光伏储能数据难题很棘手?架构升级很迷茫?来看三大真实案例
近年来,随着光伏储能装置的增加,设备数量和测点数量也在相应增加,数据采集频率也在不断提高,由此产生的时序数据量越来越庞大,对数据处理和实时分析的要求也越来越高。同时光伏储能系统需要长期保存大量的历史数据,以便进行回溯分析和趋势预测,海量历史数据的存储和管理也成为一个挑战,亟需高效的存储解决方案。在此背景下,为了更精准地监测和控制光伏储能系统,光伏储能领域的部分企业开始尝试采用更先进的数据管理和分析技术,进行数据架构的全面升级。
在本篇文章中,我们汇总了一批较为典型的光伏储能项目的数据架构改造真实案例,给到大家参考。
国轩高科海外储能项目:数据压缩率轻松达到 10% 以内
“对我们这个体量相对较小的场景来说,TDengine Cloud 按量计费加全托管的企业级服务让我们用非常小的成本便运转了这个项目,并且极大地增加了产品的效率并保留了随时扩张的灵活性。此外,数据分享、流式计算这些有趣的特性也等待我们进行更深一步地挖掘。”
改造方案
国轩高科在“海外某储能项目”中,需要实时监测电池安全,采集记录每次使用的充放电过程、电流/电压等值,而此类数据都带有时间戳,是典型的时序数据。为了应对未来海量的用户使用数据,其决定选择一款专业的时序数据库(Time Series Database,TSDB),并于去年在海外本地化成功部署了时序数据库 TDengine 2.x 版本。为了更便捷地进行该数据库的应用,国轩高科在今年选择将业务部署在物联网、工业大数据云服务平台 TDengine Cloud 上,其带来的最直观帮助就是全托管。
据了解,由于 TDengine Cloud 附带和 TDengine Enterprise(企业版)同级别的服务,因此国轩高科不再需要担心部署、优化、扩容、备份、异地容灾等事务,减少了开发人员的负担,可全心关注核心业务。在云服务版本选择上,由于该项目设备量暂时不多,根据官方现有的定价规则,基础版本便可满足。在经过计费方案估算器计算后,最终国轩高科选择了 1200 元/月的基础版规格。

改造效果
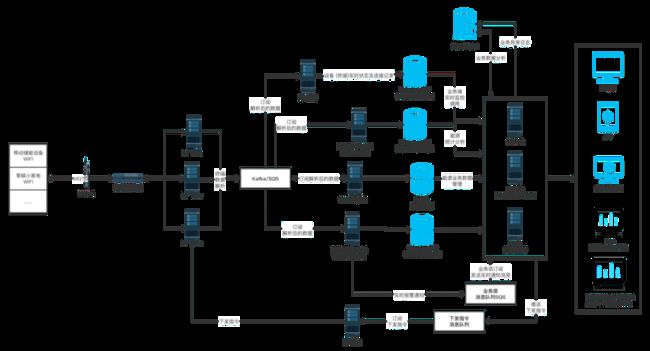
该项目的数据处理流程如下图所示,某类储能设备产生的时序数据会以 MQTT 方式上传,其中业务数据转发给 PostgreSQL,设备产生的时序数据以及设备运行日志、设备状态数据转给 TDengine。中台各系统则会统一规划使用这些数据库中的数据,来用于分析计算,也可以直接控制设备下发指令。最终,借助 PC Web、APP 以及其他管理平台等软件方式在前端体现。
在测试阶段,TDengine 的数据压缩率可以轻松达到 10% 以内,每秒可以写入数百万行数据,在具体实践中也很好地达到了这一压缩及写入效果;在查询方面,完美地支持了该项目中的各类查询,比如监测用电产品的健康状态、分析设备用电量趋势、使用寿命等等。值得一提的是,该应用与 TDengine Cloud 所属同一个 AWS region,因此通过使用 Private Link 功能,其应用网络就能够与云服务进行私密通信,而无需将数据通过公网传输,大大降低了写入方面的延迟,同时也进一步节约了由网络流量产生的费用。
点此查看案例详情
日增 40 亿条数据的光伏日电系统:读写性能提升 10 倍
“目前我们根据不同的测点类型建立了不同的超级表,按照不同的测点 ID 以及测点号作为 tag 创建了不同的子表。这样我们针对于测点可以直接进行单表分析,处理性能高、速度快;也可以针对多测点进行分析,直接操作超级表,业务实现简单,同时兼顾了查询性能。”
改造方案
八五信息在新能源电力物联网平台上,需要对物联网设备的实时数据以及光伏设备传感器的遥测数据进行存储和查询分析,规划设计数据存储规模大概在 16TB 左右,目前数据日增量为 1 亿多条,全部测点接入后预计日增量为 40 多亿条左右;系统需支撑至少 50000 台设备总计 400 万测点(信号量和模拟量)的实时数据接入、处理及存储。在查询上,应用系统的常规查询在 50QPS 左右,高并发在 100QPS 左右。一次历史数据查询分析最大跨度为一年且支撑多测点多模式分析方式。

