Netty-2-数据编解码
解析编解码支持的原理
以编码为例,要将对象序列化成字节流,你可以使用MessageToByteEncoder或MessageToMessageEncoder类。

这两个类都继承自ChannelOutboundHandlerAdapter适配器类,用于进行数据的转换。
其中,对于MessageToMessageEncoder来说,如果把口标设置为ByteBuf,那么效果等同于使用MessageToByteEncodero这就是它们都可以进行数据编码的原因。
//MessageToMessageEncoder
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
// 创建一个CodecOutputList对象,并将其初始化为null
CodecOutputList out = null;
try {
// 检查消息是否满足输出条件
if (acceptOutboundMessage(msg)) {
// 创建一个CodecOutputList对象,并将其赋值给out变量
out = CodecOutputList.newInstance();
// 将msg强制转换为I类型,并赋值给cast变量
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
// 调用encode方法,将ctx、cast和out作为参数传入
encode(ctx, cast, out);
} catch (Throwable th) {
// 释放cast的引用计数
ReferenceCountUtil.safeRelease(cast);
// 抛出异常
PlatformDependent.throwException(th);
}
// 释放cast的引用计数
ReferenceCountUtil.release(cast);
// 检查out是否为空
if (out.isEmpty()) {
// 抛出编码异常
throw new EncoderException(
StringUtil.simpleClassName(this) + " must produce at least one message.");
}
} else {
// 直接将msg写入通道
ctx.write(msg, promise);
}
} catch (EncoderException e) {
// 抛出编码异常
throw e;
} catch (Throwable t) {
// 抛出编码异常
throw new EncoderException(t);
} finally {
// 最终,释放out的引用计数
if (out != null) {
try {
// 获取out的元素个数
final int sizeMinusOne = out.size() - 1;
if (sizeMinusOne == 0) {
// 将out的第一个元素直接写入通道
ctx.write(out.getUnsafe(0), promise);
} else if (sizeMinusOne > 0) {
// 检查promise是否为voidPromise
if (promise == ctx.voidPromise()) {
// 使用voidPromise来减少GC压力
writeVoidPromise(ctx, out);
} else {
// 使用writePromiseCombiner方法来减少GC压力
writePromiseCombiner(ctx, out, promise);
}
}
} finally {
// 释放out的资源
out.recycle();
}
}
}
}
protected abstract void encode(ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception;
最终的目标是把对象转换为ByteBuf,具体的转换代码则委托子类继承的encode方法来实现。
Netty提供了很多子类来支持前面提及的各种数据编码方式。
解析典型Netty数据编解码的实现
HttpObjectEncoder编码器
//HttpObjectEncoder编码器
@Override
@SuppressWarnings("ConditionCoveredByFurtherCondition")
protected void encode(ChannelHandlerContext ctx, Object msg, List<Object> out) throws Exception {
// 为了处理不需要类检查的常见模式的fast-path
if (msg == Unpooled.EMPTY_BUFFER) {
out.add(Unpooled.EMPTY_BUFFER);
return;
}
// 以这种顺序进行instanceof检查的原因是,不依赖于ReferenceCountUtil::release作为一种通用释放机制,
// 参见https://bugs.openjdk.org/browse/JDK-8180450。
// https://github.com/netty/netty/issues/12708包含有关先前版本的此代码如何与JIT instanceof优化交互的更多详细信息。
if (msg instanceof FullHttpMessage) {
encodeFullHttpMessage(ctx, msg, out);
return;
}
// 判断msg是否为HttpMessage的实例
if (msg instanceof HttpMessage) {
final H m;
try {
// 将msg转换为H类型
m = (H) msg;
} catch (Exception rethrow) {
// 出现异常时,释放msg的引用计数并抛出异常
ReferenceCountUtil.release(msg);
throw rethrow;
}
// 判断m是否为LastHttpContent的实例
if (m instanceof LastHttpContent) {
