数据同步利器之seatunnel篇
前言
前面几篇文章分别介绍了hadoop生态圈的一些组件,但都是用来处理和接收消息的,虽然也具备同步数据的能力,但或多或少的都会涉及一些编程相关的知识,对于只是简单快速的数据同步需求来说,可能稍显麻烦,这时候就如果有一个数据同步的工具,只需修改下配置的模式,即可根据配置文件的不同来同步不同的数据,效率会提升很多,而且受众面会更广,不知道大家平时项目中都接触过哪些数据同步工具,我这边目前接触的比较多的就是sqoop、datax,下面我来介绍下关于数据同步工具的新起之秀seatunel,在经历2.1.x到2.3.x版本的更新,该工具支持的功能越来越丰富,而且执行引擎除了支持spark和flink外,还新增了zeta引擎,并且支持分布式部署,另外还包括了大量的connector插件,下面就关于该组件的安装部署内容展开讲解
提示:以下内容仅供参考
一、seatunel是什么?
seatunnel是一种数据集成平台,前身为waterdrop,后更名为seatunnel加入apache,其特点是分布式、高性能、易扩展、海量同步和转化,不仅支持spark和flink引擎,更是在2.3版本推出了自带的zeta引擎,除了支持普通的离线数据同步还支持CDC实时同步。
二、安装部署
1.下载安装包
登录seatunnel官网下载地址:https://seatunnel.apache.org/zh-CN/download/,选择apache-seatunnel-2.3.3-bin.tar.gz二进制安装包,执行以下命令解压、修改名称
tar -zxvf apache-seatunnel-2.3.3-bin.tar.gz
mv apache-seatunnel-2.3.3-bin seatunnel
2.配置环境变量
vim /etc/profie.d/my_env.sh打开并编辑配置文件,输入以下内容
export SEATUNNEL_HOME=/application/soft/seatunnel
export PATH=$PATH:$SEATUNNEL_HOME/bin
文件保存后,执行source /etc/profile使环境变量生效
3.修改Seatunnel Engine JVM
vim $SEATUNNEL_HOME/bin/seatunnel-cluster.sh打开并编辑配置文件,添加以下内容
JAVA_OPTS="-Xms2G -Xmx2G"
4.修改Seatunnel Engine配置文件
需要修改$SEATUNNEL_HOME/config目录下的seatunnel.yaml和hazelcast.yaml这两个文件,
提示:以下为seatunnel.yaml的配置,注意空格缩进
seatunnel:
engine:
history-job-expire-minutes: 1440
backup-count: 1
queue-type: blockingqueue
print-execution-info-interval: 60
print-job-metrics-info-interval: 60
slot-service:
dynamic-slot: true
checkpoint:
interval: 10000
timeout: 60000
max-concurrent: 1
tolerable-failure: 2
storage:
type: hdfs
max-retained: 3
plugin-config:
storage.type: hdfs
fs.defaultFS: hdfs://cdp1:8020
提示:以下为hazelcast.yaml的配置,注意空格缩进
hazelcast:
cluster-name: seatunnel
network:
rest-api:
enabled: true
endpoint-groups:
CLUSTER_WRITE:
enabled: true
DATA:
enabled: true
join:
tcp-ip:
enabled: true
member-list:
- cdp1
- cdp2
- cdp3
port:
auto-increment: false
port: 5801
properties:
hazelcast.invocation.max.retry.count: 20
hazelcast.tcp.join.port.try.count: 30
提示:注意三个节点配置保持一致
5.启动seatunnel集群
执行mkdir -p $SEATUNNEL_HOME/logs
进入seatunel安装目录,执行命令bin/seatunnel-cluster.sh -d以启动seatunnelserver服务,三个节点都执行,可通过jps命令查看服务是否启动
6.任务提交
进入seatunnel安装目录,执行bin/seatunnel.sh --config ./config/v2.batch.config.template查看能否成功运行,在看到以下信息说明测试样例运行成功
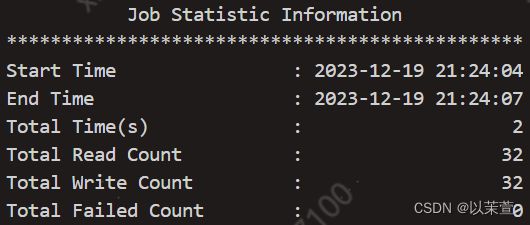
可在mvn地址离线下载自己所需的source连接器https://repo.maven.apache.org/maven2/org/apache/seatunnel/,将下载好的连接器放入到$SEATUNNEL_HOME/connectors/seatunnel目录下,将sink端所需驱动放入到SEATUNEL_HOME/lib目录下,数据同步任务配置文件可参考v2.batch.config.template,以下样是同步mysql到hive的一个样例
提示:模板配置信息可根据自身环境不同,自行修改
env {
execution.parallelism = 3
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://xx.xx.xx.xx:3306/test?seSSL=false"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 1000
user = "*****"
password = "*******"
query = "select * from test.a_test"
}
}
sink {
Hive {
table_name = "ods.a_test"
metastore_uri= "thrift://cdp1:9083"
hive_site_path = "/application/soft/hive-3.1.3/conf/hive-site.xml"
hdfs_site_path = "/application/soft/hadoop-3.3.3/etc/hadoop/hdfs-site.xml"
}
}
总结
至此,seatunnel集群就已经部署完成了,看过seatunel官网介绍过跟datax的数据同步效率对比,大概提升了20%-40%,本人经过实测,速度确实更快了,而且配置比datax的json格式更为简单,seatunnel还提供了transform中间转换功能,当然了由于seatunel是后起之秀,还有不少需要完善改进的空间,但发展前景还是挺好的,希望有越来越多优秀的工具能够出现,由于篇幅有限,今天就聊到这里,如果有兴趣的话,你可以去试试这个工具。