Hadoop+Hive学习笔记-4
Hadoop 集群搭建
配置三台虚拟机之间的免密登录
1 切换到root用户:crontab -e
在第一行写入:*/5 * * * * /usr/sbin/ntpdate ntp1.aliyun.com
三台机器都一同操作,这一步让三台机器的时间服务器一致
2 关闭selinux:vim /etc/selinux/config
vim编辑器打开文件,把里面的SELINUX值修改为disabled
这一步是关闭selinux
selinux是什么呢?
安全增强型 Linux(Security-Enhanced Linux)简称 SELinux,它是一个 Linux 内核模块,也是 Linux 的一个安全子系统。
网上有评价这样说的:
SELinux 的结构及配置非常复杂,而且有大量概念性的东西,要学精难度较大。很多 Linux 系统管理员嫌麻烦都把 SELinux 关闭了。如果可以熟练掌握 SELinux 并正确运用,我觉得整个系统基本上可以到达"坚不可摧"的地步了(请永远记住没有绝对的安全)。掌握 SELinux 的基本概念以及简单的配置方法是每个 Linux 系统管理员的必修课。
我的学习目的是数据分析,就没有深入研究这个东西,所以…关闭掉…
3 配置免密登录
在第一台虚拟机(我的是node201)上执行以下操作:
ssh-keygen -t rsa 连按回车就行了,之前配置过,所以overwrite了一下,第一次配置是没有了

出现图中的样子,就是OK了
然后进入下一步,操作如下:
ssh node201
ssh node202
exit
ssh node203
exit
ssh-copy-id node201
ssh-copy-id node201
ssh-copy-id node201
scp ~/.ssh/* hadoop@node202:/home/hadoop/.ssh/
scp ~/.ssh/* hadoop@node203:/home/hadoop/.ssh/
这些步骤的作用是记录三台机器间的登录记录,创建了密钥,以后三台机器之间相互登录就不用密码了
这个配置在第一台虚拟机上操作即可,我的node201 node202 node203三台虚拟机可以免密登录了
传输并解压文件
之前已经准备好了,需要的jdk、hadoop、hive的压缩文件,这里从Windows向Linux传输文件用到了一个工具Xftp
直接连接好把文件拖从左边拖到右边就OK了,很好用
直接放倒了家目录里就可以
在root用户下创建module目录
cd /opt
mkdir module
修改它的所有者和所属组为hadoop
chgrp hadoop module
chown hadoop module
这里比较简单就不截图了
这里需要把三个传输好的压缩文件解压:
tar -zxvf ./jdk-8u181-linux-x64.tar.gz -C /opt/module/
tar -zxvf ./hadoop-2.7.3.tar.gz -C /opt/module/
