Jave EE 网络原理之网络层与数据链路层
文章目录
- 1. 网络层
-
- 1.1 IP 协议
-
- 1.1.1 协议头格式
- 1.1.2 地址管理
-
- 1.1.2.1 认识 IP 地址
- 1.1.3 路由选择
- 2. 数据链路层
-
- 2.1 认识以太网
-
- 2.1.1 以太网帧格式
- 2.1.2 DNS 应用层协议
1. 网络层
网络层要做的事情,主要是两个方面
- 地址管理
(制定一系列的规则,通过地址,描述出网络上一个设备的位置) - 路由选择
(网络环境比较复杂,从一个节点到另一个节点之间,存在很多条不同的路径,就需要通过这种方式,筛选/规划出更合适的路径进行数据传输)
1.1 IP 协议
1.1.1 协议头格式

- 4位版本号:指定IP协议的版本,对于IPv4来说,就是4(也有 ip v6)
- 4位首部长度:IP 协议的报头,也是变长的(0 - 0xf 也就是 0 - 60字节)
- 8位服务类型:能够让 IP 协议,切换形态
3位优先权字段(已经弃⽤),4位TOS字段,和1位保留字段(必须置为0)
4位TOS分别表示:最⼩延时,最大吞吐量,最高可靠性,最⼩成本
这四者相互冲突,只能选择⼀个
这四个位,彼此之间是冲突的,只有一位设为 1,不同的位设为 1,表示 IP 协议不同的形态 - 16位总长度:描述了 IP 数据包最长是多长
IP 协议,确定也存在 64 这样的限制,但是 IP 协议本身支持“拆包组包”功能
通过 16位标识、3位标志字段、13位片偏移 ,来实现拆包组包
- 16位标识:如果一个大的 IP 数据包要拆成多个小的,此时拆出来的这多个小包,16 表示就是相同的数值
- 13位片偏移:描述当前每个小的数据包(分片)的相对位置
- 3位标志字段:其中有一位表示 是否允许拆包,还有一位表示是否是最后一个包(类属于单链表 的结束标记)
- 8位生存时间(Time To Live,TTL):描述了这个 IP 数据包,在网络上还能继续存活多久
TTL 的单位是次数,数据包构造出来的时候,TTL 会被设置成一个初始值
数据包在转发的过程中,每次经历一个路由器转发,TTL 就会 -1
如果这个数据白,已经把 TTL 耗尽了,还没有顺利到达对方,就会被丢弃掉
这个机制,还是非常有用的,给网络能够进行兜底
假设构造一个数据包,目的 IP 写作不存在的 IP,这个数据包不可能到达目标
显然这样的包,也不可能允许在网络上一直存在 - 8位协议:描述的是,IP 数据包的载荷部分,是一个 UDP 数据包还是 TCP 数据包(传输层是哪个协议)
- 16位首部校验和:这个校验和,只是校验 IP 数据的首部,不管 IP 数据的载荷
- 32位源地址和32位目标地址:IP 数据包中,最关键的内容
IP 地址,本质上就是一个 32位的整数
为了方便人来理解,写作点分十进制 方式
1.1.2 地址管理
IP 地址,是一个 32位的整数
2 ^ 32 : 42亿9千万
地址,理论上来说,是不应该重复的
互联网发展到今天,能上网的设备,非常多,早就超过了这个数字了
如何解决这个 IP 地址不够用的问题呢?
方案一:动态分配 IP
这个方案,治标不治本,提高了 IP 地址的利用率,并没有增加 IP 地址的数目
(虽然是一个 过渡方案,这个方案目前仍然是广泛存在的)
方案二:NAT 机制(网络地址转换)
本质上 让一个 IP 地址,代表一批设备
把 IP 地址分为两大类:
(1)内网 IP(局域网 IP)
如果一个IP 地址,是以 10.* 或者 172.16.* - 172.31.* 或者 192.168.*
(复合上述条件之一,IP 就是内网 IP)
在同一个局域网内部,内网 IP 之间,不能重复
在不同的局域网中,内网 IP 之间,能重复

(2)外网 IP(广域网 IP)
剩下的 IP 都是外网 IP
外网 IP 则始终都不允许重复,务必唯一

这个外网 IP 其实是所在的一个大的片区,共用一个外网 IP
NAT 机制具体是怎么工作的?