// 调用encodeHttpMessageLastContent方法对LastHttpContent进行编码
encodeHttpMessageLastContent(ctx, m, out);
}
// 判断m是否为HttpContent的实例
else if (m instanceof HttpContent) {
// 调用encodeHttpMessageNotLastContent方法对HttpContent进行编码
encodeHttpMessageNotLastContent(ctx, m, out);
}
// m既不是LastHttpContent也不是HttpContent的实例
else {
// 调用encodeJustHttpMessage方法对m进行编码
encodeJustHttpMessage(ctx, m, out);
}
}
// msg不是HttpMessage的实例
else {
// 调用encodeNotHttpMessageContentTypes方法对非HttpMessage的内容类型进行编码
encodeNotHttpMessageContentTypes(ctx, msg, out);
}
}
HttpObjectDecoder解码器
//HttpObjectDecoder.java
/**
* 定义了一个私有枚举类型State,表示不同的状态
*/
private enum State {
/**
* 用于跳过控制字符
*/
SKIP_CONTROL_CHARS,
/**
* 读取初始内容
*/
READ_INITIAL,
/**
* 读取头部信息
*/
READ_HEADER,
/**
* 读取可变长度的内容
*/
READ_VARIABLE_LENGTH_CONTENT,
/**
* 读取固定长度的内容
*/
READ_FIXED_LENGTH_CONTENT,
/**
* 读取分块大小
*/
READ_CHUNK_SIZE,
/**
* 读取分块内容
*/
READ_CHUNKED_CONTENT,
/**
* 读取分块分隔符
*/
READ_CHUNK_DELIMITER,
/**
* 读取分块脚注
*/
READ_CHUNK_FOOTER,
/**
* 错误消息
*/
BAD_MESSAGE,
/**
* 升级协议
*/
UPGRADED
}
//解码器相应实现
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception {
// 如果 resetRequested 为真
if (resetRequested) {
// 调用 resetNow() 方法
resetNow();
}
switch (currentState) {
case SKIP_CONTROL_CHARS:
// 跳过控制字符
case READ_INITIAL: try {
// 解析缓冲区中的数据
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
// 拆分初始行
String[] initialLine = splitInitialLine(line);
if (initialLine.length < 3) {
// 初始行无效 - 忽略
currentState = State.SKIP_CONTROL_CHARS;
return;
}
// 创建消息对象
message = createMessage(initialLine);
currentState = State.READ_HEADER;
// 继续读取头部
} catch (Exception e) {
// 处理异常情况
out.add(invalidMessage(buffer, e));
return;
}
case READ_HEADER: try {
State nextState = readHeaders(buffer);
if (nextState == null) {
return;
}
currentState = nextState;
switch (nextState) {
case SKIP_CONTROL_CHARS:
// 快速路径
// 无需期望任何内容
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
case READ_CHUNK_SIZE:
if (!chunkedSupported) {
throw new IllegalArgumentException("不支持分块消息");
}
// 分块编码 - 首先生成HttpMessage。后续将跟随HttpChunks。
out.add(message);
return;
default:
/**
* RFC 7230, 3.3.3 规定,如果请求没有传输编码头或内容长度头,则消息体长度为0。
* 但是对于响应,body长度是在服务器关闭连接之前接收到的字节数目。因此我们将此情况视为可变长度的分块编码。
*/
long contentLength = contentLength();
if (contentLength == 0 || contentLength == -1 && isDecodingRequest()) {
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
}
assert nextState == State.READ_FIXED_LENGTH_CONTENT ||
nextState == State.READ_VARIABLE_LENGTH_CONTENT;
out.add(message);
if (nextState == State.READ_FIXED_LENGTH_CONTENT) {
// 随着READ_FIXED_LENGTH_CONTENT状态逐块读取数据,分块大小将减小。
chunkSize = contentLength;
}
// 在这里返回,这将强制再次调用解码方法,在那里我们将解码内容
return;
}
} catch (Exception e) {
out.add(invalidMessage(buffer, e));
return;