tar -zxvf ./apache-hive-3.1.1-bin.tar.gz -C /opt/module/
配置环境变量
用编辑器打开vim ~/.bash_profile
这里引用一下别的博主的文章:
~/.bash_profile:每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件.
注:~在LINUX下面是代表HOME这个变量的。
另外在不同的LINUX操作系统下,这个文件可能是不同的,可能是~/.bash_profile; ~/.bash_login或
/.profile其中的一种或几种,如果存在几种的话,那么执行的顺序便是:/.bash_profile、 ~/.bash_login、
/.profile。比如我用的是Ubuntu,我的用户文件夹下默认的就只有/.profile文件。 ————————————————
版权声明:本文为CSDN博主「碧空独云」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hnoysz/article/details/78666272
在文本末尾添加我们的环境变量配置:
JAVA_HOME=/opt/module/jdk1.8.0_181
HADOOP_HOME=/opt/module/hadoop-2.7.3
HIVE_HOME=/opt/module/apache-hive-3.1.1-bin
PATH= P A T H : PATH: PATH:HOME/bin: J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:HADOOP_HOME/bin: H A D O O P H O M E / s b i n : HADOOP_HOME/sbin: HADOOPHOME/sbin:HIVE_HOME/bin
export JAVA_HOME
export HADOOP_HOME
export HIVE_HOME
export PATH
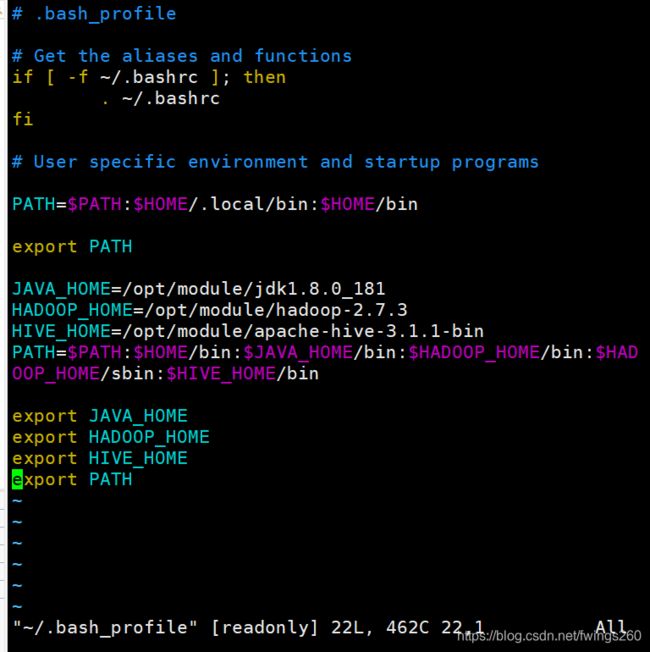
:wq之后,环境变量就修改好了
这里要注意 重新加载该文件,使环境变量生效
source ~/.bash_profile
用java -version 和hadoop version可以查看当前的版本号等信息

修改hadoop的配置文件
先进入hadoop路径 cd /opt/module/hadoop-2.7.3/etc/hadoop
1.vim ./hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181

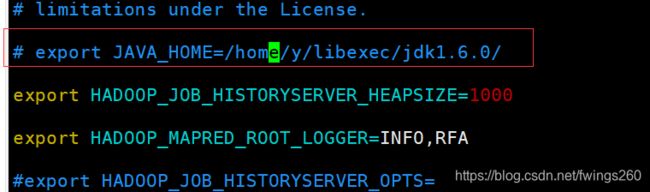
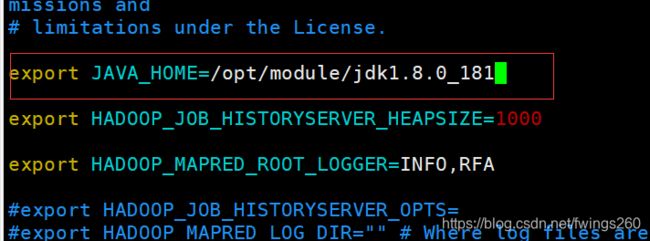
2.vim ./mapred-env.sh
这里注意,原来的哪行是被注释掉的,用 export JAVA_HOME=/opt/module/jdk1.8.0_181 替换掉
