【数据结构入门精讲 | 第十六篇】并查集知识点及考研408、企业面试练习
上一篇中我们进行了散列表的相关练习,在这一篇中我们要学习的是并查集。

目录
-
- 概念
- 伪代码
- 选择题
- 填空题
- 编程题
-
- 7-1 朋友圈
- R7-1 笛卡尔树
- R7-2 部落
- R7-3 秀恩爱分得快
在许多实际应用场景中,我们需要对元素进行分组,并且在这些分组中进行查询和修改操作。比如,在图论中,我们需要将节点按照连通性进行分组,以便进行最小生成树、最短路径等算法;在计算机视觉中,我们需要将像素进行分组,以便进行图像分割和对象识别等任务。而并查集正是为了解决这些问题而被提出来的一种数据结构。
概念
并查集(Disjoint Set)是一种用于处理元素分组的数据结构,通常用于解决一些与等价关系有关的问题,比如连通性的判断、最小生成树算法中的边的合并等。
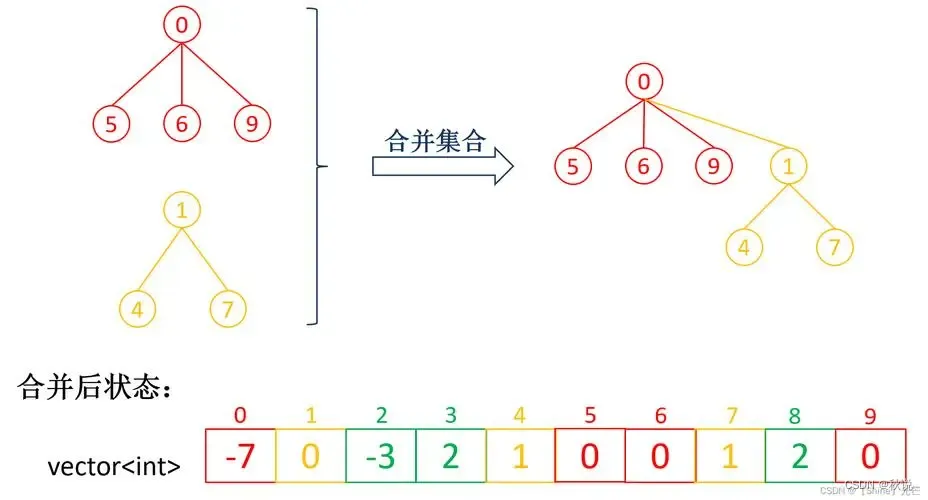
并查集中的每个元素都属于一个集合,每个集合都有一个代表元素(也称为根节点),代表元素可以用来表示整个集合。并查集支持三个基本操作:
1.MakeSet(x):创建一个只包含元素 x 的新集合;
2.Find(x):返回元素 x 所属的集合的代表元素;
3.Union(x, y):将元素 x 和 y 所属的集合合并成一个新集合。
其中,Find 操作可以使用路径压缩(Path Compression)和按秩合并(Union by Rank)优化,以提高查询效率。
并查集的应用非常广泛,比如在图论算法中求解连通性、求解最小生成树等问题时都会用到。
伪代码
// 初始化并查集,每个元素单独成集合
function MakeSet(x)
x.parent = x
x.rank = 0
// 查找元素所属的集合(根节点),并进行路径压缩
function Find(x)
if x.parent != x
x.parent = Find(x.parent) // 路径压缩:将x的父节点设为根节点
return x.parent
// 合并两个集合,按秩合并
function Union(x, y)
xRoot = Find(x)
yRoot = Find(y)
if xRoot == yRoot
return // 已经在同一个集合中,无需合并
if xRoot.rank < yRoot.rank
xRoot.parent = yRoot
else if xRoot.rank > yRoot.rank
yRoot.parent = xRoot
else
yRoot.parent = xRoot
xRoot.rank = xRoot.rank + 1
接下来,让我们进行并查集的相关练习。
选择题
1.
选B
2.
解析:
1 -4 1 1 -3 4 4 8 -2
0 1 2 3 4 5 6 7 8
1对应-4,则1是根节点且有4个子孙
又因为0、2、3都对应1
所以
1
0 2 3 null
4对应-3,则4是根节点且有3个子孙
又因为5、6都对应4
所以
4
5 6 null
8对应-2,则8是根节点且有2个子孙
又因为7对应8
所以
8
7 null
将6与8所在的集合合并,且小集合合并到大集合
则
4
5 6 8
7 null
所以树根是4,对应的编号是-5(-表示树根,5表示4的子孙个数)
3.
可以画出来对应的树
然后把小树连到大树上
接着从1到7遍历
如果有父节点,给出父节点的值
如果它本身是根节点,则给出负号和子孙个数

