of the LLM, the users can selectively choose proper contextual information and assemble the required input to the LLM. In our agent, the prompt generator needs to be defined before the agent is constructed.
提示生成器用于组合所有可用的上下文信息,如系统提示、API模式、检索的知识、对话历史记录和少量示例。根据用户查询的类型和LLM的最大长度,用户可以选择性地选择合适的上下文信息,并将所需的输入组合到LLM中。在我们的Agent中,需要在构造Agent之前定义提示生成器。
2.4.Agent Pipeline
In summary, we build the agent by combining all the modules: LLM controller, tool-use module, and memory module. With agent.run, the agent can efficiently execute and complete the instruction in a one-step generation. First, the agent retrieves query-related tools through the tool retrieval and combines the retrieved API schema with other contextual prompts in memory module, to construct a new instruction prompt. Then, the agent sends
this new prompt to the LLM, who plans whether and which API to call and generate an API request. Next, the agent will execute the selected API with the extracted API parameters and return the API results to the LLMs, which will continue to plan whether to call other APIs. If another API call is needed, the process is repeated, otherwise, the LLMs generate the final response and the agent returns the final result to the user.
总之,我们通过组合所有模块来构建Agent:LLM控制器、工具使用模块和内存模块。使用agent.run,Agent可以在一步生成中有效地执行和完成指令。首先,Agent通过工具检索与查询相关的工具,并将检索到的API模式与内存模块中的其他上下文提示结合起来,构造新的指令提示。然后,Agent将这个新提示发送给LLM, LLM计划是否调用以及调用哪个API并生成API请求。
接下来,Agent将使用提取的API参数执行选定的API,并将API结果返回给llm, llm将继续计划是否调用其他API。如果需要另一个API调用,则重复该过程,否则,llm生成最终响应,Agent将最终结果返回给用户。
agent = AgentExecutor(llm, tool_cfg, additional_tool_list = tool_list)
agent.run(" Draw a logo image of agent ")3.Training
3.1.Dataset
To facilitate building an agent with the ability to use tools while upholding an optimal level of
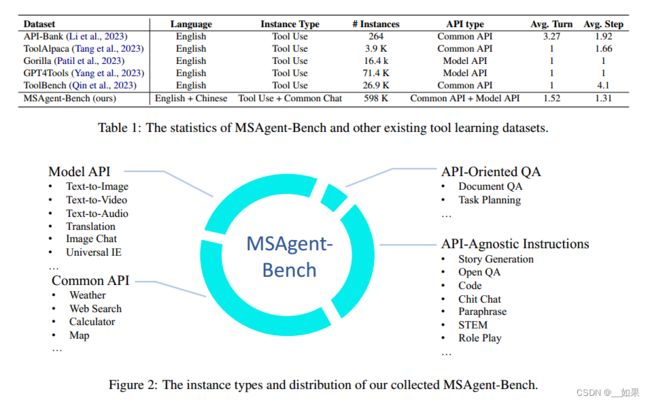
user engagement, we release a comprehensive tool dataset, MSAgent-Bench, utilizing ChatGPT synthetic data and the existing instruction-following datasets. Our released dataset encompasses 598k dialogues. Table 1 outlines the key differences between the released dataset and other public available tool learning datasets, while the data distribution of our dataset is illustrated in Figure 2. As demonstrated in the Table and Figure, we have
made certain efforts to construct a comprehensive dataset which enables the effective training of an agent.
为了方便构建一个能够使用工具的Agent,同时保持最佳的用户参与度,我们发布了一个综合的工具数据集,MSAgent-Bench7,利用ChatGPT合成数据和现有的指令遵循数据集。我们发布的数据集包含598k个对话。表1概述了发布的数据集与其他公共可用工具学习数据集之间的主要区别,而我们的数据集的数据分布如图2所示。如表和图所示,我们已经做出了一定的努力来构建一个全面的数据集,从而能够有效地训练agent。
3.2.Model Training
We use the MSAgent-Bench to fine-tune multiple open-source LLMs, including LLaMA (Touvron et al., 2023), Qwen (QwenLM, 2023), ChatPLUG (Tian et al., 2023) etc. We train all the opensource LLMs in a multi-round conversation mode and concatenate all the prompts and answers.
我们使用MSAgent-Bench对多个开源llm进行微调,包括LLaMA (Touvron等人,2023),Qwen (QwenLM, 2023), ChatPLUG (Tian等人,2023)等。我们以多轮对话模式培训所有开源Agent,并将所有提示和答案连接起来。
Compared to common instruction tuning data, the tool learning samples focus more heavily on the accuracy of tool selection and API parameter prediction. Therefore, we propose a simple training strategy, Weighted LM, which enhances the training of generation of API name and parameters, while zeroout the loss of tokens from the user prompt and the tool execution. More details can be be referred to Appendix B.3.
