Scrapy-安装与配置
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。接下来记录一下Scrapy的使用
安装Scrapy
pip install scrapy
项目结构介绍
在学习如何使用Scrapy开发爬虫项目之前,我们首先从总体上认识一下Scrapy爬虫项目的目录结构。首先我们先创建一个爬虫项目:
scrapy startproject myfirstspider
执行完上面的创建命令,默认会有如下所示的项目结构:
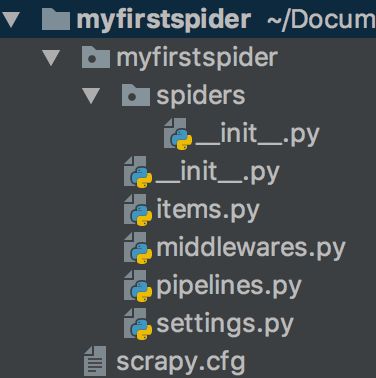
首先,会生成一个与爬虫项目名称相同的文件夹,比如此时我们爬虫项目名称为myfirstspider,所以此时,会生成一个名为myfirstspider的文件夹,该文件夹下拥有一个同名子文件夹(可以暂且称为项目核心目录)和一个scrapy.cfg文件。该同名子文件夹下放置的是爬虫项目的核心代码,scrapy.cfg文件主要是爬虫项目的配置文件。
该项目中同名子文件夹myfirstspider下放置了爬虫项目的核心代码,包括一个spiders文件夹,以及__init__.py、items.py、pipelines.py、settings.py等Python文件。其中__init__.py为项目的初始化文件,主要写的是一些项目的初始化信息。
myfirstspider/myfirstspider/items.py:爬虫项目的数据容器文件,主要用来定义我们要获取的数据myfirstspider/myfirstspider/pipelines.py:爬虫项目的管道文件,主要用来对items立面定义的数据进一步的加工与处理myfirstspider/myfirstspider/settings.py:爬虫项目的设置文件,主要为爬虫项目的一些设置信息
spiders文件下放置的是爬虫项目的爬虫部分相关的文件,其中myfirstspider/myfirstspider/spiders/__init__.py文件为爬虫项目中爬虫部分的初始化文件,主要对spiders进行初始化
创建爬虫项目
在上面的项目结构介绍中,简单提到了创建爬虫项目的命令,值得注意的是,执行完此命令之后,会在当前文件下生成爬虫项目。如果需要在指定目录下生成爬虫项目的朋友,需先进入指定目录,然后执行命令。接下来记录一下创建命令中的其他用法。
使用scrapy startproject来创建爬虫项目,在创建的时候我们也可以加上一些参数进行控制,那么有哪些参数呢?我们可以通过scrapy startproject -h调出startproject的帮助信息,详细信息如下图:
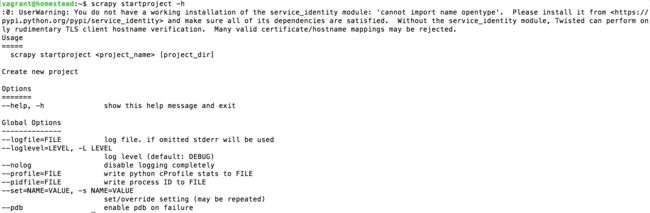
我们可以对这些重要的参数分别进行分析:
--logfile=FILE:参数用来指定日志文件,其中的FILE为指定的日志文件的路径
# 创建myfirstspider爬虫项目并在上一层目录下创建scrapy.log日志文件
scrapy startproject --logfile="../scrapy.log" myfirstspider
此时,我们可以进入上一层目录,会发现已创建一个scrapy.log的日志文件,打开之后信息如下所示:
2018-04-14 02:41:18 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: scrapybot)
2018-04-14 02:41:18 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 17.9.0, Python 2.7.12 (default, Jul 1 2016, 15:12:24) - [GCC 5.4.0 20160609], pyOpenSSL 0.15.1 (OpenSSL 1.0.2g 1 Mar 2016), cryptography 1.2.3, Platform Linux-4.4.0-38-generic-x86_64-with-Ubuntu-16.04-xenial
--loglevel=LEVEL,-L LEVEL:参数主要用来控制日志信息的等级,默认为DEBUG模式,即会将对应的调试信息都输出。除了DEBUG等级之外,对应的等级还可以设置为其他的值,具体可以设置为的值以及对应含义如下所示:
| 等级 | 含义 |
|---|---|
| CRITICAL | 发生最严重的错误 |
| ERROR | 发生了必须立即处理的错误 |
| WARNING | 出现一些警告信息,即存在潜在错误 |
| INFO | 输出一些提示信息 |
| DEBUG | 输出一些调试信息,常用于开发阶段 |
scrapy startproject --loglevel=DEBUG myfirstspider
# 或者
scrapy startproject -L DEBUG myfirstspider
--nolog:参数可以控制不输出日志信息。比如,可以通过如下命令,实现创建一个爬虫项目,并且不输出日志信息:
scrapy startproject --nolog myfirstspider
全局命令
