
有条件的最短路径一定长于无条件的最短路径
朴素dij
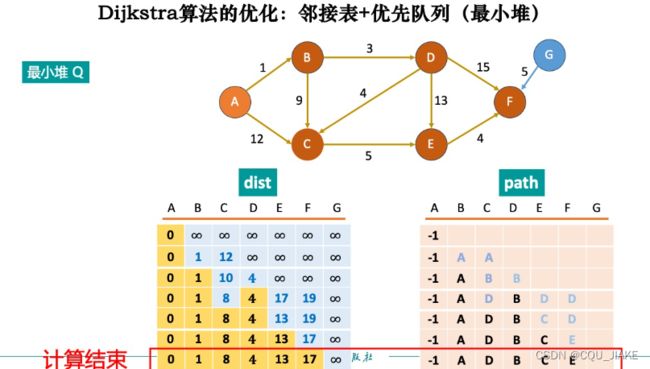
dij的思路就是先入起点,然后从起点开始向四周遍历,每次确定一个实际最短的,,这里注意,正是因为没有负权,所以越早遇到的最短,就一定是最短,不然就有可能后续还有负权会使到这个点的代价更小;
每次迭代确定一个最短的,可优化的就是中间找还没访问过的最短的




第 一个for循环仅表示迭代次数,每层迭代下,嵌套两个并列循环,第一个为找到符合要求的点,第二个是依据符合要求的点进行松弛处理操作
for(int i=0; i dist[j]))
t=j;
st[t]=true; // 代表 t 这个点已经确定最短路了
for(int j=1; j<=n; j++) // 用 t 更新其他点的最短距离
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
堆优化dij

 就是说依据符合要求点进行松弛,如果能成功松弛,就意味着dis缩小了一次,就加入到堆里
就是说依据符合要求点进行松弛,如果能成功松弛,就意味着dis缩小了一次,就加入到堆里
在堆里时,判断是否满足条件,就是看该点是否已经被确定,如果该点已经被确定,那么说明在取堆头时,取这个堆头之前就已经有更短的dis到了这个点,那么此时的路径长度就一定不是最短的,所以就不再在此基础上进行松弛;如果没有收集过,就说明是第一次遇到,那么可以据此进行松弛操作;然后在堆里排列的时候,就是严格按照dis的大小排,而不是入队的时间先后顺序

ACD
A注意如果一个节点能多次入队,就说明一直能有路径可以松弛,就是说可以不断更新这个点的最短路径;就是说,入队条件只有能松弛时才会入队,而如果能松弛,就意味着最短路径被更新了,如果某节点能不断入队,说明最短路径在不断的更新
即只要点还没出队,那么它的最小路径就还没确定;而如果一个点的最小路径确定了,那么后续的点也都不可能在对这个点进行松弛操作了,这个点也不会再被更新,重新入队了,因为后续点要进行松弛操作,都是建立在堆的后续基础上,而后续基础都已经比此时的访问代价大了,即
dis[i]