与普通指令调优数据相比,该工具学习样本更侧重于工具选择和API参数预测的准确性。因此,我们提出一个简单的训练策略,加权LM,增强了API名称和参数生成的训练,同时消除了用户提示和标记的丢失工具执行。详情请参阅附录B.3。
kwargs = dict (model = model, ...)
trainer: EpochBasedTrainer = build_trainer
(name = args.trainer, default_args = kwargs)
trainer.train()5.Usage Example of ModelScopeGPT
ModelScope Intelligent Assistant
Based on ModelScope-Agent , we have developed an intelligent assistant for the ModelScope Community, namely ModelScopeGPT. It uses LLMs as a controller to connect dozens of domain-specific AI models in the ModelScope open-source community,
covering NLP, CV, Audio, and Multi-Modal fields. To make the pipeline more practical, we have included API retrieval and knowledge retrieval tool to automatically select proper APIs and get access to the local ModelScope knowledge. As shown in Figure 3a, ModelScopeGPT can support API calls in multi-turn conversations and generate correct API call parameters using information from previous conversations. More cases can refer to Appendix C. As a result, ModelScopeGPT has achieved a total request number of over 170k from 40k user visits within one month after its release.
基于ModelScope- agent,我们为ModelScope社区开发了一个智能助手ModelScopeGPT。它使用llm作为控制器来连接ModelScope开源社区中的数十个特定领域的AI模型,涵盖NLP, CV, Audio和Multi-Modal领域。
为了使pipline更加实用,我们包含了API检索和知识检索工具,以自动选择适当的API并访问本地ModelScope知识。如图3a所示,ModelScopeGPT可以支持多轮对话中的API调用,并使用来自先前对话的信息生成正确的API调用参数。更多案例可参考附录C。
因此,ModelScopeGPT在发布后的一个月内从4万用户访问中获得了超过17万的总请求数。
Register and Use New Tools
Another key feature of an agent is its generalization capability to unseen APIs. This allows users to quickly register their own APIs and customize their specific applications. Therefore, we test the generalization ability of ModelScopeGPT by applying it to an Alibaba Cloud application scenario. As shown in Figure 3b, we first found an API for renewing an ECS instance on Alibaba Cloud. Then, we registered the API schema defined in the tool library to the agent. Finally, we entered the prompt "Please help me renew an ECS..." in the demo. The agent generated a request through planning, selected the appropriate API, called the API to renew the instance successfully, and provided a reply to inform the user that the renewal was completed. This test demonstrates that the open-source LLM optimized based on the released API dataset has a strong generalization ability towards unseen APIs.
Agent的另一个关键特性是它对看不见的api的泛化能力。这允许用户快速注册自己的api并自定义特定的应用程序。因此,我们通过将ModelScopeGPT应用于阿里云应用场景来测试其泛化能力。如图3b所示,我们首先找到了一个用于在阿里云上更新ECS实例的API。然后,我们将工具库中定义的API模式注册到Agent。
最后,我们在演示中输入提示“Please help me renew an ECS…”。Agent通过规划生成请求,选择适当的API,调用API以成功更新实例,并提供应答以通知用户更新已完成。该测试表明,基于已发布API数据集优化的开源LLM对未见API具有较强的泛化能力。
创建第一个Agent
GG安慰侠 · 创空间 (modelscope.cn)
其实也没有啥好的idea,单纯觉得好玩建的
经过一轮轮的反馈把这个Agent变得更像GGB了一些
找了个心理咨询问答语料库,这是心理咨询领域首个开放的 QA 语料库,包括 20,000 条心理咨询数据,也是迄今公开的最大的中文心理咨询对话语料(发稿日期 2022-04-07)chatopera/efaqa-corpus-zh: ❤️Emotional First Aid Dataset, 心理咨询问答、聊天机器人语料库 (github.com)
尝试
(1)聊天的时候它说可以为我提供一些工作信息或者书籍信息的资源,我琢磨着也没给你API你咋回我,测试后果不其然是在瞎编,但是就去试着找了找这方面的API,知乎的、各种招聘网站的,但是招聘网站这类API接口还是挺难找的,大部分只能让你投简历之类的
(2)想着安慰人这种东西,语音还是要比文字更温暖的,所以想练一个GGB的声音。扒了个Bert-ViTs2练,但是网上的教程千奇百怪,好不容易调好一些,又发现算力要求不够,3080好像都要跑好几个小时,就放弃了
fishaudio/Bert-VITS2: vits2 backbone with multilingual-bert (github.com)
audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim at main (huggingface.co)