三:爬虫-网络请求模块(下)
三:网络请求模块(下)
1.Requests模块:
Requests是用Python语言编写,基于urllib,采用 Apache2 Licensed开源协议的 HTTP 库,它比urllib更加的方便,可以节约我们大量的工作,完全满足 HTTP 测试需求
Requests的哲学是以 PEP 20(一种标准规范)的习语为中心开发的,所以它比urllib更加简洁
(1)Requests模块的安装:
Requests是Python语言的第三方库,专门用于发送HTTP请求
安装方式:
#1.在终端输入
pip install requests
#2.换源安装:若出现下载超时,过慢的情况,换源即可
# 示例
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 阿里云 http://mirrors.aliyun.com/pypi/simple/
# 豆瓣http://pypi.douban.com/simple/
# 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
# 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
# 华中科技大学http://pypi.hustunique.com/
(2)Requests的使用:
1.常用方法:
requests.get("网址")
request.post("网址")
2.常用参数:
url:url地址,接口文档标注的接口请求地址
params:请求数据中的链接,常见的一个get请求,请求参数都是在url地址中
data:请求数据,参数是表单的数据格式
json:接口常见的数据请求格式
headers:请求头信息
cookie:保存的用户登录信息,比如做一些充值功能,但是需要用户已经登录,需要cookie信息的请求信息传输
#推荐一个爬虫工具:爬虫工具库
# https://spidertools.cn/#/curl2Request
3.响应内容:
r.encoding:获取当前的编码
r.encoding = 'charset':设置编码格式,多为'utf-8'编码
r.text:以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字体编码进行解码
r.cookies:返回cookie
r.headers:请求头,以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
r.status_code:响应状态码
r.json():Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛出异常
r.content:字节流,以字节形式(二进制)返回,字节方式的响应体,会自动为你解码gzip和deflate压缩
4.Requests中get请求之参数应用 – 搜狗搜索海贼王案例:
(1)把参数添加到url链接中 – 平民写法(用到的最多的写法)
#导入模块
import requests
#目标url
url = 'https://www.sogou.com/web?query=%E6%B5%B7%E8%B4%BC%E7%8E%8B&_asf=www.sogou.com&_ast=&w=01015002&p=40040108&ie=utf8&from=index-nologin&s_from=index&oq=&ri=0&sourceid=sugg&suguuid=&sut=0&sst0=1678439364372&lkt=0%2C0%2C0&sugsuv=1666847250696567&sugtime=1678439364372'
#请求头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
'Cookie':'ABTEST=8|1701776265|v17; SNUID=7B0346FA646568A5CDB26F5B64A6691E; IPLOC=CN3205; SUID=186722991B5B8C0A00000000656F0B89; cuid=AAFqAmPwSAAAAAqMFCnulgEASQU=; SUV=1701776266958330; browerV=3; osV=1; sst0=372'
}
#发起请求
response = requests.get(url, headers=headers)
#指定编码格式
response.encoding = 'utf-8'
#获取响应
html = response.text
#文件写入响应数据内容
with open("海贼王1.html","w",encoding='utf-8') as i:
i.write(html)
#打印响应(数据)内容
print(html)
注意: 1.值与值之间需要用逗号隔开
(2)把参数添加到params中 – 官方写法(不常用)
#导入模块
import requests
#请求头部信息 -- 字典的形式
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
#cookie的两种设置方式