此前该平台使用 TimescaleDB 进行这些数据的处理,无论在读写性能,还是硬件资源上,都遇到了瓶颈,且没有集群功能。为了破解这一困境,八五信息选择接入 TDengine,主要用于光伏设备遥测实时数据的存储、查询和分析。
改造效果
改造完成后,读写性能较原 TimescaleDB 数据库提高 10 倍左右,在数据接入层不用再担心数据库的写入性能瓶颈;数据分析查询应用层也较原系统有较大提升,尤其是在面对时间跨度大的聚合类分析时几乎瞬间响应;在集群功能方面,TimescaleDB 虽支持流复制方式的主备库但没有集群功能,TDengine 在这点上更有优势,其集群容易搭建且无主从节点区分,对应用改造和支撑较友好,集群版读写性能提升较大。
在计算及存储资源上,应用 TDengine 后,降低了大约 4 倍左右的存储成本。在未使用 TDengine 之前,TimescaleDB 开启压缩后对 70 亿数据量占用磁盘为 165GB,且一分钟内无法查询出一个月的历史数据;而在使用 TDengine 之后磁盘占用空间为 40GB 左右,且能够毫秒级返回针对一个月的历史数据的聚合查询。此外,通过乱序插入功能,TDengine 还解决了边缘侧由于网络问题导致的数据传输不及时造成的乱序写入问题,保证了数据的完整性。
点此查看案例详情
上海电气储能系统:毫秒级响应电站运行信息监视
“此次方案改造非常成功,我们还将在后续项目中,继续拓展其分布式集群应用,构建储能电站运行情况的数字化档案,结合开发的分析算法、预测算法、数据挖掘技术,实现电站稳定性分析、效率和损耗分析、故障预测、寿命预测、性能短板定位以及热管理分析等高级分析和诊断功能。”
改造方案
为帮助客户实现储能设备的最优配置和高效利用,上海电气打造“SmartOPS 储能智慧运维系统”,支持云端部署和本地部署两种方式,其中,本地部署需要重点考虑本地硬件资源的限制,如站端系统的内存、CPU 以及读写性能等,为此上海电气开始进行技术选型,以挑选适合在站端系统中部署的时序数据库。

待选数据库方案包括 OpenTSDB、InfluxDB、Apache IoTDB、TDengine、ClickHouse。基于站端本地化部署需要轻量级资源占用出发,上海电气首先排除 OpenTSDB、Apache IoTDB 以及 ClickHouse,OpenTSDB 是由于其基于 HBase 进行设计,架构比较重,而 Apache IoTDB 在资源占用方面对边缘轻量级设备也不算友好;ClickHouse 的优势是单表快,但其他方面偏弱,包括 join、管理运维都比较复杂。研发团队最终圈定在 InfluxDB 和 TDengine 中进行测试选择。在经过一系列测试对比后,TDengine 成功胜出。
改造效果
目前该项目技术团队已采用 TDengine 作为 SCU(Station Control Unit) 架构的核心时序数据库,实现储能系统综合信息感知、就地运行控制与协调保护功能;同时支持储能电站及设备的远程运维,实现高级数据分析与运行优化,全方面守护储能电站的安全。
TDengine 高性能的写入和聚合查询功能,能够毫秒级响应电站运行信息监视。在压缩方面,对比此前使用 InfluxDB 时 1 天 200 多 MB 的数据存储,在采集点数量相同的情况下,使用 TDengine 后,1 天的数据存储低于 70 MB,是 InfluxDB 的 1/3。在查询上,对比使用 InfluxDB 一个月时间后执行查询,内存使用率达到 80%,并且过了十分钟也没出来结果,在应用 TDengine 近1个月后,使用相同的 SQL 语句,查询只需要 0.2 秒。

点此查看案例详情
结语
术业有专攻,从上述实践中我们也能看到,专业的数据库做专业的事情,在面对光伏储能设备产生的海量时序数据的处理上,时序数据库效果更为显著。TDengine 具备 10 倍以上的性能提升、简单易用的时序数据平台、完全实时的数据共享能力以及顶级的开源软件四大核心竞争力,这也让 TDengine 成为国内外数十万用户的选择,成为光储用户的不二之选。如果你也面临着数据难题,可以添加小T vx:tdengine,与 TDengine 专业的解决方案架构师直接沟通,寻找架构改造最优解。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。