#include
#include
#include
#include
using namespace std;
//要做改进就是用布尔vis去记录访问情况
//这个用vis的主要目的不是不让其去更新了,而是为了防止它继续更新,
//由于是基于dis的改良,所以优先队列里记录的就是到各个点的代价,但还需要记录目的地,因为只是记录代价是少信息的
//在dis数组里,下标就代表着目的地
const int maxn = 1e4;
const int maxm = 1e4;
struct edge {
int v, w, next;
}e[maxm];
int n, m, cnt = 0;
int h[maxn];
void add(int u, int v, int w) {
e[++cnt].v = v;
e[cnt].w = w;
e[cnt].next = h[u];
h[u] = cnt;
}
typedef pair pii;//由于数对的默认排序规则为先比第一个再比第二个,所以就应该定义第一个为距离dis,第二个为目的地编号
int dis[maxn];
int main() {
dis[1] = 0;
priority_queue, greater>heap;//优先队列的顺序与sort不同,取了个反
heap.push({ 0,1 });//这个优先队列实际上是把找点与松弛揉到一块了
while (!heap.empty()) {
pii t = heap().top;
heap.pop();
int u = t.second, d = t.first;//获取数对的第一个第二个信息,不需要(),因为本身就不是函数
if (st[u])continue;//已经访问过了,已经访问过了就意味着在这个点的基础上已经对后续的点做了松弛操作,那么此时如果再做是完全没意义的
st[u] = 1;
for (int i = h[u]; i; i = e[i].next) {
int v = e[i].v;
if (dis[v] > dis[u] + e[i].w) {
dis[v] = dis[u] + e[i].w;
heap.push({ dis[v],v });
}
}
}
return 0;
}
这个dis是从起点到终点的距离,如果某个终点已经确定过了,那么后续如果在确定某个终点后,再次对其可以到达的点做松弛操作,如果可以到达相同的点,其代价一定比现在要大,因为后续的代价是建立在要达到那个代价更大的点的基础上的
这里dis的更新,与访问数组的置1是分离的,数组的置1,代表着这个点已经进行了松弛操作,而不仅意味着是被确定了;但是如果要进行松弛操作,也的是建立在确定的最小dis基础上;而后续再访问到同样的点,其所确定的dis一定比现在大
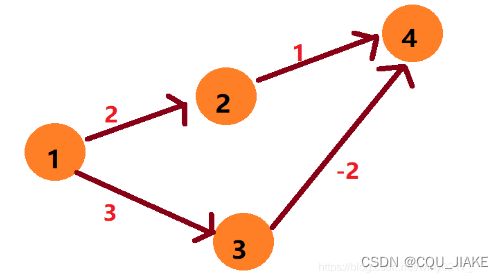
不能确定负权,是因为比如这个4,假设1到3代价很大,到4的负权也很大,从1到2再到4都是正权,那么会先通过1到2到4,如果4到后续的点代价比到3的代价小,就会在1到2到4的基础上松弛掉后续的所有点,但实际上这些松弛操作都是建立在错误的最小dis基础上的,但如果没有负权的话就不会有这一情况
数对pair的排序规则,优先队列
数对的优先队列的排序规则是根据数对中的第一个数从大到小排序,如果第一个数相同,则根据第二个数从小到大排序。
或许基于这一特性可以用来字典序?
即排序的时候编号都是按照从小到大的字典序了
本来只是希望多一个保留目的地的信息,用了pair之后,不仅保留了目的地的信息,还使其信息按照字典序排序
#include
#include
#include
#include
using namespace std;
//要做改进就是用布尔vis去记录访问情况
//这个用vis的主要目的不是不让其去更新了,而是为了防止它继续更新,
//由于是基于dis的改良,所以优先队列里记录的就是到各个点的代价,但还需要记录目的地,因为只是记录代价是少信息的
//在dis数组里,下标就代表着目的地
const int maxn = 1e5 + 2;
const int maxm = 2e5 + 3;
struct edge {
int v, w, next;
}e[maxm];
int n, m, cnt = 0;
int h[maxn];
void add(int u, int v, int w) {
e[++cnt].v = v;
e[cnt].w = w;
e[cnt].next = h[u];
h[u] = cnt;
}
int dis[maxn];
int s;
const int inf = 1e9;
bool vis[maxn];
typedef pair pii;
priority_queue, greater>q;
int main() {
cin >> n >> m >> s;
for (int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w;
add(u, v, w);
}
for (int i = 1; i <= n; i++)dis[i] = inf;
dis[s] = 0;
q.push({ 0,s });
while (!q.empty()) {
int d = q.top().first, tar = q.top().second;
q.pop();
if (vis[tar])continue;
vis[tar] = 1;
dis[tar] = d;//不应该在这里做修改,因为可能有节点多次入队,
//但好像也可以,因为前面有是否访问的判断,如果到这里的话,就说是第一次访问到,那就一定是代价最小的
for (int j = h[tar]; j; j = e[j].next) {
if (dis[e[j].v] > dis[tar] + e[j].w) {
q.push({ dis[tar] + e[j].w,e[j].v });
}
}
}
for (int i = 1; i <= n; i++) {
cout << dis[i] << " ";
}
return 0;
}
注意typedef后要加;
SPFA
先让初始点入队,然后用队头节点去更新后续可以到达的点,如果更新成功就入队,只有更新成功时才入队,每次操作时,都直接在dis上去操作,
注意是普通队列而不是优先队列,如果有相同的点重复出队,就意味着那个点的dis在不断被更新,在此基础上它也就能不断的去松弛它可以到达的点,进而使后续的点也能被更新
如果有负环的话,会使重复的节点一直重复的入队与出队,即有点的dis在一直被缩小,在此基础上,后续点的dis也可以被缩小,成环的话,那么起点的dis可以继续被缩小,所以就会形成死循环
如果不是负环,正环的话,起始点的dis被更新,后续点也只会被更新一次,就是在新dis基础上做更新,再回来的话,就会有额外成本,松弛不了
如果要判断负环,就多一个cnt数组,记录起点到x的最短路径所经过的边数,如果边数大于等于n了,就说明一定存在负环,因为走完所有点要n-1条边,再加一条就一定会成环,即走过同一节点两次
 ,这个cnt是在起点处加1做的覆盖,所以即使有负权也不会无限加,而是被这条路径上的cnt所覆盖掉,除非是负环
,这个cnt是在起点处加1做的覆盖,所以即使有负权也不会无限加,而是被这条路径上的cnt所覆盖掉,除非是负环
int dis[maxn];
int cs[maxn];
void spfa(int s) {
queueq;
q.push(s);
dis[s] = 0;
while (!q.empty()) {
int cur = q.front();
q.pop();
for (int i = h[cur]; i; i = e[i].next) {
int u = e[i].v;
if (dis[u] > dis[cur] + e[i].w) {
q.push(u);
cs[u] = cs[cur] + 1;
}
}
}
}