#(1)'Cookie':'ABTEST=8|1701776265|v17; SNUID=7B0346FA646568A5CDB26F5B64A6691E; IPLOC=CN3205; SUID=186722991B5B8C0A00000000656F0B89; cuid=AAFqAmPwSAAAAAqMFCnulgEASQU=; SUV=1701776266958330; browerV=3; osV=1; sst0=372'
}
#cookie值 -- (2)字典的形式
cookies = {
"ABTEST": "8^|1701776265^|v17",
"SNUID": "7B0346FA646568A5CDB26F5B64A6691E",
"IPLOC": "CN3205",
"SUID": "186722991B5B8C0A00000000656F0B89",
"cuid": "AAFqAmPwSAAAAAqMFCnulgEASQU=",
"SUV": "1701776266958330",
"browerV": "3",
"osV": "1",
"sst0": "372"
}
#目标url
url = "https://www.sogou.com/web"
#get请求所携带的参数
params = {
"query": "海贼王",
"_asf": "www.sogou.com",
"_ast": "",
"w": "01015002",
"p": "40040108",
"ie": "utf8",
"from": "index-nologin",
"s_from": "index",
"oq": "",
"ri": "0",
"sourceid": "sugg",
"suguuid": "",
"sut": "0",
"sst0": "1678439364372",
"lkt": "0^%^2C0^%^2C0",
"sugsuv": "1666847250696567",
"sugtime": "1678439364372"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params) #因为cookie中不只有一个键值对所以要加s
print(response.text)
print(response)
#文件写入响应数据内容
with open("海贼王2.html","w",encoding='utf-8') as i:
i.write(response.text)
官方写法快速的写法:
1.进入目标
url的页面进行如下操作:

2.进入爬虫工具库进行如下操作:
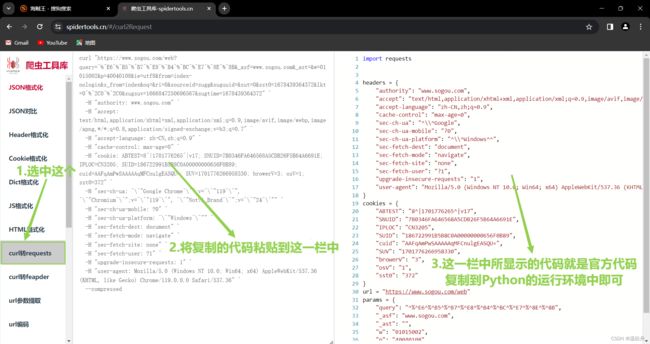
3.得到如下代码:
import requests headers = { "authority": "www.sogou.com", "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "accept-language": "zh-CN,zh;q=0.9", "cache-control": "max-age=0", "sec-ch-ua": "^\\^Google", "sec-ch-ua-mobile": "?0", "sec-ch-ua-platform": "^\\^Windows^^", "sec-fetch-dest": "document", "sec-fetch-mode": "navigate", "sec-fetch-site": "none", "sec-fetch-user": "?1", "upgrade-insecure-requests": "1", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36" } cookies = { "ABTEST": "8^|1701776265^|v17", "SNUID": "7B0346FA646568A5CDB26F5B64A6691E", "IPLOC": "CN3205", "SUID": "186722991B5B8C0A00000000656F0B89", "cuid": "AAFqAmPwSAAAAAqMFCnulgEASQU=", "SUV": "1701776266958330", "browerV": "3", "osV": "1", "sst0": "372" } url = "https://www.sogou.com/web" params = { "query": "^%^E6^%^B5^%^B7^%^E8^%^B4^%^BC^%^E7^%^8E^%^8B", "_asf": "www.sogou.com", "_ast": "", "w": "01015002", "p": "40040108", "ie": "utf8", "from": "index-nologin", "s_from": "index", "oq": "", "ri": "0", "sourceid": "sugg", "suguuid": "", "sut": "0", "sst0": "1678439364372", "lkt": "0^%^2C0^%^2C0", "sugsuv": "1666847250696567", "sugtime": "1678439364372" } response = requests.get(url, headers=headers, cookies=cookies, params=params) print(response.text) print(response)