我的电脑就会构造一个 IP 数据包

我的电脑会把报头发给运营商,此时,运营商路由器,也是一个 NAT 设备,也就能够对当前这里的源 IP 进程替换
(内网 IP,无法在广域网上使用)
站在服务器的角度,看到的源 IP 就是经过转换过后的 IP
如果进行反向操作也是相同的操作
运营商路由器,内部会记录一个映射关系
刚才是把 192.168.0.200 这个 ip 给替换成了 123.139.168.15
现在响应报文回来了,就需要把这个 ip 替换回去
此时运营商路由器,NAT 设备,就相当于一个中转站
如果当前局域网内,有多个主机,都访问同一个网站服务器
此时服务器返回的响应,经过路由器,要交给哪个主机呢?

当服务器返回数据之后,路由器如何决定这个数据要交给哪个设备?
是要结合端口号,来进行区分
端口号,可以用来区分同一个主机的不同进程,也可以区分不同主机的不同进程
虽然 ip 一样,但是这两个请求来自于不同的端口返回的响应数据,自然也会带有不同的目的端口
服务器返回的两条数据
一个目的端口是 10001,另一个目的端口是 8888
路由器就知道了,10001 的这个,就需要把 ip 替换回 第一个主机 ip (192.168.0.100)
8888 这个,就需要把 ip 替换回 第二个主机的 ip(192.168.0.200)
如果两个端口号一样,这个时候,路由器就可以主动把相同的端口,替换成不同的端口
第一个主机的数据包:
源 ip: 192.168.0.100
源端口 8888
目的 ip: 1.2.3.4
目的端口 80
第一个主机的数据包:
源 ip: 192.168.0.100
源端口 8888
目的 ip: 1.2.3.4
目的端口 80
到达路由器之后,路由器这回发现这两个数据包的目的 ip 和目的端口都一样(访问同一个服务器)
源端口也一样
路由器直接把源端口也一起给替换掉
路由器内部会记录映射关系
第一个主机:
源IP: 123.139.168.15
源端口 1001
目的IP: 1.2.3.4
目的端口 80
第二个主机:
源IP: 123.139.168.15
源端口 1002
目的IP: 1.2.3.4
目的端口 80
这样就不怕端口号一样了
当前的网络环境,就是以 NAT + 动态分配的方式来解决 IP 地址不够用的问题
NAT 机制,最大的优势,“纯软件的方案”
也正是因为这个机制,局域网内部的设备,能够主动访问外网的设备
外网的设备无法主动访问局域网内部的设备
(之前写的 UDP echo server 必须部署到云服务器上才能执行了)
当然,这个局限性也不是坏事,反而更好的保护了电脑的安全
最终解决这个问题的方式就是:IPv6
IPv6:IPv6并不是IPv4的简单升级版,这是互不相干的两个协议,彼此并不兼容
IPv6用16字节128位来表示⼀个IP地址
但是⽬前IPv6还没有普及
1.1.2.1 认识 IP 地址
把一个 IP 地址,会分为两个部分
网络号(标识了一个局域网) + 主机号(标识了局域网中的一个设备)
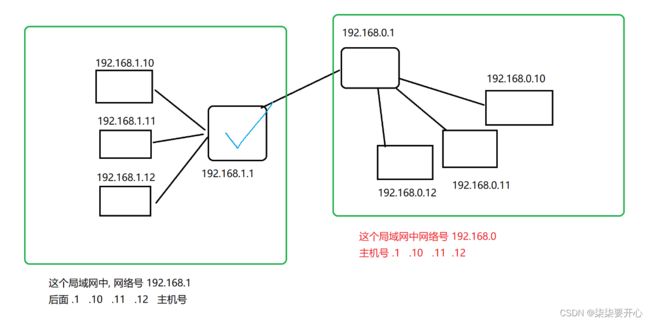
同一个局域网中的设备,网络号必须相同,主机号必须不同

一个 IP 地址,哪个部分是网络号,哪个部分是主句还,是不一定的
子网掩码,就是用来确定网络号的
![]()
子网掩码是 32 位的整数
左侧都是 1,右侧都是 0,不会出现1 0 交替出现
![]()
这里的 1 也不一定就非得是 24 哥,可以根据实际的网络环境,灵活配置
一般来说,家用的路由器,子网掩码就是 255.255.255.0

