java中的三大集合框架(List,Set,Map)
1.集合的继承结构

2.集合和数组的区别
集合的特点:
- 类型不固定,可以随意存放任何数据。长度也不固定,可以根据元素的增长而增长。
- 集合只能存储引用数据类型(对象),集合存储基本数据类型会进行自动装箱,变成对象。
数组的特点:
- 类型固定,只能存储同一种类型的数据。长度固定,只能存储数组定义时,确定的长度。
- 数组可以存储引用数据类型,又可以存储基本数据类型,其中基本数据类型存储的是值,引用数据类型存储的是地址值。
3.集合的使用方式
1.ArrayList
介绍:ArrayList是实现List接口的集合,底层采用数组(Object)实现,是没有固定长度的。
构造函数
ArrayList():默认构造函数,提供初始容量为10的空列表。
ArrayList(int initialCapacity):构造一个具有指定初始容量的空列表。
ArrayList(Collection c) : 构造一个包含指定collection的元素的列表,这些元素是按照该collection的迭代器返回它们的顺序排列的。
常用方法
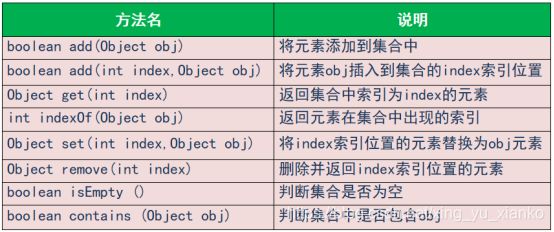
2.LinkedList
介绍:存储原理是一个链表,在元素的前后分别有一个前置结点和后置结点,用于连接集合中的上一个元素和下一个元素,依次“手拉手”,构成一条链式数据的集合。
构造函数
LinkedList<类> list = new LinkedList<类>(); LinkedList<类> list = new
LinkedList(Collection c); 使用一个集合创建一个新的linkedList。
常用方法

3.HashSet
介绍:存储一组唯一(不允许出现重复的元素),无序(没有index下标)的对象,HashSet是Set接口常用的实现类。可以用来去重。
构造方法
private transient HashMap<E,Object> map;
//默认构造器
public HashSet() {
map = new HashMap<>();
}
//将传入的集合添加到HashSet的构造器
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//明确初始容量和装载因子的构造器
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//仅明确初始容量的构造器(装载因子默认0.75)
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
常用方法
add方法:向集合中添加元素,并且返回一个boolean值,添加成功返回ture,添加失败返回false。
remove方法:
//HashSet的remove方法
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
//map的remove方法
public V remove(Object key) {
Node<K,V> e;
//通过hash(key)找到元素在数组中的位置,再调用removeNode方法删除
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
/**
*
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//步骤1.需要先找到key所对应Node的准确位置,首先通过(n - 1) & hash找到数组对应位置上的第一个node
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//1.1 如果这个node刚好key值相同,运气好,找到了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
/**
* 1.2 运气不好,在数组中找到的Node虽然hash相同了,但key值不同,很明显不对, 我们需要遍历继续
* 往下找;
*/
else if ((e = p.next) != null) {
//1.2.1 如果是TreeNode类型,说明HashMap当前是通过数组+红黑树来实现存储的,遍历红黑树找到对应node
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//1.2.2 如果是链表,遍历链表找到对应node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//通过前面的步骤1找到了对应的Node,现在我们就需要删除它了
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
/**
* 如果是TreeNode类型,删除方法是通过红黑树节点删除实现的,具体可以参考【TreeMap原理实现
* 及常用方法】
*/
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
/**
* 如果是链表的情况,当找到的节点就是数组hash位置的第一个元素,那么该元素删除后,直接将数组
* 第一个位置的引用指向链表的下一个即可
*/
else if (node == p)
tab[index] = node.next;
/**
* 如果找到的本来就是链表上的节点,也简单,将待删除节点的上一个节点的next指向待删除节点的
* next,隔离开待删除节点即可
*/
else
p.next = node.next;
++modCount;
--size;
//删除后可能存在存储结构的调整,可参考【LinkedHashMap如何保证顺序性】中remove方法
afterNodeRemoval(node);
return node;
}
}
return null;
}
遍历方法:
public static void main(String[] args) {
HashSet<String> setString = new HashSet<> ();
setString.add("星期一");
setString.add("星期二");
setString.add("星期三");
setString.add("星期四");
setString.add("星期五");
Iterator it = setString.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
4.HashMap
介绍:
用于存储Key-Value键值对的集合(每一个键值对也叫做一个Entry)(无顺序)。
根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值。
键key为null的记录至多只允许一条,值value为null的记录可以有多条。
非线程安全。
HashMap是由数组+链表+红黑树(JDK1.8后增加了红黑树部分,链表长度超过阈值(8)时会将链表转换为红黑树)实现的。
HashMap与Hashtable区别:
Hashtable是synchronized的。
Hashtable不可以接受为null的键值(key)和值(value)。
数组 + 链表 + 红黑树
数组是用来确定桶的位置(寻址容易,插入和删除困难):
数组的查找效率比LinkedList大。
HashMap中数组扩容刚好是2的次幂,在做取模运算的效率高,而ArrayList的扩容机制是1.5倍扩容。链表是用来解决hash冲突问题,当出现hash值一样的情形,就在数组上的对应位置形成一条链表(寻址困难,插入和删除容易)(链地址法)。
链表转为红黑树:
当元素小于8个当时候,此时做查询操作,链表结构已经能保证查询性能。
当元素大于8个的时候,此时需要红黑树来加快查询速度,但是新增节点的效率会变慢。当链表转为红黑树后,元素个数是6会退化为链表:
中间有个差值7可以防止链表和树之间频繁的转换。
构造方法
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
常用方法

HashMap集合遍历的三种方法:
1.遍历所有的key键
Set keys=map.keySet();//取出所有的key,存入set集合
for(Object key:keys){
System.out.println(key);
}
2.遍历所有的value值
Collection values=map.values();//取出所有的value,存入
for(Object v:valuse){
System.out.println(v);
}
3.遍历所有的key 、 value
Set set=map.entrySet();
for(Object o:set){
Map.Entry entry=(Map.Entry)o; // 类型转换
System.out.println(entry.getKey()+"-"+entry.getValue());
}