}
case READ_VARIABLE_LENGTH_CONTENT: {
// 一直读取数据直到连接结束。
int toRead = Math.min(buffer.readableBytes(), maxChunkSize);
if (toRead > 0) {
// 从缓冲区中读取指定长度的数据,并以保留引用的形式分割成多个片段
ByteBuf content = buffer.readRetainedSlice(toRead);
out.add(new DefaultHttpContent(content));
}
return;
}
case READ_FIXED_LENGTH_CONTENT: {
int readLimit = buffer.readableBytes();
// 首先检查缓冲区是否可读,因为我们使用可读字节计数来创建HttpChunk。需要这样做,以防止创建包含空缓冲区的HttpChunk,从而被当作最后一个HttpChunk进行处理。
// 参见:https://github.com/netty/netty/issues/433
if (readLimit == 0) {
return;
}
int toRead = Math.min(readLimit, maxChunkSize);
if (toRead > chunkSize) {
toRead = (int) chunkSize;
}
ByteBuf content = buffer.readRetainedSlice(toRead);
chunkSize -= toRead;
if (chunkSize == 0) {
// 读取所有内容。
out.add(new DefaultLastHttpContent(content, validateHeaders));
resetNow();
} else {
out.add(new DefaultHttpContent(content));
}
return;
}
/**
* 从这里开始处理读取分块的内容。基本上,读取分块大小,读取分块,忽略CRLF,然后重复直到分块大小为0
*/
case READ_CHUNK_SIZE: try {
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
int chunkSize = getChunkSize(line.toString());
this.chunkSize = chunkSize;
if (chunkSize == 0) {
currentState = State.READ_CHUNK_FOOTER;
return;
}
currentState = State.READ_CHUNKED_CONTENT;
// fall-through
} catch (Exception e) {
out.add(invalidChunk(buffer, e));
return;
}
case READ_CHUNKED_CONTENT: {
// 判断chunkSize是否小于等于Integer的最大值
assert chunkSize <= Integer.MAX_VALUE;
// 计算本次需要读取的字节数,取chunkSize和maxChunkSize中的较小值
int toRead = Math.min((int) chunkSize, maxChunkSize);
// 如果不允许部分chunk,且buffer中可读取的字节数小于toRead,则返回
if (!allowPartialChunks && buffer.readableBytes() < toRead) {
return;
}
// 如果buffer中可读取的字节数小于toRead,则将toRead更新为buffer中可读取的字节数
toRead = Math.min(toRead, buffer.readableBytes());
// 如果toRead为0,则返回
if (toRead == 0) {
return;
}
// 从buffer中获取长度为toRead的slice,并用其创建HttpContent对象
HttpContent chunk = new DefaultHttpContent(buffer.readRetainedSlice(toRead));
// 更新剩余的chunkSize
chunkSize -= toRead;
// 将chunk添加到out中
// 如果chunkSize不为0,则返回
if (chunkSize != 0) {
return;
}
// 设置当前状态为READ_CHUNK_DELIMITER
currentState = State.READ_CHUNK_DELIMITER;
// 继续执行下一个case语句
// fall-through
}
case READ_CHUNK_DELIMITER: {
// 读取分隔符
final int wIdx = buffer.writerIndex();
int rIdx = buffer.readerIndex();
while (wIdx > rIdx) {
byte next = buffer.getByte(rIdx++);
if (next == HttpConstants.LF) {
currentState = State.READ_CHUNK_SIZE;
break;
}
}
buffer.readerIndex(rIdx);
return;
}
case READ_CHUNK_FOOTER: {
try {
// 读取尾部的Http头部信息
LastHttpContent trailer = readTrailingHeaders(buffer);
if (trailer == null) {
return;
}
out.add(trailer);
resetNow();
return;
} catch (Exception e) {
// 发生异常时,将异常信息和当前buffer一起添加到输出channel
out.add(invalidChunk(buffer, e));
return;
}
}
case BAD_MESSAGE: {
// 直到断开连接为止,丢弃消息