3.vim ./yarn-env.sh
同样,这一行也是被注释掉的,用 export JAVA_HOME=/opt/module/jdk1.8.0_181 替换掉
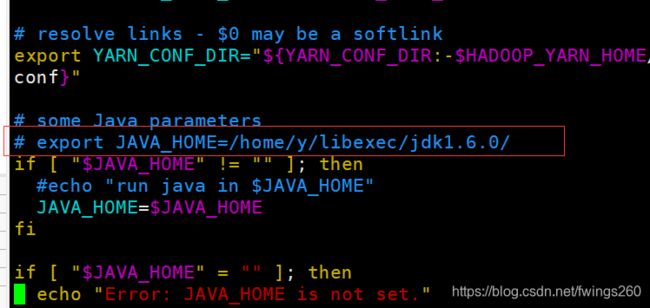
前三项是为了配置java的环境变量
4.vim ./core-site.xml
fs.defaultFS
hdfs://node201:9000
hadoop.tmp.dir
/opt/module/hadoopdata
在文件中的configuration标签内加入上面代码
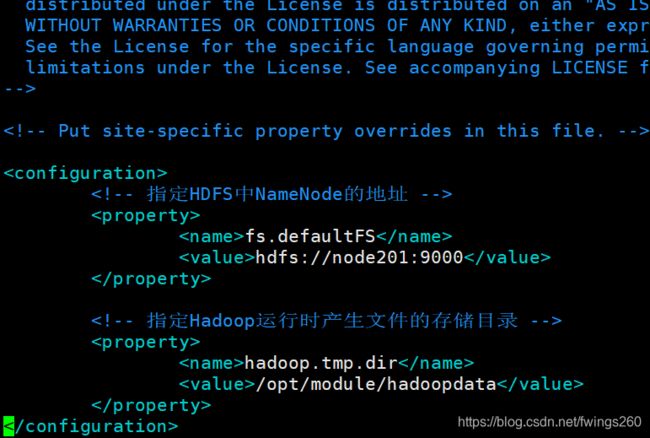
这一步设定了namenode是在node201虚拟机上
下面几步差不多,就不贴图了
5.vim ./hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
node203:50090
这一步和第四部一样,也是要在configuration标签内加入我们的配置代码
这一步设置了辅助namenode节点在node203虚拟机
HDFS副本数量和虚拟机数量一致,设为3
6.vim ./mapred-site.xml
这里默认应该是没有这个文件的,所以先执行:
cp ./mapred-site.xml.template ./mapred-site.xml
然后再编辑文件:vim ./mapred-site.xml
mapreduce.framework.name
yarn
这一步设置了mapreduce运行在yarn上
7.vim ./yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node201
这一步指定了yarn的resource manager运行在node201上
8.vim ./slaves
这里是设置从属服务器,默认是localhost,删掉修改成我们的机器名

截止目前为止,第一台虚拟机的Hadoop基本已经配置好了
现在要把第一台的jdk和Hadoop复制到另外两台机器上
进入module目录,开始复制:
scp -r /opt/module/hadoop-2.7.3 hadoop@node202:/opt/module/
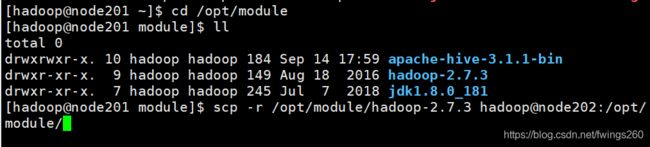
我们一共三台虚拟机,所以另外一台也要复制:
scp -r /opt/module/hadoop-2.7.3 hadoop@node203:/opt/module/
scp -r /opt/module/jdk1.8.0_181/ hadoop@node202:/opt/module/
scp -r /opt/module/jdk1.8.0_181/ hadoop@node203:/opt/module/
接下来偷个懒,直接把环境变量也复制到另外两台虚拟机:
scp ~/.bash_profile hadoop@node202:/home/hadoop/
