从 MQTT、InfluxDB 将数据无缝接入 TDengine,接入功能与 Logstash 类似
利用 TDengine Enterprise 和 TDengine Cloud 的数据接入功能,我们现在能够将 MQTT、InfluxDB 中的数据通过规则无缝转换至 TDengine 中,在降低成本的同时,也为用户的数据转换工作提供了极大的便捷性。由于该功能在实现及使用上与 Logstash 类似,本文将结合 Logstash 为大家进行解读。
偏向于日志收集整理的 Logstash
Logstash 是一个开源的实时数据收集处理引擎,通常作为 ETL 工具使用,它可以根据转换规则将数据从多种数据源中采集并转换数据,然后发送到指定的存储中。其通常与 ElasticSearch(ES)、Kibana、Beats 共同使用,形成免费开源工具组合 Elastic Stack(又称 ELK Stack),适用于数据的采集、扩充、存储、分析和可视化等工作。
Logstash 可以由 Beats、Kafka、DataSource 等数据源将数据转换写入 ES、MySQL 等数据库中进行存储:

数据流转总体分为三部分:Input、Filter、Output,这三部分的定义覆盖了数据整个的生命周期。Input 和 Output 支持编解码器,使用编解码器,可以在数据进入或退出管道时进行编码或解码,而不必使用单独的过滤器。原始数据在 Input 中被转换为 Event,在 Output 中 Event 被转换为目标式数据,在配置文件中可以对 Event 中的属性进行增删改查。


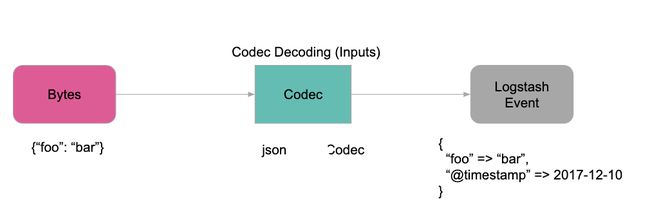
其中,Filter 是 Logstash 功能强大的主要原因,它可以对 Logstash Event 进行丰富的处理,比如解析数据、删除字段、类型转换等等,常见的有如以下几个:
- date 日期解析
- grok 正则匹配解析
- 正则表达式:
- Debuggex: Online visual regex tester. JavaScript, Python, and PCRE.
- RegExr: Learn, Build, & Test RegEx
- Grok
- kibana – grokdebugger
- https://github.com/elastic/logstash/tree/v1.4.2/patterns
- GitHub - logstash-plugins/logstash-patterns-core
- Grok Debugger | Autocomplete and Live Match Highlghting
- 正则表达式:
- dissect 分割符解析
- mutate 可以对事件中的数据进行修改,包括 rename、update、replace、convert、split、gsub、uppercase、lowercase、strip、remove_field、join、merge 等功能。
- json 按照 json 解析字段内容到指定字段中
- geoip 增加地理位置数据
- ruby 利用 ruby 代码来动态修改 Logstash Event
filter {
grok => {
match => {
"message" => "%{SERVICE:service}"
}
pattern_definitions => {
"SERVICE" => "[a-z0-9]{10,11}"
}
}
}Logstash 在实时数据处理方面有一定的能力,也有一定的流行性,但并不是所有场景下都适用 Logstash。针对多种数据源的收集,TDengine 打造了自己的数据接入功能。
TDengine:针对多种数据源的收集
如果你使用 Elasticsearch 和 Kibana 来构建日志管理、数据分析和可视化解决方案,Logstash 可能是一个不错的选择,因为它与 Elasticsearch 的集成非常紧密。但 Logstash 并不适用于处理大规模时序数据,它在处理大量数据时会消耗大量的系统资源,包括内存和 CPU,在数据量很大的情况下甚至会导致出现性能问题,它的可扩展性在处理大规模数据时也可能受到限制。而且如果你最初接触 Logstash,那你会需要付出较高的学习成本,因为 Logstash 在处理数据的各个阶段(输入、过滤、输出)需要正确配置,错误的配置可能会导致数据丢失或格式错误。
这也是 TDengine 打造自己的数据接入功能的一些主要原因,如果你正在使用 TDengine,那这一功能一定能帮助你更便捷、更低成本地进行数据转换工作。
目前利用 TDengine 数据接入功能,你可以轻松从 MQTT、InfluxDB 等服务器获取数据,并高效地写入 TDengine 数据库中,实现数据的顺畅集成和分析。这一功能负责整个过程的自动化数据接入,最大限度地减少了手动操作的工作量。同时它还具备以下特点:
- 支持 JSON 格式:充分利用 JSON 的灵活性,使用户能够以 JSON 格式进行数据摄取和存储。机构可以有效地构建和管理数据,从复杂数据结构中挖掘有价值的见解。
- 支持 JSON path 提取字段:TDengine 支持 JSON path 提取,在处理 JSON 数据时更加轻松。通过精确选择和捕获所需的数据元素,用户可以专注于数据集的核心内容,最大化分析效率。
- 简单配置:提供了易于使用的配置文件,您可以在其中指定 TDengine 的超级表、子表、列和标签,轻松定制数据接入流程以满足特定需求。
另外 TDengine 的数据接入后还可以进行数据清洗和转换,用户可以根据业务需要设计相应的数据清洗和转换规则,实现完整的数据 ETL 流程。借助上述创新功能,实时数据可以实现与高性能的 TDengine 数据库的无缝结合,实时分析、预防性维护和数据驱动决策也拥有了无限可能。
配置方法很简单,你只需要登录到 TDengine 企业版或 TDengine Cloud 的 Web 管理界面,选择 Data in 并添加 MQTT 作为数据源,简单配置一下 InfluxDB/MQTT 数据对应到 TDengine 库、超级表、子表的解析规则即可。具体配置方案可见《TDengine 推出重磅功能,让 MQTT 无缝数据接入更加简单》《TDengine 数据接入功能支持 InfluxDB 啦!》
TDengine 3.0 企业版和 TDengine Cloud 凭借简洁易用的命令行操作,为用户提供了高效、可靠的数据接入方法。无论你是想要从 InfluxDB/MQTT 迁移数据,还是想将多个数据源的数据集中到 TDengine 中,TDengine 3.0 企业版和 TDengine Cloud 都能够满足你的需求。
如果你对这一数据接入功能感兴趣或正面临数据接入难题,可以添加小T vx:tdengine,和 TDengine 的资深研发直接进行沟通。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。