Flink数据类型&&序列化&&序列化器
官网:https://ci.apache.org/projects/flink/flink-docs-master/zh/dev/types_serialization.html
背景:在Java和大数据生态圈中,已有不少序列化工具,比如:
1、Java自带的序列化工具、Kryo等。
2、一些RPC框架也提供序列化功能,比如:
(1)最初用于Hadoop的【Apache Avro】
(2)Facebook开发的【Apache Thrift】
(3)Google开发的【Protobuf】
这些工具在速度和压缩比等方面与JSON相比有一定的优势。
但是Flink依然选择了重新开发了自己的序列化框架,因为序列化和反序列化将关乎整个流处理框架个方便的性能,对数据类型了解越多,可以更早地完成数据类型检查,节省数据存储空间。
一、Flink数据类型
1. 基础类型(Basic):Int、String、Double、Long、Date
2. 数组类型(Array):
(1)原生类型构成的数组
(2)对象类型构成的数组
3. 复合类型(Composite):
(1)scala ——> case class(样例类)
(2)java ——> POJO
(3)scala、java ——> Tuple(元组)
4. 辅助类型(Auxiliary):
(1)Option
(2)List
(3)Map
'当以上任何一个类型均不满足时,Flink认为该数据结构是一种泛型(GenericType),使用Kryo来进行序列化和反序列化。'
5. 泛型和其它类型(Generic):
(1)Kryo
1、基础类型
所有Java和Scala基础数据类型,诸如Int(包括Java原生类型int和装箱后的类型Integer)、Double、Long、String,以及Date、BigDecimal和BigInteger。
2、数组
基础类型或其他对象类型组成的数组,如String[]。
3、复合类型
(1)Scala case class
case class Person(name:String,age:Int)
(2)Java POJO
定义POJO类有一些注意事项:
(1)该类必须用public修饰。
(2)该类必须有一个public的无参数的构造函数。
(3)该类的所有非静态(non-static)、非瞬态(non-transient)字段必须是public,如果字段不是public则必须有标准的getter和setter方法,比如对于字段A a有A getA()和setA(A a)。
(4)所有子字段也必须是Flink支持的数据类型。
判断一个类是否是POJO,可以使用下面的代码检查:
System.out.println(TypeInformation.of(Person.class).createSerializer(new ExecutionConfig()));
POJO类型的序列化
类PojoTypeInfomation用于创建针对POJO中所有成员的序列化器。Flink自带了针对诸如int,long,String等标准类型的序列化器,对于所有其他的类型,我们交给Kryo处理。
如果Kryo不能处理某类型,则我们可以通过PojoTypeInfo来使用Avro来序列化POJO,为了达成该目的,我们需要调用如下接口:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().enableForceAvro();
注意:Flink自动序列化POJO对象,该对象由Avro用Avro序列化器产生。
如果我们想使得整个POJO类型都由Kryo序列化器处理,则我们如下设置:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().enableForceKryo();
如果Kryo不能序列化该POJO对象,我们可以添加一个自定义序列化器到Kryo,使用代码如下:
env.getConfig().addDefaultKryoSerializer(Class<?> type, Class<? extends Serializer<?>> serializerClass)
(3)Tuple
Flink为Java专门准备了元组类型,最多支持到25元组。
Scala的Tuple中所有元素都不可变,Java的Tuple中的元素是可以被更改和赋值的,因此在Java中使用Tuple可以充分利用这一特性,这样可以减少垃圾回收的压力。
4、辅助类型
(1)Java:
- ArrayList
- HashMap
- Enum
(2)Scala:
- Either
- Option
5、泛型和其他类型
当以上任何一个类型均不满足时,Flink认为该数据结构是一种泛型(GenericType),使用Kryo来进行序列化和反序列化。但Kryo在有些流处理场景效率非常低,有可能造成流数据的积压。我们可以使用env.getConfig().disableGenericTypes();来禁用Kryo,禁用后,Flink遇到无法处理的数据类型将抛出异常,这种方法对于调试非常有效。
二、TypeInformation
在Flink中,类TypeInformation是所有类型描述类的基类。TypeInformation的一个重要的功能就是创建TypeSerializer序列化器,为该类型的数据做序列化。每种类型都有一个对应的序列化器来进行序列化。
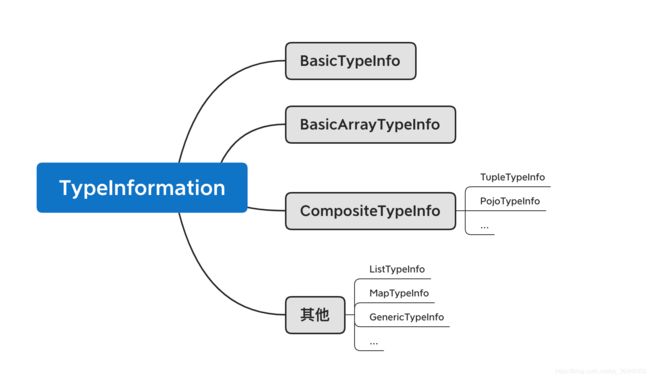
使用前面介绍的各类数据类型时,Flink会自动探测传入的数据类型,生成对应的TypeInformation,调用对应的序列化器,因此用户其实无需关心类型推测。比如,Flink的map函数Scala签名为:
def map[R: TypeInformation](fun: T => R): DataStream[R]
