shell之sed和awk
目录
sed编辑器
sed常用选项
sed常用操作:
基本用法
sed脚本格式
例:
搜索替代
改配置文件
AWK
基础用法
取 IP 地址
awk 常见的内置变量
sed编辑器
sed是一种流编辑器,流编辑器会在编辑器处理数据之前基于预先提供的–组规则来编辑数据流。
sed编辑器可以根据命令来处理数据流中的数据,这些命令要么从命令行中输入,要么存储在一个命令文本文件中。
sed的工作流程主要包括读取、执行和显示三个过程:
●读取: sed从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)
●执行:默认情况下,所有的sed命令都在模式空间中顺序地执行,除非指定了行的地址,否则sed 命令将会在所有的行上依次执行。
●显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。在所有的文件内容都被处理完成之前,,上述过程将重复执行,直至所有内容被处理完。
在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的sed命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
命令格式:
sed -e '操作' 文件1文件2...
sed -n -e '操作' 文件1文件2 ...
sed -f 脚本文件 文件1文件2 ...
sed -i -e '操作' 文件1文件2 ...
sed -e '{
操作1
操作2
...
}' 文件1 文件2 ...
sed常用选项
-e 或--expression=: 表示用指定命令来处理输入的文本文件,只有一一个操作命令时可省略,一-般在执行多个操作命令使用
-f 或--file=:表示用指定的脚本文件来处理输入的文本文件。
-h 或--help: 显示帮助。
-n、--quiet 或silent: 禁止:sed编辑器输出,但可以与p命令- -起使用完成输出。
-i: 直接修改目标文本文件。
sed常用操作:
s:替换,替换指定字符。
d:删除,删除选定的行。
a: 增加,在当前行下面增加一-行指定内容。
i: 插入,在选定行上面插入一行指定内容。
c:替换,将选定行替换为指定内容。
y:字符转换,转换前后的字符长度必须相同。
p:打印,如果同时指定行,表示打印指定行:如果不指定行,表示打印所有内容:如果有非打印字符,则以ASCII码输出。其通常与“-n”选项一-起使用。
=: 打印行号。
1(小写L):打印数据流中的文本和不可打印的ASCII字符(比如结束符$、制表符\t)
基本用法
默认将输入内容打印出来

查看文件内容
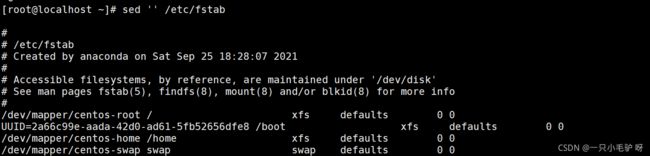 支持重定向
支持重定向

支持管道符

sed脚本格式
'地址+命令'组成
1.不给地址:对全文进行处理(比如行号)
2.单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
3. 地址范围:
#,# #从#行到第#行,3,6 从第3行到第6行
#,+# #从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/ 第一个正则表达式和第二个正则表达式之间的行
#,/pat/ 从#号行为开始找到 pat为止
/pat/,# 找到#号个pat为止
4. 步进:~
1~2 奇数行
2~2 偶数行
例:
带有自动打印功能,p又再打印一遍
-n 选项关闭自动打印功能

直接显示第3行
![]()
直接显示第二行内容
![]()
支持正则表达式 自动打印需要关闭否则会全部打印

将包含root的行打印出来 /root(需要匹配的内容)/p(打印) 文件名
与 grep root /etc/passwd 功能相同
![]()
显示范围 行号,行号 显示范围

3 往后加4行

可以匹配 两个正则表达式之间的行
显示b开头 和f开头中间的行

先开始找b开头一直找到f开头
然后再重新找b开头,一找到f开头,没有f开头就全显示
重复循环
查找几点几分到几点几分之间的日志

奇数偶数表示

修改文件内容,常常用于修改配置文件
-i 与 -i.bak
修改文件 修改文件前先备份

-a 追加




搜索替代
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写![]()

改配置文件

AWK
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔,并按模式或者条件执行编辑命令。而awk比较倾向于将一行分成多个字段然后进行处理。AWK信息的读入也是逐行指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互 的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。
工作原理:前面提到 sed 命令常用于一整行的处理,而 awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
格式:
awk [选项] ‘模式条件{操作}’ 文件1 文件2....
awk -f|-v 脚本文件 文件1 文件2.....
模式:
未指定表示 为空
/1/2/代表正则表达式
关系表达式基础用法
再打印一遍


![]()

![]()

取 IP 地址

[root@localhost ~]#wc -l /etc/passwd
45 /etc/passwd
[root@localhost ~]#awk -F: '{print $0}' /etc/passwd
#$0代表全部元素
[root@localhost ~]#awk -F: '{print $1}' /etc/passwd
#代表第一列
[root@localhost ~]#awk -F: '{print $1,$3}' /etc/passwd
#代表第一第三列
[root@localhost ky15]#awk '/^root/{print}' passwd
#已root为开头的行
[root@localhost ky15]#grep -c "/bin/bash$" passwd
#统计当前已/bin/bash结尾的行
2
##### BEGIN{}模式表示,在处理指定的文本前,需要先执行BEGIN模式中的指定动作; awk再处理指定的文本,之后再执行END模式中的指定动作,END{}语句中,一般会放入打印结果等语句。
awk 常见的内置变量
FS :指定每行文本的字段分隔符,缺省为空格或制表位。与 “-F”作用相同 -v "FS=:"
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
FS
[root@localhost ky15]#awk -v FS=: '{print $1FS$3}' /etc/passwd
#此处FS 相当于于变量
[root@localhost ky15]#awk -F: '{print $1":"$3}' /etc/passwd
shell中的变量
[root@localhost ky15]#fs=":";awk -v FS=$fs '{print $1FS$3}' /etc/passwd
#定义变量传给FS
OFS
[root@localhost ky15]#fs=":";awk -v FS=$fs -v OFS="+" '{print $1,$3}' /etc/passwd
#输出分隔符
NF
[root@localhost ky15]#awk -F: '{print NF}' /etc/passwd
[root@localhost ky15]#awk -F: '{print $NF}' /etc/passwd
#最后一个字段
[root@localhost ky15]#df|awk -F: '{print $(NF-1)}'
#倒数第二行
[root@localhost ky15]#df|awk -F "[ %]+" '{print $(NF-1)}'
NR
[root@localhost ky15]#awk '{print $1,NR}' /etc/passwd
##行号
[root@localhost ky15]#awk 'NR==2{print $1}' /etc/passwd
#只取第二行的第一个字段
[root@localhost ky15]#awk 'NR==1,NR==3{print}' passwd
#打印出1到3 行
[root@localhost ky15]#awk 'NR==1||NR==3{print}' passwd
#打印出1和3行
[root@localhost ky15]#awk '(NR%2)==0{print NR}' passwd
#打印出函数取余数为0行
[root@localhost ky15]#awk '(NR%2)==1{print NR}' passwd
#打印出函数取余数为1的行
[root@localhost ky15]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
[root@localhost ky15]#seq 10|awk 'NR>5 && NR<10'
#取 行间
6
7
8
9
[root@localhost ky15]#awk '$3>1000{print}' /etc/passwd