全局命令有哪些呢,要想了解在Scrapy中有哪些全局命令,可以在不进入Scrapy项目所在目录的情况下,运行scrapy-h,如图所示:
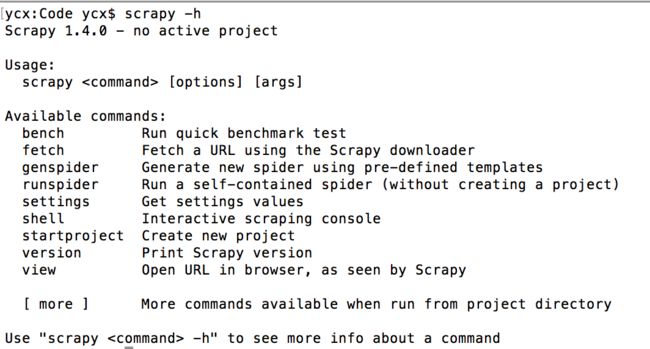
可以看到,此时在可用命令在终端下展示出了常见的全局命令,分别为fetch、runspider、settings、shell、startproject、version、view。
fetch命令
fetch命令主要用来显示爬虫爬取的过程.如下图所示:

在使用fetch命令时,同样可以使用某些参数进行相应的控制。那么fetch有哪些相关参数可以使用呢?我们可以通过scrpy fetch -h列出所有可以使用的fetch相关参数。比如我们可以使用–headers显示头信息,也可以使用–nolog控制不显示日志信息,还可以使用–spider=SPIDER参数来控制使用哪个爬虫,通过–logfile=FILE指定存储日志信息的文件,通过–loglevel=LEVEL控制日志等级。举个栗子:
# 显示头信息,并且不显示日志信息
scrpay -fetch --headers --nolog http://www.baidu.com
runspider命令
通过runspider命令可以不依托scrapy的爬虫项目,直接运行一个爬虫文件。下面我们将展示一个运用runspider命令运行爬虫文件的例子。首先在spiders文件夹创建一个名为first.py的爬虫文件,first.py代码如下:
from scrapy.spiders import Spider
class FirstSpider(Spider):
name = 'first' # 爬虫名
allowed_domains = ['baidu.com']
start_urls = ['http://www.baidu.com']
def parse(self, response, **kwargs):
pass
然后,我们可以通过scrapy runspider命令运行该爬虫文件,并将日志等级设置了INFO
# first.py为自定义的一个爬虫文件
scrapy runspider --loglevel=INFO first.py
settings命令
在scrapy项目所在的目录中使用settings命令查看的使用对应的项目配置信息, 如果在scrapy项目所在的目录外使用settings命令查看的Scrapy默认的配置信息
# 在项目目录中使用此命令打印的为BOT_NAME对应的值,即scrapy项目名称。
# 在项目目录外使用此命令打印的为scrapybot
scrapy settings --get BOT_NAME
shell命令
通过shell命令可以启动Scrapy的交互终端。
Scrapy的交互终端经常在开发以及调试的时候用到,使用Scrapy的交互终端可以实现在不启动Scrapy爬虫的情况下,对网站响应进行调试,同样,在该交互终端下,我们也可以写一些Python代码进行相应测试。

可以看到,在执行了该命令后,会出现可以适用的Scrapy对象以及快捷命令,比如items、response、settings、spider等,并进入交互模式,在>>>后面可以输入交互命令以及相应的代码
startproject命令
用于创建scrapy项目
version命令
查看scrapy版本
view命令
用于下载某个网页,然后通过浏览器查看
项目命令
bench命令
测试本地硬件的性能。当我们运行scrapy bench的时候,会创建一个本地服务器并且会以最大的速度爬行,在此为了测试本地硬件的性能,避免其他过多因素的影响,所以仅进行链接跟进,不进行内容处理
scrapy bench
genspider命令
用于创建爬虫文件,这是一种快速创建爬虫文件的方式。
# scrpay genspider -t 基本格式
# basic 模板
# baidu.com 爬取的域名
scrapy genspider -t basic xxx baidu.com
此时在spider文件夹下会生成一个以xxx命名的py文件。可以使用scrapy genspider -l查看所有可用爬虫模板。当前可用的爬虫模板有:basic、crawl、csvfeed、xmlfeed
check命令
使用check命令可以实现对某个爬虫文件进行合同检查,即测试.
# xxx为爬虫名
scrapy check xxx
crawl命令
启动某个爬虫
# xxx为爬虫名
scrapy crawl xxx
list命令
列出当前可使用的爬虫文件
scrapy list
edit命令
编辑爬虫文件
# xxx为爬虫名
scrapy edit xxx
parse命令
通过parse命令,我们可以实现获取指定的URL网址,并使用对应的爬虫文件进行处理和分析
scrapy parse http://www.baidu.com --nolog
日志等级
| 等级名 | 含义 |
|---|---|
| CRITICAL | 发生了最严重的错误 |
| ERROR | 发生了必须立即处理的错误 |
| WARNING | 出现了一些警告信息,即存在潜在错误 |
| INFO | 输出一些提示显示 |
| DEBUG | 输出一些调试信息 |