buffer.skipBytes(buffer.readableBytes());
break;
}
case UPGRADED: {
int readableBytes = buffer.readableBytes();
if (readableBytes > 0) {
// 读取可读字节数,如果大于0,则执行以下操作
// 由于否则可能会触发一个DecoderException异常,其他处理器会在某个时刻替换此codec为升级的协议codec来接管流量。
// 参见 https://github.com/netty/netty/issues/2173
out.add(buffer.readBytes(readableBytes));
}
break;
}
default:
break;
}
}
自定义编解码
下面先实现一个Netty编码处理程序。
public class OrderProtocolEncoder extends MessageToMessageEncoder<ResponseMessage> {
/**
* 编码器类,用于将ResponseMessage对象编码为ByteBuf对象并添加到输出列表中
*/
@Override
protected void encode(ChannelHandlerContext ctx, ResponseMessage responseMessage, List<Object> out) throws Exception {
/**
* 获取一个ByteBuf对象用于存储编码后的数据
*/
ByteBuf buffer = ctx.alloc().buffer();
/**
* 对ResponseMessage对象进行编码,并将编码后的数据写入ByteBuf对象中
*/
responseMessage.encode(buffer);
/**
* 将编码后的ByteBuf对象添加到输出列表中
*/
out.add(buffer);
}
}
接下来,再实现对应的Netty解码处理程序。
/**
* 订单协议解码器
*/
public class OrderProtocolDecoder extends MessageToMessageDecoder<ByteBuf> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf byteBuf, List<Object> out) throws Exception {
// 创建一个请求消息对象
RequestMessage requestMessage = new RequestMessage();
// 对字节缓冲区进行解码,将解码后的消息填充到请求消息对象中
requestMessage.decode(byteBuf);
// 将请求消息对象添加到输出列表中
out.add(requestMessage);
}
}
最后,将这对编解码处理程序添加到处理程序流水线(pipeline)中就可以完成集成工作了。
这是我们第一次提及处理程序流水线这个概念。在这里,只需要将它理解成"一串”有序的处理程序集合并有一个初步印象即可,后续会详细介绍相关内容。
为了完成处理程序流水线的设置,还要构建ServerBootstrap这个“启动”对象。
ServerBootstrap serverBootstrap = new ServerBootstrap(); // 创建一个ServerBootstrap对象
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() { // 为子通道设置ChannelInitializer处理器
@Override
protected void initChannel(NioSocketChannel ch) throws Exception { // 初始化连接通道
ChannelPipeline pipeline = ch.pipeline(); // 获取通道的编排器
// 省略其他非核心代码
pipeline.addLast("protocolDecoder", new OrderProtocolDecoder()); // 添加一个解码器到通道的最后
pipeline.addLast("protocolEncoder", new OrderProtocolEncoder()); // 添加一个编码器到通道的最后
// 省略其他非核心代码
}
});
常见疑问解析
为什么Netty自带的编解码方案很少有人使用
其中个很重要的因素就是历史原因,但实际上,除历史原因之外,更重要的原因在于Netty自带的编解码方案大多是具有封帧和解帧功能的编解码器,并且融两层编码于一体,因此从结构上看并不清晰。
另外,Netty自带的编解码方案在使用方式上不够灵活。
在进行序列化和反序列时,字段的顺序弄反了
我们在序列化对象的字段时,使用的顺序是a b c;但是,等到我们解析时,顺序可能不小心写成了 c b a, 因此,我们一定要完全对照好顺序才行。
编解码的顺序问题
有时候,我们往往采用多层编解码。
例如,在得到可传输的字节流之后,我们可能想压缩一下以进一步减少所传输内容占用的空间。
此时,多级编解码就可以派上用场了:对于发送者, 先编码后压缩;而对于接收者,先解压后解码。
但是,代码的添加顺序和我们想要的顺序不一定完全匹配。如果顺序错了,那么代码可能无法工作。
if (compressor != null) {
pipeline.addLast("frameDecompressorn", new Frame.Decompressor(compressor));
pipeline.addLast("frameCompressor", new Frame.Compressor(compressor));
pipeline.addLast("messageDecoder", messageDecoder);
pipeline.addLast("messageEncoder", messageEncoderFor(protocolversion));
}
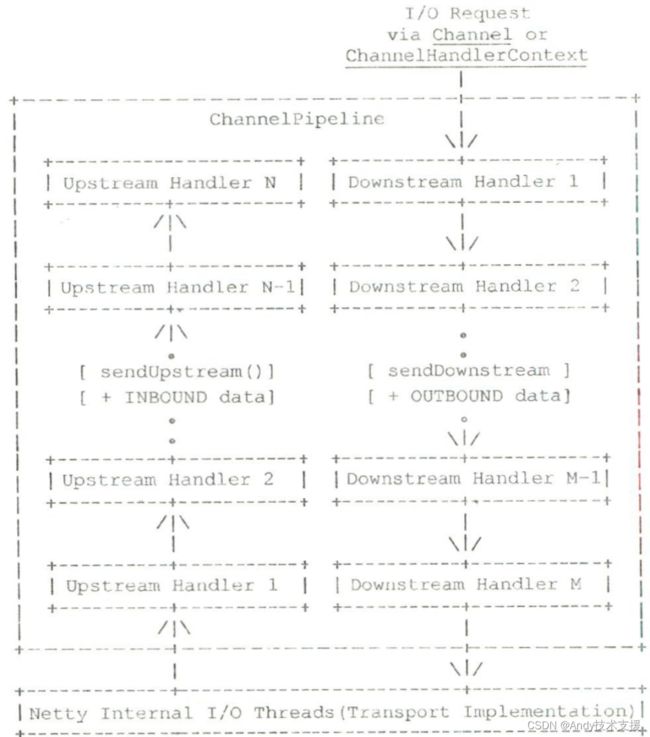
处理程序对于读取操作和写出操作的执行顺序刚好是相反的。