scp ~/.bash_profile hadoop@node203:/home/hadoop/

环境变量复制完之后,记得回两台虚拟机上让配置文件生效
在另外两台上都执行:source ~/.bash_profile
然后用java -version和hadoop version 检查一下是否复制成功
格式化Hadoop集群
这里注意要在主节点上也就是第一台虚拟机上进行格式化
执行:hdfs namenode -format
启动/关闭hadoop集群
启动集群
在主节点机器上执行:start-all.sh 启动集群
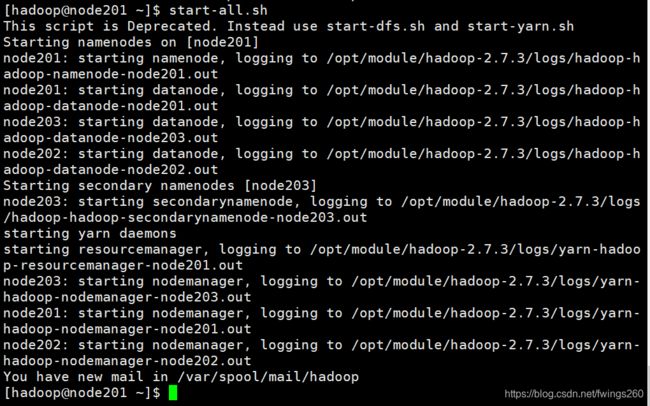
验证Hadoop集群是否正常启动
执行完启动之后,分别在三台虚拟机上运行jps命令,查看当前的Java进程是否正确
主节点机器上应该有5个进程:
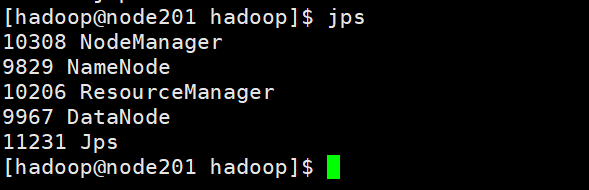
另外两台虚拟机上应该分别有3和4个进程如下:
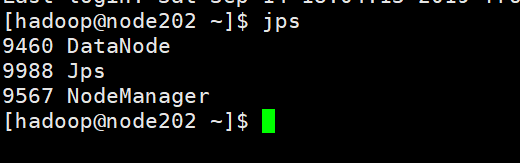
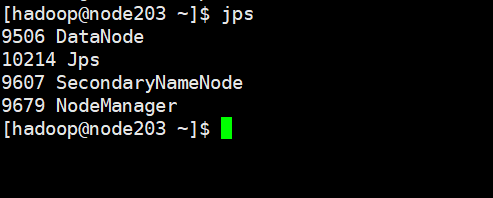
这样进程这样的话,Hadoop集群就是已经正常运行了
关闭集群,在主节点这台机器上执行:stop-all.sh
因为后面还要调试,暂时不运行
验证集群
访问端口:192.168.5.201:50070
如果集群正常启动
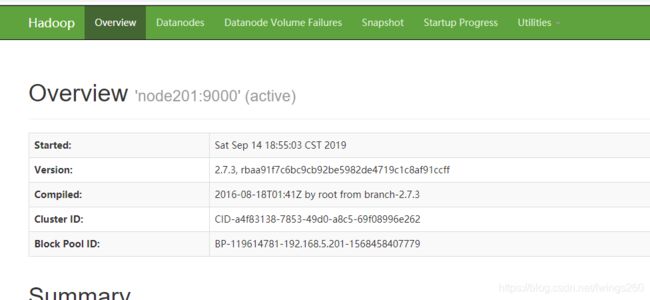
访问端口192.168.5.201:8088,如果正常启动则:
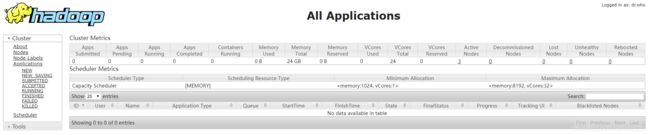
Hadoop的wordcount
1.vim word.txt
新建一个word.txt文件,然后insert经典的:
hello world
:wq 退出之后,开始我们的测试
2.wordcount测试
在Hadoop集群运行的情况下:hadoop fs -mkdir /test
创建test文件夹在hadoop目录下
运行 hadoop fs -put ./word.txt /test
将刚的word文件转移到test目录下
测试一下结果:
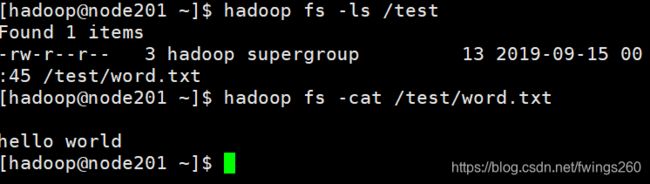

通过虚拟机的Hadoop端口页面访问均可以看到word文件,验证这一步成功
接下来可以执行wordcount方法进行验证
执行:hadoop jar /opt/module/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/word.txt /output
集群开始调取资源进行处理,处理完成后
执行:hadoop fs -cat /output/part-r-00000 查看count结果
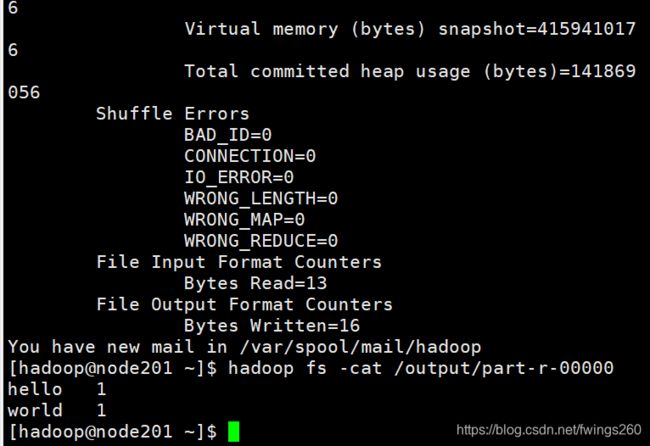
可以看到,hello和world都分别出现了一次,验证OK
其实应该弄一个复杂点的文本来测试,失算了