这是以前的网络划分的图,不过到了现在基本不使用了
如果一个 IP 地址,主机号全 0,当前这个 IP 就表示“网络号”
192.168.100.0
255.255.255.0
这是代表是一个局域网,不能给一个具体的主机,分配这个 IP
如果一个 IP 地址,主机号全是 1,当前这个 IP 就是一个“广播地址”
192.168.100.255
255.255.255.0
也是不能给具体的主机分配这个 IP 的
前面都说 UDP 天然能支持广播,就是和这个 IP 有关系
使用UDP socket 给这个地址发送 UDP 数据报,此时局域网中所有的设备,都能收到这个数据报
TCP 则无法和这个地址,建立连接
如果一个 IP 是 127 开头,此时这个 IP 就是“环回 ip”(loopback)
127.0.0.1(最常用的)
都表示“设备自身”,自己发给自己
这是操作系统提供了一个特殊的“虚拟网卡”,关联到了这个 IP 上
这里的 环回 IP 主要的用途就是进行一些测试性的工作
环回 IP 能够排除 网络不通 这个干扰因素,更好的排查代码中的问题
1.1.3 路由选择
路由选择,就是描述了 IP 协议(IP 数据报)转发过程
从 A 到 B ,中间可能有很多条可行的路径,到底如何走也是一个问题
平时,使用 地图软件,一搜索,就会出现很多条路径
地图软件能够做出这样的路径规划,主要是因为,开了全图的整个地图的信息,路径信息,都是在地图的服务器上全都存储的,可以给出“最优解"
但是 IP 数据报转发的时候,每个路由器,都是无法知道 网络的“全貌”的
只知道一些局部信息(一个路由器能只带那些设备和它自己是相连的)
这就意味着 IP 数据在这转发过程中,是一个“探索式”“启发式”过程
这个过程,很难给住“最优解”,只能是“较优解”
一个网络层的数据白,每次到达一个路由器,就会进行“问路”的操作
(一个接一个的进行询问)
每个路由器内部都有一个数据结构“路由表”,根据数据报中的 目的 IP,查询路由表
如果查到了,就直接按照路由表给定的方向(从哪个网络接口进行转发),继续转发就行了
如果没有查到,路由表里有一个“默认的表项”(下一跳地址),按照默认的表转发即可
这里的路由表的数据结构中的内容如何来
- 手动配置(网管可以根据需要手动配置)
- 自动花钱(北邮还有一系列的 路由表生成算法)
2. 数据链路层
2.1 认识以太网
在数据链路层也有很多协议,其中一个比较常见的常用的,就是“以太网协议”
通过网线 / 光纤,来通信,使用的协议,就是以太网协议
以太网,横跨数据链路层 + 物理层
网线水晶头,都是标准的
网线的水晶头,和电话的水晶头就不一样
2.1.1 以太网帧格式
以太网数据帧格式:
帧头 + 载荷(IP 数据报)+ 帧尾
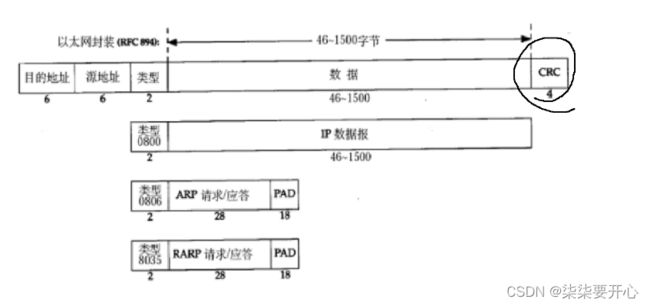
- 目的地址/源地址:
6 个字节,不过不是 IP 地址,是网络中的另一套地址体系,mac 地址(物理地址)
mac 地址 的 定位和 IP 地址是有一点的冲突/重合的
由于最开始搞网络的时候,网络层协议和数据链路层协议,是各自独立被发明的
地址这个东西就被搞了两份出来
这俩地址就被用到了不同的场景中
mac 地址由于是 6 个字节,能表示的方位,比 ip 地址大了 6w 多倍
ip 地址虽然早就不够用了,但是 mac 地址还是够用的
目前来说,每个设备都有唯一的 mac 地址
mac 地址,在网卡出厂的时候就被写死了,不会被改变
(mac 也可以作为一台网络设备 的身份标识)
![]()
mac 地址通常是 十六进制 表示的
两个十六进制数字就是一个字节
字节和字节之间通常使用 - 或者 : 来分割
IP 地址和 mac 地址各自的用途是什么?
IP 协议立足于全局,完成整个通信过程的路径规划工作
以太网 则是关注局部,相连两个设备之间的通信过程
传输层关注的是,起点和终点
网络层关注的是,从起点到终点的路径
数据链路层关注的是,“相邻节点”之间如何转发
源 IP 和 目的 IP 始终是整个通信过程中的,最初的起点和终点 (这里是不考虑 NAT 的情况)
源 mac 和 目的 mac 会根据你当前转发的过程,每次到达一个节点,往下一个节点转发的时候,源 mac 和 目的 mac 都会随之改变
- 类型:
描述载荷数据是什么样子的数据