填空题
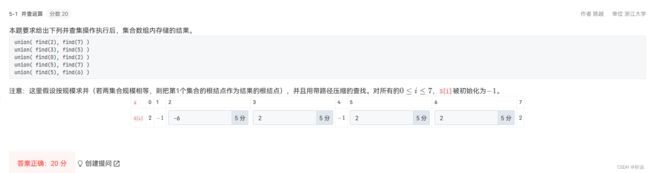

编程题
7-1 朋友圈
某学校有N个学生,形成M个俱乐部。每个俱乐部里的学生有着一定相似的兴趣爱好,形成一个朋友圈。一个学生可以同时属于若干个不同的俱乐部。根据“我的朋友的朋友也是我的朋友”这个推论可以得出,如果A和B是朋友,且B和C是朋友,则A和C也是朋友。请编写程序计算最大朋友圈中有多少人。
输入格式:
输入的第一行包含两个正整数N(≤30000)和M(≤1000),分别代表学校的学生总数和俱乐部的个数。后面的M行每行按以下格式给出1个俱乐部的信息,其中学生从1~N编号:
第i个俱乐部的人数Mi(空格)学生1(空格)学生2 … 学生Mi
输出格式:
输出给出一个整数,表示在最大朋友圈中有多少人。
输入样例:
7 4
3 1 2 3
2 1 4
3 5 6 7
1 6
输出样例:
4
#includeR7-1 笛卡尔树
笛卡尔树是一种特殊的二叉树,其结点包含两个关键字K1和K2。首先笛卡尔树是关于K1的二叉搜索树,即结点左子树的所有K1值都比该结点的K1值小,右子树则大。其次所有结点的K2关键字满足优先队列(不妨设为最小堆)的顺序要求,即该结点的K2值比其子树中所有结点的K2值小。给定一棵二叉树,请判断该树是否笛卡尔树。
输入格式:
输入首先给出正整数N(≤1000),为树中结点的个数。随后N行,每行给出一个结点的信息,包括:结点的K1值、K2值、左孩子结点编号、右孩子结点编号。设结点从0~(N-1)顺序编号。若某结点不存在孩子结点,则该位置给出−1。
输出格式:
输出YES如果该树是一棵笛卡尔树;否则输出NO。
输入样例1:
6
8 27 5 1
9 40 -1 -1
10 20 0 3
12 21 -1 4
15 22 -1 -1
5 35 -1 -1
输出样例1:
YES
输入样例2:
6
8 27 5 1
9 40 -1 -1
10 20 0 3
12 11 -1 4
15 22 -1 -1
50 35 -1 -1
输出样例2:
NO
#includeR7-2 部落
在一个社区里,每个人都有自己的小圈子,还可能同时属于很多不同的朋友圈。我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同一个部落。
输入格式:
输入在第一行给出一个正整数N(≤104),是已知小圈子的个数。随后N行,每行按下列格式给出一个小圈子里的人:
K P[1] P[2] ⋯ P[K]
其中K是小圈子里的人数,P[i](i=1,⋯,K)是小圈子里每个人的编号。这里所有人的编号从1开始连续编号,最大编号不会超过104。
之后一行给出一个非负整数Q(≤104),是查询次数。随后Q行,每行给出一对被查询的人的编号。
输出格式:
首先在一行中输出这个社区的总人数、以及互不相交的部落的个数。随后对每一次查询,如果他们属于同一个部落,则在一行中输出Y,否则输出N。
输入样例:
4
3 10 1 2
2 3 4
4 1 5 7 8
3 9 6 4
2
10 5
3 7
输出样例:
10 2
Y
N
#includeR7-3 秀恩爱分得快
古人云:秀恩爱,分得快。
互联网上每天都有大量人发布大量照片,我们通过分析这些照片,可以分析人与人之间的亲密度。如果一张照片上出现了 K 个人,这些人两两间的亲密度就被定义为 1/K。任意两个人如果同时出现在若干张照片里,他们之间的亲密度就是所有这些同框照片对应的亲密度之和。下面给定一批照片,请你分析一对给定的情侣,看看他们分别有没有亲密度更高的异性朋友?
输入格式:
输入在第一行给出 2 个正整数:N(不超过1000,为总人数——简单起见,我们把所有人从 0 到 N-1 编号。为了区分性别,我们用编号前的负号表示女性)和 M(不超过1000,为照片总数)。随后 M 行,每行给出一张照片的信息,格式如下:
K P[1] ... P[K]
其中 K(≤ 500)是该照片中出现的人数,P[1] ~ P[K] 就是这些人的编号。最后一行给出一对异性情侣的编号 A 和 B。同行数字以空格分隔。题目保证每个人只有一个性别,并且不会在同一张照片里出现多次。
输出格式:
首先输出 A PA,其中 PA 是与 A 最亲密的异性。如果 PA 不唯一,则按他们编号的绝对值递增输出;然后类似地输出 B PB。但如果 A 和 B 正是彼此亲密度最高的一对,则只输出他们的编号,无论是否还有其他人并列。
输入样例 1:
10 4
4 -1 2 -3 4
4 2 -3 -5 -6
3 2 4 -5
3 -6 0 2
-3 2
输出样例 1:
-3 2
2 -5
2 -6
输入样例 2:
4 4
4 -1 2 -3 0
2 0 -3
2 2 -3
2 -1 2
-3 2
输出样例 2:
-3 2
#include以上就是并查集的知识点及相关练习了,在下一篇文章中我们将学习图的相关知识点。