传入map的数据类型是T,生成的数据类型是R,Flink会推测T和R的数据类型,并使用对应的序列化器进行序列化。
以一个字符串Tuple3类型为例,Flink首先推断出该类型,并生成对应的TypeInformation,然后在序列化时调用对应的序列化器,将一个内存对象写入内存块。如下图:

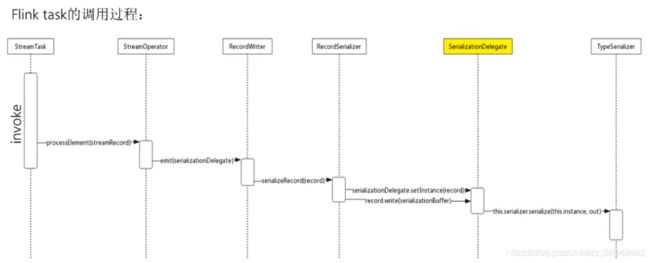
Flink的Task之间如果需要跨网络传输数据记录,那么就需要将数据序列化之后写入NetworkBufferPool,然后下层的Task读出之后再进行反序列化操作,最后进行逻辑处理。
为了使得记录以及事件能够被写入Buffer随后在消费时再从Buffer中读出,Flink提供了数据记录序列化器(RecordSerializer)与反序列化器(RecordDeserializer)以及事件序列化器(EventSerializer)。
我们的Function发送的数据被封装成SerializationDelegate,它将任意元素公开为IOReadableWritable以进行序列化,通过setInstance()来传入要序列化的数据。
Flink job的提交过程:

Flink task的调用过程:
三、注册类
如果传递给Flink算子的数据类型是父类,实际运行过程中使用的是子类,子类中有一些父类没有的数据结构和特性,将子类注册可以提高性能。在执行环境上调用env.registerType(clazz);来注册类。registerType方法的源码如下所示,其中TypeExtractor对数据类型进行推断,如果传入的类型是POJO,则可以被Flink识别和注册,否则将使用Kryo。
registerType源码:
public void registerType(Class<?> type) {
if (type == null) {
throw new NullPointerException("Cannot register null type class.");
} else {
TypeInformation<?> typeInfo = TypeExtractor.createTypeInfo(type);
if (typeInfo instanceof PojoTypeInfo) {
this.config.registerPojoType(type);
} else {
this.config.registerKryoType(type);
}
}
}
四、注册序列化器
如果数据类型不是Flink支持的上述类型,需要对数据类型和序列化器进行注册,以便Flink能够对该数据类型进行序列化。
//对PersonClassSerializer(序列化器)和Person(数据类型)进行注册
env.getConfig().registerTypeWithKryoSerializer(Person.class,PersonClassSerializer.class);
自定义序列化器:使用PersonClassSerializer(序列化器)对Person(数据类型)进行序列化
public class PersonClassSerializer extends Serializer<Person> {
@Override
public void write(Kryo kryo, Output output, Person person) {
}
@Override
public Person read(Kryo kryo, Input input, Class<Person> aClass) {
return null;
}
}
请注意,您的自定义序列化程序必须扩展Kryo的Serializer类。对于【Apache Thrift】和【Google Protobuf】而言,已经有人将序列化器编写好了,我们可以直接拿来使用:
(1)Protobuf
env.getConfig().registerTypeWithKryoSerializer(Person.class,ProtobufSerializer.class);
【Google Protobuf】需要导入的依赖:
<dependency>
<groupId>com.twitter</groupId>
<artifactId>chill-protobuf</artifactId>
<version>0.7.6</version>
<exclusions>
<exclusion>
<groupId>com.esotericsoftware.kryo</groupId>
<artifactId>kryo</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.7.0</version>
</dependency>
(2)Thrift
env.getConfig().addDefaultKryoSerializer(Person.class,TBaseSerializer.class);
【Apache Thrift】需要导入的依赖:
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libthrift</artifactId>
<version>0.11.0</version>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</exclusion>
</exclusions>
</dependency>
打开ProtobufSerializer和TBaseSerializer的源码查看,可知它们都扩展了Kryo的Serializer类:
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.Serializer;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;