这里的 IP 数据报不能超过 1500 字节
MUT:数据链路层的数据报能携带的最大载荷长度
IP 数据报的分包组包,大概率是因为 MTU 引起的,而不是触发 64KB 上限引起的
不同数据链路层的协议的 MTU 是不一样的
(也和物理层的介质有关)
MTU 可以考虑成一辆汽车的载重量,路是土路,汽车太重了,就容易压坏,路是沥青的路,载重量就更大,路是高速公路级别的,载重量就更大

下面的这两种次协议不是传输“业务数据”,而是辅助转发的协议
像交换机这样的设备,收到以太网数据帧的时候,就需要进行转发
(这个转发过程就需要能够根据 mac 地址,判断出数据要走哪个网口)
这里的网口是“物理意义”上查网线的口
(IP 协议,路由器,走哪个网络接口,其实是抽象的概念,最终还是要在数据链路层才能觉得是走哪个网口)

具体如何转发?
交换机内部也有一个数据结构“转发表,和前面说的路由表,还是有点像,但其实还是有一系列差别
转发表是一个简单的像 hash 这样的映射
(当然这个表不一定是软件实现的,也可能是硬件实现的)
转发表如何构造(里面的内容咋来的?)
主要就是通过 arp 协议来生成的
2.1.2 DNS 应用层协议
这是一个 域名解析系统
使用 IP 地址,来描述设备在网络上的位置
为了让自己的网站可以得到宣传,就引入了“域名”来进行解决
(IP 地址不适合进行宣传)
域名是一串“单词”来表示实际意义
比如:www.baidu.com
这样就需要有一套自动的系统,把域名翻译成 IP 地址
(域名 和 IP 想象成一组键值对)
最早的域名解析系统,是通过一个简单的文件来实现的(hosts 文件)

但是真的打开 host 文件,大概率是空的(这个机制已经不使用了)
不过有时候进行一些测试工作的时候,需要手动编辑这个
使用 hosts 文件来维护 域名 和 ip 的映射关机,非常不方便
这个时候 就有了 DNS 系统(一组服务器)
把上述这样的映射关系,保存到这个服务器中了
如果想访问某个域名,就先给这个 DNS 服务器发起请求,询问一下当前域名对应的 IP,然后再访问目标网站
后续如果有域名的更新,只需要更新这一组指定的服务器即可,不需要修改每个用户电脑的 hosts
全世界,无时不刻都有很多设备需要进行 DNS 的请求,这一组的服务器,能扛得住这么高的请求量吗?
一个服务器硬件资源是有限的(CPU,内存,硬盘,网络带宽…)
服务器处理每个请求,肯定都是要消耗一定的资源的
单位时间内,请求太多,消耗的总资源超过了机器本身的资源上限,这样机器就挂了
这种所谓的“高并发”问题,核心思路,就是两条
- 开源
搭建DNS系统的大佬们,就开始号召各个网络运营商,你们都可以自己搭建一组 “DNS 镜像服务器”,镜像服务器的数据,都从他们这边来同步
此时用户就会优先访问离自己最近的镜像服务器 - 节流
让请求量变少,让每个上网的设备,搞一个本地缓存
我的电脑 1min 之内要访问 10 次 www.sogou.com
只是让第一次请求 DNS 即可,把请求得到的结果保存到本地,后面 9 次请求都使用第一次的结果即可
(域名的变换,没有那么频繁)