注意: (1)官方写法不建议使用,因为它会把所有的参数都携带上,有些参数可能会有反爬
(2)params的数据类型为字典数据,必须满足键值对
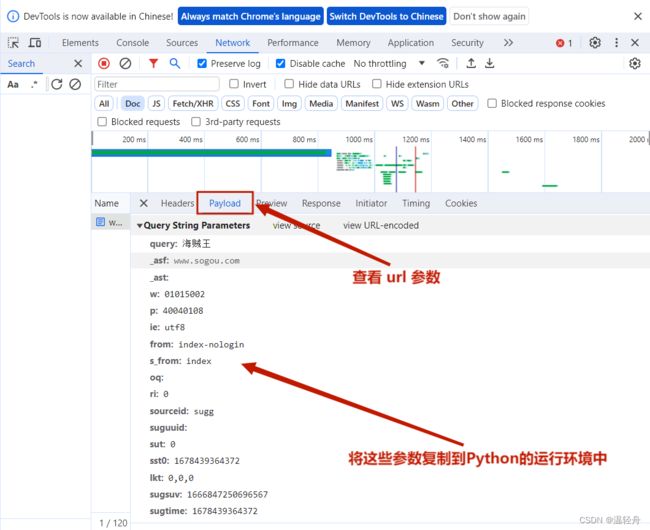
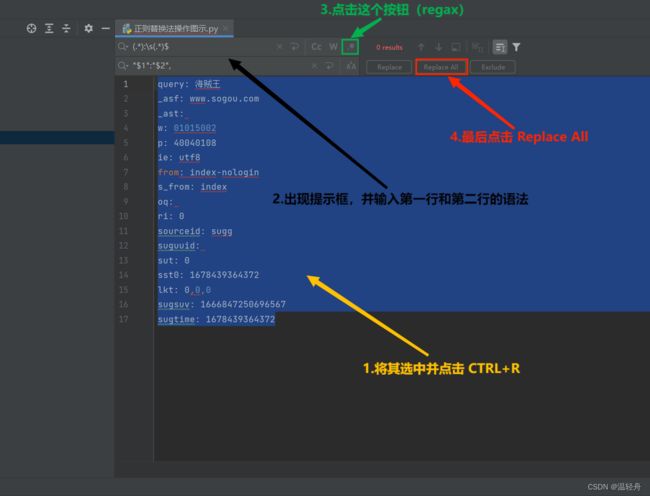
5.如何快速将headers中的参数匹配为字典数据(了解):
#使用正则替换
1.将 headers 中的参数内容全部选中
2.按住 CTRL + R 键:会弹出一个提示框
3.在第一行输入正则语法:(.*):\s(.*)$
4.在第二行输入正则语法:"$1":"$2",
5.点击 regax
6.点击 Replace All
注意: 1.因为已经有爬虫工具库了,所以这个方法也就用不上了,大家当作拓展就好
2.写的时候注意语法不要写错,特别是第二行的正则语法后面的英文逗号,一定要加
正则替换法的操作图示:
6.Requests中post请求:
post请求的大多数用法和get请求一样,只是需要加上data参数
post方法的使用场景:
1.网页需要登录的情况下
2.需要给网页传输内容的情况下
语法格式:
response = requests.post("网址", data = data,headers=headers)
360翻译 – 实现英汉互译示例:
#导入模块
import requests
#目标url
'''
url分析 -- 实现英文翻译成中文:
https://fanyi.so.com/index/search?eng=1&validate=&ignore_trans=0&query=love
https://fanyi.so.com/index/search?eng=1&validate=&ignore_trans=0&query=like
https://fanyi.so.com/index/search?eng=1&validate=&ignore_trans=0&query=enjoy
根据多个英文翻译的url分析,发现改变的只有单词不同,其余的内容完全一致,也就是说我们可以把最后面单词的位置设置成一个变量,这样的话就可以实现单词翻译,
而不是想翻译一个单词就去改变一下它的url
'''
'''
url分析 -- 实现中文翻译成英文:
https://fanyi.so.com/index/search?eng=0&validate=&ignore_trans=0&query=%E7%88%B1%E6%83%85
https://fanyi.so.com/index/search?eng=0&validate=&ignore_trans=0&query=%E5%96%9C%E6%AC%A2
https://fanyi.so.com/index/search?eng=0&validate=&ignore_trans=0&query=%E4%BA%AB%E5%8F%97
'''
'''
根据两种翻译的url分析,发现除结尾不同外其eng也不同,一个是0;一个是1
两种方法都实现的实现方法:
第一个方法: if判断
第二个方法: 函数
'''
print("中文 --> 英文 ; 点击0")
print("英文 --> 中文 ; 点击1")
choose = input("请输入你的选择: ")
word = input("请输入你想翻译的内容: ")
url = f'https://fanyi.so.com/index/search?eng={choose}&validate=&ignore_trans=0&query={word}'
#请求头信息
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
'Pro':'fanyi' # 查看后发现在这个参数中做了反爬,所以这个参数必须要加上
}
#post请求要携带的参数
data = {
'eng': f'{choose}', # 注意改变参数,因为url中的eng参数已经被我们设置成了choose变量
'validate': "",
'ignore_trans': '0',
'query': f'{word}' # 注意改变参数,因为url中的最后一项参数已经被我们设置成了word变量
}
#发起请求
response = requests.post(url,headers = headers,data = data)
'''
#检测可能出现的错误
print(response.text) #经过检测后发现没有报错,data不可能有问题,所以只能是在其它地方出现反爬
'''
'''
#获取响应数据
result = response.json() #报出 JSONDecodeError 错误,说明response并不能满足转换成json对象
print(result)
'''
'''
#获取响应数据
result = response.json()
print(result)
'''
#获取响应数据
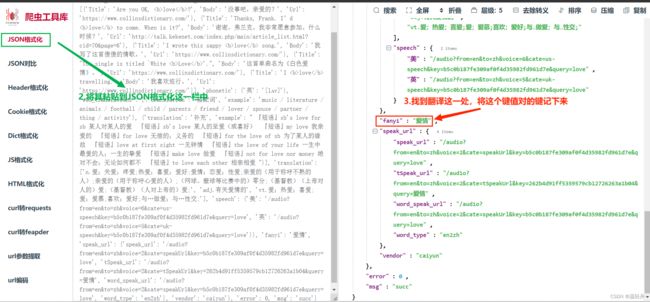
result = response.json()
#信息过滤
fanyi = result['data']['fanyi'] #字典取值
'''
字典取值的两种方法:
1.['key'] -- 取不到值会报错
2.xxx.get('key') -- 取不到值会返回None
注意:一旦取不到值对于第一种方法需要进行异常处理,而第二种方法则不用去管
'''
print(fanyi)
信息过滤图示: